Foxit PDF SDK C# 대안 - IronPDF와 비교
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
IronPDF 대 iText / iText
포괄적인 .NET PDF 라이브러리 비교 — 증거 기반 문맥으로 기능별 비교
| 특징 | iText / iText | IronPDF ✦ |
|---|---|---|
| PDF 생성 및 변환 | ||
| HTML/CSS를 PDF로 |
$ Paid Add-on
HTML→PDF는
pdfHTML 애드온을 통해 가능합니다 (별도의 패키지; AGPL/상업 모델). |
✓ Yes
픽셀 단위의 완벽한 CSS3, Flexbox 및 Grid 렌더링이 내장된 Chromium 기반 엔진.
|
| JavaScript 실행 |
? Unknown
pdfHTML은 HTML/CSS→PDF 변환을 설명하지만, JS 실행 지원은 문서에 명시되어 있지 않습니다.
|
✓ Yes
렌더링 중 JS를 완전 실행 — 동적 차트, SPA 및 인터랙티브 콘텐츠.
|
| 프로그래매틱 생성 |
✓ Yes
.NET을 위한 프로그래머블 PDF SDK로서 위치 — 생성, 편집, 향상 가능.
|
✓ Yes
HTML 템플릿, 문자열, ASPX 보기 또는 이미지에서 생성. Chromium이 레이아웃을 처리합니다.
|
| PDF URL |
$ Paid Add-on
URL 가져오기를 통해 pdfHTML 애드온으로 가능하지만, 핵심 기능은 아닙니다.
|
✓ Yes
RenderUrlAsPdf() 완전한 CSS/JS 렌더링으로 실시간 URL을 캡처합니다. |
| DOCX 파일을 PDF로 변환 |
✕ No
네이티브 Word 변환 없음 — iText는 PDF 네이티브 SDK입니다.
|
✓ Yes
DocxToPdfRenderer 구조와 형식을 그대로 유지한 채 Word 문서를 변환합니다. |
| 읽기 및 추출 | ||
| 텍스트 추출 |
✓ Yes
PdfTextExtractor.GetTextFromPage() 여러 추출 전략을 통해. |
✓ Yes
레이아웃 인식이 있는 텍스트를 추출합니다. 스캔된 문서의 경우 IronOCR와 결합됩니다.
|
| 페이지를 이미지로 렌더링 |
? Unknown
OCR 워크플로우는 렌더링을 언급하지만, 주 출처인 "PDF→이미지 렌더러" 모듈이 iText 문서에
증명되지는 않았습니다.
|
✓ Built-in
PNG, JPEG, BMP로 네이티브 래스터화, DPI 설정 가능.
|
| 내장형 OCR |
$ Paid Add-on
pdfOCR 애드온 가능; 설치 노트는 플랫폼별/네이티브 종속성(예:
Linux/macOS 런타임 요구 사항)을 언급합니다.
|
✓ Via IronOCR
IronOCR과의 네이티브 통합, 127+ 언어 OCR을 스캔된 PDF에서 지원.
|
| 편집 및 조작 | ||
| 병합 및 분할 |
✓ Yes
PdfMerger .NET API의 클래스; 공식 예제는 PdfMerger를 통한 병합을 다룹니다.
|
✓ Yes
직관적인 API로 한 줄 병합, 분할, 추가, 선행, 페이지 재정렬
|
| 머리글, 바닥글 및 페이지 번호 |
✓ Yes
PDF Association 목록은 기존 PDF에 '페이지 번호' 및 유사 기능 추가 능력을 확인합니다.
|
✓ Yes
HTML 기반의 머리글/바닥글로 자동 페이지 번호, 날짜 및 사용자 지정 콘텐츠 포함.
|
| 워터마크 |
✓ Yes
PDF Association 목록에 의해 '워터마크 … 기존 PDF 문서로'가 명시적으로 포함되어 있습니다.
|
✓ Yes
ApplyWatermark() HTML/CSS 수용 — 불투명도, 회전,
위치에 대한 완전한 제어. |
| 스탬프에 글자와 이미지를 새길 수 있습니다. |
✓ Yes
iText의 캔버스 및 레이아웃 API를 통한 프로그래밍 방식의 콘텐츠 배치 가능.
|
✓ Yes
TextStamper & google 폰트, 위치 선정,
페이지별 제어가 가능한 ImageStamper. |
| 콘텐츠 수정 |
✓ Yes
iText는 클린업 모듈을 통해 콘텐츠 수정 주석 지원을 제공합니다.
