
PythonでPDFから請求書データを抽出する方法
この記事では、IronPDFライブラリを使用してPythonで請求書のPDFファイルからテキストデータを抽出する方法について説明します。
PythonでPDFから請求書データを抽出する方法
- Pythonライブラリをインストールして、PDF請求書からデータを抽出します。
PdfDocument.FromFileメソッドを利用してPDFファイルを開いてください。ExtractAllTextメソッドを使用して、請求書からすべてのデータを抽出してください。printメソッドを使って、請求書から抽出したすべてのデータを印刷してください。- 請求書データから特定のデータを抽出します。
1. IronPDF
IronPDF for Pythonは、PythonアプリケーションとPDFドキュメントの間のブリッジとして機能するPythonを使用した強力なライブラリです。 この多用途なツールは、開発者がPythonプロジェクト内でPDFファイルを容易に作成、操作、やり取りできる手段を提供します。 以下は、IronPDFを貴重な資産にしている際立った機能のいくつかです:
- PDFの生成:IronPDFは、PDFファイルをゼロから動的に生成することを可能にし、開発者がプログラム的にカスタムコンテンツ、スタイル、レイアウトを持つPDFを作成することを可能にします。
- HTMLからPDFへの変換: それは、レイアウトやスタイルを保持しながら、特にレポートや文書を生成するために、ウェブページを含むHTMLコンテンツを高品質なPDFに変換できる。
- PDF編集:開発者は、テキスト、画像、インタラクティブ要素の追加、変更、削除によって既存のPDFを簡単に編集することができ、文書操作の強力なツールです。
- PDFの結合と分割: IronPDFは、複数のPDFドキュメントを1つのファイルに結合する または PDFを複数のファイルに分割することができ、大規模なPDFセットの管理において柔軟性を提供します。
- PDFフォーム: それは、インタラクティブPDFフォームの作成と記入をサポートしており、ユーザー入力とデータ収集を必要とするアプリケーションに最適です。
- デジタル署名: PDFドキュメントにデジタル署名を追加でき、法的およびセキュリティ目的でのファイルの完全性と信頼性を保証します。
- PDFデータ抽出: IronPDFは、PDF内の情報を保護するための抽出機能を提供します。
2. 環境のセットアップ
PythonでのIronPDF環境のセットアップは、ライブラリを効果的に使用するためのいくつかのステップを含みます。 ステップバイステップガイドは以下の通りです:
- PyCharmで新しいPythonプロジェクトを作成し、仮想環境を作成するか、既存のインタープリターを使用します。
- コマンドライン端末を使用して、以下のコマンドを実行してIronPDFをインストールします。
pip install ironpdf
 コマンドラインからのIronPDFのインストール
コマンドラインからのIronPDFのインストール
3. IronPDFを使用して請求書からデータを抽出する
このセクションでは、PythonライブラリのIronPDFを使用して請求書形式と出力形式からデータを抽出する方法を確認します。 以下のコードは、請求書からすべてのデータを抽出し、コンソールに出力します。
請求書例
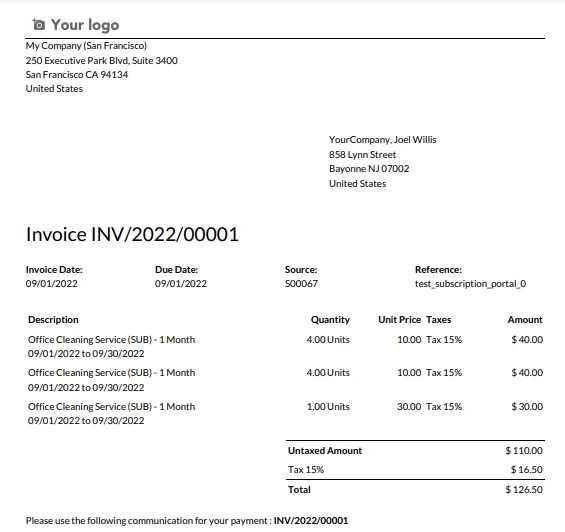 サンプル請求書
サンプル請求書
from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import PdfDocument
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)上記のコードは、PdfDocument.FromFile メソッドを使って"INV_2022_00001.pdf"という特定のPDFファイルをロードします。 その後、ロードしたPDF文書からすべてのテキストコンテンツを抽出し、変数 all_text に格納します。 最後に、抽出したテキストをprint 関数を使用してコンソールに出力します。 本質的に、このコードはPDFファイルから構造化および非構造化テキストデータを抽出するプロセスを自動化し、Python環境でのさらなる処理または分析が可能になります。
3.1. 出力
 コンソールに出力された請求書のテキスト
コンソールに出力された請求書のテキスト
4. 請求書から特定のデータを抽出する
IronPDFを使用して請求書データを抽出するのは非常に簡単なプロセスです。 請求書番号や金額などのデータをPDFの請求書データから抽出することは難しいプロセスかもしれませんが、IronPDFとPythonのオープンソースライブラリ re を組み合わせて使用することで、実現可能です。 以下のコードは、PDF請求書から特定のデータを抽出し、コンソールに出力します。
from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)from ironpdf import PdfDocument
import re
# Define regex patterns to find invoice number and amount
invoice_number_pattern = r"Invoice\s+(INV/\d{4}/\d{5})"
amount_pattern = r"Total\s+\$\s*([\d,.]+(?:\.\d{2})?)"
