
iText7 Czytaj PDF w C# Alternatywy (VS IronPDF)
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
IronPDF vs iTextSharp / iText7
Kompleksowe porównanie bibliotek PDF .NET — funkcja po funkcji z uzasadnieniem w oparciu o dowody
| Funkcja | iTextSharp / iText7 | IronPDF ✦ |
|---|---|---|
| PDF Creation & Conversion | ||
| HTML/CSS do PDF |
$ Paid Add-on
HTML→PDF przez dodatek
pdfHTML (oddzielny pakiet; model AGPL/komercyjny). |
✓ Yes
Silnik oparty na Chromium z wbudowanym renderowaniem doskonałym pikselowo CSS3, Flexbox i Grid.
|
| Wykonanie JavaScript |
? Unknown
pdfHTML opisuje konwersję HTML/CSS→PDF, ale wsparcie dla wykonania JS nie jest uwzględnione w dokumentacji.
|
✓ Yes
Pełne wykonywanie JS podczas renderowania — interaktywne wykresy, SPA i interaktywna treść.
|
| Programistyczne generowanie |
✓ Yes
Pozycjonowana jako programowalny SDK PDF dla .NET — tworzenie, edytowanie i poprawianie.
|
✓ Yes
Generowanie z szablonów HTML, ciągów, widoków ASPX lub obrazów. Chromium obsługuje układ.
|
| URL do pliku PDF |
$ Paid Add-on
Możliwe za pomocą dodatku pdfHTML z pobieraniem URL, ale nie jest to funkcja podstawowa.
|
✓ Yes
RenderUrlAsPdf() przechwytuje każdy aktywny URL z pełnym renderowaniem CSS/JS. |
| DOCX do PDF |
✕ No
Brak natywnej konwersji Word — iText to natywny SDK PDF.
|
✓ Yes
DocxToPdfRenderer konwertuje dokumenty Word z zachowaniem struktury i formatowania. |
| Reading & Extraction | ||
| Wyodrębnianie tekstu |
✓ Yes
PdfTextExtractor.GetTextFromPage() z wieloma strategiami ekstrakcji. |
✓ Yes
Wyodrębnia tekst z uwzględnieniem układu. Łączy się z IronOCR dla zeskanowanych dokumentów.
|
| Renderowanie stron do obrazów |
? Unknown
Przepływy pracy OCR wspominają o renderowaniu, ale brak jest "modułu renderującego PDF→obraz" jako źródła pierwotnego
udokumentowanego w cytowanej dokumentacji iText.
|
✓ Built-in
Natywna rasteryzacja do PNG, JPEG, BMP z konfigurowalnym DPI.
|
| Wbudowany OCR |
$ Paid Add-on
Dostępny dodatek pdfOCR; zalecenia instalacyjne obejmują platformowe/specyficzne zależności (np.
wymagania dotyczące środowiska Linux/macOS).
|
✓ Via IronOCR
Natywna integracja z IronOCR dla 127+ języków OCR na zeskanowanych PDF.
|
| Editing & Manipulation | ||
| Merging & Splitting |
✓ Yes
PdfMerger klasa w API .NET; oficjalne przykłady omawiają scalanie przez PdfMerger.
|
✓ Yes
Jednoliniowe scalanie, dzielenie, dołączanie, przedkładanie i zmiana kolejności stron przy użyciu intuicyjnego API.
|
| Headers, Footers & Page Numbers |
✓ Yes
Lista PDF Association potwierdza możliwość dodawania "numerów stron" i podobnych funkcji do
istniejących PDF-ów.
|
✓ Yes
Nagłówki/stopki oparte na HTML z automatycznymi numerami stron, datami i niestandardową treścią.
|
| Znaki wodne |
✓ Yes
Lista PDF Association wyraźnie uwzględnia "znaki wodne … do istniejących dokumentów PDF".
|
✓ Yes
ApplyWatermark() akceptuje HTML/CSS — pełna kontrola nad przezroczystością, rotacją,
położeniem. |
| Stamp Text & Images |
✓ Yes
Programistyczne umieszczanie treści dostępne za pomocą płótna i API układu iText.
|
✓ Yes
TextStamper & ImageStamper z czcionkami Google, pozycjonowaniem,
kontrolą per-strona. |
| Redagowanie treści |
✓ Yes
iText zapewnia wsparcie dla adnotacji redagowania za pomocą modułu czyszczenia.
