


How to Access All PDF DOM Objects in C#
To access PDF DOM objects in C#, use IronPDF's ObjectModel property which provides programmatic access to text, images, and path objects within PDF documents, allowing you to read, modify, translate, scale, and remove elements directly.
Quickstart: Access and Update PDF DOM Elements with IronPDF
Start manipulating PDF documents using IronPDF's DOM access features. This guide shows how to access the PDF DOM, select a page, and modify text objects. Load your PDF, access the desired page, and update content with a few lines of code.
-
Install IronPDF with NuGet Package Manager
-
Copy and run this code snippet.
var objs = IronPdf.ChromePdfRenderer.RenderUrlAsPdf("https://example.com").Pages.First().ObjectModel; -
Deploy to test on your live environment
Start using IronPDF in your project today with a free trial

Minimal Workflow (5 steps)
- Download the C# library to access PDF DOM Objects
- Import or render the targeted PDF document
- Access the PDF's
Pagescollection and select the desired page - Use the ObjectModel property to view and interact with the DOM objects
- Save or export the modified PDF document
How Do I Access DOM Objects in PDFs?
The ObjectModel is accessed from the PdfPage object. First, import the target PDF and access its Pages property. From there, select any page to access the ObjectModel property. This enables interaction with PDF content programmatically, similar to working with HTML DOM elements.
When working with PDF DOM objects, you access the underlying structure of the PDF document. This includes text elements, images, vector graphics (paths), and other content that makes up the visual representation of your PDF. IronPDF provides an object-oriented approach to PDF manipulation that integrates with C# applications.
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object.csusing IronPdf;
using System.Linq;
// Instantiate Renderer
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Create a PDF from a URL
PdfDocument pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/");
// Access DOM Objects
var objects = pdf.Pages.First().ObjectModel;Imports IronPdf
Imports System.Linq
' Instantiate Renderer
Private renderer As New ChromePdfRenderer()
' Create a PDF from a URL
