
Qual SDK de PDF em C# você deve escolher para o seu projeto?
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against QuestPDF on pricing, HTML support, and licensing.
Neste tutorial, veremos como extrair texto de documentos PDF (Portable Document Format) em C# usando duas bibliotecas PDF diferentes.
Na era moderna da internet, existem diversas bibliotecas capazes de extrair texto e imagens de arquivos PDF para análise e leitura. Hoje, usaremos duas poderosas bibliotecas de PDF, IronPDF e QuestPDF , para extrair texto de um arquivo PDF. Comparando o desempenho dessas duas bibliotecas em uma tarefa simples de extração de texto, podemos determinar qual delas é mais adequada para lidar com tarefas mais avançadas em PDFs. Antes de entrarmos na seção de comparação, vamos dedicar um momento para uma breve introdução a cada biblioteca.
QuestPDF
QuestPDF é uma biblioteca de geração de PDF de código aberto e de última geração, projetada especificamente para desenvolvedores .NET . Utiliza uma API declarativa moderna que permite aos usuários definir e gerar layouts de PDF complexos com grande flexibilidade e precisão. Embora o foco principal do QuestPDF seja a geração de documentos em vez da extração de texto, ele oferece uma abordagem clara e intuitiva para criar documentos do zero e manipular diferentes elementos dentro do documento. Isso o torna particularmente adequado para aplicações que exigem conteúdo PDF personalizado e dinâmico.
IronPDF
IronPDF é uma biblioteca versátil para processamento de PDFs, projetada para tornar o trabalho com PDFs em C# mais fácil e eficiente. Diferentemente do QuestPDF, o IronPDF foi desenvolvido especificamente para geração e manipulação de PDFs. Entre os recursos oferecidos, destacam-se a criptografia de PDF, amplo suporte para edição e anotação de PDFs existentes, conversão de diversos documentos para o formato PDF, adição de cabeçalhos e rodapés (que podem ser usados para exibir números de página), edição de metadados de documentos, suporte a multithreading e processamento assíncrono, além de ferramentas avançadas de conversão de PDF.
Além de seu rico conjunto de recursos, o IronPDF oferece suporte multiplataforma completo, incluindo compatibilidade com .NET 5/6/7, .NET Core e .NET Framework. Além disso, é totalmente compatível com Windows, macOS, Linux e plataformas em nuvem como Azure e AWS, tornando-se uma ótima opção para aplicativos .NET multiplataforma.
No exemplo de hoje, vamos extrair o texto do nosso documento PDF de fatura de exemplo usando ambas as bibliotecas.
Primeiro, vamos analisar se o QuestPDF consegue lidar com essa tarefa.
Extrair texto de um arquivo PDF usando o QuestPDF
Infelizmente, embora o QuestPDF seja excelente na criação de PDFs e na execução de determinadas tarefas relacionadas a eles, a extração de texto não está entre os recursos que ele oferece atualmente. Embora o QuestPDF não seja inerentemente projetado para extrair texto de arquivos PDF existentes, ele fornece ferramentas básicas para trabalhar com PDFs, que podem ser ampliadas para extração de texto com lógica adicional ou integrações de terceiros. Por exemplo, o QuestPDF pode ser usado para gerar documentos PDF com conteúdo estruturado, e você pode implementar uma solução personalizada para extrair conteúdo com base na estrutura do documento usando uma biblioteca de terceiros.
