


Łączenie plików PDF w jeden plik PDF za pomocą języka Python
IronPDF for Python zapewnia proste rozwiazanie do laczenia wielu dokumentow PDF w jeden plik przy uzyciu metody PdfDocument.Merge(), wspierajacej zarówno laczenie dwoch plikow, jak i operacje wsadowe do efektywnego laczenia licznych plikow PDF.
Format PDF, czyli Portable Document Format, jest szeroko stosowany do wyświetlania tekstu i grafiki w spójny sposób na różnych platformach i w różnych aplikacjach. Niezależnie od tego, czy konsolidujesz raporty, łączysz zeskanowane dokumenty, czy tworzysz wieloczęściowe formularze, tworzenie plików PDF łączących treści z różnych źródeł jest powszechnym wymaganiem w aplikacjach biznesowych.
Python oferuje wszechstronność i łatwość użytkowania podczas pracy z różnymi systemami komputerowymi. Jednak obsługa plików PDF źródłowych i strumieni danych wejściowych może stanowić wyzwanie. IronPDF, biblioteka języka Python, zapewnia wygodne rozwiązanie do manipulowania istniejącymi plikami PDF i pracy z nimi.
W tym przewodniku omówiono proces instalacji IronPDF for Python oraz pokazano, jak połączyć wiele dokumentów PDF w jeden plik PDF. Omówimy zarówno podstawowe łączenie dwóch plików, jak i zaawansowane operacje wsadowe służące do łączenia wielu dokumentów.
Szybki start: Łączenie plików PDF w języku Python
- Zainstaluj bibliotekę Python do scalania plików PDF
- Użyj
funkcji RenderHtmlAsPdfdo generowania pojedynczych plików PDF - Zastosuj metodę
Merge,aby połączyć pliki PDF - Zapisz scalony dokument za pomocą
opcji "Zapisz jako" - Połącz wiele plików PDF, tworząc listę i korzystając z
funkcji Merge
Czym jest biblioteka IronPDF for Python?
IronPDF to biblioteka języka Python do operacji na plikach PDF. Umożliwia tworzenie, odczytywanie i edytowanie plików PDF. Dzięki IronPDF możesz tworzyć pliki PDF od podstaw, dostosowywać ich wygląd za pomocą HTML, CSS i JavaScript oraz dodawać metadane, takie jak tytuły i nazwiska autorów. IronPDF umożliwia płynne łączenie wielu plików PDF w jeden plik docelowy bez konieczności korzystania z zewnętrznych frameworków.
Biblioteka zapewnia kompleksową funkcjonalność do obróbki plików PDF, w tym możliwość kompresji plików PDF po scaleniu w celu zmniejszenia rozmiaru pliku, wyodrębniania tekstu ze scalanych dokumentów oraz programowego wypełniania formularzy PDF.
Dlaczego warto używać IronPDF do operacji na plikach PDF?
IronPDF jest kompatybilny z wieloma platformami, obsługując Python 3.x w systemach Windows i Linux. Zapewnia to funkcjonalność niezależnie od środowiska operacyjnego. Biblioteka wewnętrznie obsługuje złożone operacje na plikach PDF, pozwalając programistom skupić się na logice biznesowej, a nie na szczegółach manipulacji plikami PDF na niskim poziomie.
IronPDF zachowuje formatowanie i jakość dokumentów podczas scalania plików PDF, zapewniając, że czcionki, obrazy i układy pozostają nienaruszone w trakcie całego procesu. Obsługuje również zaawansowane funkcje, takie jak podpisy cyfrowe i szyfrowanie w celu zabezpieczenia scalanych dokumentów.
Jak zainstalować IronPDF za pomocą Pip?
Aby zainstalować bibliotekę IronPDF za pomocą pip, należy wykonać następujące polecenie:
```shell :title=Install IronPDF pip install ironpdf
Szczegółowe instrukcje instalacji oraz informacje dotyczące rozwiązywania typowych problemów, takich jak [błędy "Module Not Defined"](https://ironpdf.com/python/troubleshooting/module-not-defined/) lub [problemy z uprawnieniami](https://ironpdf.com/python/troubleshooting/could-not-install-package/), można znaleźć w oficjalnej dokumentacji.