Private pdf As PdfDocument = renderer.RenderUrlAsPdf("https://ironpdf.com/")
' Access DOM Objects
Private objects = pdf.Pages.First().ObjectModel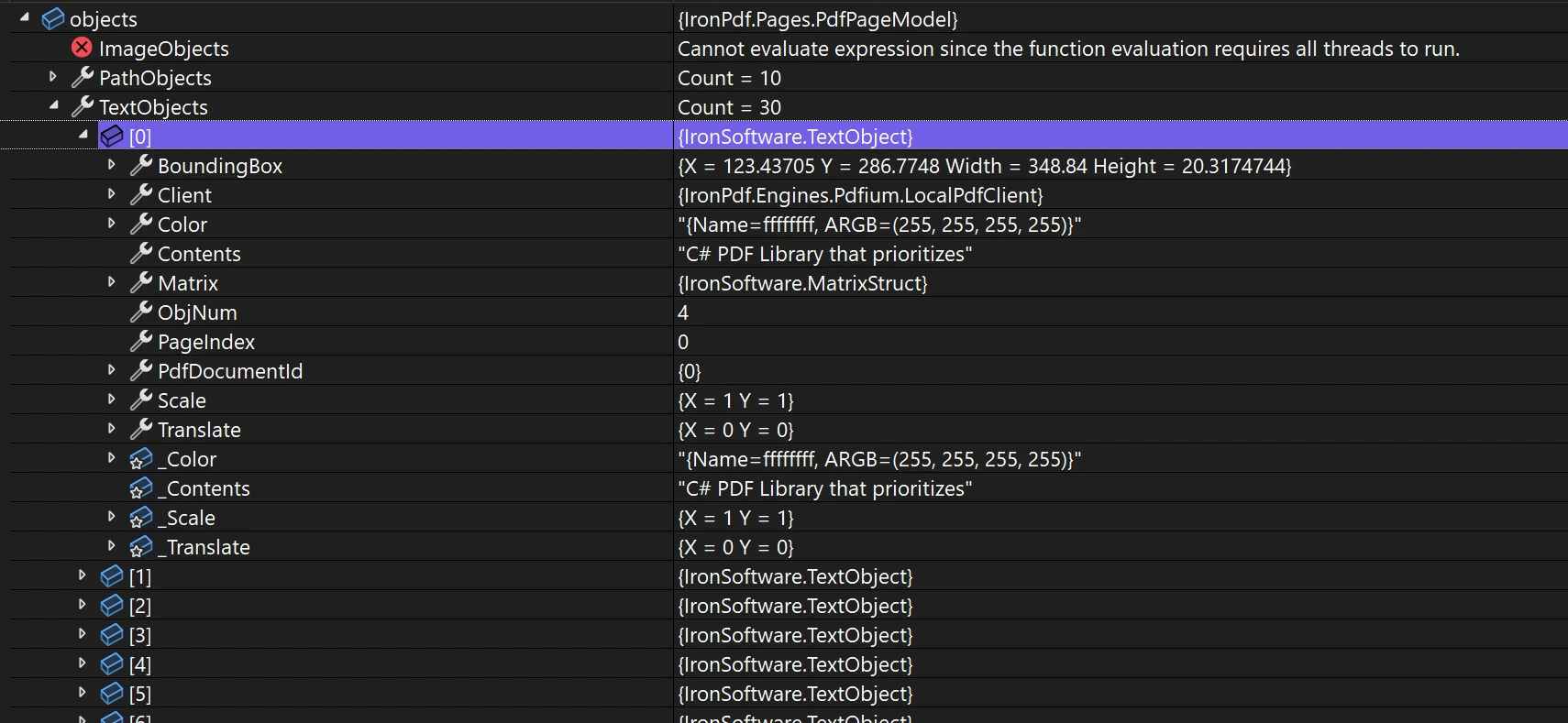
The ObjectModel property contains ImageObject, PathObject, and TextObject. Each object contains information about its page index, bounding box, Scale, and Translation. This information can be modified. For rendering options, you can customize how these objects display. When working with custom margins, understanding object positioning is important.
<ImageObject>:
Height: Height of the imageWidth: Width of the imageExportBytesAsJpg: Method to export the image as JPG byte array
<PathObject>:
FillColor: The fill color of the pathStrokeColor: The stroke color of the pathPoints: Collection of points defining the path
<TextObject>:
Color: The color of the textContents: The actualTextcontent
Each object type provides methods and properties tailored to their content type. When you need to extract text and images or modify specific content, these objects provide granular control. This is useful when working with PDF forms where you need to manipulate form fields programmatically.
How Can I Retrieve Glyph Information and Bounding Boxes?
When specifying exact glyphs with custom fonts, retrieving bounding box and glyph information is essential. IronPDF provides this information for pixel-perfect positioning when drawing text and bitmaps on existing PDFs.
Access the ObjectModel from the PdfPage object. Then access the TextObjects collection. Call the GetGlyphInfo method to retrieve glyph and bounding box information.
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-retrieve-glyph.csusing IronPdf;
using System.Linq;
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
var glyph = pdf.Pages.First().ObjectModel.TextObjects.First().GetGlyphInfo();Imports IronPdf
Imports System.Linq
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
Dim glyph = pdf.Pages.First().ObjectModel.TextObjects.First().GetGlyphInfo()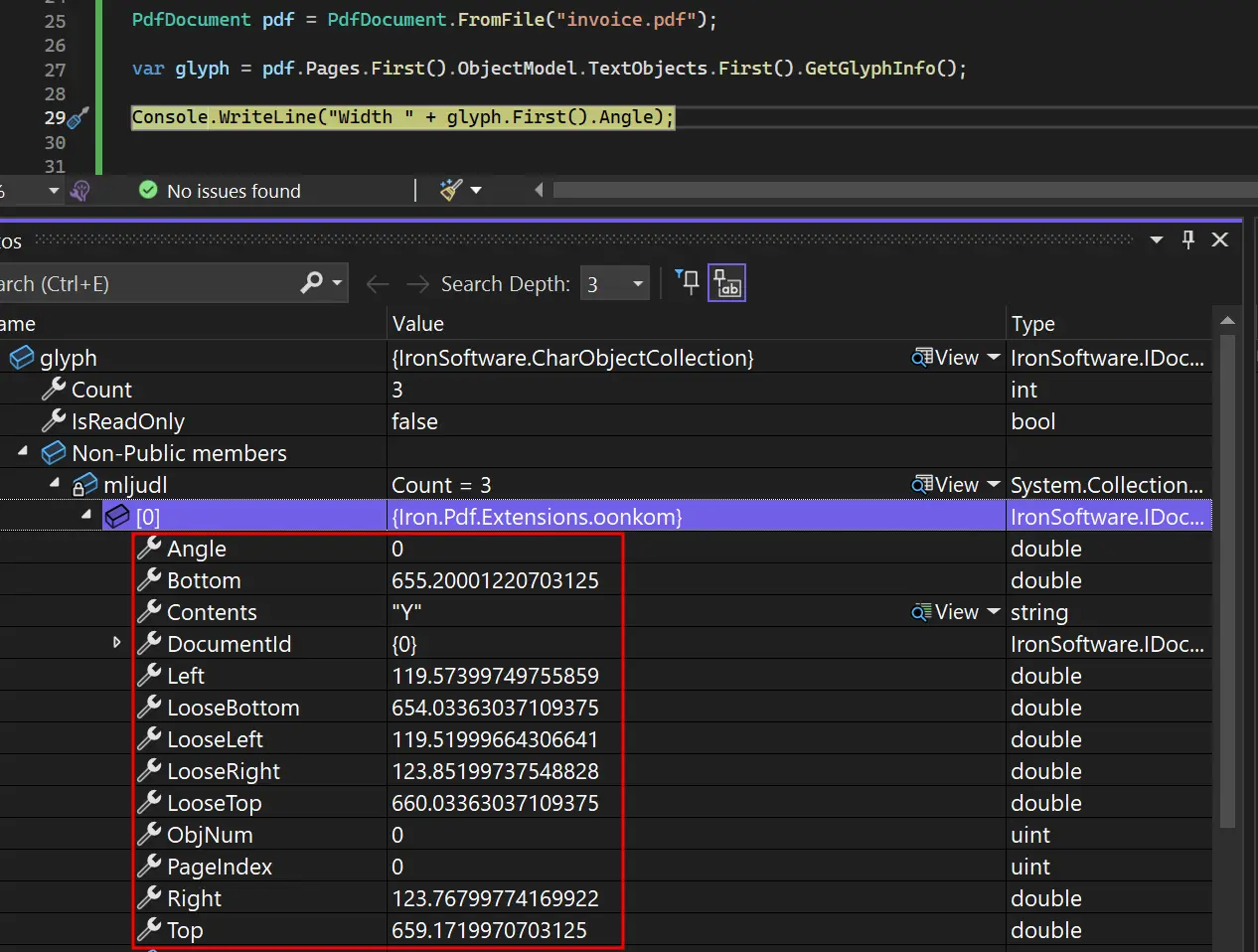
The glyph information includes positioning data, font metrics, and character-specific details for advanced PDF manipulation. This allows creation of PDF processing applications that handle complex typography and layout requirements. When working with custom fonts, this glyph-level access ensures accurate rendering across systems.