|
✓ Yes
RedactTextOnAllPages() usuwa wrażliwy tekst na stałe w jednym kroku.
|
| Security & Compliance | ||
| Encryption & Passwords |
✓ Yes
Pełna kontrola nad szyfrowaniem i uprawnieniami za pośrednictwem API zabezpieczeń iText.
|
✓ Yes
Szyfrowanie AES, hasła właściciela/użytkownika, szczegółowe uprawnienia (drukowanie, kopiowanie, adnotacje).
|
| Podpisy cyfrowe |
✓ Yes
Dedykowana dokumentacja podpisu cyfrowego i API podpisu (
PdfSigner). |
✓ Yes
PdfSignature ze wsparciem dla certyfikatów X509/PFX. |
| PDF/A & PDF/UA Compliance |
✓ Yes
Dokumentacja obejmuje tworzenie PDF/A i wyjaśnia ograniczenia (konwersja z istniejących nie jest
automatyczna).
|
✓ Yes
Natywna archiwizacja PDF/A i zgodność z dostępnością PDF/UA do użytku w przedsiębiorstwie.
|
| Platform & Deployment | ||
| Obsługa wielu platform |
✓ Yes
.NET Standard 2.0 / .NET Framework 4.6.1 — działa na .NET 6+ we wszystkich systemach operacyjnych.
|
✓ Yes
Windows, Linux, macOS, x64, x86, ARM. .NET 6–10, Core, Standard 2.0+, Framework 4.6.2+.
|
| Serwer / Docker / Chmura |
~ Complex
Podstawowa instalacja wymaga wielu pakietów (iText + adapter Bouncy Castle); dodatki (pdfHTML/pdfOCR)
dodają dalsze kroki zależności/zgodności.
|
✓ Yes
Docker, Azure, AWS, IIS. Oficjalne obrazy Docker i przewodniki wdrożeniowe.
|
| Łatwość instalacji |
~ Complex
Podstawowa instalacja wymaga wielu pakietów (adapter Bouncy Castle); HTML/OCR wymagają dodatkowych
dodatków, a czasami natywnych zależności.
|
✓ Simple
Pojedyncza komenda NuGet
Install-Package IronPdf. Gotowe w kilka minut. |
| Licensing & Support | ||
| Model licencjonowania |
~ Complex
Podwójna licencja: AGPLv3 (obowiązki ujawnienia źródła dla użycia sieci) lub komercyjna. AGPL może
być ograniczeniem dla aplikacji proprietarnych.
|
✓ Commercial
Licencje wieczyste. 30-dniowy w pełni funkcjonalny bezpłatny okres próbny, bez znaków wodnych.
|
| Commercial Support & SLA |
✓ Yes
Strona iText zawiera licencjonowanie komercyjne + umowy wsparcia jako część modelu licencjonowania.
|
✓ 24/5 Support
Dedykowane wsparcie inżynieryjne z gwarantowanym SLA — e-mail, czat na żywo, telefon.
|
| Dokumentacja |
✓ Yes
Dostępne przewodniki instalacji, artykuły bazy wiedzy i dokumentacja API (rdzeń + dodatki).
|
✓ Extensive
Pełna dokumentacja API, 100+ poradników, tutoriali, przykłady kodu, rozwiązywanie problemów, filmy.
|
Dane pochodzą z oficjalnej dokumentacji iText, listy PDF Association i referencji pakietu NuGet.
iText7 jest potężny, ale niesie skomplikowanie licencjonowania AGPL i nadmiarowe konfiguracje pakietów.
IronPDF dostarcza pełne pokrycie z prostszą konfiguracją — spróbuj bezpłatnie przez 30
dni.
PDF to przenośny format dokumentu stworzony przez Adobe Acrobat Reader, szeroko stosowany do udostępniania informacji cyfrowo przez Internet. Zachowuje formatowanie danych i oferuje funkcje takie jak ustawianie zabezpieczeń i ochrona hasłem. Jako programista C#, możesz napotkać sytuacje, w których integracja funkcjonalności PDF z aplikacją jest konieczna. Tworzenie jej od podstaw może być czasochłonne i żmudne. Z tego powodu, biorąc pod uwagę wydajność, efektywność i skuteczność aplikacji, kompromis między tworzeniem nowej usługi od zera a używaniem gotowej biblioteki jest istotny.