|
✓ Yes
RedactTextOnAllPages() 한 줄로 민감한 텍스트를 영구적으로 제거합니다.
|
| 보안 및 규정 준수 | ||
| 암호화 & 비밀번호 |
✓ Yes
iText의 보안 API를 통한 전체 암호화 및 권한 제어.
|
✓ Yes
AES 암호화, 소유자/사용자 비밀번호, 세부적인 권한(인쇄, 복사, 주석 추가).
|
| 디지털 서명 |
✓ Yes
디지털 서명 문서화 및 서명 API (
PdfSigner) 전용. |
✓ Yes
PdfSignature X509/PFX 인증서 지원. |
| PDF/A 및 PDF/UA 준수 |
✓ Yes
문서화는 PDF/A를 생성하는 방법과 제약 사항에 대해 설명합니다 (기존 파일의 변환은
자동이 아님).
|
✓ Yes
기업 사용을 위한 네이티브 PDF/A 보관 및 PDF/UA 접근성 준수.
|
| 플랫폼 및 배포 | ||
| 크로스 플랫폼 지원 |
✓ Yes
.NET Standard 2.0 / .NET Framework 4.6.1 — 여러 운영 체제에서 .NET 6+ 실행.
|
✓ Yes
Windows, Linux, macOS, x64, x86, ARM. .NET 6–10, Core, Standard 2.0 이상, Framework 4.6.2 이상.
|
| 서버 / Docker / 클라우드 |
~ Complex
핵심 설치는 여러 패키지 (iText + Bouncy Castle 어댑터)가 필요합니다. 애드온
(pdfHTML/pdfOCR)는 추가 종속성/준수 단계를 추가합니다.
|
✓ Yes
Docker, Azure, AWS, IIS. 공식 Docker 이미지 및 배포 가이드.
|
| 설치의 용이성 |
~ Complex
핵심 설치는 여러 패키지 (Bouncy Castle 어댑터)가 필요합니다. HTML/OCR은 추가
애드온과 때로는 네이티브 종속성이 필요합니다.
|
✓ Simple
단일
Install-Package IronPdf NuGet 명령. 몇 분 안에 준비가 완료됩니다. |
| 라이센스 및 지원 | ||
| 라이센스 모델 |
~ Complex
이중 라이센스: AGPLv3 (네트워크 사용을 위한 소스 공개 의무) 또는 상업용. AGPL은
독점 앱에 대해 제약이 될 수 있습니다.
|
✓ Commercial
영구 라이센스. 완전 기능의 30일 무료 체험판, 워터마크 없음.
|
| 상업적 지원 및 SLA |
✓ Yes
iText 사이트는 라이센스 모델의 일부로 상업적 라이센싱 + 지원 계약을 포함합니다.
|
✓ 24/5 Support
전용 엔지니어링 지원과 보장된 SLA — 이메일, 실시간 채팅, 전화.
|
| 문서 |
✓ Yes
설치 가이드, 지식 기반 기사, API 참조가 제공됨 (핵심 + 애드온).
|
✓ Extensive
전체 API 참조, 100개 이상의 사용 방법, 튜토리얼, 코드 예제, 문제 해결, 동영상.
|
공식 iText 문서, PDF 협회 목록 및 NuGet 패키지 참조에서 가져온 데이터.
iText는 강력하지만 AGPL 라이선스 복잡성과 다중 패키지 설정 오버헤드를 수반합니다.
IronPDF는 더 간단한 설정으로 완전한 커버리지를 제공합니다 — 30
일 동안 무료로 체험해 보세요.
PDF는 Adobe Acrobat Reader가 만든 포터블 문서 형식으로, 인터넷을 통해 디지털로 정보를 공유하는 데 널리 사용됩니다. 데이터의 서식을 유지하고 보안 권한 설정 및 비밀번호 보호와 같은 기능을 제공합니다. C# 개발자로서 소프트웨어 애플리케이션에 PDF 기능을 통합해야 하는 경우를 접했을 수 있습니다. 처음부터 구축하는 것은 시간이 많이 걸리고 번거로운 작업이 될 수 있습니다. 따라서 애플리케이션의 성능, 효과 및 효율성을 고려할 때, 처음부터 새로운 서비스를 만드는 것과 사전 구축된 라이브러리를 사용하는 것 사이의 절충은 중요합니다.
