Foxit PDF SDK C# Alternativen - Vergleich mit IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
IronPDF vs iText / iText
Umfassender Vergleich von .NET PDF-Bibliotheken – detaillierte Funktionsanalyse mit fundiertem Kontext
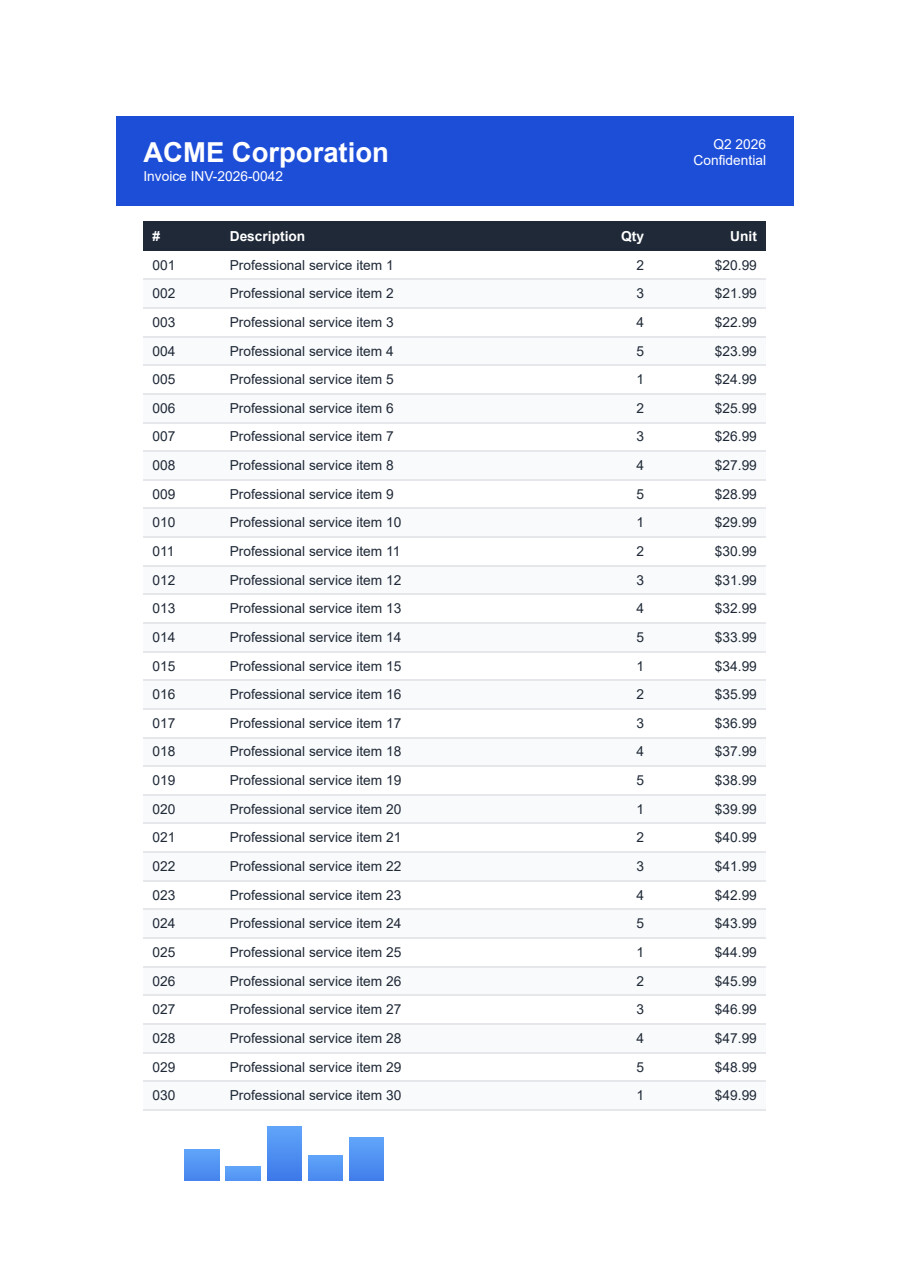
| Merkmal | iText / iText | IronPDF ✦ |
|---|---|---|
| PDF-Erstellung und -Konvertierung | ||
| HTML/CSS zu PDF |
$ Paid Add-on
HTML→PDF über
pdfHTML -Add-on (separates Paket; AGPL/kommerzielles Modell). |
✓ Yes
Chromium-basierte Engine mit integrierter pixelgenauer CSS3-, Flexbox- und Grid-Darstellung.
|
| JavaScript-Ausführung |
? Unknown
pdfHTML beschreibt die HTML/CSS→PDF-Konvertierung, die Unterstützung für die JS-Ausführung wird in der Dokumentation jedoch nicht erwähnt.