How Can I Translate PDF Objects?
Adjust PDF layout by repositioning elements like text or images. Move objects by changing their Translate property. This functionality is part of IronPDF's PDF transformation capabilities.
The example below renders HTML using CSS Flexbox to center text. It accesses the first TextObject and translates it by assigning a new PointF to the Translate property. This shifts the text 200 points right and 150 points up. For more examples, visit the translate PDF objects example page.
What Code Do I Use to Translate Objects?
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-translate.csusing IronPdf;
using System.Drawing;
using System.Linq;
// Setup the Renderer
var renderer = new ChromePdfRenderer();
// We use CSS Flexbox to perfectly center the text vertically and horizontally.
var html = @"
<div style='display: flex; justify-content: center; align-items: center; font-size: 48px;'>
Centered
</div>";
// Render the HTML to a PDF
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
// Save the original PDF to see the "before" state
pdf.SaveAs("BeforeTranslate.pdf");
// Access the first text object on the first page
// In this simple HTML, this will be our "Centered" text block.
var textObject = pdf.Pages.First().ObjectModel.TextObjects.First();
// Apply the translation
// This moves the object 200 points to the right and 150 points up from its original position.
textObject.Translate = new PointF(200, 150);
// Save the modified PDF to see the "after" state
pdf.SaveAs("AfterTranslate.pdf");Imports IronPdf
Imports System.Drawing
Imports System.Linq
' Setup the Renderer
Dim renderer As New ChromePdfRenderer()
' We use CSS Flexbox to perfectly center the text vertically and horizontally.
Dim html As String = "
<div style='display: flex; justify-content: center; align-items: center; font-size: 48px;'>
Centered
</div>"
' Render the HTML to a PDF
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
' Save the original PDF to see the "before" state
pdf.SaveAs("BeforeTranslate.pdf")
' Access the first text object on the first page
' In this simple HTML, this will be our "Centered" text block.
