
解析C#(開發者如何理解其工作)
在 C# 中處理資料時,開發人員經常需要將數字的文字表示轉換為整數。 這項稱為"解析整數"的任務對於各種應用程式都非常重要,從處理使用者輸入到從 PDF 等檔案中擷取資料。 雖然 C# 提供了強大的 解析整數的方法,但在處理非結構化或半結構化資料(例如 PDF 中的資料)時,過程可能會變得更加複雜。
這就是 IronPDF 的用武之地,IronPDF 是專為 .NET 開發人員設計的強大 PDF 函式庫。 使用 IronPDF,您可以從 PDF 中提取文字,並利用 C# 的解析功能將這些文字轉換為可用的數值資料。 無論您是分析發票、報告或表單,結合 C# 的解析工具與 IronPDF,都能簡化 PDF 資料的處理,讓您將字串格式的數字轉換成整數。
在本文中,我們將深入探討 ParseInt 如何在 C# 中用於將數字的字串表示轉換為整數,以及 IronPDF 如何簡化從 PDF 中提取和解析數值資料的流程。
什麼是 C# 中的 ParseInt?
解析整數的基礎知識
在 C# 中,將字串值(例如"123")轉換為整數通常使用 int.Parse() 或 Convert.ToInt32() 來完成。 這些方法可以幫助開發人員將文字資料轉換成可用的數值,以便進行計算和驗證。
- int.Parse(string s):將字串轉換為整數。 如果字串不是有效的整數,會產生異常。
- Convert.ToInt32(string s):將字串轉換為整數,對空輸入進行特殊處理。
以下是使用 int.Parse() 轉換字串的範例:
string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123Dim numberString As String = "123"
' Convert the string to an integer using int.Parse
Dim num As Integer = Integer.Parse(numberString)
Console.WriteLine(num) ' Output: 123或者,使用 Convert 類別:
string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123Dim numericString As String = "123"
' Convert the string to an integer using Convert.ToInt32
Dim result As Integer = Convert.ToInt32(numericString)
Console.WriteLine(result) ' Outputs: 123Convert 類別可讓您安全地轉換字串和其他資料類型。 當字串變數可能表示空值或無效值時,它尤其有用,因為 Convert.ToInt32() 傳回預設值(本例中為 0),而不是拋出例外。
預設值與錯誤處理
將字串轉換為整數時,開發人員經常面臨的一個問題是處理無效或非數字輸入。 如果數字的字串表示形式不正確,則類似 int.Parse() 的方法會拋出例外。 但是,Convert.ToInt32() 具有針對無效字串的內建回退機制。
以下是一個範例,示範解析時如何處理預設值:
string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0Dim invalidString As String = "abc"
' Convert will return 0 instead of throwing an exception for invalid input
Dim result As Integer = Convert.ToInt32(invalidString)
Console.WriteLine(result) ' Outputs: 0如果您想要更有控制地轉換字串,可以使用 int.TryParse(),它會回傳一個布林值,表示轉換是否成功:
string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}Dim invalidInput As String = "abc"
' Attempt to parse using TryParse, which avoids exceptions for invalid input
Dim result As Integer
If Integer.TryParse(invalidInput, result) Then
Console.WriteLine(result)
Else
Console.WriteLine("Parsing failed.")
End If在這種情況下,TryParse() 使用 out 參數來儲存轉換後的整數,這使得該方法能夠在不拋出異常的情況下傳回一個值。 如果轉換失敗,else 語句將會執行,而不是直接讓您的程式當機。 否則,程式會顯示從輸入字串中成功解析出的數字結果。 在預期會出現轉換失敗且您希望避免程式崩潰的情況下,使用 int.TryParse 可能會有所幫助。
使用 IronPDF 從 PDF 解析資料
為何使用 IronPDF 解析資料?