|
✓ Yes
Führt JavaScript vollständig während des Renderings aus – dynamische Diagramme, Single-Page-Anwendungen und interaktive Inhalte.
|
| Programmatische Generierung |
✓ Yes
Positioniert als programmierbares PDF SDK for .NET – erstellen, bearbeiten und erweitern.
|
✓ Yes
Generiert aus HTML-Vorlagen, Zeichenketten, ASPX-Ansichten oder Bildern. Chromium kümmert sich um das Layout.
|
| URL-zu-PDF |
$ Paid Add-on
Möglich über das pdfHTML-Add-on mit URL-Abruf, aber keine Kernfunktion.
|
✓ Yes
RenderUrlAsPdf() Erfasst jede beliebige Live-URL mit vollständiger CSS/JS-Darstellung. |
| DOCX to PDF |
✕ No
Keine native Word-Konvertierung – iText ist ein PDF-natives SDK.
|
✓ Yes
DocxToPdfRenderer Konvertiert Word-Dokumente unter Beibehaltung von Struktur und Formatierung. |
| Lesen & Extrahieren | ||
| Textextraktion |
✓ Yes
PdfTextExtractor.GetTextFromPage() mit mehreren Extraktionsstrategien. |
✓ Yes
Extrahiert Text unter Berücksichtigung des Layouts. Kombiniert sich mit IronOCR für gescannte Dokumente.
|
| Seiten in Bilder umwandeln |
? Unknown
In den OCR-Workflows wird das Rendern erwähnt, aber ein Modul namens "PDF→Bildrenderer" aus dem Primärquellcode ist in den zitierten iText-Dokumenten nicht nachweisbar.
|
✓ Built-in
Native Rasterisierung zu PNG, JPEG, BMP mit konfigurierbarer DPI.
|
| Eingebaute OCR |
$ Paid Add-on
pdfOCR-Add-on verfügbar; Installationshinweise erwähnen plattformspezifische/native Abhängigkeiten (z. B. Laufzeitvoraussetzungen für Linux/macOS).
|
✓ Via IronOCR
Native Integration mit IronOCR für OCR in über 127 Sprachen auf gescannten PDFs.
|
| Bearbeitung & Manipulation | ||
| Zusammenführen & Aufteilen |
✓ Yes
PdfMerger Klasse in der .NET -API; offizielle Beispiele behandeln das Zusammenführen mit PdfMerger.
|
✓ Yes
Einzeiliges Zusammenführen, Aufteilen, Anhängen, Voranstellen und Neuanordnen von Seiten mit intuitiver API.
|
| Kopf- und Fußzeilen sowie Seitenzahlen |
✓ Yes
Der Eintrag in der PDF Association bestätigt die Möglichkeit, bestehenden PDFs "Seitenzahlen" und ähnliche Funktionen hinzuzufügen.
|
✓ Yes
HTML-basierte Kopf- und Fußzeilen mit automatischer Seitenzählung, Datumsangaben und benutzerdefinierten Inhalten.
|
| Wasserzeichen |
✓ Yes
Die PDF Association listet ausdrücklich auch "Wasserzeichen … für bestehende PDF-Dokumente" auf.
|
✓ Yes
ApplyWatermark() Akzeptiert HTML/CSS – volle Kontrolle über Deckkraft, Drehung und Position. |
| Text- & Bildstempel |
✓ Yes
Programmatische Inhaltsplatzierung ist über die Canvas- und Layout-APIs von iText möglich.
|
✓ Yes
TextStamper & ImageStamper mit Google Fonts, Positionierung, seitenweise Steuerung. |
| Inhalt schwärzen |
✓ Yes
iText bietet Unterstützung für Schwärzungsanmerkungen über das Bereinigungsmodul.
|
✓ Yes
RedactTextOnAllPages() Entfernt sensible Texte dauerhaft in einer einzigen Zeile.
|
| Sicherheit und Konformität | ||
| Verschlüsselung & Passwörter |
✓ Yes
Vollständige Verschlüsselung und Berechtigungskontrolle über die Sicherheits-API von iText.
|
✓ Yes
AES-Verschlüsselung, Besitzer-/Benutzerpasswörter, differenzierte Berechtigungen (Drucken, Kopieren, Kommentieren).
|
| Digitale Signaturen |
✓ Yes
Spezielle Dokumentation zur digitalen Signatur und Signatur-API (
PdfSigner ). |
✓ Yes
PdfSignature mit Unterstützung für X509/PFX-Zertifikate. |
| PDF/A- und PDF/UA-Konformität |
✓ Yes
Die Dokumentation beschreibt die Erstellung von PDF/A-Dateien und erläutert die Einschränkungen (die Konvertierung von bestehenden Dateien erfolgt nicht automatisch).
