
Best Python Libraries for PDF Processing
Python programming offers multiple Python libraries for almost every task you can imagine. From natural language processing to text analytics, the ecosystem is vibrant. However, when dealing with PDF document files such as generating PDF documents, the choices for pure Python libraries can be overwhelming. Finding the best Python PDF file library is crucial for data scientists, programmers, or anyone looking to manipulate PDF files or create PDF documents.
This article will compare three pure Python PDF processing libraries: IronPDF, PyPDF2, and ReportLab. We'll delve into their features, pros and cons, and licensing options to help you make an informed decision on how to write PDF files in Python.
IronPDF - A Modern Python PDF Library
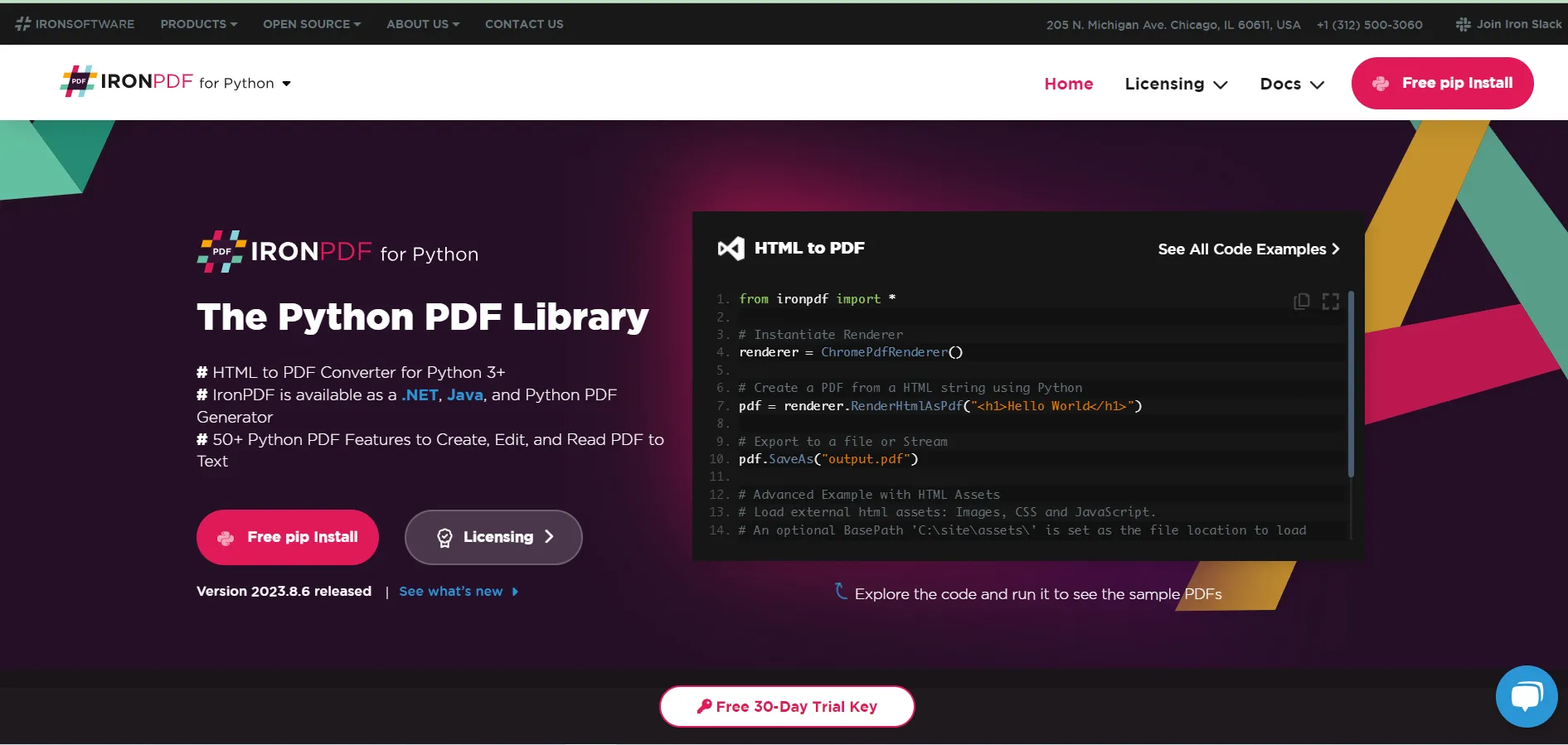 IronPDF is a pure Python PDF library that empowers developers to create, manipulate, and process PDF files with or without structured data effortlessly. With IronPDF, you can generate PDFs from scratch, merge different types of PDF files, overlay text and images, and even extract crucial data. Designed to accommodate a wide range of tasks, IronPDF is a comprehensive tool and one of the popular Python libraries for anyone looking to manage PDF documents using the Python programming language.