Istnieje kilka bibliotek PDF dostępnych dla C#. W tym artykule przyjrzymy się dwóm z najbardziej popularnych bibliotek PDF do czytania dokumentów PDF w C#.
Oprogramowanie iText
iText 7, wcześniej znany jako iText 7 Core, jest biblioteką PDF do programowania dokumentów PDF w .NET C# i Java. Jest dostępny jako licencja open source (AGPL) i może być licencjonowany dla aplikacji komercyjnych.
iText Core to wysokopoziomowe API, które zapewnia łatwe metody generowania i edytowania PDF-ów na wszystkie możliwe sposoby. Z iText 7 Core można dzielić, scalanie, dodawać adnotacje, wypełniać formularze, podpisywać cyfrowo i robić dużo więcej na plikach PDF. iText 7 zapewnia konwerter HTML do PDF.
IronPDF
Dowiedz się więcej o IronPDF jest to API .NET i .NET Framework C# i Java używane do generowania dokumentów PDF z HTML, CSS i JavaScript, zarówno z URL, plików HTML, jak i ciągów HTML. IronPDF pozwala manipulować istniejącymi plikami PDF takimi jak dzielenie, scalanie, dodawanie adnotacji, podpisy cyfrowe i wiele więcej.
IronPDF jest wzbogacone o 50+ funkcji do tworzenia, czytania i edytowania plików PDF. Priorytetuje prędkość, łatwość użycia i dokładność, kiedy trzeba dostarczyć profesjonalne pliki PDF o wysokiej jakości z użyciem Adobe Acrobat Reader. API jest dobrze udokumentowane, a wiele przykładowego kodu źródłowego można znaleźć na stronie przykładów kodu.
Utwórz aplikację konsolową
Będziemy używać IDE Visual Studio 2022 do tworzenia aplikacji na początek. Visual Studio to oficjalne IDE do rozwoju w C#, które musisz mieć zainstalowane. Możesz je pobrać z strony Microsoft Visual Studio jeśli jeszcze jej nie zainstalowałeś.
Następujące kroki utworzą nowy projekt o nazwie "DemoApp".
-
Otwórz Visual Studio i kliknij "Utwórz nowy projekt".
-
Wybierz "Aplikacja konsolowa" i kliknij "Dalej".
-
Ustaw nazwę projektu.
-
Wybierz wersję .NET. Wybierz stabilną wersję .NET 6.0.
Zainstaluj bibliotekę IronPDF
Gdy projekt zostanie utworzony, konieczne jest zainstalowanie biblioteki IronPDF w projekcie, aby móc ją używać. Postępuj zgodnie z tymi krokami, aby ją zainstalować.
-
Otwórz Menedżer pakietów NuGet, albo z Eksploratora rozwiązań, albo z Narzędzi.
-
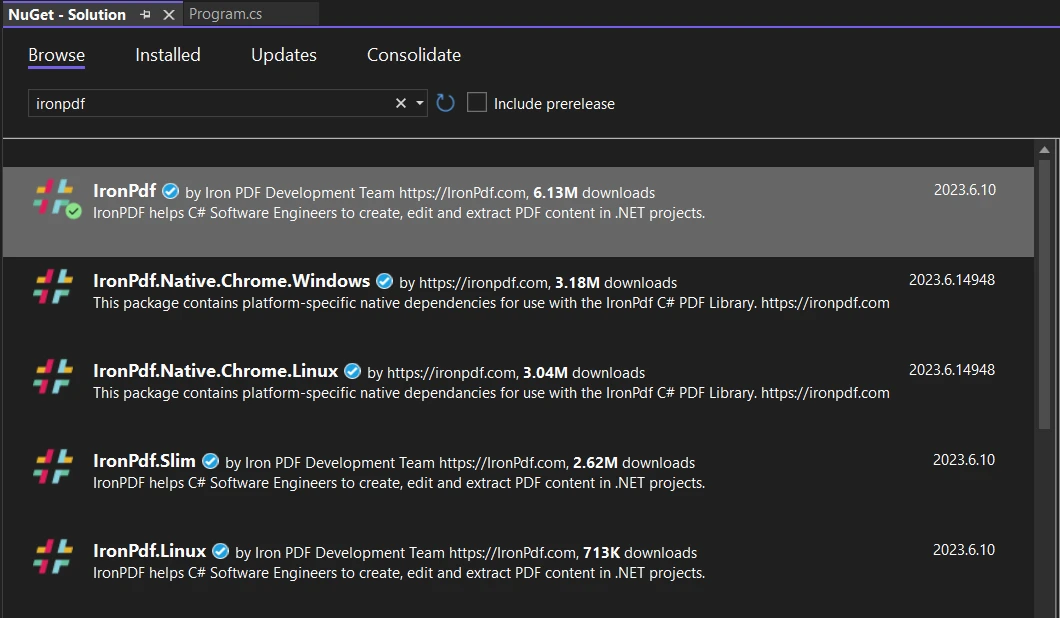
Wyszukaj bibliotekę IronPDF i wybierz ją dla bieżącego projektu. Kliknij Zainstaluj.