|
✓ Yes
Native PDF/A-Archivierung und PDF/UA-Barrierefreiheitskonformität für den Enterprise .
|
| Plattform & Bereitstellung | ||
| Plattformübergreifende Unterstützung |
✓ Yes
.NET Standard 2.0 / .NET Framework 4.6.1 — läuft auf .NET 6+ auf verschiedenen Betriebssystemen.
|
✓ Yes
Windows, Linux, macOS, x64, x86, ARM. .NET 6-10, Core, Standard 2.0+, Framework 4.6.2+.
|
| Server / Docker / Cloud |
~ Complex
Für die Core-Installation werden mehrere Pakete benötigt (iText + Bouncy Castle Adapter); die Add-ons (pdfHTML/pdfOCR) erfordern zusätzliche Abhängigkeits-/Konformitätsschritte.
|
✓ Yes
Docker, Azure, AWS, IIS. Offizielle Docker-Images und Bereitstellungsleitfäden.
|
| Einfache Einrichtung |
~ Complex
Für die Core-Installation werden mehrere Pakete benötigt (Bouncy Castle-Adapter); für HTML/OCR werden zusätzliche Add-ons und manchmal native Abhängigkeiten benötigt.
|
✓ Simple
Einzelner IronPdf- NuGet Befehl
Install-Package IronPdf . In wenigen Minuten einsatzbereit. |
| Lizenzierung & Support | ||
| Lizenzmodell |
~ Complex
Doppellizenz: AGPLv3 (Offenlegungspflichten für die Netzwerknutzung) oder kommerzielle Lizenz. Die AGPL kann für proprietäre Anwendungen einschränkend wirken.
|
✓ Commercial
Dauerlizenzen. 30 Tage voll funktionsfähige, kostenlose Testversion, keine Wasserzeichen.
|
| Kommerzieller Support & SLA |
✓ Yes
Die iText-Website beinhaltet kommerzielle Lizenz- und Supportvereinbarungen als Teil ihres Lizenzmodells.
|
✓ 24/5 Support
Engagierter technischer Support mit garantierter Service-Level-Vereinbarung (SLA) – E-Mail, Live-Chat, Telefon.
|
| Dokumentation |
✓ Yes
Installationsanleitungen, Wissensdatenbankartikel und API-Referenzen sind verfügbar (Kern + Add-ons).
|
✓ Extensive
Vollständige API-Referenz, über 100 Anleitungen, Tutorials, Codebeispiele, Fehlerbehebung, Videos.
|
Daten stammen aus der offiziellen iText-Dokumentation, Listung der PDF Association und NuGet-Paketreferenzen.
iText ist leistungsstark, aber es gibt AGPL-Lizenzkompliziertheit und Overhead bei der Einrichtung mehrerer Pakete.
IronPDF bietet umfassende Abdeckung bei einfacherem Setup — probieren Sie es 30
Tage kostenlos aus.
PDF ist ein tragbares Dokumentenformat, das von Adobe Acrobat Reader erstellt wurde und häufig zum digitalen Austausch von Informationen über das Internet verwendet wird. Es bewahrt das Datenformat und bietet Funktionen wie das Festlegen von Sicherheitsberechtigungen und Passwortschutz. Als C#-Entwickler haben Sie möglicherweise Szenarien erlebt, in denen es notwendig ist, PDF-Funktionalität in Ihre Softwareanwendung zu integrieren. Es von Grund auf neu zu erstellen, kann eine zeitaufwendige und mühsame Aufgabe sein. Daher ist es angesichts der Leistung, Effektivität und Effizienz der Anwendung von Bedeutung, den Kompromiss zwischen der Erstellung eines neuen Dienstes von Grund auf neu oder der Verwendung einer vorgefertigten Bibliothek abzuwägen.
Es gibt mehrere PDF-Bibliotheken für C#. In diesem Artikel werden wir zwei der beliebtesten PDF-Bibliotheken zum Lesen von PDF-Dokumenten in C# untersuchen.
iText-Software
iText, vormals bekannt als iText Core, ist eine PDF-Bibliothek zur Programmierung von PDF-Dokumenten in .NET C# und Java. Es ist als Open Source-Lizenz (AGPL) erhältlich und kann für kommerzielle Anwendungen lizenziert werden.
iText Core ist eine High-Level-API, die einfache Methoden zum Generieren und Bearbeiten von PDFs in jeder erdenklichen Weise bietet. Mit iText Core können Sie PDF-Dateien trennen, zusammenführen, kommentieren, Formulare ausfüllen, digital unterschreiben und vieles mehr. iText provides an HTML to PDF converter.
