
QuestPDF Wyodrębnij tekst z PDF w C# Alternatywy vs IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against QuestPDF on pricing, HTML support, and licensing.
W tym poradniku przyjrzymy się, jak wyodrębnić tekst z dokumentów PDF (Portable Document Format) w C# używając dwóch różnych bibliotek PDF.
W dzisiejszych czasach nowoczesnego internetu istnieje wiele bibliotek, które są w stanie wyodrębniać tekst i obrazy z plików PDF do odczytu i analizy. Dzisiaj użyjemy dwóch potężnych bibliotek PDF, IronPDF i QuestPDF, aby wyodrębnić tekst z pliku PDF. Porównując, jak te dwie biblioteki radzą sobie z prostym zadaniem wyodrębniania tekstu, możemy określić, która z nich lepiej nadaje się do obsługi zaawansowanych zadań z PDF. Zanim przejdziemy do sekcji porównania, najpierw przyjrzyjmy się krótkim wprowadzeniom dla każdej z bibliotek.
QuestPDF
QuestPDF to nowoczesna, otwartoźródłowa biblioteka generowania PDF zaprojektowana specjalnie dla programistów .NET. Wykorzystuje nowoczesne deklaratywne API, które umożliwia użytkownikom definiowanie i generowanie skomplikowanych układów PDF z dużą elastycznością i precyzją. Chociaż główny cel QuestPDF to generowanie dokumentów, a nie wyodrębnianie tekstu, zapewnia ono czyste, intuicyjne podejście do budowania dokumentów od podstaw i manipulowania różnymi elementami w dokumencie. Czyni to szczególnie odpowiednim dla aplikacji wymagających dostosowanej, dynamicznej zawartości PDF.
IronPDF
IronPDF to wszechstronna biblioteka przetwarzania PDF zaprojektowana, aby ułatwić i uczynić bardziej efektywną pracę z dokumentami PDF w C#. W przeciwieństwie do QuestPDF, IronPDF zostało zbudowane zarówno do generowania, jak i manipulacji PDF. Oferowane funkcje to m.in. szyfrowanie PDF, rozbudowane wsparcie dla edycji i adnotacji istniejących PDF, konwertowanie różnych dokumentów do formatu PDF, dodawanie nagłówków i stopki (które mogą służyć do wyświetlania numerów stron), edycja metadanych dokumentu, wsparcie dla wielowątkowości i asynchroniczności oraz zaawansowane narzędzia konwersji PDF.
Oprócz bogatego zestawu funkcji, IronPDF oferuje pełne wsparcie dla wielu platform, w tym dla .NET 5/6/7, .NET Core i .NET Framework. Jest również w pełni kompatybilny z Windows, macOS, Linux oraz platformami chmurowymi, jak Azure i AWS, co czyni go doskonałym wyborem dla aplikacji .NET na wielu platformach.
W dzisiejszym przykładzie będziemy wyodrębniać tekst z naszego przykładowego dokumentu faktury PDF przy użyciu obu bibliotek.
Najpierw sprawdzimy, czy QuestPDF poradzi sobie z tym zadaniem.
Wyodrębnianie tekstu z pliku PDF za pomocą QuestPDF
Niestety, mimo że QuestPDF świetnie radzi sobie z tworzeniem PDF i niektórymi zadaniami PDF, wyodrębnianie tekstu nie jest jedną z funkcji, które obecnie oferuje. Chociaż QuestPDF nie jest stworzony do wyodrębniania tekstu z istniejących plików PDF, oferuje podstawowe narzędzia do pracy z PDF, które można rozszerzyć do wyodrębniania tekstu za pomocą dodatkowej logiki lub integracji zewnętrznych. Na przykład, QuestPDF można użyć do generowania dokumentów PDF o zorganizowanej strukturze, a następnie zaimplementować własne rozwiązanie do wyodrębniania zawartości na podstawie struktury dokumentu przy użyciu zewnętrznej biblioteki.