Dim textObject = pdf.Pages.First().ObjectModel.TextObjects.First()
' Apply the translation
' This moves the object 200 points to the right and 150 points up from its original position.
textObject.Translate = New PointF(200, 150)
' Save the modified PDF to see the "after" state
pdf.SaveAs("AfterTranslate.pdf")What Does the Translation Result Look Like?
The output shows "Centered" shifted 200 points right and 150 points up from its original position.
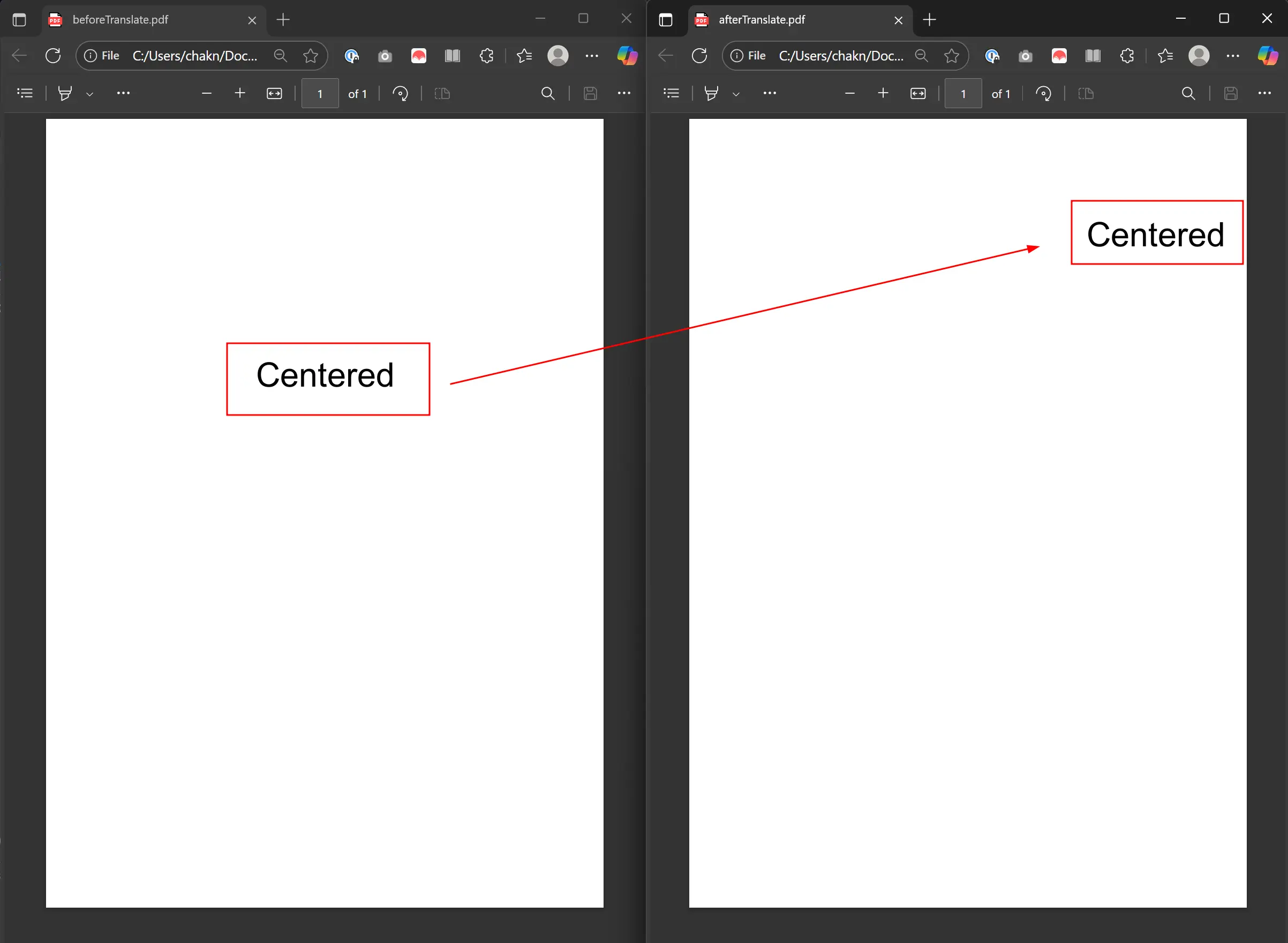
Translation operations maintain the object's original properties like font, size, and color while only changing position. This is ideal for layout adjustments without affecting visual appearance. This feature works with headers and footers when repositioning dynamically generated content.