IronPDF
Erfahren Sie mehr über IronPDF ist eine .NET- und .NET Framework C#- und Java-API, die zum Generieren von PDF-Dokumenten aus HTML, CSS und JavaScript entweder aus einer URL, HTML-Dateien oder HTML-Strings verwendet wird. IronPDF ermöglicht das Manipulieren bestehender PDF-Dateien, wie das Aufteilen, Zusammenführen, Kommentieren, digital Signieren und vieles mehr.
IronPDF ist mit über 50 Funktionen angereichert, um PDF-Dateien zu erstellen, zu lesen und zu bearbeiten. Es priorisiert Geschwindigkeit, Benutzerfreundlichkeit und Genauigkeit, wenn Sie hochwertige, pixelgenaue professionelle PDF-Dateien mit Adobe Acrobat Reader liefern müssen. Die API ist gut dokumentiert, und viele Beispiel-Quellcodes finden Sie auf der Beispielcode-Seite.
Erstellen Sie eine Konsolenanwendung
Wir werden die Visual Studio 2022 IDE verwenden, um eine Anwendung zu erstellen, mit der wir beginnen. Visual Studio ist die offizielle IDE für die C#-Entwicklung, und Sie müssen es installiert haben. Wenn es nicht installiert ist, können Sie es von der Microsoft Visual Studio Website herunterladen.
Die folgenden Schritte werden ein neues Projekt namens "DemoApp" erstellen.
-
Öffnen Sie Visual Studio und klicken Sie auf "Create a New Project".
-
Wählen Sie "Console Application" und klicken Sie auf "Next".
-
Geben Sie dem Projekt einen Namen.
-
Wählen Sie die .NET-Version. Wählen Sie die stabile Version .NET 6.0.
IronPDF-Bibliothek installieren
Sobald das Projekt erstellt ist, muss die IronPDF-Bibliothek im Projekt installiert werden, um sie zu verwenden. Befolgen Sie diese Schritte zur Installation.
-
Öffnen Sie den NuGet-Paket-Manager, entweder aus dem Lösungsexplorer oder über Tools.
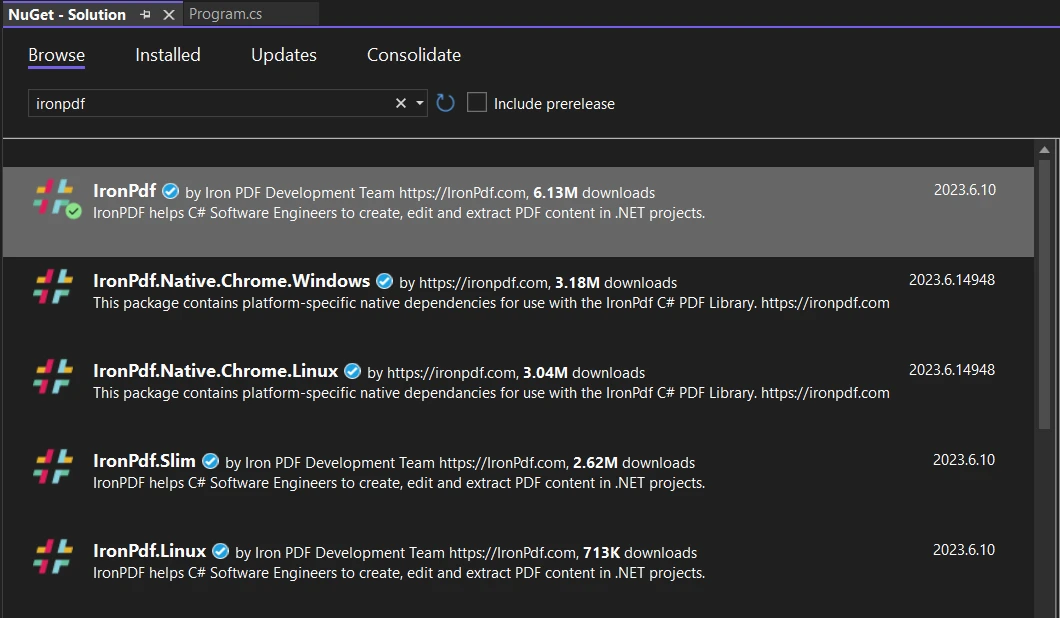
-
Suchen Sie nach der IronPDF-Bibliothek und wählen Sie sie für das aktuelle Projekt aus. Klicken Sie auf Installieren.