Wyodrębnianie tekstu z pliku PDF za pomocą IronPDF
Wyodrębnianie tekstu to tylko jedno z zadań, które IronPDF doskonale wykonuje w pracy z PDF. W zaledwie kilku liniach kodu jesteśmy w stanie wyodrębnić tekst z całego dokumentu PDF. Można to zobaczyć na poniższym przykładzie kodu:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all the text from the loaded PDF document
string text = pdf.ExtractAllText();
// Print the extracted text to the console
Console.WriteLine(text);
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all the text from the loaded PDF document
string text = pdf.ExtractAllText();
// Print the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all the text from the loaded PDF document
Dim text As String = pdf.ExtractAllText()
' Print the extracted text to the console
Console.WriteLine(text)
End Sub
End ClassPlik wyjściowy
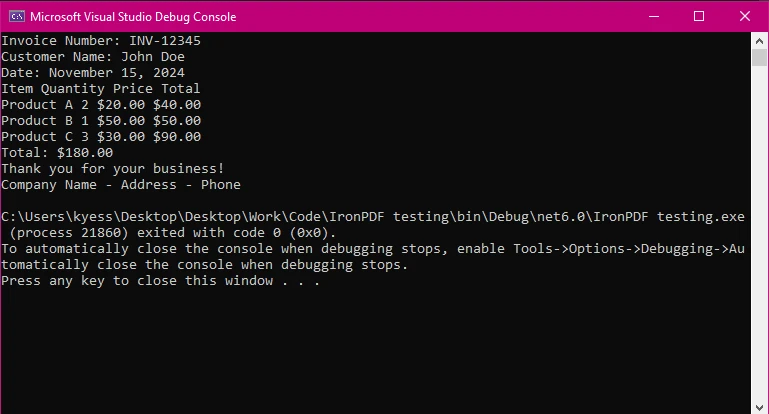
Porównanie
IronPDF oferuje proste API do wyodrębniania tekstu, co czyni je idealnym dla deweloperów skupionych na efektywności. W zaledwie trzech liniach wyodrębniliśmy zawartość tekstową w naszym dokumencie PDF i wyświetliliśmy ją do odczytu. Stąd można łatwo zapisać wyekstrahowany tekst do dalszego użycia lub manipulacji.
Z drugiej strony QuestPDF nie poradził sobie z zadaniem takim jak wyodrębnianie tekstu, ze względu na bardziej ograniczoną liczbę funkcji niż biblioteki takie jak IronPDF. Chociaż może obsługiwać inne zadania, takie jak generowanie PDF i podstawowa manipulacja, do wyodrębniania tekstu konieczna byłaby implementacja zewnętrznych bibliotek.
Wnioski
Jeśli chodzi o wyodrębnianie tekstu, QuestPDF jest darmowy dzięki wykorzystaniu licencji społecznościowej dla projektów prywatnych, ale oferuje również opcję licencji komercyjnych.
Obie biblioteki są dokładne i niezawodne, ale wybór ostatecznie zależy od wymagań projektu.
Aby uzyskać głębsze porównanie tych bibliotek, sprawdź pełny blog na temat IronPDF vs QuestPDF.
Często Zadawane Pytania
Jak wyodrębnić tekst z pliku PDF za pomocą języka C#?
Możesz skorzystać z prostego API IronPDF, aby wydajnie wyodrębnić tekst z dokumentu PDF za pomocą zaledwie kilku linii kodu. Biblioteka ta udostępnia dedykowaną metodę do wyodrębniania tekstu, dzięki czemu idealnie nadaje się do takich zadań.
Jakie jest główne zastosowanie QuestPDF?
QuestPDF służy przede wszystkim do generowania złożonych układów PDF za pomocą nowoczesnego deklaratywnego API. Skupia się na tworzeniu dokumentów, a nie na ich ekstrakcji, przez co mniej nadaje się do wyciągania tekstu z istniejących plików PDF.
Która biblioteka jest zalecana do wyodrębniania tekstu z plików PDF w języku C#?
Do wyodrębniania tekstu z plików PDF w języku C# zaleca się użycie IronPDF ze względu na wydajny i prosty interfejs API zaprojektowany specjalnie do tego celu.
Czy IronPDF obsługuje tworzenie oprogramowania na wiele platform?
Tak, IronPDF obsługuje tworzenie oprogramowania na wiele platform, w tym jest kompatybilny z systemami Windows, macOS, Linux oraz środowiskami chmurowymi, takimi jak Azure i AWS.
Jakie dodatkowe funkcje oferuje IronPDF?
IronPDF oferuje szereg funkcji, w tym szyfrowanie plików PDF, dodawanie adnotacji, konwersję różnych formatów dokumentów do formatu PDF oraz obsługę wielowątkowości.
Czy QuestPDF nadaje się do wyodrębniania tekstu z istniejących dokumentów PDF?
Nie, QuestPDF nie jest przeznaczony do wyodrębniania tekstu z istniejących dokumentów PDF. Służy on głównie do generowania plików PDF, a wyodrębnianie tekstu wymagałoby dodatkowych narzędzi lub niestandardowych rozwiązań.
Czy IronPDF może konwertować HTML na PDF?
Tak, IronPDF może konwertować HTML na PDF przy użyciu metod takich jak RenderHtmlAsPdf dla ciągów HTML oraz RenderHtmlFileAsPdf dla plików HTML.
Jakie licencje są dostępne dla QuestPDF?
QuestPDF oferuje licencję społecznościową dla projektów prywatnych, natomiast licencje komercyjne są dostępne dla innych zastosowań.