Dodaj następującą przestrzeń nazw na początku pliku Program.cs:
using IronPdf;using IronPdf;Imports IronPdfZainstaluj bibliotekę iText 7
Gdy projekt zostanie utworzony, konieczne jest zainstalowanie biblioteki iText 7 w projekcie, aby móc jej używać. Postępuj zgodnie z krokami, aby ją zainstalować.
-
Otwórz Menedżer pakietów NuGet, albo z Eksploratora rozwiązań, albo z Narzędzi.
-
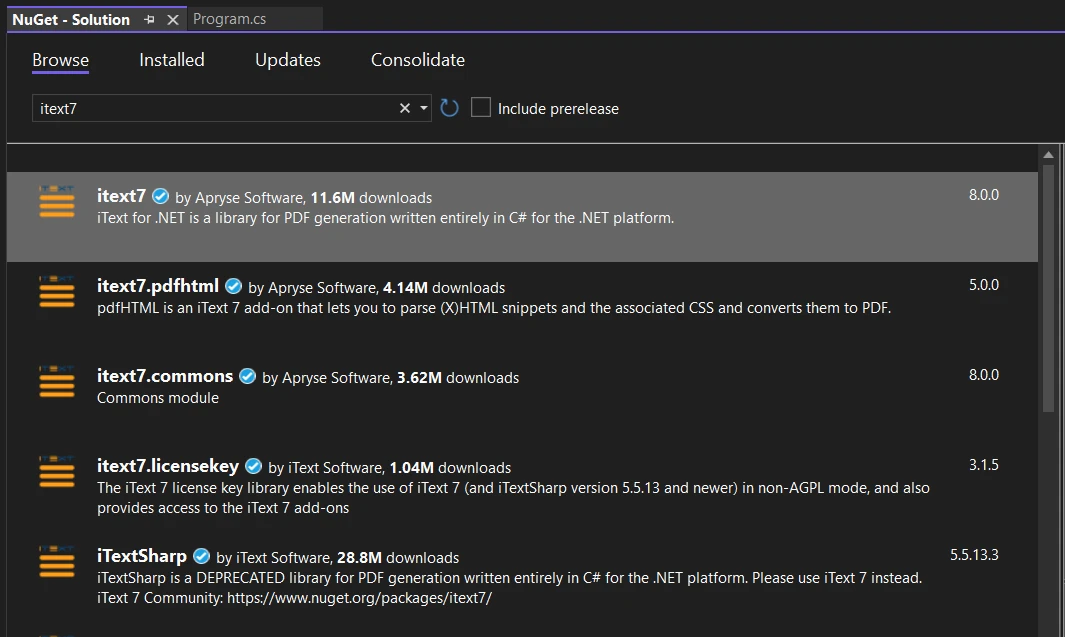
Wyszukaj bibliotekę iText 7 i wybierz ją dla bieżącego projektu. Kliknij zainstaluj.
Dodaj następujące przestrzenie nazw na początku pliku Program.cs:
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;Imports iText.Kernel.Pdf.Canvas.Parser.Listener
Imports iText.Kernel.Pdf.Canvas.Parser
Imports iText.Kernel.PdfOtwieranie plików PDF
Będziemy używać następującego pliku PDF, aby wydobyć z niego tekst. Jest to dokument PDF o dwóch stronach.
