
PDFsharp Wyodrębnij tekst z PDF vs IronPDF (Przykład)
W dzisiejszym samouczku zajmiemy się tym, jak wyodrębnić tekst z dokumentów PDF przy użyciu dwóch potężnych bibliotek PDF: IronPDF i PDFsharp. Dowiemy się, jak działa wyodrębnianie tekstu za pomocą tych narzędzi bez konieczności posiadania licencji na bibliotekę Adobe oraz jak wypadają one w porównaniu ze sobą.
Istnieje wiele bibliotek skupiających się na plikach PDF, a poświęcając czas na ich porównanie i zapoznanie się z działaniem ich funkcji, będziesz w stanie wybrać bibliotekę odpowiednią do potrzeb Twojego projektu. Wyodrębnianie tekstu to tylko jeden z wielu przykładów zadań, które mogą być konieczne do wykonania na plikach PDF. Wyodrębnianie tekstu jest pomocne w sytuacjach, w których może zaistnieć potrzeba efektywnego odczytania lub analizy danych z plików PDF.
PDFsharp
PDFsharp to biblioteka .NET typu open source przeznaczona do programowego tworzenia i modyfikowania dokumentów PDF. Chociaż jego główną zaletą jest generowanie i edycja plików PDF, w połączeniu z odpowiednimi bibliotekami zewnętrznymi zapewnia również podstawowe narzędzia do odczytu istniejących plików PDF i wyodrębniania treści.
PDFsharp oferuje więcej niż tylko tworzenie nowych dokumentów PDF w dowolnym miejscu — można go używać do modyfikowania istniejących plików PDF, łączenia i dzielenia dokumentów, dodawania adnotacji i nie tylko.
IronPDF
IronPDF to profesjonalna biblioteka .NET zaprojektowana w celu uproszczenia pracy z dokumentami PDF w języku C#. Jest to bogate w funkcje narzędzie przeznaczone dla programistów tworzących aplikacje związane z generowaniem i edycją plików PDF, szyfrowaniem plików PDF, konwersją plików PDF, scalaniem stron PDF, konwersją HTML do PDF, wyodrębnianiem treści i nie tylko.
Dzięki swoim rozbudowanym możliwościom IronPDF wyróżnia się jako wszechstronne rozwiązanie do tworzenia plików PDF i zarządzania nimi zarówno w małych projektach, jak i w aplikacjach na poziomie Enterprise.
IronPDF został zaprojektowany tak, aby był kompatybilny z nowoczesnymi frameworkami .NET, w tym .NET Core, .NET 5, .NET 6 i .NET 7, a także starszymi wersjami, takimi jak .NET Framework. Działa płynnie na różnych systemach operacyjnych, takich jak Windows, macOS i Linux, i jest w pełni kompatybilny ze środowiskami Docker, Azure i AWS. Dzięki temu programiści mogą wdrażać swoje procesy związane z plikami PDF na dowolnej platformie lub w dowolnej usłudze w chmurze.
W dzisiejszym przykładzie spróbujemy wyodrębnić tekst z tego dokumentu PDF w programie Visual Studio:
Wyodrębnianie tekstu z pliku PDF za pomocą PDFsharp
PDFSharp w obecnej wersji nie obsługuje natywnie wyodrębniania tekstu z dokumentów PDF. Jest przeznaczony przede wszystkim do tworzenia i edycji plików PDF, takich jak rysowanie grafiki, dodawanie treści i scalanie dokumentów, ale nie posiada wbudowanego mechanizmu do samodzielnego wyodrębniania tekstu, nie obsługuje znaków specjalnych, zaawansowanego kodowania itp. Może to skutkować fragmentarycznym lub niekompletnym tekstem wyjściowym albo pustymi ciągami znaków zamiast rzeczywistej treści pliku PDF. Na przykład:
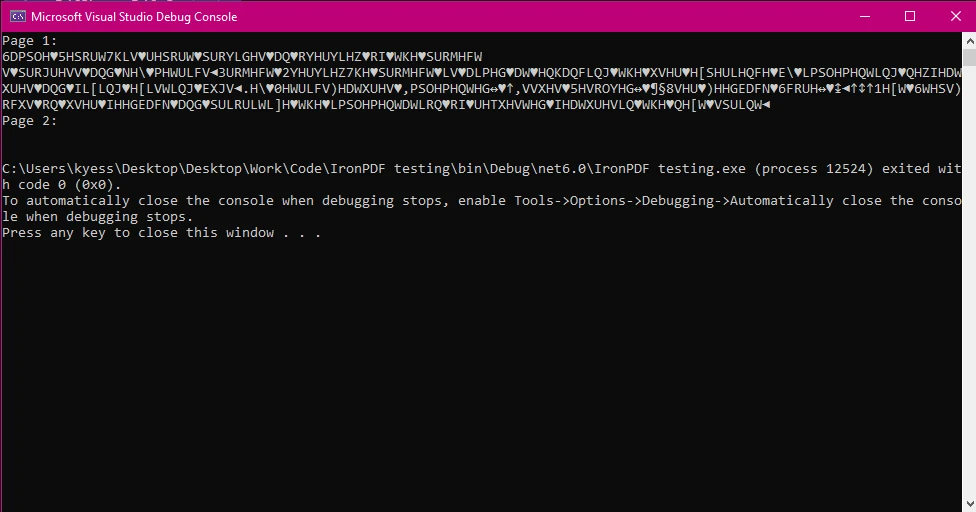
Jeśli potrzebujesz zaawansowanego wyodrębniania tekstu z lepszą obsługą różnych czcionek, kodowań i układów, prawdopodobnie będziesz musiał skorzystać z bardziej wyspecjalizowanej biblioteki, takiej jak:
-
iTextSharp (lub iText 7): Jest to popularna biblioteka PDF z rozbudowaną obsługą wyodrębniania i analizowania tekstu.