# Load the PDF using the PdfDocument.FromFile method
pdf = PdfDocument.FromFile("INV_2022_00001.pdf")
# Extract all text from the PDF
all_text = pdf.ExtractAllText()
# Search for the invoice number and amount in text
invoice_number_match = re.search(invoice_number_pattern, all_text)
amount_match = re.search(amount_pattern, all_text)
# Extract the matching groups if matches are found
invoice_number = invoice_number_match.group(1) if invoice_number_match else "Not found"
amount = amount_match.group(1) if amount_match else "Not found"
# Print the extracted data
print('Invoice Number: ' + invoice_number + '\nAmount: $' + amount)このコードスニペットは、PythonとIronPDFライブラリを使用して、PDFドキュメントからデータを抽出します。 最初に必要なライブラリをインポートし、PDFのテキストコンテンツ内で請求書番号と総金額を識別するための正規表現パターンを定義します。 その後、ターゲットPDFをロードし、そのすべてのテキストを抽出して、定義されたパターンの一致を検索し始めます。
一致が見つかれば、請求書番号と金額の対応する値が格納されます; 見つからなければ"Not found"が割り当てられます。 最後に、スクリプトは抽出された請求書番号と金額をコンソールに出力し、様々なデータ処理や会計アプリケーションで一般的に見られるPDFドキュメントから特定のデータを自動的に抽出するための簡潔な方法を提供します。
4.1. 出力
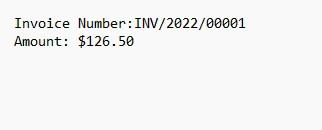 出力テキスト
出力テキスト
5. 結論
今日のビジネスの急速なペースの中で、PythonはPDF請求書からの重要データ抽出を自動化することで財務業務を効率化しようとする組織の強力な味方として立っています。 Pythonの機能とIronPDFライブラリを活用することで、企業は手作業でのデータ入力を大幅に削減し、エラーを軽減し、時間を節約し、請求書管理の会計プロセス全体の生産性を向上させることができます。 PDF生成、HTMLからPDFへの変換、PDFの編集、結合、分割、フォーム処理、デジタル署名、正確なデータ抽出など、多才な機能を備えたIronPDFは、これらの作業の強力なツールとして台頭しています。
シンプルなセットアップ手順を従うことで、Python開発者はすばやくIronPDFをプロジェクトに統合でき、請求書の処理のワークフローを革命的に進化させ、請求書からのデータ抽出をシームレスかつ効率的なプロセスにします。 IronPDFを使用したデータ抽出のコード例は、詳細なコードサンプルから見つけることができます。 IronPDF for Pythonを使用したデータ抽出に関する完全なチュートリアルは、以下のPythonチュートリアルで利用可能であり、C#を使用した請求書抽出に関してはIronOCRチュートリアルを参照してください。
よくある質問
Pythonを使用してPDF請求書からテキストを抽出するにはどうすればよいですか?
IronPDFのPdfDocument.FromFileメソッドを使用してPDFを読み込み、ExtractAllTextメソッドですべてのテキストコンテンツをドキュメントから取得できます。
Python用のIronPDFをどのようにインストールしますか?
Pythonパッケージマネージャpipを使用して、pip install ironpdfコマンドでIronPDFをインストールします。
Pythonを使用してPDFから請求書番号などの特定のデータを抽出できますか?
はい、Pythonのreライブラリと組み合わせたIronPDFを使用して、請求書番号や金額などの特定のデータを抽出するための正規表現パターンを定義できます。
Python用のIronPDFの特徴は何ですか?
IronPDFは、PDF生成、HTMLからPDFへの変換、PDF編集、結合、分割、フォーム処理、デジタル署名、データ抽出などの機能を提供します。
IronPDFはPythonでHTMLをPDFに変換できますか?
はい、IronPDFはウェブページを含むHTMLコンテンツを高品質なPDFに変換し、元のHTMLのレイアウトとスタイリングを保持します。
IronPDFは請求書データの抽出における生産性をどのように向上させますか?
IronPDFはPDF請求書からのデータ抽出を自動化し、手入力とエラーを削減することで、財務操作における時間を節約し、生産性を高めます。
PythonでIronPDFを使用してPDFドキュメントを編集することは可能ですか?
はい、IronPDFは、テキスト、画像、インタラクティブ要素を追加、変更、削除することによって、開発者が既存のPDFを編集できるようにします。
PythonでIronPDFを使用してPDFドキュメントを結合または分割することはできますか?
はい、IronPDFは複数のPDFドキュメントを一つのファイルに結合したり、PDFを複数のファイルに分割する機能を提供します。
IronPDFはPythonでデジタル署名をPDFに追加できるのですか?
はい、IronPDFによりPDFドキュメントにデジタル署名を追加でき、整合性と信頼性を保証します。
IronPDFがPython開発者にとって堅牢なツールと見なされる理由は何ですか?
IronPDFは、開発者にとって不可欠なPDF生成、変換、編集、データ抽出などのさまざまなPDF操作をサポートする包括的な機能を提供する点で、堅牢と見なされています。
