### Jakie instrukcje importu są mi potrzebne?
W skrypcie w języku Python należy umieścić następujące instrukcje importu, aby korzystać z funkcji IronPDF do generowania i scalania plików PDF:
```python
from ironpdf import *
# Optional: Configure license key if you have one
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"W przypadku aplikacji produkcyjnych konieczne będzie skonfigurowanie klucza licencyjnego, aby odblokować pełną funkcjonalność IronPDF.
Jak połączyć dwa pliki PDF w języku Python?
Łączenie plików PDF obejmuje dwa etapy:
- Tworzenie plików PDF
- Połączenie ich w jeden ostateczny plik PDF
Oto kompletny przykład ilustrujący ten proces:
from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
# Merge the PDF documents
merged = PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
# Save the merged document
merged.SaveAs("Merged.pdf")from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
# Merge the PDF documents
merged = PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
# Save the merged document
merged.SaveAs("Merged.pdf")Dlaczego warto używać RenderHtmlAsPdf do generowania plików PDF?
W podanym kodzie tworzone są dwa ciągi HTML, z których każdy reprezentuje treść obejmującą dwie strony. Metoda RenderHtmlAsPdf z IronPDF konwertuje obie lancuchy HTML na oddzielne dokumenty PDF jako obiekty PdfDocument. Takie podejście zapewnia elastyczność w tworzeniu dynamicznych plików PDF na podstawie treści HTML, co jest szczególnie przydatne podczas generowania raportów lub dokumentów z internetowych szablonów. W przypadku bardziej złożonych scenariuszy renderowania HTML zapoznaj się z samouczkiem dotyczącym konwersji HTML do PDF.
Jak działa metoda Merge?
Aby zlaczyc pliki PDF, wykorzystywana jest metoda PdfDocument.Merge. Laczy dwa dokumenty PDF w jeden dokument PDF przez polaczenie zawartosci obiektow PdfDocument do nowego PdfDocument. Metoda przyjmuje listę obiektów PdfDocument i zachowuje kolejność, w jakiej pojawiają się one na liście. Ułatwia to kontrolowanie kolejności stron w ostatecznym, scalonym dokumencie.
Jak zapisać scalony dokument PDF?
Aby zapisać scalony plik PDF w określonej ścieżce docelowej, użyj następującego zwięzłego polecenia:
# Save the merged PDF document
merged.SaveAs("Merged.pdf")
# Optional: Save with compression to reduce file size
merged.CompressImages(90)
merged.SaveAs("Merged_Compressed.pdf")# Save the merged PDF document
merged.SaveAs("Merged.pdf")
# Optional: Save with compression to reduce file size
merged.CompressImages(90)
merged.SaveAs("Merged_Compressed.pdf")Można również zastosować dodatkowe optymalizacje, takie jak kompresja PDF, aby zmniejszyć rozmiar pliku połączonego dokumentu.