IronPDF is a pure Python PDF library that empowers developers to create, manipulate, and process PDF files with or without structured data effortlessly. With IronPDF, you can generate PDFs from scratch, merge different types of PDF files, overlay text and images, and even extract crucial data. Designed to accommodate a wide range of tasks, IronPDF is a comprehensive tool and one of the popular Python libraries for anyone looking to manage PDF documents using the Python programming language.
Built for versatility, IronPDF is based on the Chromium web browser engine. This underlying technology allows it to render HTML and CSS accurately, enabling developers to convert intricate web pages with dynamic content and interactive elements into high-fidelity PDF documents.
The library is packaged as a Python package and is easily installable via pip. Once added as a dependency, integrating IronPDF into your Python project becomes a breeze. What's more, IronPDF offers robust documentation, providing a treasure trove of resources such as tutorials, API references, and a comprehensive knowledge base to help you get the most out of the library.
IronPDF Pros & Cons
Pros
Feature-Rich: IronPDF stands head and shoulders above many other Python PDF libraries regarding functionality. It offers various features for creating data-driven PDFs, editing, and manipulating PDF files. This includes but is not limited to support for multiple PDF standards and formats and a unique capability to convert HTML to PDF.
Ease of Use: With just a few lines of Python code, you can generate PDF documents, convert PDFs to intermediate formats, extract text, and more.
Highly Customizable: The library offers many options to transform PDF files, from rotating PDF pages to converting them to different data formats.
- Compatibility: While this article focuses on IronPDF's capabilities within the Python programming language, it's worth noting that IronPDF is also available for .NET and Java developers. This cross-language availability makes it a versatile choice for teams working on multi-stack projects.
Cons
Price: IronPDF is a paid library, which might be a limiting factor for small projects or independent developers.
- Learning Curve: While it is feature-rich, it may take some time to explore all its functionalities.
Licensing
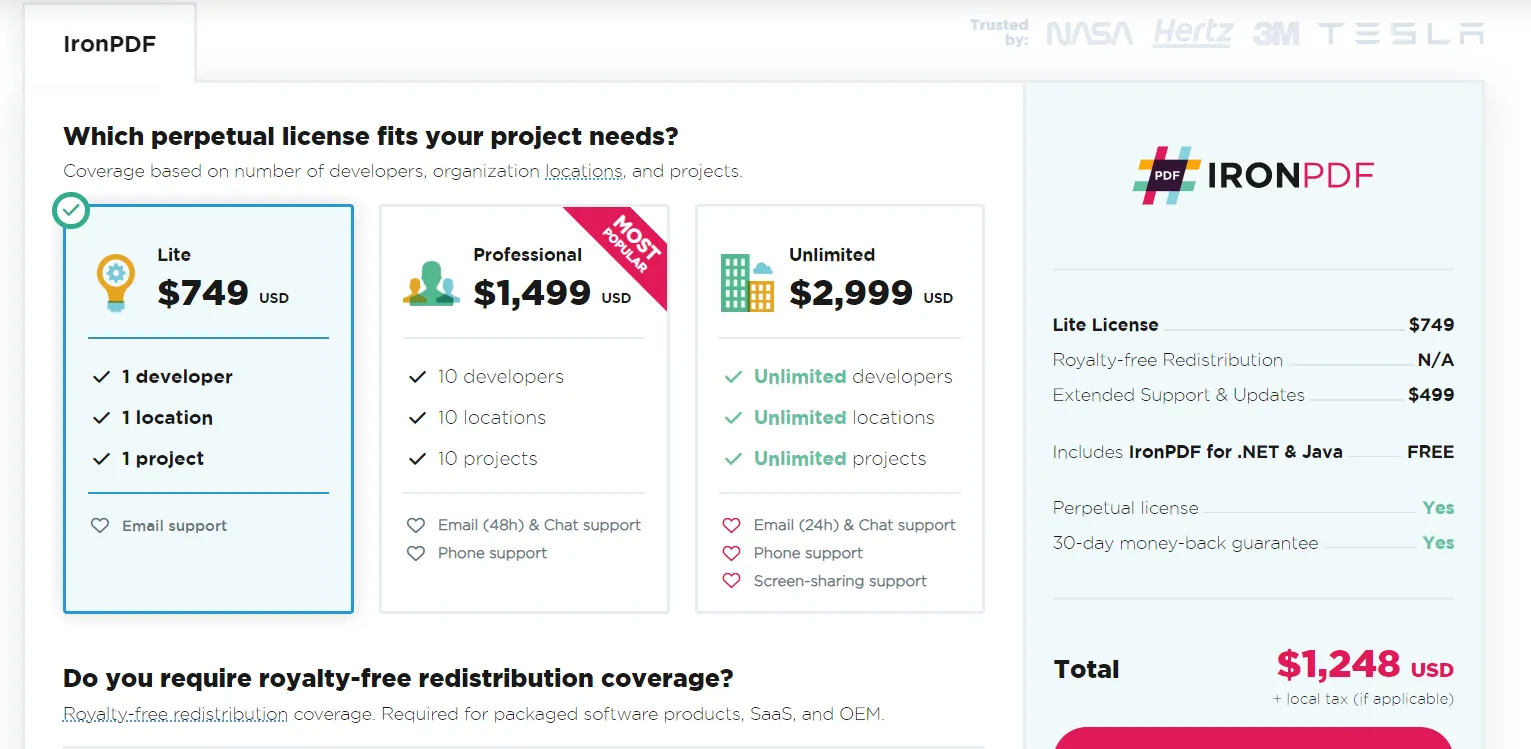
IronPDF offers a commercial license, which starts at $799 for a single developer license. This license grants developers the right to use IronPDF in many web, desktop, or server-side applications. Moreover, this license has free updates and support for one year, ensuring you stay current with all the latest features and improvements.