在處理 PDF 時,您可能會遇到表格或非結構化的文字,這些文字包含字串值的數值資料。 為了擷取和處理這些資料,將字串轉換為整數至關重要。 IronPDF 讓這個過程變得簡單直接,同時提供讀取 PDF 內容的彈性與功能,並執行將字串轉換為數值等作業。
以下是 IronPDF 提供的一些主要功能:
- HTML 轉 PDF 轉換: IronPDF 可以將HTML 內容(包括 CSS、圖片和 JavaScript)轉換為格式完整的 PDF。 這對於呈現動態網頁或 PDF 格式的報告尤其有用。
- PDF 編輯:使用 IronPDF,您可以對現有的 PDF 文件進行操作,添加文字、圖像和圖形,以及編輯現有頁面的內容。 *文字和圖像提取:*該庫可讓您從 PDF 中提取文字和圖像,從而輕鬆解析和分析 PDF 內容。 浮水印:**也可以在 PDF 文件中添加浮水印,用於品牌推廣或版權保護。
開始使用 IronPDF
若要開始使用 IronPDF,您首先需要安裝它。 如果已安裝,則可跳至下一節,否則,以下步驟將介紹如何安裝 IronPDF 函式庫。
透過 NuGet 套件管理員控制台
要使用 NuGet Package Manager Console 安裝 IronPDF,請開啟 Visual Studio 並導航至 Package Manager Console。 然後執行以下指令:
// Command to install IronPDF package via the Package Manager Console
Install-Package IronPdf透過解決方案的 NuGet 套件管理員
打開 Visual Studio,進入"工具 -> NuGet 套件管理員 -> 管理解決方案的 NuGet 套件",搜尋 IronPDF。 從這裡開始,您只需要選擇專案,然後按一下"安裝",IronPDF 就會加入您的專案中。
安裝 IronPDF 之後,您只需在程式碼頂端加上正確的 using statement 即可開始使用 IronPDF:
using IronPdf;using IronPdf;Imports IronPdf解鎖免費試用
IronPDF 提供免費試用,可完全使用其功能。 請造訪 IronPDF 網站 下載試用版,並開始在您的 .NET 專案中整合進階 PDF 處理功能。
範例:從 PDF 中萃取並解析數字
以下 C# 程式碼示範如何使用 IronPDF 從 PDF 中萃取文字,然後再使用正則表達式找出並解析萃取文字中的所有數值。 程式碼可處理整數和十進位數字,並清理非數字字元(如貨幣符號)。
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ")
Console.WriteLine(text)
' Parse and print all numbers found in the extracted text
Console.WriteLine(vbLf & "Parsed Numbers:")
' Use regular expression to find all number patterns, including integers and decimals
Dim numberMatches = Regex.Matches(text, "\d+(\.\d+)?")