Poniżej przedstawiono wynikowy plik PDF:
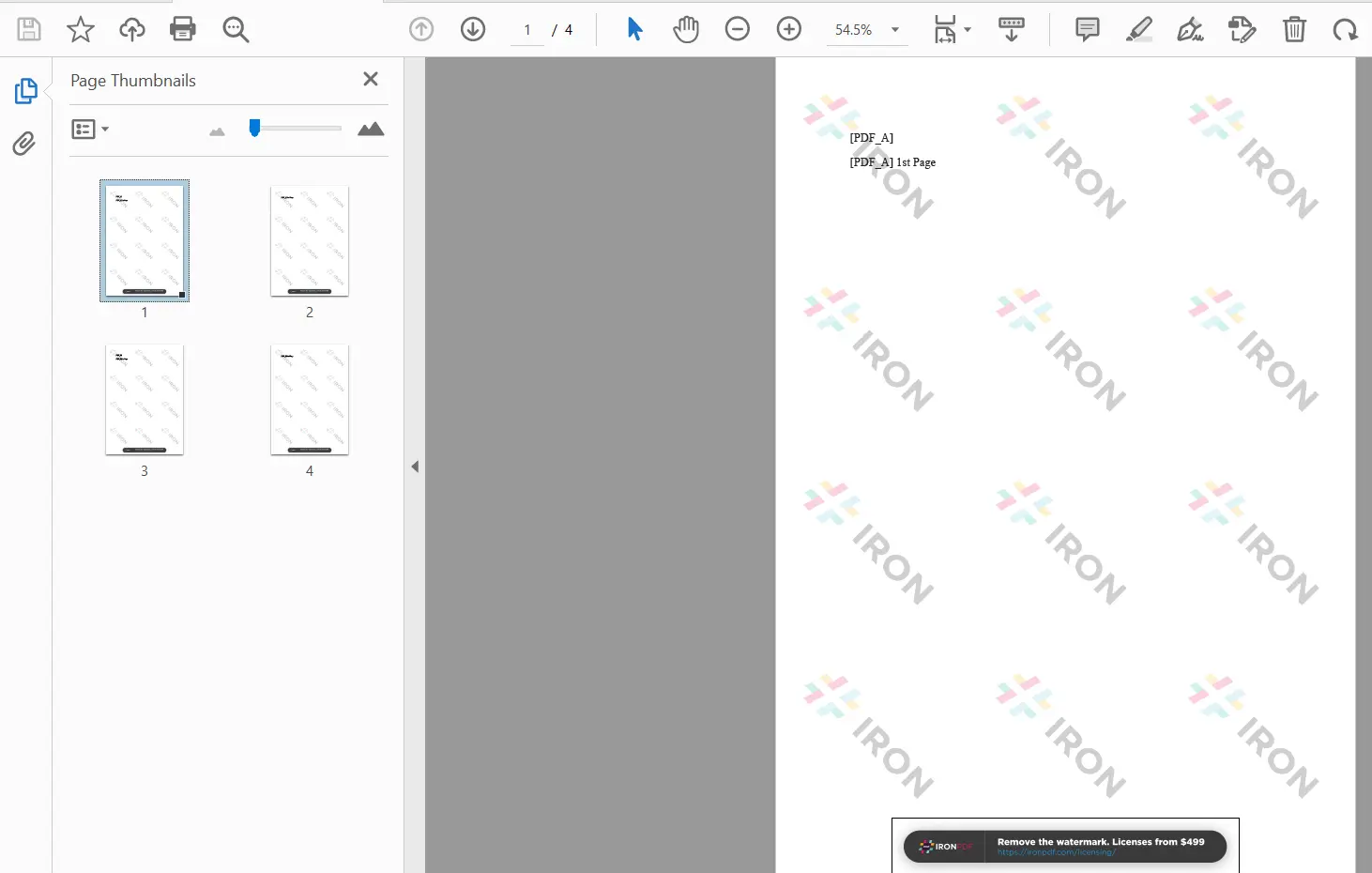
Scal dwa dokumenty PDF
Jak połączyć więcej niż dwa pliki PDF?
Aby połączyć więcej niż dwa dokumenty PDF w języku Python przy użyciu IronPDF, wykonaj te dwa proste kroki:
- Utwórz listę i dodaj obiekty PdfDocument plików PDF, które chcesz połączyć
- Przekaz te liste jako pojedynczy argument do metody
PdfDocument.Merge.
Jak wygląda proces łączenia wielu plików PDF?