How Do I Scale PDF Objects?
Resize PDF objects using the Scale property. This property acts as a multiplier. Values greater than 1 increase size, while values between 0 and 1 decrease it. Scaling is essential for dynamic layouts and adjusting content to fit page dimensions. See the scale PDF objects guide for more examples.
The example renders HTML containing an image. It accesses the first ImageObject and scales it to 70% by assigning Scale a new PointF with 0.7 for both axes.
What's the Code for Scaling PDF Objects?
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-scale.csusing IronPdf;
using System.Linq;
// Setup the Renderer
var renderer = new ChromePdfRenderer();
// The image is placed in a div to give it some space on the page.
string html = @"<img src='https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTi8LuOR6_A98euPLs-JRwoLU7Nc31nVP15rw&s'>";
// Render the HTML to a PDF
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
// Save the PDF before scaling for comparison
pdf.SaveAs("BeforeScale.pdf");
// Access the first image object on the first page
var image = pdf.Pages.First().ObjectModel.ImageObjects.First();
// We scale the image to 70% of its original size on both the X and Y axes.
image.Scale = new System.Drawing.PointF(0.7f, 0.7f);
// Save the modified PDF to see the result
pdf.SaveAs("AfterScale.pdf");Imports IronPdf
Imports System.Linq
Imports System.Drawing
' Setup the Renderer
Dim renderer As New ChromePdfRenderer()
' The image is placed in a div to give it some space on the page.
Dim html As String = "<img src='https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTi8LuOR6_A98euPLs-JRwoLU7Nc31nVP15rw&s'>"
' Render the HTML to a PDF
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
' Save the PDF before scaling for comparison
pdf.SaveAs("BeforeScale.pdf")
' Access the first image object on the first page
Dim image = pdf.Pages.First().ObjectModel.ImageObjects.First()
' We scale the image to 70% of its original size on both the X and Y axes.
image.Scale = New PointF(0.7F, 0.7F)
' Save the modified PDF to see the result
pdf.SaveAs("AfterScale.pdf")Apply different scaling factors to X and Y axes independently for non-uniform scaling. This is useful for fitting content into specific dimensions. When working with custom paper sizes, scaling helps ensure content fits within page boundaries.
