
pyarrow (How It Works For Developers)
PyArrow is a powerful library that provides a Python interface to the Apache Arrow framework. Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. PyArrow is basically the Apache Arrow Python Bindings realized as a Python package. PyArrow enables efficient data interchange and interoperability between different data processing systems and programming languages. Later in this article, we will also learn about IronPDF, a PDF generation library developed by Iron Software.
Key Features of PyArrow
Columnar Memory Format:
PyArrow uses a columnar memory format, which is highly efficient for in-memory analytic operations. This format allows for better CPU cache utilization and vectorized operations, making it ideal for data processing tasks. PyArrow can read and write efficiently to parquet file structures due to its columnar nature.
- Interoperability: One of the main advantages of PyArrow is its ability to facilitate data interchange between different programming languages and systems without the need for serialization or deserialization. This is particularly useful in environments where multiple languages are used, such as data science and machine learning.
- Integration with Pandas: PyArrow can be used as a backend for Pandas, allowing for efficient data manipulation and storage. Starting from Pandas 2.0, it is possible to store data in Arrow arrays instead of NumPy arrays, which can lead to performance improvements, especially when dealing with string data.
- Support for Various Data Types: PyArrow supports a wide range of data types, including primitive types (integers, floating-point numbers), complex types (structs, lists), and nested types. This makes it versatile for handling different kinds of data.
- Zero-Copy Reads: PyArrow allows for zero-copy reads, meaning that data can be read from the Arrow memory format without copying it. This reduces memory overhead and increases performance.
Installation
To install PyArrow, you can use either pip or conda:
pip install pyarrowpip install pyarrowor
conda install pyarrow -c conda-forgeconda install pyarrow -c conda-forgeBasic Usage
We are using Visual Studio Code as the code editor. Begin by creating a new file, pyarrowDemo.py.
Here is a simple example of how to use PyArrow to create a table and perform some basic operations:
import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)import pyarrow as pa
import pyarrow.dataset as pt
# Create a PyArrow table
data = [
pa.array([1, 2, 3]),
pa.array(['a', 'b', 'c']),
pa.array([1.1, 2.2, 3.3])
]
table = pa.Table.from_arrays(data, names=['col1', 'col2', 'col3'])
# Display the table
print(table)Code Explanation
The Python code uses PyArrow to create a table (pa.Table) from three arrays (pa.array). It then prints the table, displaying columns named 'col1', 'col2', and 'col3', each containing corresponding data of integers, strings, and floats.
OUTPUT

Integration with Pandas
PyArrow can be seamlessly integrated with Pandas to enhance performance, especially when dealing with large datasets. Here’s an example of converting a Pandas DataFrame to a PyArrow Table:
import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)import pandas as pd
import pyarrow as pa
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)Code Explanation
The Python code converts a Pandas DataFrame into a PyArrow table (pa.Table) and then prints the table. The DataFrame consists of three columns (col1, col2, col3) with integer, string, and float data.
OUTPUT