Poniższy fragment kodu ilustruje ten proces:
from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# HTML content for the third PDF
html_c = """<p> [PDF_C] </p>
<p> [PDF_C] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_C] 2nd Page</p>"""
# HTML content for the fourth PDF (adding more documents)
html_d = """<p> [PDF_D] </p>
<p> [PDF_D] Content Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_D] Summary Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
pdfdoc_c = renderer.RenderHtmlAsPdf(html_c)
pdfdoc_d = renderer.RenderHtmlAsPdf(html_d)
# List of PDF documents to merge
pdfs = [pdfdoc_a, pdfdoc_b, pdfdoc_c, pdfdoc_d]
# Merge the list of PDFs into a single PDF
pdf = PdfDocument.Merge(pdfs)
# Save the merged PDF document
pdf.SaveAs("merged_multiple.pdf")
# Optional: Add metadata to the merged document
pdf.MetaData.Author = "IronPDF Python"
pdf.MetaData.Title = "Merged Document Collection"
pdf.SaveAs("merged_with_metadata.pdf")from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# HTML content for the third PDF
html_c = """<p> [PDF_C] </p>
<p> [PDF_C] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_C] 2nd Page</p>"""
# HTML content for the fourth PDF (adding more documents)
html_d = """<p> [PDF_D] </p>
<p> [PDF_D] Content Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_D] Summary Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
pdfdoc_c = renderer.RenderHtmlAsPdf(html_c)
pdfdoc_d = renderer.RenderHtmlAsPdf(html_d)
# List of PDF documents to merge
pdfs = [pdfdoc_a, pdfdoc_b, pdfdoc_c, pdfdoc_d]
# Merge the list of PDFs into a single PDF
pdf = PdfDocument.Merge(pdfs)
# Save the merged PDF document
pdf.SaveAs("merged_multiple.pdf")
# Optional: Add metadata to the merged document
pdf.MetaData.Author = "IronPDF Python"
pdf.MetaData.Title = "Merged Document Collection"
pdf.SaveAs("merged_with_metadata.pdf")Czym różni się scalanie oparte na listach?
W powyższym kodzie generowanych jest wiele dokumentów PDF przy użyciu metody renderowania HTML. W celu przechowywania tych plików PDF tworzona jest nowa kolekcja list. Lista ta jest następnie przekazywana jako pojedynczy argument do metody merge, co powoduje połączenie plików PDF w jeden dokument. To podejście jest wysoce skalowalne i pozwala efektywnie obsługiwać dziesiątki, a nawet setki plików PDF.