Fügen Sie die folgende Namespace-Deklaration am Anfang der Program.cs-Datei hinzu:
using IronPdf;using IronPdf;Imports IronPdfiText Bibliothek installieren
Sobald das Projekt erstellt ist, muss die iText-Bibliothek im Projekt installiert werden, um sie zu verwenden. Befolgen Sie die Schritte zur Installation.
-
Öffnen Sie den NuGet-Paketmanager entweder über den Lösungs-Explorer oder über Werkzeuge.
-
Suchen Sie nach der iText-Bibliothek und wählen Sie sie für das aktuelle Projekt aus. Klicken Sie auf Install.
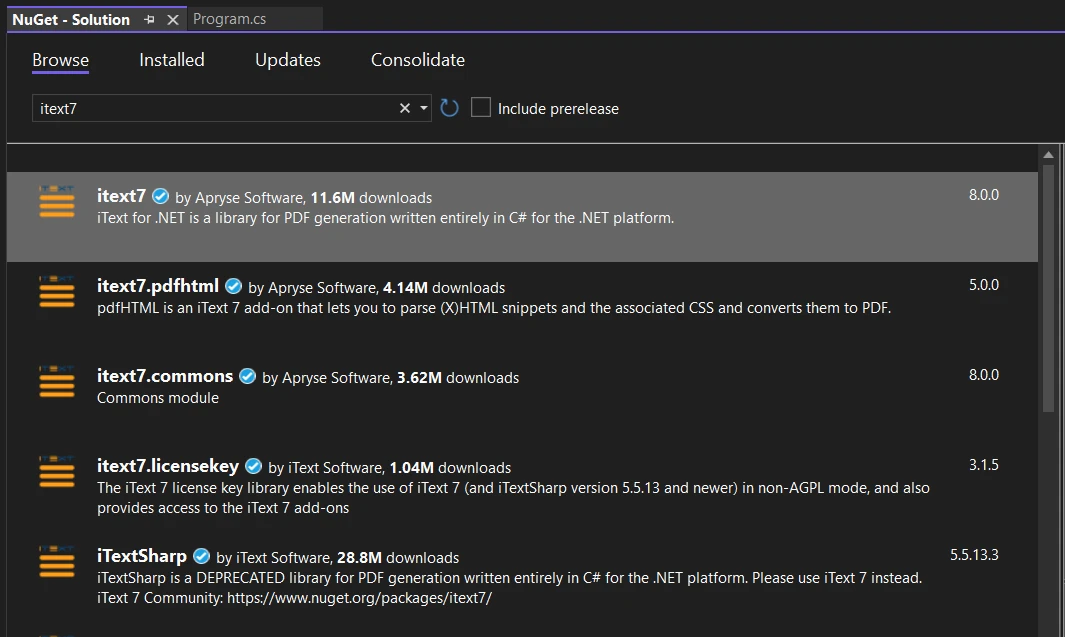
Fügen Sie die folgenden Namespaces am Anfang der Program.cs-Datei hinzu:
using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;using iText.Kernel.Pdf.Canvas.Parser.Listener;
using iText.Kernel.Pdf.Canvas.Parser;
using iText.Kernel.Pdf;Imports iText.Kernel.Pdf.Canvas.Parser.Listener
Imports iText.Kernel.Pdf.Canvas.Parser
Imports iText.Kernel.PdfPDF-Dateien öffnen
Wir werden die folgende PDF-Datei verwenden, um Text aus ihr zu extrahieren. Es ist ein zweiseitiges PDF-Dokument.