- Pdfium: Kolejna opcja, która doskonale sprawdza się w wyodrębnianiu tekstu, zwłaszcza z plików PDF o złożonym formatowaniu.
Wyodrębnianie tekstu z pliku PDF za pomocą IronPDF
Zobaczmy teraz, jak wygląda pobieranie tekstu przy użyciu IronPDF. Funkcja wyodrębniania tekstu w IronPDF zapewnia programistom zwięzłą, a jednocześnie potężną metodę wydajnego wyodrębniania tekstu z dokumentów PDF, bez konieczności stosowania dodatkowego kodu w celu poprawnego sformatowania ciągu danych w czytelny tekst.
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Provide the file path to the PDF document
string pdfPath = @"invoice.pdf";
// Load the PDF document using IronPDF
var pdf = PdfDocument.FromFile(pdfPath);
// Extract all text from the PDF
var extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Provide the file path to the PDF document
string pdfPath = @"invoice.pdf";
// Load the PDF document using IronPDF
var pdf = PdfDocument.FromFile(pdfPath);
// Extract all text from the PDF
var extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Provide the file path to the PDF document
Dim pdfPath As String = "invoice.pdf"
' Load the PDF document using IronPDF
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract all text from the PDF
Dim extractedText = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End Class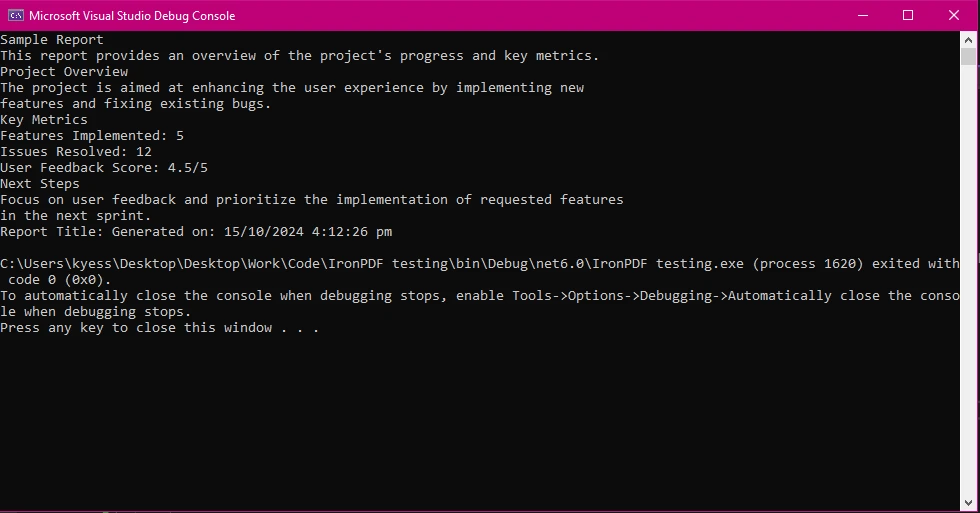
IronPDF zapewnia proste i wydajne API do wyodrębniania tekstu z podanej ścieżki pliku PDF. Gwarantuje to, że wyodrębniony tekst jest dobrze zorganizowany i dokładny, co czyni go niezawodnym rozwiązaniem dla programistów, którzy muszą przetwarzać zawartość plików PDF w swoich aplikacjach.
Porównanie
PDFSharp to bezpłatna biblioteka typu open source, idealna do podstawowego tworzenia i edycji plików PDF, ale ma ograniczoną funkcjonalność i ma trudności z obsługą złożonych plików PDF. Chociaż teoretycznie można go używać do wyodrębniania tekstu z plików PDF, wymagałoby to zaawansowanego parsowania tekstu i mogłoby skutkować fragmentarycznym wynikiem.