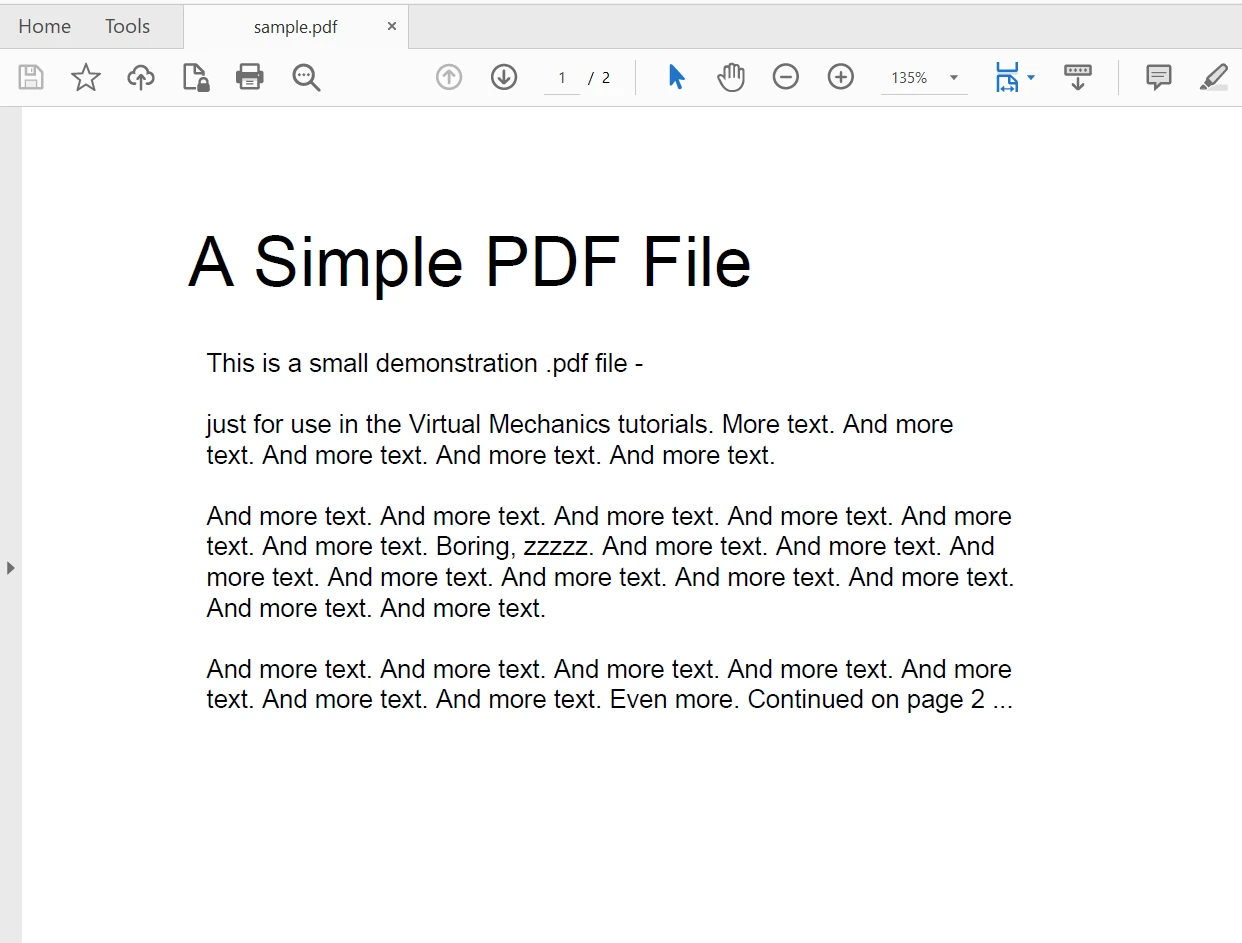
Użycie biblioteki iText
Otwieranie pliku PDF za pomocą biblioteki iText to proces dwuetapowy. Najpierw tworzymy obiekt PdfReader i przekazujemy lokalizację pliku jako parametr. Następnie używamy klasy PdfDocument, aby utworzyć nowy dokument PDF. Kod wygląda następująco:
// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);' Initialize a reader instance by specifying the path of the PDF file
Dim pdfReader As New PdfReader("sample.pdf")
' Initialize a document instance using the PdfReader
Dim pdfDoc As New PdfDocument(pdfReader)Korzystanie z IronPDF
Otwieranie plików PDF za pomocą IronPDF jest proste. Użyj metody FromFile klasy PdfDocument, aby otwierać pliki PDF z dowolnej lokalizacji pliku. Poniższy jednoliniowy kod otwiera plik PDF do odczytu danych:
// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");' Open a PDF file using IronPDF and create a PdfDocument instance
Dim pdf = PdfDocument.FromFile("sample.pdf")Czytaj dane z plików PDF
Użycie biblioteki iText7
Czytanie danych PDF w bibliotece iText 7 nie jest takie proste. Musimy ręcznie przeglądać każdą stronę dokumentu PDF, aby wydobyć tekst z każdej strony. Poniższy kod źródłowy pomaga w wyodrębnieniu tekstu z dokumentu PDF strona po stronie:
// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();' Iterate through each page and extract text
Dim page As Integer = 1
Do While page <= pdfDoc.GetNumberOfPages()
' Define the text extraction strategy
Dim strategy As ITextExtractionStrategy = New SimpleTextExtractionStrategy()
' Extract text from the current page using the strategy
Dim pageContent As String = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy)