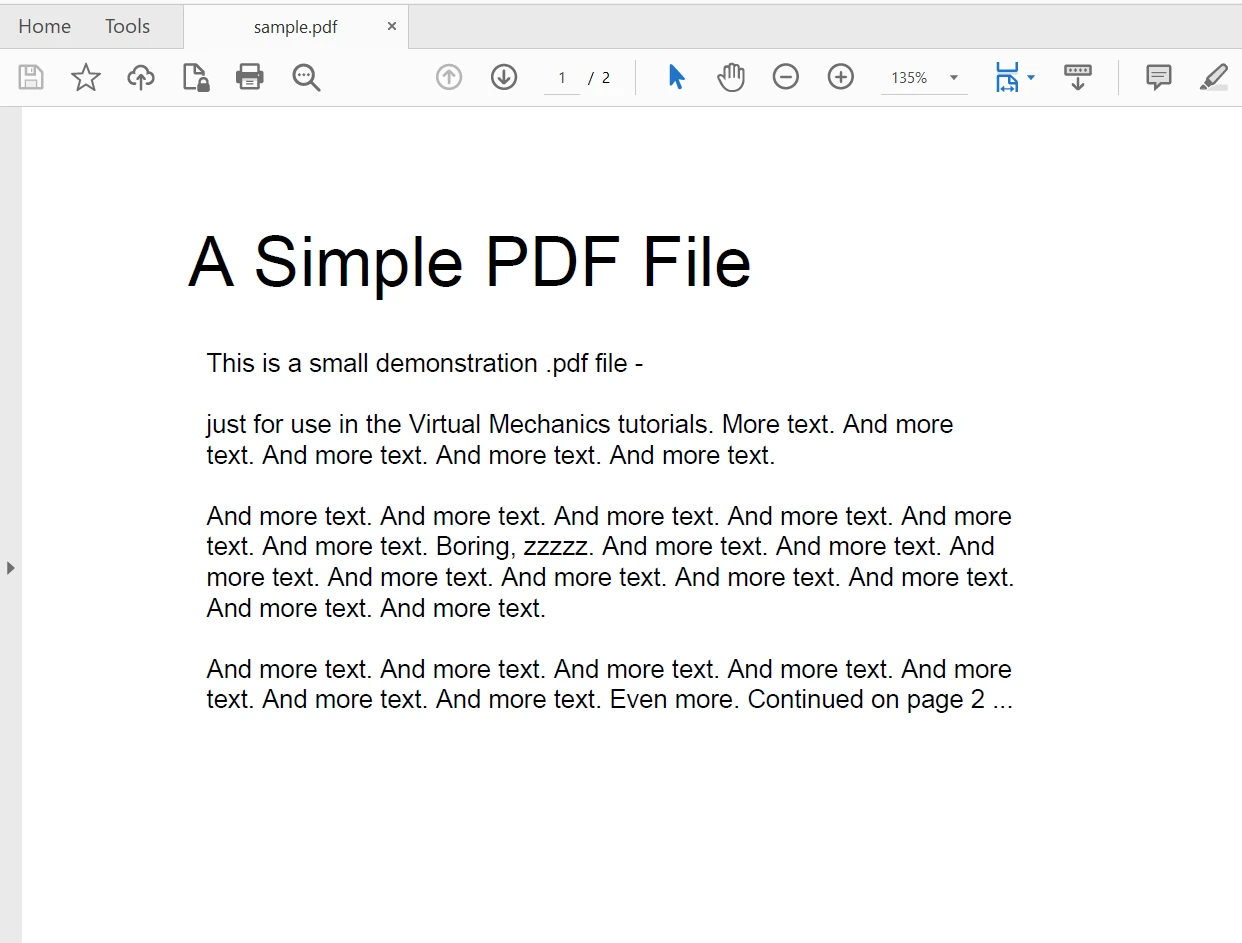Verwendung der iText-Bibliothek
Eine PDF-Datei mit der iText-Bibliothek zu öffnen, ist ein zweistufiger Prozess. Zuerst erstellen wir ein PdfReader Objekt und übergeben den Dateispeicherort als Parameter. Dann verwenden wir die PdfDocument Klasse, um ein neues PDF-Dokument zu erstellen. Der Code sieht wie folgt aus:
// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);// Initialize a reader instance by specifying the path of the PDF file
PdfReader pdfReader = new PdfReader("sample.pdf");
// Initialize a document instance using the PdfReader
PdfDocument pdfDoc = new PdfDocument(pdfReader);' Initialize a reader instance by specifying the path of the PDF file
Dim pdfReader As New PdfReader("sample.pdf")
' Initialize a document instance using the PdfReader
Dim pdfDoc As New PdfDocument(pdfReader)Verwendung von IronPDF
PDF-Dateien mit IronPDF zu öffnen ist einfach. Verwenden Sie die PdfDocument Klasse der FromFile Methode, um PDFs von beliebigen Dateispeicherorten zu öffnen. Der folgende Einzeiler öffnet eine PDF-Datei zum Lesen der Daten:
// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");// Open a PDF file using IronPDF and create a PdfDocument instance
var pdf = PdfDocument.FromFile("sample.pdf");' Open a PDF file using IronPDF and create a PdfDocument instance
Dim pdf = PdfDocument.FromFile("sample.pdf")Lesen von Daten aus PDF-Dateien
Verwendung der iText-Bibliothek
Das Lesen von PDF-Daten ist in der iText-Bibliothek nicht so einfach. Wir müssen manuell durch jede Seite des PDF-Dokuments blättern, um Text aus jeder Seite zu extrahieren. Der folgende Quellcode hilft, Text aus dem PDF-Dokument seitenweise zu extrahieren:
// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();// Iterate through each page and extract text
for (int page = 1; page <= pdfDoc.GetNumberOfPages(); page++)
{
// Define the text extraction strategy
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
// Extract text from the current page using the strategy
string pageContent = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy);
// Output the extracted text to the console
Console.WriteLine(pageContent);
}
// Close document and reader to release resources
pdfDoc.Close();
pdfReader.Close();' Iterate through each page and extract text