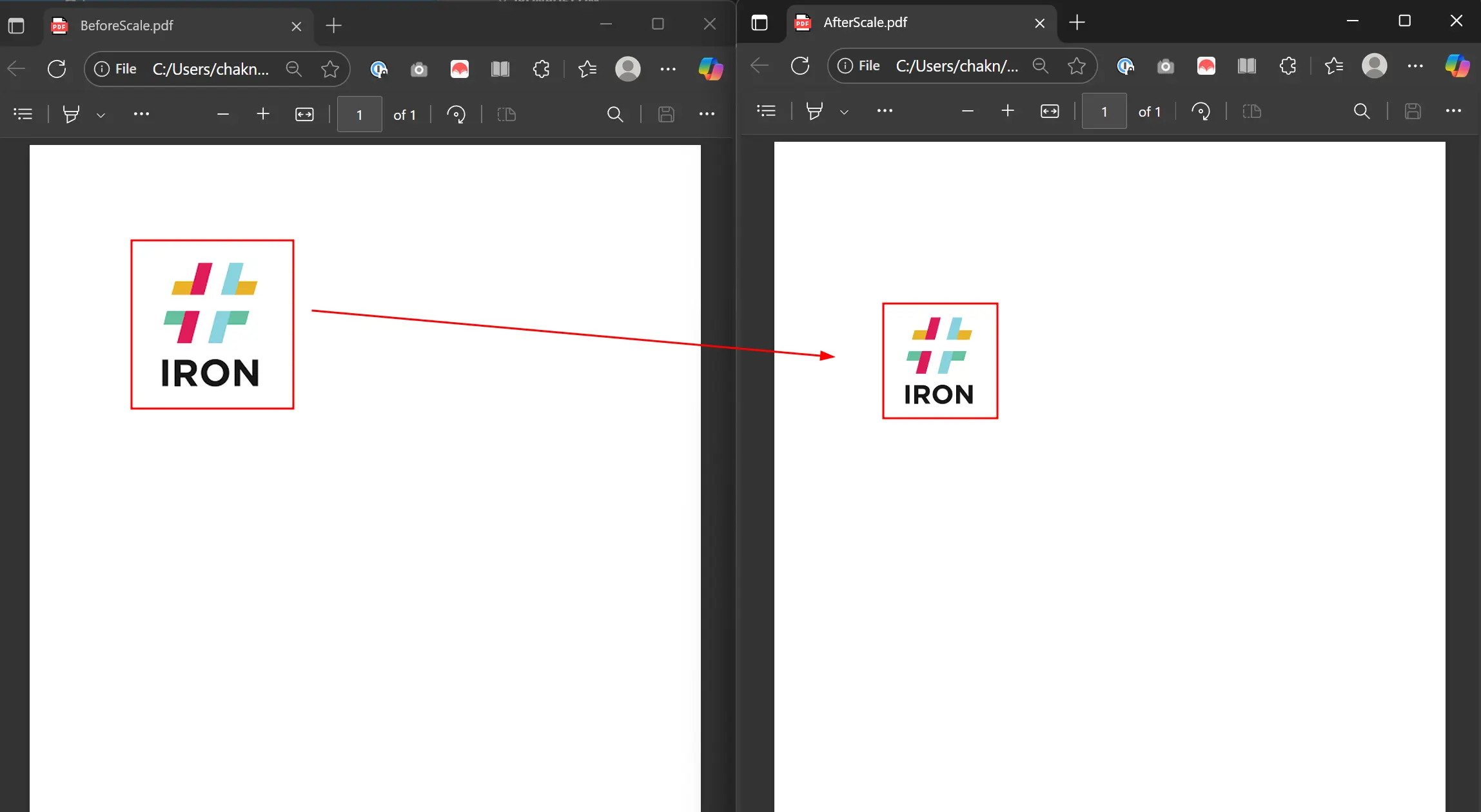
What Does Scaling Look Like in Practice?
The output shows the image scaled to 70% of its original size.
My favorite library of this kind is IronPDF. It allows for fast and efficient manipulation of PDF files. It also has many valuable features, like exporting to PDF/A format and digitally signing PDF documents.
IronOCR means we can save $40,000 annually from manual processing, while enhancing productivity and freeing up resources for high-impact tasks. I would highly recommend it.
The IronSuite play a crucial role in our operations. These are tools that increase efficiencies across the business including creating floor plans and improving inventory management.
How Can I Remove PDF Objects?
Remove objects by accessing the PDF DOM collection like ImageObjects or TextObjects. Call RemoveAt on the collection, passing the index of the object to delete. This is useful for redacting content or simplifying documents. Learn more at the remove PDF objects example.
The code loads BeforeScale.pdf and removes the first image from the first page.
What Code Should I Use to Remove Objects?
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-remove.csusing IronPdf;
using System.Linq;
// Load the PDF file we created in the Scale example
PdfDocument pdf = PdfDocument.FromFile("BeforeScale.pdf");
// Access DOM Objects
var objects = pdf.Pages.First().ObjectModel;
// Remove first image
objects.ImageObjects.RemoveAt(0);
// Save the modified PDF
pdf.SaveAs("removedFirstImage.pdf");Imports IronPdf
Imports System.Linq
' Load the PDF file we created in the Scale example
Dim pdf As PdfDocument = PdfDocument.FromFile("BeforeScale.pdf")
' Access DOM Objects
Dim objects = pdf.Pages.First().ObjectModel
' Remove first image
objects.ImageObjects.RemoveAt(0)
' Save the modified PDF
pdf.SaveAs("removedFirstImage.pdf")What Happens When I Remove Multiple Objects?
Indices of remaining objects shift after removal. When removing multiple objects, remove them in reverse order to maintain correct indices. This technique helps when you redact text from sensitive documents.
How Do I Combine Multiple DOM Operations?
IronPDF's DOM access enables sophisticated document processing workflows. Combine operations for complex transformations:
When Should I Use Combined Operations?