C#을 위한 여러 PDF 라이브러리가 있습니다. 이 기사에서는 C#에서 PDF 문서를 읽기 위한 가장 인기 있는 두 가지 PDF 라이브러리를 탐구할 것입니다.
iText 소프트웨어
iText, 이전에는 iText Core로 알려졌으며, .NET C# 및 Java에서 PDF 문서를 프로그래밍하기 위한 PDF 라이브러리입니다. 오픈 소스 라이센스(AGPL)로 제공되며 상업용 애플리케이션을 위해 라이센스 취득할 수 있습니다.
iText Core는 모든 가능한 방법으로 PDF를 생성하고 편집하는 간단한 메서드를 제공하는 고급 API입니다. iText Core를 사용하면 PDF 파일에서 양식을 분할, 병합, 주석 처리, 채울 수 있으며 디지털 서명도 가능합니다. iText는 HTML to PDF 변환기를 제공합니다.
IronPDF
IronPDF에 대해 더 알아보기는 URL, HTML 파일 또는 HTML 문자열에서 HTML, CSS, JavaScript로 PDF 문서를 생성하는 데 사용되는 .NET 및 .NET Framework C# 및 Java API입니다. IronPDF는 파일 분할, 병합, 주석 처리, 디지털 서명 등 기존 PDF 파일을 조작할 수 있습니다.
IronPDF는 PDF 파일을 생성, 읽기, 편집하기 위한 50개 이상의 기능을 갖추고 있습니다. Adobe Acrobat Reader로 고품질, 픽셀 완벽의 전문 PDF 파일을 전달해야 할 때 속도, 사용 편의성 및 정확성을 우선시합니다. API는 잘 문서화되어 있고, 많은 예제 소스 코드를 코드 예제 페이지에서 찾을 수 있습니다.
콘솔 애플리케이션 만들기
우리는 애플리케이션 제작을 위해 Visual Studio 2022 IDE를 사용할 것입니다. Visual Studio는 C# 개발의 공식 IDE이며 설치되어 있어야 합니다. 설치되지 않은 경우 Microsoft Visual Studio 웹사이트에서 다운로드할 수 있습니다.
다음 단계는 "DemoApp"이라는 새 프로젝트를 만드는 것입니다.
-
Visual Studio를 열고 "새 프로젝트 만들기"를 클릭합니다.
-
"콘솔 애플리케이션"을 선택하고 "다음"을 클릭합니다.
-
프로젝트의 이름을 설정합니다.
-
.NET 버전을 선택하세요. 안정된 버전 .NET 6.0을 선택하십시오.
IronPDF 라이브러리를 설치하세요
프로젝트가 생성되면 IronPDF 라이브러리를 프로젝트에 설치해야 사용 가능합니다. 다음 단계에 따라 설치하세요.
-
솔루션 탐색기 또는 도구에서 NuGet 패키지 관리자를 엽니다.
-
IronPDF 라이브러리를 찾아 현재 프로젝트에 선택합니다. 설치를 클릭합니다.
Program.cs 파일 상단에 다음 네임스페이스를 추가합니다:
using IronPdf;using IronPdf;Imports IronPdfiText 라이브러리 설치
프로젝트가 만들어지면 iText 라이브러리를 프로젝트에 설치하여 사용해야 합니다. 설치를 위해 다음 단계를 따르세요.
-
솔루션 탐색기 또는 도구에서 NuGet 패키지 관리자를 엽니다.
-
iText 라이브러리를 찾아 현재 프로젝트에 선택합니다. 설치를 클릭하세요.
