
QuestPDF: Alternativas ao IronPDF para adicionar números de página a um PDF (Exemplo)
No tutorial de hoje, vamos explorar como extrair texto de documentos PDF usando duas poderosas bibliotecas de PDF, IronPDF e PDFSharp. Vamos aprender como a extração de texto funciona com essas ferramentas sem a necessidade de possuir licenças da biblioteca Adobe, e como elas se comparam entre si.
Existem dezenas de bibliotecas focadas em PDF disponíveis, e ao dedicar um tempo para compará-las e aprender como seus recursos funcionam, você poderá escolher a biblioteca certa para as necessidades do seu projeto. A extração de texto é apenas um dos muitos exemplos de tarefas que você pode precisar realizar em seus PDFs, sendo útil em situações onde você precisa ler ou analisar dados de arquivos PDF de forma eficiente.
PDFSharp
PDFSharp é uma biblioteca .NET open-source projetada para a criação e modificação de documentos PDF programaticamente. Embora sua principal vantagem seja a geração e manipulação de PDFs, ele também oferece ferramentas básicas para leitura de arquivos PDF existentes e extração de conteúdo, quando combinado com as bibliotecas externas adequadas.
O PDFSharp pode fazer mais além da criação de novos documentos PDF em movimento, ele pode ser usado para modificar arquivos PDF existentes, mesclar e dividir documentos, adicionar anotações, e mais.
IronPDF
IronPDF é uma biblioteca .NET de nível profissional projetada para simplificar o processo de trabalho com documentos PDF em C#. É uma ferramenta rica em recursos, projetada para desenvolvedores que criam aplicativos que envolvem geração, manipulação , criptografia, conversão de arquivos PDF , mesclagem de páginas PDF , conversão de HTML para PDF , extração de conteúdo e muito mais.
Com seus recursos robustos, o IronPDF se destaca como uma solução versátil para criar e gerenciar PDFs tanto em projetos de pequena escala quanto em aplicações de nível empresarial.
O IronPDF foi projetado para ser compatível com as versões modernas do .NET Framework, incluindo .NET Core, .NET 5, .NET 6 e .NET 7, bem como com versões antigas como o .NET Framework. Ele funciona perfeitamente em sistemas operacionais como Windows, macOS e Linux, e é totalmente compatível com ambientes Docker, Azure e AWS. Isso garante que os desenvolvedores possam implantar seus fluxos de trabalho em PDF em qualquer plataforma ou serviço em nuvem.
No exemplo de hoje, tentaremos extrair texto deste documento PDF no Visual Studio:
Extrair Texto de um Arquivo PDF Usando PDFSharp
O PDFSharp, em sua versão atual, não possui suporte nativo para extração de texto de documentos PDF. Ele foi projetado principalmente para criar e manipular PDFs, como desenhar gráficos, adicionar conteúdo e mesclar documentos, mas não possui um mecanismo integrado para extrair texto por conta própria, não sendo capaz de lidar com caracteres especiais, codificação avançada e assim por diante. Isso pode gerar textos fragmentados ou incompletos, ou ainda sequências em branco em vez do conteúdo real do PDF. Por exemplo:
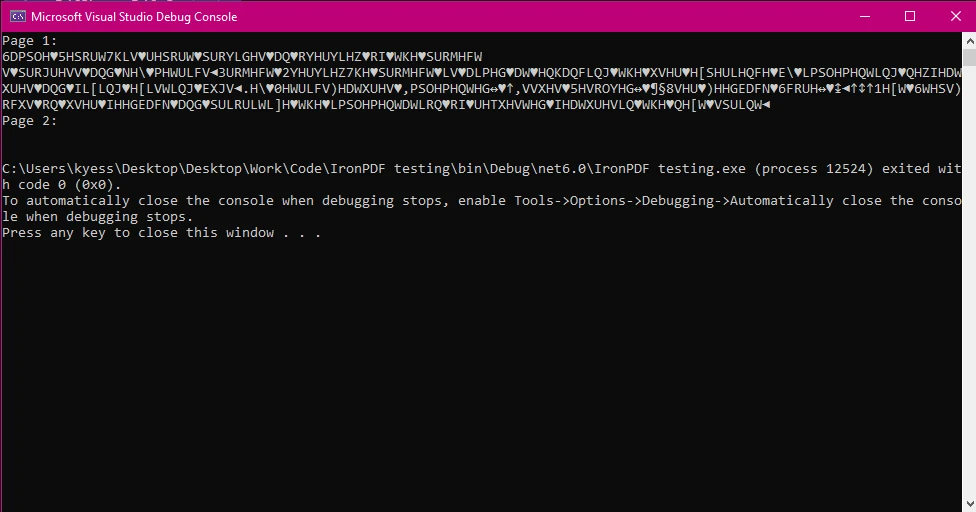
Se você precisar de extração de texto avançada com melhor suporte para diferentes fontes, codificações e layouts, provavelmente precisará usar uma biblioteca mais especializada, como:
-
iText (ou iText): Esta é uma biblioteca popular de PDF com forte suporte para extração e parsing de texto.