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-7.cs// Example of combining multiple DOM operations
using IronPdf;
using System.Linq;
PdfDocument pdf = PdfDocument.FromFile("complex-document.pdf");
// Iterate through all pages
foreach (var page in pdf.Pages)
{
var objects = page.ObjectModel;
// Process text objects
foreach (var textObj in objects.TextObjects)
{
// Change color of specific text
if (textObj.Contents.Contains("Important"))
{
textObj.Color = System.Drawing.Color.Red;
}
}
// Scale down all images by 50%
foreach (var imgObj in objects.ImageObjects)
{
imgObj.Scale = new System.Drawing.PointF(0.5f, 0.5f);
}
}
pdf.SaveAs("processed-document.pdf");
Imports IronPdf
Imports System.Linq
Imports System.Drawing
Dim pdf As PdfDocument = PdfDocument.FromFile("complex-document.pdf")
' Iterate through all pages
For Each page In pdf.Pages
Dim objects = page.ObjectModel
' Process text objects
For Each textObj In objects.TextObjects
' Change color of specific text
If textObj.Contents.Contains("Important") Then
textObj.Color = Color.Red
End If
Next
' Scale down all images by 50%
For Each imgObj In objects.ImageObjects
imgObj.Scale = New PointF(0.5F, 0.5F)
Next
Next
pdf.SaveAs("processed-document.pdf")What Are Common Use Cases for Combined Operations?
Combined DOM operations work well for:
- Batch Document Processing: Process documents to standardize formatting or remove sensitive content
- Dynamic Report Generation: Modify template PDFs with real-time data while controlling layout
- Content Migration: Extract and reorganize content from PDFs into new layouts
- Accessibility Improvements: Enhance documents by modifying text size, contrast, or spacing
These techniques enable powerful PDF processing applications that handle complex modifications. For managing document properties, see the metadata management guide.
How Does DOM Access Compare to Other PDF Manipulation Methods?
Working with PDF DOM provides advantages over traditional approaches:
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-8.cs// Example: Selective content modification based on criteria
using IronPdf;
using System.Linq;
PdfDocument report = PdfDocument.FromFile("quarterly-report.pdf");
foreach (var page in report.Pages)
{
var textObjects = page.ObjectModel.TextObjects;
// Highlight negative values in financial reports
foreach (var text in textObjects)
{
if (text.Contents.StartsWith("-$") || text.Contents.Contains("Loss"))
{
text.Color = System.Drawing.Color.Red;
}
}
}
report.SaveAs("highlighted-report.pdf");
Imports IronPdf
Imports System.Linq
Imports System.Drawing
' Example: Selective content modification based on criteria
Dim report As PdfDocument = PdfDocument.FromFile("quarterly-report.pdf")
For Each page In report.Pages
Dim textObjects = page.ObjectModel.TextObjects
' Highlight negative values in financial reports
For Each text In textObjects
If text.Contents.StartsWith("-$") OrElse text.Contents.Contains("Loss") Then
text.Color = Color.Red
End If
Next
Next
report.SaveAs("highlighted-report.pdf")This granular control isn't possible with HTML to PDF conversion alone, making DOM access essential for sophisticated PDF processing.
Ready to see what else you can do? Check out the tutorial page here: Edit PDFs
Frequently Asked Questions
What is the ObjectModel property used for in PDF manipulation?
The ObjectModel property in IronPDF provides programmatic access to text, images, and path objects within PDF documents. It allows developers to read, modify, translate, scale, and remove elements directly from the PDF DOM, similar to working with HTML DOM elements.
How do I access PDF DOM objects in C#?
To access PDF DOM objects using IronPDF, first import your target PDF document, then access its Pages property. From there, select any page and use the ObjectModel property. For example: var objs = IronPdf.ChromePdfRenderer.RenderUrlAsPdf("https://example.com").Pages.First().ObjectModel;
What types of objects can I access through the PDF DOM?
IronPDF's ObjectModel contains three main object types: ImageObject (with properties like Height, Width, and ExportBytesAsJpg), PathObject (with FillColor, StrokeColor, and Points), and TextObject (with Color and Contents properties). Each provides methods tailored to their specific content type.
Can I modify text content within a PDF document programmatically?
Yes, IronPDF allows you to modify text content through the TextObject's Contents property. You can access text objects via the ObjectModel, update their content, and save the modified PDF document with just a few lines of code.
How can I export images from PDF documents?
IronPDF's ImageObject provides the ExportBytesAsJpg method, which allows you to export images as JPG byte arrays. Access the image through the ObjectModel property and use this method to extract image data programmatically.
What information is available about each DOM object's position?
Each object in IronPDF's ObjectModel contains information about its page index, bounding box coordinates, scale, and translation. This positioning data can be both read and modified to reposition or transform elements within the PDF.


Still Scrolling?
Want proof fast? PM > Install-Package IronPdf
run a sample watch your HTML become a PDF.