IronPDF offers a free trial to let developers test the waters. You can evaluate all the features during this period, from generating data-driven PDF documents and extracting text to integrating text analytics libraries. The trial includes all the functionalities of the commercial license, giving you a comprehensive understanding of what you are investing in.
PyPDF2 - The Lightweight Champ for Quick and Easy PDF Processing
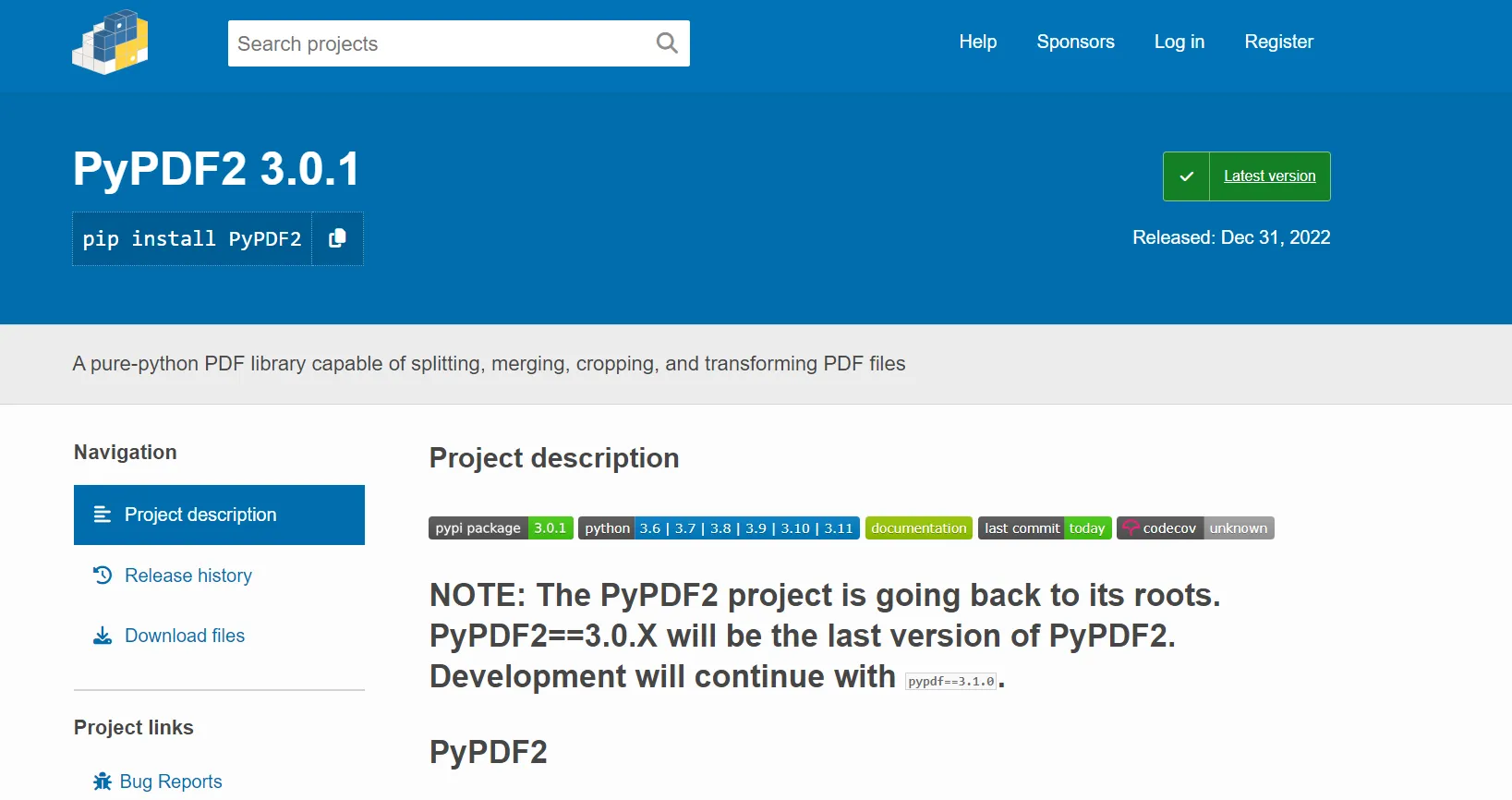
PyPDF2 offers a more minimalistic approach than other Python PDF libraries, but don't let its size fool you. Designed for the Python programmer who needs to get PDF-related tasks done without the bells and whistles, PyPDF2 focuses on providing the most commonly required functionalities like splitting, merging, and text extraction.