Extrair texto de um arquivo PDF usando o IronPDF
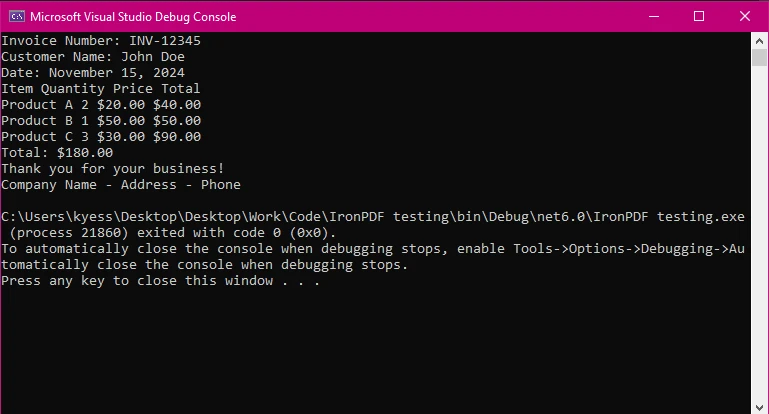
A extração de texto é apenas uma das tarefas em que o IronPDF se destaca ao trabalhar com PDFs. Com apenas algumas linhas de código, conseguimos extrair o texto de um documento PDF inteiro. Isso pode ser visto no seguinte trecho de código:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all the text from the loaded PDF document
string text = pdf.ExtractAllText();
// Print the extracted text to the console
Console.WriteLine(text);
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all the text from the loaded PDF document
string text = pdf.ExtractAllText();
// Print the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all the text from the loaded PDF document
Dim text As String = pdf.ExtractAllText()
' Print the extracted text to the console
Console.WriteLine(text)
End Sub
End ClassArquivo de saída
Comparação
O IronPDF oferece uma API simples para extrair texto, tornando-o ideal para desenvolvedores focados em eficiência. Em apenas três linhas, conseguimos extrair o conteúdo textual do nosso documento PDF e exibi-lo para leitura. A partir daqui, você pode facilmente salvar o texto extraído para uso ou manipulação posterior.
Por outro lado, o QuestPDF não conseguiu lidar com uma tarefa como a extração de texto, devido a um número mais limitado de recursos em comparação com bibliotecas como o IronPDF. Embora possa lidar com outras tarefas, como geração de PDF e manipulação básica, você precisaria implementar bibliotecas externas para extrair texto.
Conclusão
Quanto à extração de texto, QuestPDF é gratuito através do uso de sua licença comunitária para projetos privados, mas também tem a opção de licenças comerciais.
Ambas as bibliotecas são precisas e confiáveis, mas a escolha final depende dos requisitos do seu projeto.
Para uma comparação mais aprofundada dessas bibliotecas, confira o artigo completo sobre IronPDF vs QuestPDF .
Perguntas frequentes
Como posso extrair texto de um PDF usando C#?
Você pode usar a API intuitiva do IronPDF para extrair texto de um documento PDF de forma eficiente com apenas algumas linhas de código. Esta biblioteca oferece um método dedicado para extração de texto, tornando-a ideal para esse tipo de tarefa.
Qual é a principal utilização do QuestPDF?
O QuestPDF é usado principalmente para gerar layouts de PDF complexos com uma API declarativa moderna. Ele se concentra na criação de documentos em vez da extração, o que o torna menos adequado para extrair texto de PDFs existentes.
Qual biblioteca é recomendada para extração de texto em PDF usando C#?
O IronPDF é recomendado para extrair texto de PDFs em C# devido à sua API eficiente e direta, projetada especificamente para essa finalidade.
O IronPDF suporta desenvolvimento multiplataforma?
Sim, o IronPDF oferece suporte ao desenvolvimento multiplataforma, incluindo compatibilidade com Windows, macOS, Linux e ambientes de nuvem como Azure e AWS.
Que funcionalidades adicionais oferece o IronPDF?
O IronPDF oferece uma gama de recursos, incluindo criptografia de PDF, anotações, conversão de vários formatos de documento para PDF e suporte para multithreading, entre outros.
O QuestPDF é adequado para extrair texto de documentos PDF existentes?
Não, o QuestPDF não foi projetado para extrair texto de documentos PDF existentes. Ele se concentra na geração de PDFs, e a extração de texto exigiria ferramentas adicionais ou soluções personalizadas.
O IronPDF consegue converter HTML para PDF?
Sim, o IronPDF pode converter HTML em PDF usando métodos como RenderHtmlAsPdf para strings HTML e RenderHtmlFileAsPdf para arquivos HTML.
Quais licenças estão disponíveis para o QuestPDF?
A QuestPDF oferece uma licença comunitária para projetos privados, enquanto licenças comerciais estão disponíveis para outros casos de uso.