' Iterate through all matched numbers and print them
For Each match As Match In numberMatches
' Print each matched number
Console.WriteLine($"{match.Value}")
Next match
End Sub
End Class輸入 PDF 文件
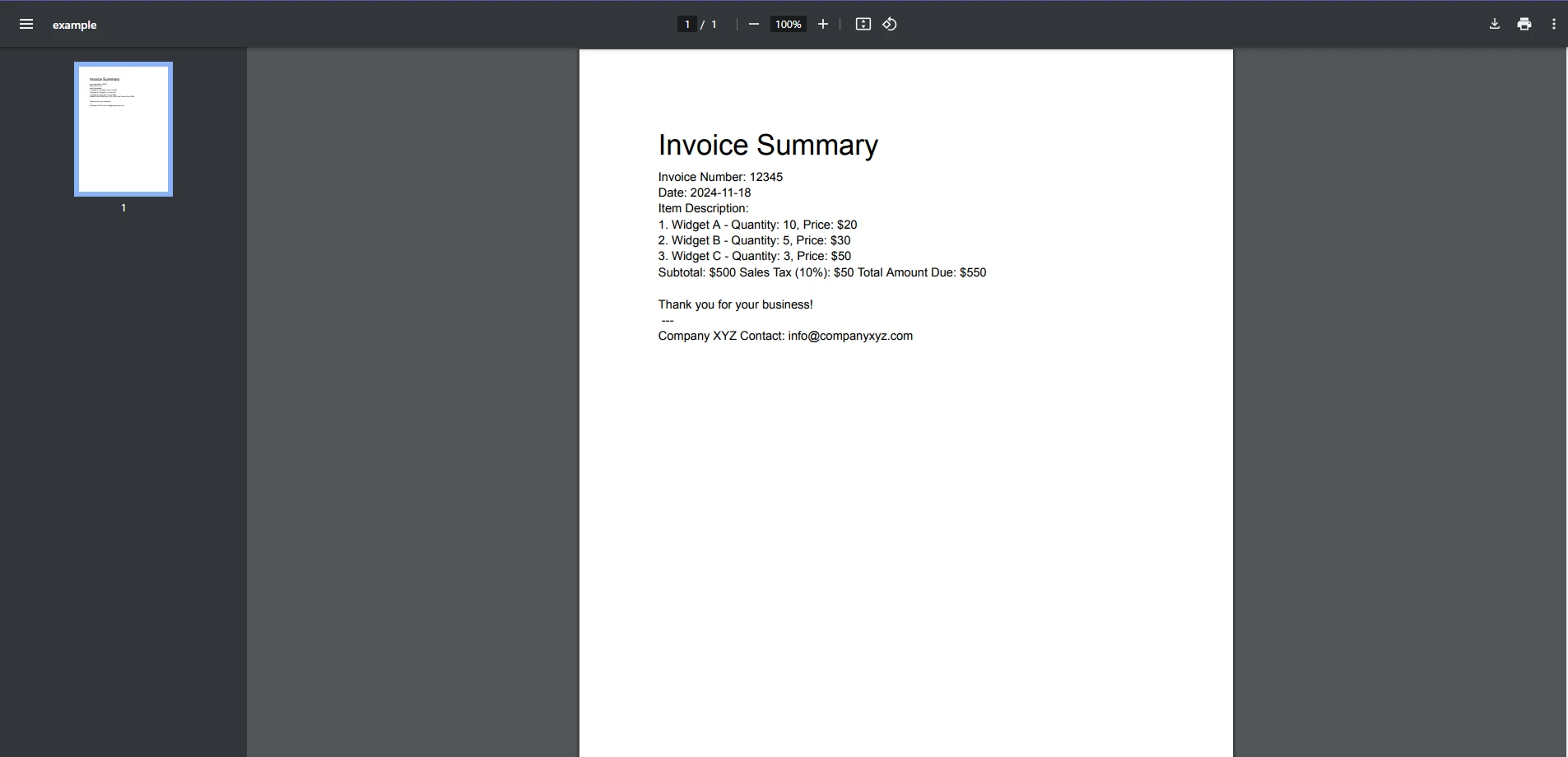
控制台輸出
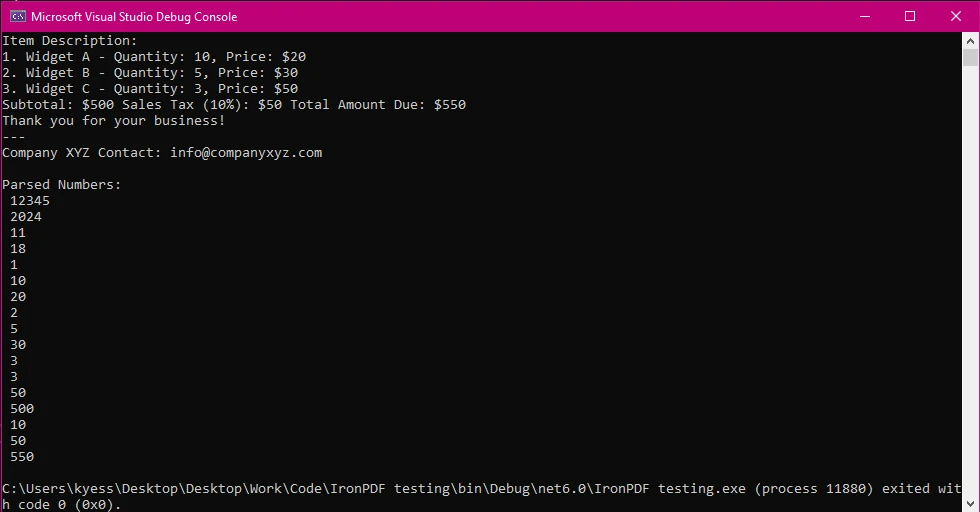
說明程式碼
1.從PDF中提取文字:
程式碼一開始使用 IronPDF 載入 PDF 檔案。 然後抽取 PDF 中的所有文字。
2.使用正規表示式找出數字:
程式碼使用 正則表達式(匹配文字的模式)搜尋擷取的文字,並找出任何數字。 正則表達式可尋找 整數 (例如 12345) 和 十進位數字 (例如 50.75)。
3.解析和列印數字:
找到數字後,程式會將每個數字列印到控制台。 這包括整數和小數。
4.為什麼需要正規表示式:
使用正規表達式是因為它們是在文字中尋找模式(如數字)的強大工具。 他們可以處理帶符號的數字(如貨幣符號 $),使翻譯過程更加靈活。
常見的挑戰以及 IronPDF 如何解決這些挑戰。
從複雜的 PDF 結構中擷取乾淨的資料,通常會產生字串值,可能需要進一步處理,例如將字串轉換為整數。 以下是一些常見的挑戰,以及 IronPDF 如何提供協助:
PDF 中的不正確格式
PDF 文件通常包含格式化為文字的數字(例如,"1,234.56 "或 "12,345 USD")。 若要正確處理這些內容,您必須確保數字的字串表示格式正確,以便進行解析。 IronPDF 允許您乾淨地提取文本,並且您可以使用字串操作方法(例如,Replace())在轉換之前調整格式。
範例:
string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234Dim formattedNumber As String = "1,234.56" ' String value with commas
' Remove commas from the string to clean it
Dim cleanNumber As String = formattedNumber.Replace(",", "")
' Convert the cleaned string to an integer by first converting to double then to integer
Dim result As Integer = Convert.ToInt32(Convert.ToDouble(cleanNumber))
Console.WriteLine(result) ' Outputs: 1234在文字中處理多重數值
在複雜的 PDF 中,數值可能以不同格式出現或分散在不同位置。 使用 IronPDF,您可以擷取所有文字,然後使用正則表達式找出字串並將其有效轉換為整數。
結論