- Pdfium: Outra opção que se destaca na extração de texto, especialmente de PDFs com formatação complexa.
Extrair texto de um arquivo PDF usando o IronPDF
Agora, vamos ver como a extração de texto é tratada usando o IronPDF. O recurso de extração de texto do IronPDF oferece aos desenvolvedores um método conciso, porém poderoso, para extrair texto de documentos PDF de forma eficiente, sem a necessidade de código adicional para formatar corretamente a sequência de dados em texto legível.
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Provide the file path to the PDF document
string pdfPath = @"invoice.pdf";
// Load the PDF document using IronPDF
var pdf = PdfDocument.FromFile(pdfPath);
// Extract all text from the PDF
var extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Provide the file path to the PDF document
string pdfPath = @"invoice.pdf";
// Load the PDF document using IronPDF
var pdf = PdfDocument.FromFile(pdfPath);
// Extract all text from the PDF
var extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Provide the file path to the PDF document
Dim pdfPath As String = "invoice.pdf"
' Load the PDF document using IronPDF
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract all text from the PDF
Dim extractedText = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End Class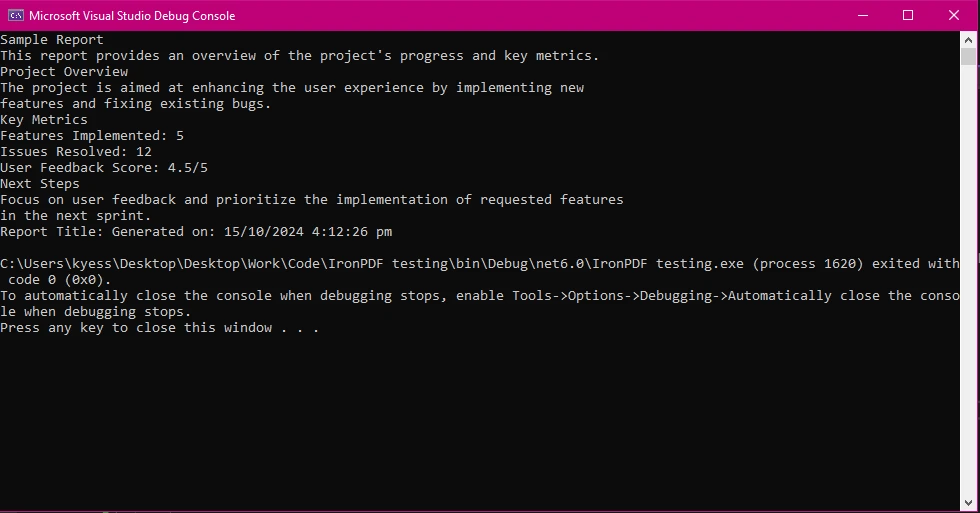
O IronPDF fornece uma API simples e eficiente para extrair texto do caminho do PDF fornecido. Isso garante que o texto extraído seja bem estruturado e preciso, tornando-se uma opção confiável para desenvolvedores que precisam processar conteúdo de PDF em seus aplicativos.