IronPDF oferuje bardziej niezawodne rozwiązanie z zaawansowanymi funkcjami, takimi jak dokładne wyodrębnianie tekstu, konwersja HTML do PDF oraz obsługa nowoczesnych standardów PDF. Jest zoptymalizowany pod kątem wydajności i łatwości użytkowania dzięki intuicyjnemu API. Chociaż jest to oprogramowanie darmowe do celów programistycznych, oferuje również licencje komercyjne w ramach płatnych planów licencyjnych.
Wnioski
Zarówno PDFsharp, jak i IronPDF są cennymi narzędziami do pracy z wyodrębnianiem tekstu z plików PDF w języku C#, ale są przeznaczone do różnych zastosowań:
- PDFSharp to doskonały wybór dla programistów, którzy potrzebują bezpłatnej biblioteki typu open source do podstawowego tworzenia plików PDF i wyodrębniania tekstu. Jednak jego możliwości w zakresie ekstrakcji tekstu są ograniczone i mogą nie spełniać wymagań bardziej złożonych aplikacji.
- Z kolei IronPDF wyróżnia się w zakresie wyodrębniania tekstu, konwersji HTML do PDF oraz zaawansowanych zadań związanych z edycją plików PDF. Łatwość obsługi, kompatybilność międzyplatformowa oraz szeroki zakres funkcji sprawiają, że jest to preferowany wybór dla programistów obsługujących profesjonalne procesy związane z plikami PDF.
Aby dowiedzieć się więcej o tym, jak IronPDF przewyższa inne biblioteki, odwiedź oficjalną dokumentację IronPDF.
Często Zadawane Pytania
Jak wyodrębnić tekst z dokumentów PDF za pomocą biblioteki .NET?
Możesz użyć IronPDF do wydajnego wyodrębniania tekstu z dokumentów PDF. IronPDF zapewnia, że wyodrębniony tekst jest dobrze ustrukturyzowany i dokładny, bez konieczności stosowania dodatkowego kodu do formatowania tekstu.
Jakie są ograniczenia korzystania z PDFsharp do wyodrębniania tekstu?
PDFsharp jest przeznaczony przede wszystkim do tworzenia i modyfikowania plików PDF i nie posiada natywnej obsługi wydajnego wyodrębniania tekstu. Może to skutkować fragmentarycznym lub niekompletnym tekstem podczas próby wyodrębniania tekstu ze złożonych dokumentów PDF.
Dlaczego warto wybrać IronPDF zamiast PDFsharp do wyodrębniania tekstu z plików PDF?
IronPDF oferuje solidne możliwości ekstrakcji tekstu, zapewniając dokładne i dobrze ustrukturyzowane wyniki. Obsługuje złożone formaty PDF i nowoczesne .NET Frameworky, co czyni go bardziej wszechstronnym wyborem w porównaniu z PDFsharp do kompleksowych zadań ekstrakcji tekstu.
Czy IronPDF może być używany do tworzenia plików PDF na różnych platformach?
Tak, IronPDF jest kompatybilny z nowoczesnymi frameworkami .NET Framework i obsługuje tworzenie oprogramowania na wielu platformach, takich jak Windows, macOS i Linux. Działa również płynnie z usługami w chmurze, takimi jak Docker, Azure i AWS.
Jakie są alternatywy dla PDFsharp do obsługi ekstrakcji tekstu z plików PDF?
Alternatywami dla PDFsharp w zakresie ekstrakcji tekstu są IronPDF, który oferuje zaawansowane funkcje ekstrakcji tekstu, a także iTextSharp (iText 7) i Pdfium, znane z doskonałej obsługi ekstrakcji i analizy tekstu.
Czy IronPDF nadaje się do profesjonalnej obróbki plików PDF?
Tak, IronPDF to profesjonalna biblioteka .NET, która oferuje szeroki zakres funkcji do generowania, edycji i szyfrowania plików PDF oraz konwersji HTML na PDF, dzięki czemu idealnie nadaje się do zaawansowanych procesów pracy z plikami PDF w profesjonalnych środowiskach.
Jakie są przykłady zastosowań biblioteki takiej jak IronPDF?
IronPDF nadaje się do zastosowań związanych z generowaniem plików PDF, manipulowaniem nimi, wyodrębnianiem tekstu, konwersją HTML do PDF oraz zaawansowanymi zadaniami edycji plików PDF, co czyni go preferowanym wyborem dla programistów potrzebujących niezawodnych i wydajnych rozwiązań do obsługi plików PDF.
Czy istnieje biblioteka, która oferuje zarówno bezpłatne użytkowanie, jak i licencję komercyjną?
IronPDF oferuje bezpłatne użytkowanie do celów programistycznych, a także udostępnia licencje komercyjne dla płatnych planów, dostosowanych do różnych potrzeb projektowych i wymagań zawodowych.