' Output the extracted text to the console
Console.WriteLine(pageContent)
page += 1
Loop
' Close document and reader to release resources
pdfDoc.Close()
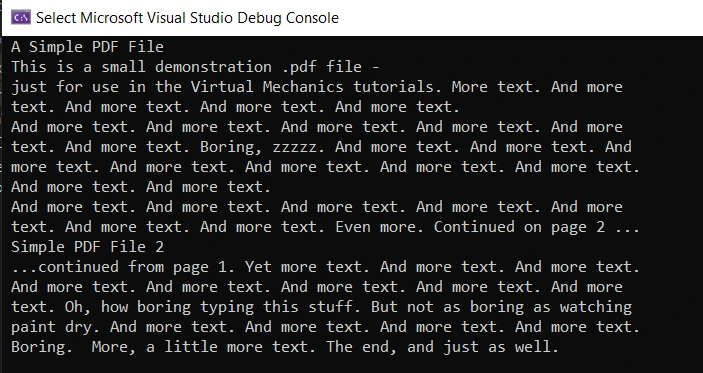
pdfReader.Close()W powyższym kodzie dzieje się wiele rzeczy. Najpierw deklarujemy Strategię Wydobywania Tekstu, a następnie używamy metody GetTextFromPage klasy PdfExtractor do czytania tekstu. Ta metoda akceptuje dwa parametry: pierwszy to strona dokumentu PDF, a drugi to strategia. Aby uzyskać stronę dokumentu PDF, użyj instancji PdfDocument, aby wywołać metodę GetPage i przekaż numer strony jako parametr. Wynik jest zwracany jako ciąg, który następnie jest wyświetlany na ekranie wyjściowym konsoli. Na koniec zamykane są obiekty PDFReader i PdfDocument. Również sprawdź poniższy przykład kodu dotyczący wydobywania tekstu z PDF przy użyciu iText7.
Wynik
Korzystanie z IronPDF
Podobnie jak otwieranie pliku PDF był to jednoliniowy kod, podobnie czytanie tekstu z pliku PDF to również jednoliniowy proces. Klasa PDFDocument udostępnia metodę ExtractAllText, aby czytać całą treść z PDF. Console.WriteLine jest używany do wydrukowania tekstu na ekranie. Kod wygląda następująco:
// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);' Extract all text from the PDF document
Dim text As String = pdf.ExtractAllText()
' Display the extracted text
Console.WriteLine(text)Wynik
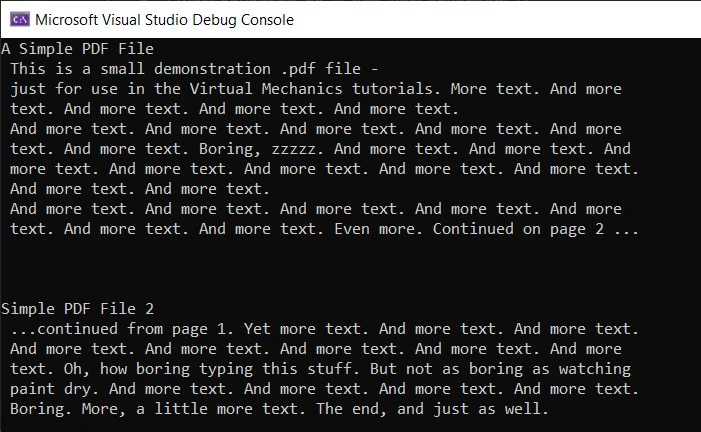
Wynik jest dokładny i bez żadnych błędów. Aby jednak skorzystać z metody ExtractAllText, potrzebujesz licencji, ponieważ działa ona tylko w trybie produkcyjnym. Możesz uzyskać swój klucz licencji próbnej na 30 dni z strony licencji próbnej IronPDF.