Dim page As Integer = 1
Do While page <= pdfDoc.GetNumberOfPages()
' Define the text extraction strategy
Dim strategy As ITextExtractionStrategy = New SimpleTextExtractionStrategy()
' Extract text from the current page using the strategy
Dim pageContent As String = PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(page), strategy)
' Output the extracted text to the console
Console.WriteLine(pageContent)
page += 1
Loop
' Close document and reader to release resources
pdfDoc.Close()
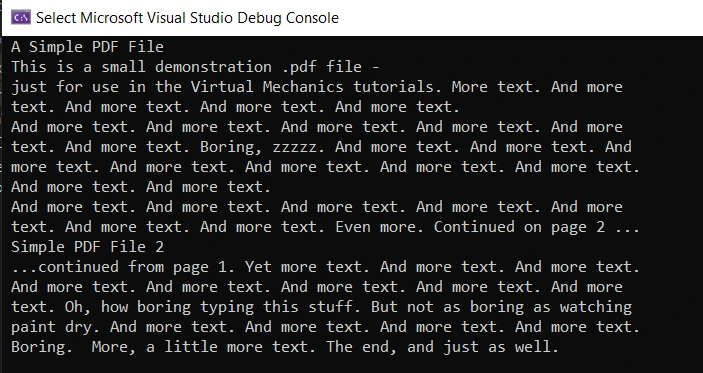
pdfReader.Close()Im obigen Code geschieht viel. Zuerst deklarieren wir die Text Extracting Strategy und verwenden dann die PdfExtractor Klasse der GetTextFromPage Methode, um Text zu lesen. Diese Methode akzeptiert zwei Parameter: Der erste ist die PDF-Dokumentseite und der zweite die Strategie. Um die PDF-Dokumentseite zu erhalten, verwenden Sie die Instanz von PdfDocument, um die GetPage Methode aufzurufen und die Seitenzahl als Parameter zu übergeben. Die Ausgabe wird als Zeichenfolge zurückgegeben, die dann auf dem Konsolenausgabebildschirm angezeigt wird. Schließlich werden die PDFReader und PdfDocument Objekte geschlossen. Siehe auch das folgende Beispiel für Code zur Textextraktion aus PDFs mit iText.
Ausgabe
Verwendung von IronPDF
So wie das Öffnen der PDF-Datei ein Einzeiler war, ist auch das Lesen von Text aus einer PDF-Datei ein Einzeiler. Die PDFDocument Klasse stellt die ExtractAllText Methode bereit, um den gesamten Inhalt aus dem PDF zu lesen. Console.WriteLine wird verwendet, um den Text auf dem Bildschirm auszugeben. Der Code sieht wie folgt aus:
// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);// Extract all text from the PDF document
string text = pdf.ExtractAllText();
// Display the extracted text
Console.WriteLine(text);' Extract all text from the PDF document
Dim text As String = pdf.ExtractAllText()
' Display the extracted text
Console.WriteLine(text)Ausgabe
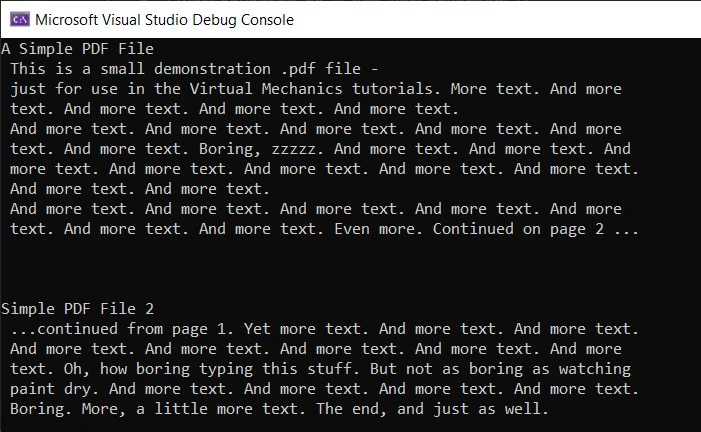Die Ausgabe ist genau und fehlerfrei. Um jedoch die ExtractAllText Methode zu verwenden, benötigen Sie eine Lizenz, da sie nur im Produktionsmodus funktioniert. Sie können Ihren Testlizenzschlüssel für 30 Tage von der IronPDF-Testlizenz-Seite erhalten.