W bardziej zaawansowanych scenariuszach może zaistnieć potrzeba scalania istniejących plików PDF z dysku. Oto jak to zrobić:
# Load existing PDF files from disk
existing_pdf1 = PdfDocument.FromFile("report1.pdf")
existing_pdf2 = PdfDocument.FromFile("report2.pdf")
existing_pdf3 = PdfDocument.FromFile("report3.pdf")
# Merge existing PDFs
merged_existing = PdfDocument.Merge([existing_pdf1, existing_pdf2, existing_pdf3])
# Save the result
merged_existing.SaveAs("merged_reports.pdf")# Load existing PDF files from disk
existing_pdf1 = PdfDocument.FromFile("report1.pdf")
existing_pdf2 = PdfDocument.FromFile("report2.pdf")
existing_pdf3 = PdfDocument.FromFile("report3.pdf")
# Merge existing PDFs
merged_existing = PdfDocument.Merge([existing_pdf1, existing_pdf2, existing_pdf3])
# Save the result
merged_existing.SaveAs("merged_reports.pdf")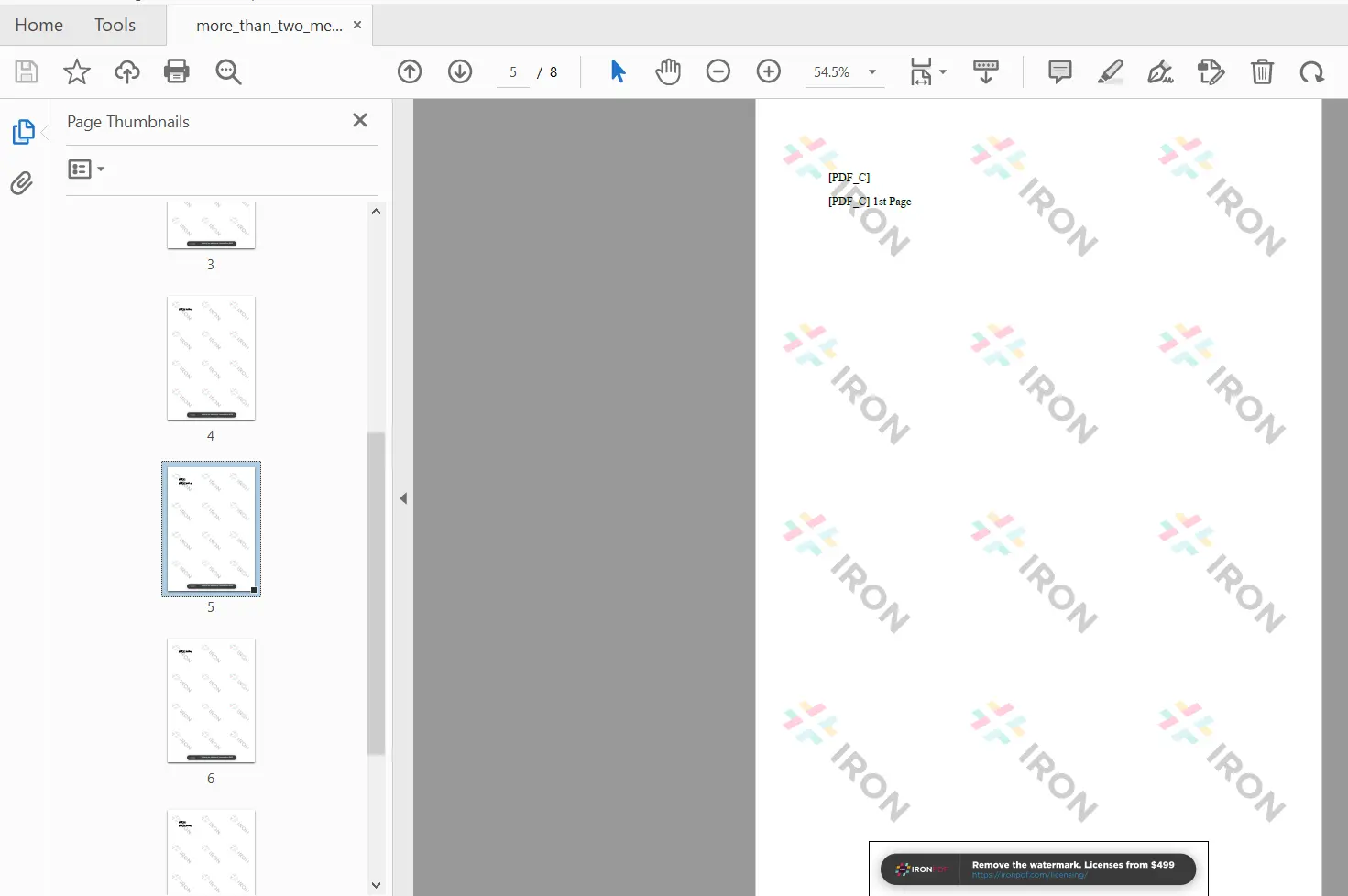
Łączenie więcej niż dwóch plików PDF
Jakie są najważniejsze wnioski?
Ten artykuł zawiera kompleksowy przewodnik dotyczący scalania plików PDF przy użyciu biblioteki IronPDF for Python.
Zaczniemy od omówienia procesu instalacji IronPDF for Python. Następnie omówimy proste podejście do generowania plików PDF przy użyciu metod renderowania HTML. Dodatkowo pokazujemy, jak połączyć dwa lub więcej pliki PDF w jeden plik PDF. Biblioteka obsługuje również zaawansowane funkcje, takie jak dodawanie nagłówków i stopek do połączonych dokumentów lub stosowanie znaków wodnych w celach brandingowych.
Dlaczego warto wybrać IronPDF for Python do operacji na plikach PDF?
Dzięki wydajności i precyzji działania IronPDF jest doskonałym wyborem do pracy z plikami PDF w języku Python. Biblioteka umożliwia płynną konwersję z HTML/URL/String do PDF. Obsługuje popularne typy dokumentów, takie jak HTML, CSS, JS, JPG i PNG, zapewniając tworzenie wysokiej jakości dokumentów PDF. Zbudowany przy użyciu najnowszych technologii, IronPDF zapewnia niezawodne rozwiązanie do zadań związanych z plikami PDF w języku Python.