Program.cs 파일 상단에 다음 네임스페이스를 추가합니다:
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;Imports iText.Kernel.Pdf.Canvas.Parser.Listener
Imports iText.Kernel.Pdf.Canvas.Parser
Imports iText.Kernel.PdfPDF 파일 열기
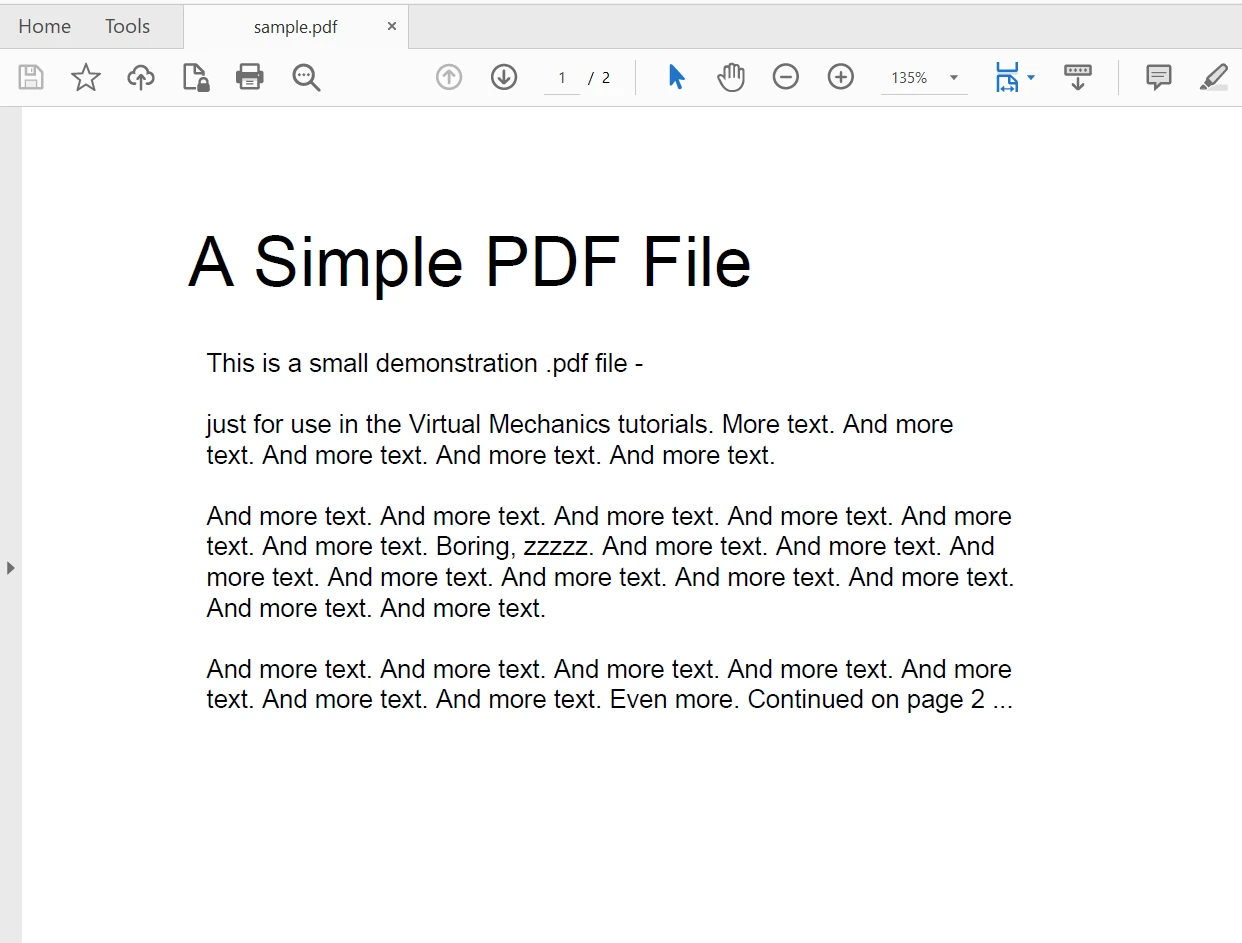
이제 텍스트를 추출하기 위해 다음 PDF 파일을 사용할 것입니다. 이것은 두 페이지로 구성된 PDF 문서입니다.
iText 라이브러리 사용
iText 라이브러리를 사용하여 PDF 파일을 열기 위한 절차는 두 단계로 이루어집니다. 먼저, PdfReader 객체를 생성하고 파일 위치를 매개변수로 전달합니다. 그런 다음 PdfDocument 클래스를 사용하여 새 PDF 문서를 생성합니다. 코드는 다음과 같습니다.
// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);' Initialize a reader instance by specifying the path of the PDF file
Dim pdfReader As New PdfReader("sample.pdf")
' Initialize a document instance using the PdfReader
Dim pdfDoc As New PdfDocument(pdfReader)IronPDF 사용하기
IronPDF를 사용하여 PDF 파일을 여는 것은 쉽습니다. PdfDocument 클래스의 FromFile 메서드를 사용하여 PDF를 파일 위치에서 엽니다. 다음의 한 줄 코드로 데이터를 읽기 위해 PDF 파일을 엽니다:
// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");' Open a PDF file using IronPDF and create a PdfDocument instance
Dim pdf = PdfDocument.FromFile("sample.pdf")PDF 파일에서 데이터 읽기
iText 라이브러리 사용
iText 라이브러리에서 PDF 데이터를 읽는 것은 그리 간단하지 않습니다. PDF 문서의 각 페이지를 수동으로 순회하여 각 페이지에서 텍스트를 추출해야 합니다. 다음 소스 코드는 PDF 문서에서 페이지별로 텍스트를 추출하는 데 도움이 됩니다:
// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();' Iterate through each page and extract text
Dim page As Integer = 1
Do While page <= pdfDoc.GetNumberOfPages()
' Define the text extraction strategy
Dim strategy As ITextExtractionStrategy = New SimpleTextExtractionStrategy()
' Extract text from the current page using the strategy
Dim pageContent As String = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy)
' Output the extracted text to the console
Console.WriteLine(pageContent)
page += 1
Loop
' Close document and reader to release resources
pdfDoc.Close()
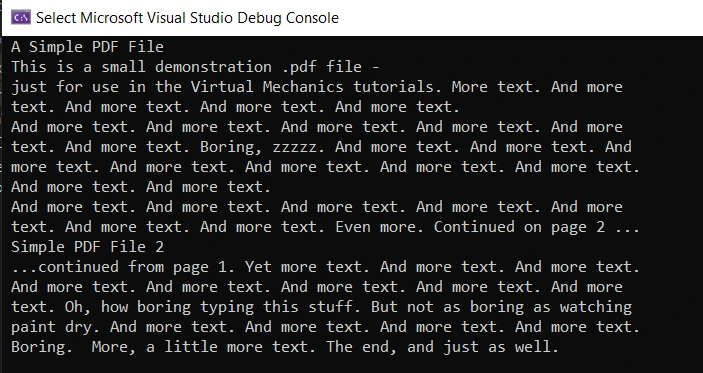
pdfReader.Close()위 코드에는 많은 내용이 포함되어 있습니다. 먼저 텍스트 추출 전략을 선언한 다음 PdfExtractor 클래스의 GetTextFromPage 메서드를 사용하여 텍스트를 읽습니다. 이 메소드는 두 개의 매개변수를 받습니다: 첫 번째는 PDF 문서 페이지이고, 두 번째는 전략입니다. PDF 문서 페이지를 얻으려면 PdfDocument의 인스턴스를 사용하여 GetPage 메서드를 호출하고 페이지 번호를 매개변수로 전달합니다. 출력은 문자열로 반환되며, 이는 콘솔 출력 화면에 표시됩니다. 마지막으로 PDFReader 및 PdfDocument 객체가 닫힙니다. iText를 사용하여 PDF에서 텍스트를 추출하는 다음 코드 예제도 참조하십시오.
산출
IronPDF 사용하기
PDF 파일을 여는 것이 한 줄의 코드였던 것처럼, PDF 파일에서 텍스트를 읽는 것도 한 줄의 절차입니다. PDFDocument 클래스는 PDF에서 전체 내용을 읽기 위한 ExtractAllText 메서드를 제공합니다. Console.WriteLine는 화면에 텍스트를 인쇄하는 데 사용됩니다. 코드는 다음과 같습니다.
// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);' Extract all text from the PDF document
Dim text As String = pdf.ExtractAllText()
' Display the extracted text
Console.WriteLine(text)산출
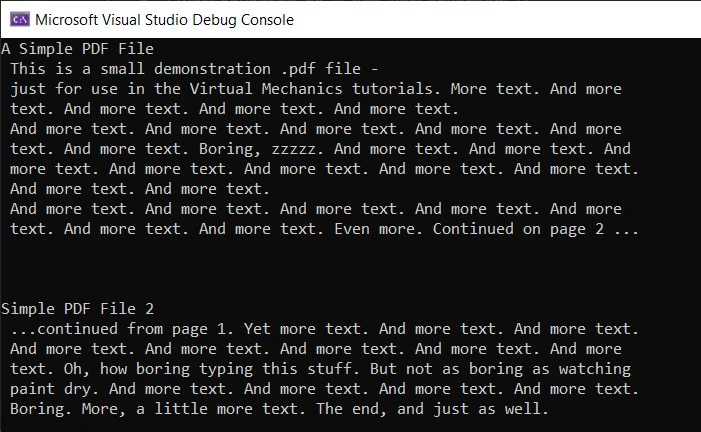
출력은 정확하고 오류가 없습니다. 그러나 ExtractAllText 메서드를 사용하려면 라이선스가 필요하며 이는 프로덕션 모드에서만 작동합니다. 30일 동안 IronPDF 체험판 라이센스 페이지에서 체험판 라이선스 키를 받을 수 있습니다.