Vergleich
Im Vergleich erzielen beide Bibliotheken genaue Ergebnisse beim Extrahieren von Text aus einem PDF-Dokument. Sie sind vergleichbar, wenn es um die Genauigkeit der Textextraktion geht. IronPDF ist jedoch effizienter in Bezug auf Code-Lesbarkeit und Entwickler-Ergonomie.
IronPDF benötigt nur zwei Codezeilen, um dieselbe Aufgabe wie iText zu erledigen. Es bietet Textextraktionsmethoden ohne zusätzliche Logik, die implementiert werden muss. Der iText-Code ist etwas knifflig und man muss die beiden beim Öffnen eines PDF-Dokuments erstellten Instanzen schließen. Hingegen räumt IronPDF automatisch den Speicher auf, sobald die Aufgabe erledigt ist.
Zusammenfassung
In diesem Artikel haben wir uns angesehen, wie man PDF-Dokumente mit der iText-Bibliothek in C# lesen kann und sie dann mit IronPDF verglichen. Beide Bibliotheken liefern genaue Ergebnisse und bieten zahlreiche PDF-Manipulationsmethoden, mit denen man arbeiten kann. Sie können Daten aus PDF-Dateien mit beiden Bibliotheken erstellen, bearbeiten und lesen.
iText ist Open Source und frei nutzbar, jedoch mit Einschränkungen. Es kann für kommerzielle Nutzung lizenziert werden. IronPDF ist ebenfalls frei nutzbar und kann für kommerzielle Aktivitäten lizenziert werden mit einem 30-tägigen kostenlosen Testzeitraum.
Laden Sie IronPDF herunter und probieren Sie es aus.
Häufig gestellte Fragen
Was ist IronPDF und wie verhält es sich im Vergleich zu iText 7?
IronPDF ist eine .NET-Bibliothek, die zum Erstellen und Manipulieren von PDF-Dokumenten aus HTML, CSS und JavaScript entwickelt wurde. Im Vergleich zu iText 7 legt IronPDF Wert auf Geschwindigkeit, Benutzerfreundlichkeit und Genauigkeit und benötigt weniger Codezeilen, um PDF-Aufgaben zu erledigen.
Wie kann ich HTML in PDF in C# konvertieren?
Sie können die RenderHtmlAsPdf-Methode von IronPDF verwenden, um HTML-Strings in PDFs zu konvertieren. Zusätzlich können Sie HTML-Dateien mithilfe von RenderHtmlFileAsPdf in PDFs konvertieren.
Was sind die Installationsschritte für IronPDF in einem C#-Projekt?
Um IronPDF in einem C#-Projekt zu installieren, öffnen Sie den NuGet-Paket-Manager in Visual Studio, suchen Sie nach IronPDF, wählen Sie es für Ihr Projekt aus und klicken Sie auf Installieren. Fügen Sie am Anfang Ihrer C#-Datei using IronPDF; hinzu.
Wie extrahiere ich Text aus einem PDF mit IronPDF?
Um Text aus einem PDF mit IronPDF zu extrahieren, verwenden Sie die FromFile-Methode der PdfDocument-Klasse, um das PDF zu laden, gefolgt von der ExtractAllText-Methode, um den Text abzurufen.
Was sind einige Tipps zur Fehlerbehebung bei der Verwendung von IronPDF?
Stellen Sie sicher, dass IronPDF über NuGet korrekt installiert ist und dass die richtigen Namespaces in Ihrer C#-Datei enthalten sind. Überprüfen Sie die Dateipfade und stellen Sie sicher, dass der HTML-Inhalt gut geformt ist, wenn Sie HTML in PDF konvertieren.
Kann IronPDF PDF-Formulare und Anmerkungen verarbeiten?
Ja, IronPDF unterstützt Funktionen wie das Ausfüllen von Formularen und das Hinzufügen von Anmerkungen zu PDFs, sodass Sie interaktive und dynamische PDF-Dokumente erstellen können.
Ist IronPDF kostenlos nutzbar?
IronPDF bietet eine kostenlose Version mit eingeschränkten Funktionen und eine 30-tägige kostenlose Testversion für die kommerzielle Version, die alle Funktionen bietet.
Was sind die Einschränkungen bei der Verwendung von iText 7 zur PDF-Manipulation?
Obwohl iText 7 eine robuste PDF-Bibliothek ist, erfordert es für bestimmte Aufgaben wie das Textextrahieren zusätzliche Logik, was im Vergleich zu IronPDF zu komplexerem und längerem Code führen kann.