用 C# 解析整數是開發人員的基本技能,尤其是在處理使用者輸入或從各種來源擷取資料時。 雖然像 int.Parse() 和 Convert.ToInt32() 這樣的內建方法很有用,但處理非結構化或半結構化資料(例如 PDF 中的文字)可能會帶來額外的挑戰。 這就是 IronPDF 發揮作用的地方,它為從 PDF 中提取文字並在 .NET 應用程式中使用文字提供了強大而直接的解決方案。
透過使用 IronPDF,您可獲得從複雜的 PDF(包括掃描文件)中輕鬆擷取文字,並將資料轉換為可用數值的能力。 IronPDF 具有針對掃描 PDF 的 OCR 和強大的文字擷取工具等功能,讓您即使在具有挑戰性的格式中,也能簡化資料處理流程。
無論您是在處理發票、財務報告或任何其他包含數值資料的文件,將 C# 的 ParseInt 方法與 IronPDF 相結合,將可協助您更有效率、更精準地工作。
不要讓複雜的 PDF 拖慢您的開發進程-開始使用 IronPDF是探索 IronPDF 如何強化您的工作流程的絕佳機會,何不試試看它如何簡化您的下一個專案?
常見問題
我如何在 C# 中將字串轉換為整數?
在 C# 中,你可以使用 int.Parse() 方法或 Convert.ToInt32() 將字串轉換為整數。如果字串不是有效的整數,int.Parse() 方法會引發異常,而 Convert.ToInt32() 對於 null 輸入返回 0。
int.Parse() 和 Convert.ToInt32() 之間有什麼不同?
int.Parse() 用於直接將字串轉換為整數,對於無效格式會引發異常。Convert.ToInt32() 可以通過返回預設值 0 處理空值,這使其對某些應用更安全。
int.TryParse() 如何加強解析過程中的錯誤處理?
int.TryParse() 通過返回一個布林值來加強錯誤處理,該布林值指示轉換的成功或失敗,並使用一個 out 參數來存儲結果,而不會對於無效輸入拋出異常。
IronPDF 如何幫助從 PDF 中提取文本進行解析?
IronPDF 通過提供強大的功能,如文本和圖像提取,簡化了從 PDF 提取文本的過程,使開發人員能夠輕鬆訪問字串數據以使用 C# 解析為數值。
安裝像 IronPDF 這樣的 PDF 庫涉及哪些步驟?
要安裝 IronPDF,請在 Visual Studio 中使用 NuGet Package Manager Console 並運行命令 Install-Package IronPDF,或使用 NuGet Package Manager 窗口搜索並安裝該庫。
解析 PDF 中的數據可能出現哪些挑戰?
由於格式問題如逗號和不同的數字格式,從 PDF 解析數據可能是一項挑戰。IronPDF 允許乾淨地提取文本,然後可以使用正則表達式進行處理。
正則表達式如何幫助從 PDF 中提取數據?
正則表達式允許開發人員識別文本中的模式,如帶有符號的數字,從而促進從由 IronPDF 提取的 PDF 文本中提取和轉換數據。
是否可以從掃描的 PDF 文件中提取文本?
是的,IronPDF 包含 OCR(光學文字識別)功能,可以從掃描的 PDF 中提取文本,將掃描圖像轉換為可編輯和搜索的文本。
使用 IronPDF 時,正則表達式提供了哪些好處?
正則表達式補充了 IronPDF 的功能,通過啟用靈活的文本搜索和模式匹配來處理複雜的文本提取場景,例如查找和轉換數字。