Comparação
O PDFSharp é uma biblioteca gratuita e de código aberto, ideal para a criação e manipulação básica de PDFs, mas possui funcionalidades limitadas e apresenta dificuldades com PDFs complexos. Embora, em teoria, possa ser usado para extrair texto de arquivos PDF, isso exigiria uma análise de texto avançada e poderia resultar em uma saída fragmentada.
O IronPDF oferece uma solução mais robusta com recursos avançados, como extração precisa de texto, conversão de HTML para PDF e suporte para padrões PDF modernos. É otimizado para desempenho e facilidade de uso, com uma API intuitiva. Embora seja gratuito para desenvolvimento, também oferece licenciamento comercial para seus planos pagos.
Conclusão
Tanto o PDFSharp quanto o IronPDF são valiosas ferramentas para trabalhar com extração de texto de PDFs em C#, mas atendem a diferentes casos de uso:
- O PDFSharp é uma ótima opção para desenvolvedores que precisam de uma biblioteca gratuita e de código aberto para criação básica de PDFs e extração de texto. No entanto, suas capacidades de extração de texto são limitadas e podem não atender às necessidades de aplicações mais complexas.
- O IronPDF , por outro lado, destaca-se na extração de texto, conversão de HTML para PDF e tarefas avançadas de edição de PDF. Sua facilidade de uso, compatibilidade entre plataformas e ampla gama de recursos fazem dele a escolha preferida para desenvolvedores que lidam com fluxos de trabalho de PDF de nível profissional.
Para uma análise mais aprofundada de como o IronPDF supera outras bibliotecas, visite a documentação oficial do IronPDF .
Perguntas frequentes
Como posso extrair texto de documentos PDF usando uma biblioteca .NET?
Você pode usar o IronPDF para extrair texto de documentos PDF de forma eficiente. O IronPDF garante que o texto extraído seja bem estruturado e preciso, sem a necessidade de código adicional para formatação.
Quais são as limitações do uso do PDFsharp para extração de texto?
O PDFsharp foi projetado principalmente para criar e modificar PDFs e não oferece suporte nativo para extração eficiente de texto. Isso pode resultar em texto fragmentado ou incompleto ao tentar extrair texto de documentos PDF complexos.
Por que escolher o IronPDF em vez do PDFsharp para extrair texto de PDFs?
O IronPDF oferece recursos robustos de extração de texto, fornecendo resultados precisos e bem estruturados. Ele suporta formatos PDF complexos e frameworks .NET modernos, tornando-se uma opção mais versátil em comparação com o PDFsharp para tarefas abrangentes de extração de texto.
O IronPDF pode ser usado para desenvolvimento de PDFs multiplataforma?
Sim, o IronPDF é compatível com as estruturas .NET modernas e oferece suporte ao desenvolvimento multiplataforma em Windows, macOS e Linux. Ele também funciona perfeitamente com serviços em nuvem como Docker, Azure e AWS.
Quais são algumas alternativas ao PDFsharp para lidar com a extração de texto em PDFs?
Alternativas ao PDFsharp para extração de texto incluem o IronPDF, que oferece recursos avançados de extração de texto, bem como o iTextSharp (iText 7) e o Pdfium, conhecidos pelo seu forte suporte em extração e análise de texto.
O IronPDF é adequado para manipulação de PDFs em nível profissional?
Sim, o IronPDF é uma biblioteca .NET de nível profissional que oferece amplos recursos para geração, manipulação e criptografia de PDFs, além de conversão de HTML para PDF, tornando-o ideal para fluxos de trabalho avançados com PDFs em ambientes profissionais.
Quais são os casos de uso para uma biblioteca como o IronPDF?
O IronPDF é adequado para aplicações que envolvem geração, manipulação, extração de texto, conversão de HTML para PDF e tarefas avançadas de edição de PDF, tornando-se a escolha preferida de desenvolvedores que precisam de soluções de PDF confiáveis e eficientes.
Existe alguma biblioteca que ofereça tanto uso gratuito quanto licença comercial?
O IronPDF oferece uso gratuito para fins de desenvolvimento e também fornece licenciamento comercial para seus planos pagos, atendendo a diversas necessidades de projetos e requisitos profissionais.