Biblioteka oferuje również zaawansowane funkcje, takie jak równoległe generowanie plików PDF dla scenariuszy wymagających wysokiej wydajności oraz przetwarzanie asynchroniczne dla operacji nieblokujących, dzięki czemu nadaje się zarówno do aplikacji desktopowych, jak i usług internetowych.
Gdzie mogę znaleźć więcej zasobów?
Aby uzyskać więcej informacji na temat wykorzystania IronPDF for Python, zapoznaj się z naszą obszerną kolekcją przykładów kodu. Jeśli szukasz konkretnych zadań związanych z obsługą plików PDF, zapoznaj się z naszymi przewodnikami dotyczącymi dzielenia plików PDF, konwersji plików PDF na obrazy lub drukowania plików PDF.
IronPDF oferuje bezpłatne użytkowanie do celów programistycznych oraz opcje licencyjne dla zastosowań komercyjnych. Szczegółowe informacje na temat licencji można znaleźć pod poniższym linkiem.
Pobierz oprogramowanie.
Często Zadawane Pytania
Jak połączyć wiele plików PDF w jeden za pomocą języka Python?
IronPDF for Python zapewnia proste rozwiązanie wykorzystujące metodę PdfDocument.Merge(). Można zainstalować IronPDF, utworzyć lub załadować dokumenty PDF, a następnie użyć metody Merge, aby połączyć je w jeden plik. Biblioteka obsługuje zarówno scalanie dwóch plików, jak i operacje wsadowe, umożliwiające wydajne łączenie wielu plików PDF.
Jakie są podstawowe kroki, aby połączyć pliki PDF w języku Python?
Podstawowe kroki to: 1) Zainstaluj bibliotekę IronPDF for Python, 2) Użyj metody RenderHtmlAsPdf do wygenerowania pojedynczych plików PDF lub załadowania istniejących plików PDF, 3) Zastosuj metodę Merge, aby połączyć pliki PDF, 4) Zapisz połączony dokument za pomocą metody SaveAs. W przypadku wielu plików PDF możesz utworzyć listę i użyć metody Merge, aby połączyć je wszystkie jednocześnie.
Czy scalanie plików PDF pozwala zachować oryginalną jakość i formatowanie dokumentu?
Tak, IronPDF zachowuje formatowanie i jakość dokumentów podczas łączenia plików PDF. Biblioteka zapewnia, że czcionki, obrazy i układy pozostają nienaruszone podczas całego procesu łączenia, zachowując oryginalny wygląd każdego dokumentu w ostatecznym, połączonym pliku PDF.
Czy mogę wykonywać dodatkowe operacje na połączonych plikach PDF?
Oczywiście! IronPDF oferuje szeroki zakres funkcji wykraczających poza łączenie plików. Po połączeniu plików PDF można skompresować połączony dokument, aby zmniejszyć rozmiar pliku, wyodrębnić tekst z połączonego pliku, wypełnić formularze PDF programowo, a nawet dodać podpisy cyfrowe do końcowego dokumentu.
Czy biblioteka do łączenia plików PDF w języku Python jest kompatybilna z różnymi platformami?
Tak, IronPDF jest kompatybilny z wieloma platformami i obsługuje Python 3.x zarówno w systemach operacyjnych Windows, jak i Linux. Zapewnia to spójną funkcjonalność niezależnie od środowiska operacyjnego, dzięki czemu nadaje się do różnorodnych scenariuszy programistycznych.
Co sprawia, że to podejście jest lepsze niż korzystanie z zewnętrznych frameworków?
IronPDF umożliwia płynne łączenie wielu plików PDF w jeden plik docelowy bez konieczności korzystania z zewnętrznych frameworków. Biblioteka wewnętrznie obsługuje złożone operacje na plikach PDF, pozwalając programistom skupić się na logice biznesowej, a nie na szczegółach manipulacji plikami PDF na niskim poziomie, co skutkuje czystszym i łatwiejszym w utrzymaniu kodem.


Wciąż przewijasz?
Czy chcesz szybko dowodu?
Uruchom przykład i zobacz, jak Twój kod HTML zamienia się w plik PDF.