Porównanie
W porównaniu obie biblioteki dają 100% dokładne wyniki podczas wydobywania tekstu z dokumentu PDF. Są identyczne pod względem dokładności. Jednak IronPDF jest bardziej efektywny pod względem wydajności i czytelności kodu.
IronPDF wymaga jedynie dwóch linii kodu, aby osiągnąć to samo co iText. Zapewnia wbudowane metody ekstrakcji tekstu bez potrzeby implementacji dodatkowej logiki. Kod iText jest nieco skomplikowany, a trzeba zamknąć dwa utworzone przypadki podczas otwierania dokumentu PDF. Natomiast IronPDF automatycznie czyści pamięć po wykonaniu zadania.
Podsumowanie
W tym artykule spojrzeliśmy, jak czytać dokumenty PDF przy użyciu biblioteki iText w C#, a następnie porównaliśmy ją z IronPDF. Obie biblioteki dają dokładne wyniki i oferują wiele metod manipulacji PDF-ami do pracy. Możesz tworzyć, edytować i czytać dane z plików PDF przy użyciu obu z tych bibliotek.
iText jest open source i można go używać za darmo, ale z ograniczeniami. Można go licencjonować do użytku komercyjnego. IronPDF jest również darmowy do użycia i można go licencjonować do działalności komercyjnej z dostępną darmową 30-dniową wersją próbną.
Często Zadawane Pytania
Czym jest IronPDF i jak wypada w porownaniu z iText 7?
IronPDF to biblioteka .NET zaprojektowana do generowania i manipulowania dokumentami PDF z HTML, CSS i JavaScript. W porownaniu do iText 7, IronPDF kladzie nacisk na szybkosc, latwosc uzycia i dokladnosc, wymagajac mniej kodu do realizacji zadan zwiazanych z PDF.
Jak mogę przekonwertować HTML na PDF w języku C#?
Możesz użyć metody RenderHtmlAsPdf biblioteki IronPDF do konwersji ciągów HTML na pliki PDF. Dodatkowo możesz konwertować pliki HTML na pliki PDF za pomocą metody RenderHtmlFileAsPdf.
Jakie sa kroki instalacji IronPDF w projekcie C#?
Aby zainstalowac IronPDF w projekcie C#, otworz Menedzera Pakietow NuGet w Visual Studio, wyszukaj IronPDF, wybierz go dla swojego projektu, a nastepnie kliknij Instaluj. Zalacz using IronPdf; na poczatku pliku C#.
Jak wyodrebnic tekst z PDF przy uzyciu IronPDF?
Aby wyodrebnic tekst z PDF przy uzyciu IronPDF, uzyj metody FromFile klasy PdfDocument do zaladowania PDF, a nastepnie metody ExtractAllText do pobrania tekstu.
Jakie sa wskazowki dotyczace rozwiazywania problemow z IronPDF?
Upewnij sie, ze IronPDF jest prawidlowo zainstalowany przez NuGet i ze odpowiednie przestrzenie nazw sa zawarte w pliku C#. Zweryfikuj sciezki do plikow i upewnij sie, ze tresc HTML jest dobrze sformowana, jesli konwertujesz HTML na PDF.
Czy IronPDF obsluguje formularze i adnotacje PDF?
Tak, IronPDF obsluguje takie funkcje jak wypelnianie formularzy i dodawanie adnotacji do PDF, pozwalajac na tworzenie interaktywnych i dynamicznych dokumentow PDF.
Czy korzystanie z IronPDF jest darmowe?
IronPDF oferuje darmowa wersje z ograniczonymi funkcjami oraz 30-dniowy okres probny dla swojej wersji komercyjnej, ktora zapewnia pelna gamme funkcjonalnosci.
Jakie sa ograniczenia korzystania z iText 7 do manipulacji PDF?
Chociaz iText 7 to solidna biblioteka PDF, wymaga dodatkowej logiki do niektorych zadan, takich jak wyodrebnianie tekstu, co moze skutkowac bardziej skomplikowanym i dluzszym kodem w porownaniu do IronPDF.













