
How to Read PDF File in Java
Reading a PDF document in Java can be an integral part of any project, ranging from business applications to data analytics. With the IronPDF library, it has become easier than ever before to integrate PDF processing capabilities into your Java projects.
How to Read PDF Files in Java
- Install IronPDF to Read PDF Files in Java
- Load an existing PDF document using the
fromFilemethod - Render a new PDF from an HTML string, file, or web URL
- Utilize the
extractAllTextMethod to Read Text from the Opened PDF - Print Extracted PDF Text to Console or Save in Java
IronPDF: Import Java PDF Library
IronPDF Java PDF Library Overview is the perfect solution for software developers who need to produce high-quality, capture-ready PDFs quickly from HTML. The library also provides powerful document manipulation tools that enable dynamic control over page layout and formatting in IronPDF, content, and formatting.
Let's see how to read a PDF file stored at a path in a Java program using the IronPDF library.
Read PDFs Using IronPDF
The first step is to install IronPDF using Maven; more details can be found in the IronPDF Installation Guide.
Install IronPDF in Maven
Here are the steps to install IronPDF in a Maven project:
- Open your Maven project in your preferred IDE.
-
In the
pom.xmlfile, add the IronPDF library dependency in thedependenciessection.<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>Your_IronPDF_Version_Here</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>Your_IronPDF_Version_Here</version> </dependency>XML - Save the
pom.xmlfile and let Maven download and install the IronPDF library.
Once the installation is complete, you should be able to import and use IronPDF's classes in your project.
Java Code to Read PDF Document
Here is the code which you can use to read a file with or without tabular boundaries using the IronPDF library.
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
/**
* This class demonstrates how to read text from a PDF document using the IronPDF library.
*/
public class PdfReader {
public static void main(String[] args) {
try {
// Load the PDF document from the specified file path
PdfDocument pdf = PdfDocument.fromFile(Paths.get("C:\\sample.pdf"));
// Extract all text content from the loaded PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
// Handle exceptions that may occur during file loading or reading.
e.printStackTrace();
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
/**
* This class demonstrates how to read text from a PDF document using the IronPDF library.
*/
public class PdfReader {
public static void main(String[] args) {
try {
// Load the PDF document from the specified file path
PdfDocument pdf = PdfDocument.fromFile(Paths.get("C:\\sample.pdf"));
// Extract all text content from the loaded PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println(text);
} catch (IOException e) {
// Handle exceptions that may occur during file loading or reading.
e.printStackTrace();
}
}
}In this program, the PdfDocument class in IronPDF is used to read the contents of a PDF file. The main method creates a PdfDocument object by loading a PDF file from the specified file path "C:\sample.pdf" using the fromFile method. The extractAllText method is then called on this object to extract and return all text in the PDF as a String. The extracted text is printed to the console. The program includes error handling using try-catch blocks to manage potential IOException.
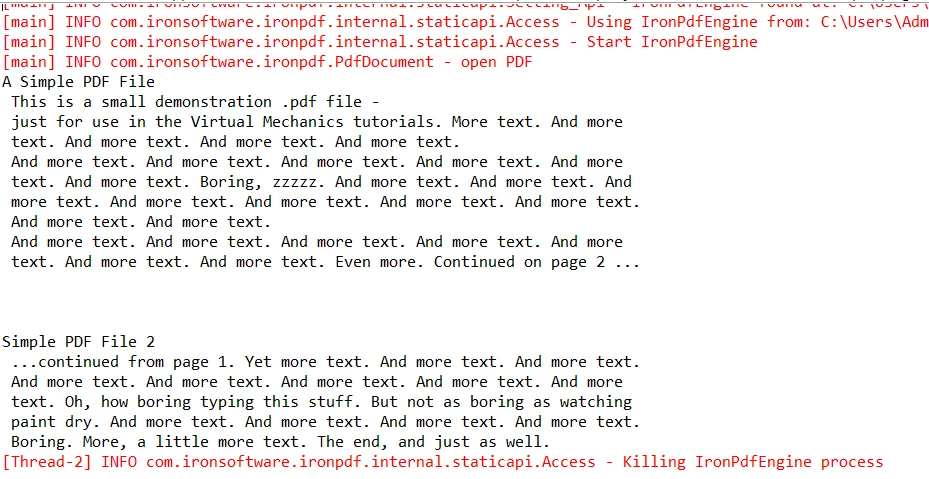 Program Output
Program Output
Conclusion
IronPDF is a great solution for reading PDF files within the same path or multiple different paths in Java, as it offers high performance and many features that make developing PDFs easy. Its syntax is straightforward and user-friendly. Its API allows developers to quickly craft the code that they need for their projects.
Explore IronPDF Licensing Options plans start from just $999, making it accessible for those on a budget. Overall, IronPDF provides an excellent option for any Java developer looking to work with PDFs in their applications.
Frequently Asked Questions
How do I read PDF files in Java?
You can read PDF files in Java by using the IronPDF library. First, install IronPDF via Maven by adding the necessary dependency to your `pom.xml` file. Then, use the `PdfDocument.fromFile` method to load the PDF and `extractAllText` to read its contents.
What is the process for installing IronPDF in a Java project?
To install IronPDF in a Java project, open your Maven project and add the IronPDF dependency in the `pom.xml` file under the `dependencies` section. Save the file, and Maven will handle the download and installation.
Can I render a PDF from HTML in Java?
Yes, with IronPDF, you can render a PDF from HTML in Java. You can convert HTML strings, files, or web URLs into PDFs using IronPDF's rendering capabilities.
How can I extract text from a PDF in Java using IronPDF?
To extract text from a PDF in Java using IronPDF, load the PDF with `PdfDocument.fromFile`, and then use the `extractAllText` method to get the text content from the document.
What should I do if I encounter an IOException when reading a PDF in Java?
If you encounter an `IOException` when using IronPDF to read a PDF in Java, ensure that you have implemented proper error handling using try-catch blocks to manage such exceptions during file loading or reading.
What are the advantages of using IronPDF for PDF processing in Java?
IronPDF offers high performance, a user-friendly syntax, and powerful document manipulation tools. It is ideal for Java applications needing robust PDF processing capabilities, such as text extraction and HTML-to-PDF rendering.
How can I handle different PDF file paths when using IronPDF in Java?
IronPDF allows you to handle PDF files stored at various paths. Use the `PdfDocument.fromFile` method with the specific file path to load and process the PDFs as needed.
Is IronPDF a suitable option for business applications that require PDF capabilities?
Yes, IronPDF is suitable for business applications requiring PDF capabilities. It provides robust processing features, making it an excellent choice for applications ranging from business solutions to data analytics.

