Pros
Small Footprint: PyPDF2 is lightweight and easily integrated into any Python environment.
Versatile: With features that cover everything from splitting PDF pages and merging PDF files to extracting text, it's a versatile tool for simple tasks.
- Free: No strings attached; PyPDF2 is entirely free, which makes it great for small projects.
Cons
Limited Customization: PyPDF2 lacks customization options for generating data-driven PDF documents.
- No Built-in Text Analytics: For analyzing text data, manual integration with other analytics libraries is required.
Licensing
PyPDF2 is distributed under the MIT license, a permissive free software license. This means you can use, modify, and distribute the library even for commercial purposes. The MIT license allows you to use PyPDF2 in any project without worrying about costs or restrictions.
While PyPDF2 is free to use, it's worth noting that it doesn't offer the kind of official support or regular updates that come with a commercial license like IronPDF. Nevertheless, extensive community support can often fill that void.
ReportLab
ReportLab is like the grand master of Python PDF libraries, having been in the game for decades. With age comes experience, and ReportLab has been at the forefront of providing a diverse set of PDF functionalities, ranging from generating complex tabular data layouts to advanced graphic elements. If you're looking for a library with a proven track record and many features, ReportLab merits serious consideration.
Pros
Feature-Rich: ReportLab is a powerhouse of features, from handling tabular data to incorporating graphical elements in PDFs.
Community Support: Its longstanding presence means a rich community of users and abundant tutorials are available.
- Text Analytics Integration: Much like IronPDF, ReportLab can integrate with text analytics libraries for advanced text data manipulation.
Cons
Complexity: Its extensive feature set can make it intimidating for newcomers.
- Less Modern Interface: While robust, the API is less intuitive than some modern offerings like IronPDF.
Licensing
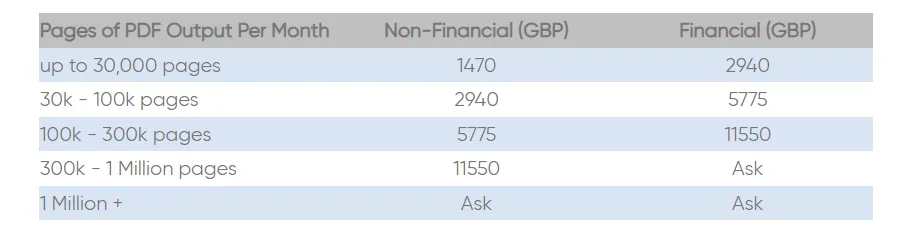
ReportLab takes a unique approach to licensing with its ReportLab PLUS licenses, which are available on an annual lease. Unlike other licensing models that charge based on the number of software installations, ReportLab's fees are determined by the volume of PDF output pages you generate each month. This model allows you to run multiple copies of the software within your organization if you stay within the purchased usage allowance.
Here's a quick rundown of their pricing structure:
- Up to 30,000 pages: £1,470 for Non-Financial Organizations, £2,940 for Financial Organizations
- 30,000 - 100,000 pages: £2,940 for Non-Financial Organizations, £5,775 for Financial Organizations
- 100,000 - 300,000 pages: £5,775 for Non-Financial Organizations, £11,550 for Financial Organizations
- 300,000 - 1 Million pages: £11,550 for Non-Financial Organizations, Custom Pricing for Financial Organizations
- 1 Million+ pages: Custom Pricing for both Non-Financial and Financial Organizations
Conclusion
While all three libraries offer valuable features for anyone looking to process PDF files, IronPDF stands out for its ease of use, data-driven capabilities, and text analytics integration. Despite being a paid library, its range of functionalities is worth the investment, especially for businesses or data scientists dealing with complex PDF processing tasks.
So, if you're looking for a Python PDF library that balances advanced features and ease of use, IronPDF is your best option. With it, you can effortlessly manipulate PDF files, convert them to different formats, and much more, making it the best Python PDF library for comprehensive PDF processing.
