비교
비교해보면, 두 라이브러리 모두 PDF 문서에서 텍스트를 추출할 때 정확한 결과를 제공합니다. 텍스트 추출 정확성 면에서 비슷합니다. 그러나 IronPDF는 코드 가독성과 개발자 편의성 면에서 더 효율적입니다.
IronPDF는 iText와 동일한 작업을 수행하는데 코드 두 줄만 필요합니다. 추가적인 로직을 구현할 필요 없이 바로 사용할 수 있는 텍스트 추출 메서드를 제공합니다. iText 코드는 조금 까다롭고, PDF 문서를 열 때 생성된 두 인스턴스를 닫아야 합니다. 반면, IronPDF는 작업이 수행되면 자동으로 메모리를 정리합니다.
요약
이 문서에서는 C#에서 iText 라이브러리를 사용하여 PDF 문서를 읽는 방법을 살펴보고 IronPDF와 비교했습니다. 두 라이브러리는 정확한 결과를 제공하며 작업할 수 있는 다양한 PDF 조작 메서드를 제공합니다. 이 두 라이브러리를 사용하여 PDF 파일에서 데이터를 생성, 편집 및 읽을 수 있습니다.
iText는 오픈 소스이며 사용이 무료이지만 제한이 있습니다. 상업적 사용을 위해 라이센스를 구매할 수 있습니다. IronPDF는 또한 무료로 사용할 수 있으며, 30일 무료 체험판이 제공되며 상업적 활동을 위한 라이센스를 받을 수 있습니다.
자주 묻는 질문
IronPDF는 무엇이며 iText 7과 어떻게 비교됩니까?
IronPDF는 HTML, CSS, JavaScript로부터 PDF 문서를 생성하고 조작하기 위해 설계된 .NET 라이브러리입니다. iText 7과 비교했을 때, IronPDF는 속도, 사용 편의성, 정확성을 강조하며 PDF 작업을 수행하기 위해 더 적은 코드 줄을 요구합니다.
C#에서 HTML을 PDF로 변환하는 방법은 무엇인가요?
IronPDF의 RenderHtmlAsPdf 메서드를 사용하여 HTML 문자열을 PDF로 변환할 수 있습니다. 또한 RenderHtmlFileAsPdf 사용하여 HTML 파일을 PDF로 변환할 수도 있습니다.
IronPDF를 C# 프로젝트에 설치하기 위한 단계는 무엇인가요?
C# 프로젝트에 IronPDF를 설치하려면 Visual Studio의 NuGet 패키지 관리자를 열고, IronPDF를 검색하여 프로젝트에 선택한 후 설치 버튼을 클릭하세요. 그리고 C# 파일의 상단에 using IronPdf;를 포함하세요.
IronPDF를 사용하여 PDF에서 텍스트를 추출하려면 어떻게 하나요?
IronPDF를 사용하여 PDF에서 텍스트를 추출하려면, PdfDocument 클래스의 FromFile 메서드를 사용하여 PDF를 로드하고, 그 후 ExtractAllText 메서드를 사용하여 텍스트를 가져옵니다.
IronPDF 사용에 대한 문제 해결 팁은 무엇인가요?
IronPDF가 NuGet을 통해 올바르게 설치되었는지 확인하고, C# 파일에 올바른 네임스페이스가 포함되어 있는지 확인하세요. 파일 경로를 확인하고 HTML이 PDF로 변환될 때 HTML 내용이 잘 형성되어 있는지 확인하세요.
IronPDF는 PDF 폼 및 주석을 처리할 수 있나요?
네, IronPDF는 폼 채우기와 PDF에 주석 추가 같은 기능을 지원하여 상호작용적이고 동적인 PDF 문서를 만들 수 있습니다.
IronPDF 무료로 사용할 수 있나요?
IronPDF는 제한된 기능이 있는 무료 버전과 전체 기능을 제공하는 상업용 버전을 위한 30일 무료 체험판을 제공합니다.
iText 7를 사용한 PDF 조작의 제한 사항은 무엇인가요?
iText 7는 강력한 PDF 라이브러리이지만, 텍스트 추출 같은 특정 작업을 위해 추가적인 로직이 필요하며, IronPDF에 비해 코드가 더 복잡하고 길어질 수 있습니다.