Advanced Features
1. File Formats
PyArrow supports reading and writing various file formats such as Parquet and Feather. These formats are optimized for performance and are widely used in data processing pipelines.
2. Memory Mapping
PyArrow supports memory-mapped file access, which allows for efficient reading and writing of large datasets without loading the entire dataset into memory.
3. Interprocess Communication
PyArrow provides tools for interprocess communication, enabling efficient data sharing between different processes.
Introducing IronPDF
IronPDF is a library for Python that facilitates working with PDF files, enabling tasks such as creating, editing, and manipulating PDF documents programmatically. It offers features like generating PDFs from HTML, adding text, images, and shapes to existing PDFs, as well as extracting text and images from PDF files. Here are some of the key features:
PDF Generation from HTML
IronPDF can easily convert HTML files, HTML strings, and URLs into PDF documents. Utilize the Chrome PDF renderer to render webpages directly into PDF format.
Cross-Platform Compatibility
IronPDF is compatible with Python 3+ and operates seamlessly across Windows, Mac, Linux, and Cloud Platforms. It is also supported in .NET, Java, Python, and Node.js.
Editing and Signing Capabilities
Enhance PDF documents by setting properties, adding security features like passwords and permissions, and applying digital signatures.
Custom Page Templates and Settings
With IronPDF, you can tailor PDFs with customizable headers, footers, page numbers, and adjustable margins. It supports responsive layouts and allows for setting custom paper sizes.
Standards Compliance
IronPDF is compliant with PDF standards, including PDF/A and PDF/UA. It supports UTF-8 character encoding and seamlessly handles assets such as images, CSS styles, and fonts.
Generate PDF Documents using IronPDF and PyArrow
IronPDF Prerequisites
- IronPDF uses .NET 6.0 as its underlying technology. So, you need to have the .NET 6.0 runtime installed on your system.
- Python 3.0+: You need to have Python version 3 or later installed.
- pip: Install the Python package installer pip for IronPDF package installation.
Install necessary libraries:
pip install pyarrow
pip install ironpdfpip install pyarrow
pip install ironpdfThen add the below code to demonstrate the usage of IronPDF and PyArrow Python packages:
import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
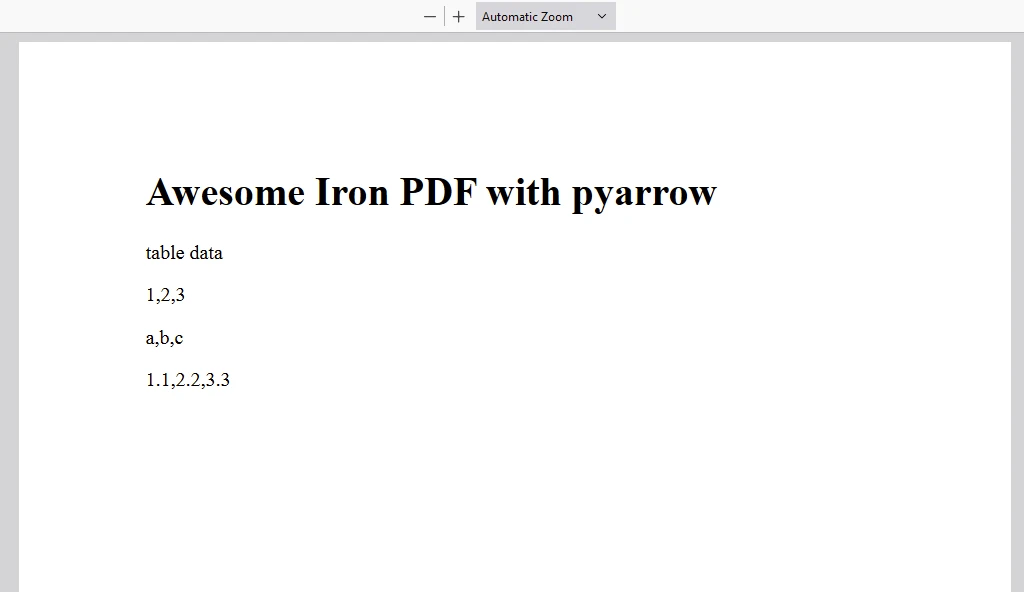
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")import pandas as pd
import pyarrow as pa
from ironpdf import *
# Apply your license key
License.LicenseKey = "license"
# Create a Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [1.1, 2.2, 3.3]
})
# Convert the DataFrame to a PyArrow Table
table = pa.Table.from_pandas(df)
# Display the table
print(table)
#create a PDF renderer
renderer = ChromePdfRenderer()
# Create a PDF from an HTML string using Python
content = "<h1>Awesome Iron PDF with pyarrow</h1>"
content += "<p>table data</p>"
# Iterate over table rows
for row in table:
# Access specific values in a row
value_in_column1 = row[0]
value_in_column2 = row[1]
value_in_column3 = row[2]
# Append row data to content
content += "<p>"+str(value_in_column1)+","+str(value_in_column2)+","+str(value_in_column3)+"</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export to a file or stream
pdf.SaveAs("DemoPyarrow.pdf")Code Explanation
The script demonstrates integrating Pandas, PyArrow, and IronPDF libraries to create a PDF document from data stored in a Pandas DataFrame:
Pandas DataFrame Creation:
- Create a Pandas DataFrame (
df) with three columns (col1,col2,col3) containing numerical and string data.
- Create a Pandas DataFrame (
Conversion to PyArrow Table:
- Converts the Pandas DataFrame (
df) into a PyArrow Table (table) using thepa.Table.from_pandas()method. This conversion facilitates efficient data handling and interoperability with Arrow-based applications.
- Converts the Pandas DataFrame (
PDF Generation with IronPDF:
- Uses IronPDF's ChromePdfRenderer and calls its RenderHtmlAsPdf method to generate a PDF document (
DemoPyarrow.pdf) from an HTML string (content), which includes headers and data extracted from the PyArrow Table (table).
- Uses IronPDF's ChromePdfRenderer and calls its RenderHtmlAsPdf method to generate a PDF document (
OUTPUT

OUTPUT PDF
IronPDF License
Place the License Key at the start of the script before using the IronPDF package:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"Conclusion
PyArrow is a versatile and powerful library that enhances the capabilities of Python for data processing tasks. Its efficient memory format, interoperability features, and integration with Pandas make it an essential tool for data scientists and engineers. Whether you are working with large datasets, performing complex data manipulations, or building data processing pipelines, PyArrow offers the performance and flexibility needed to handle these tasks effectively. On the other hand, IronPDF is a robust Python library that simplifies the creation, manipulation, and rendering of PDF documents directly from Python applications. It seamlessly integrates with existing Python frameworks, allowing developers to generate and customize PDFs dynamically. Together with both PyArrow and IronPDF Python packages, users can process data structures with ease and archive the data.
IronPDF also provides comprehensive documentation to aid developers in getting started, accompanied by numerous code examples that showcase its powerful capabilities. For further details, please visit the documentation and code examples pages.
















