
如何在 Node.js 中解析 PDF 文件
本文將示範如何使用Node.js的IronPDF,PDF解析Node.js程式庫來解析PDF。
什麼是Node?
跨平台、開源的Node.js JavaScript運行環境允許JavaScript代碼在瀏覽器之外執行。 程式設計師可以透過啟用伺服器端JavaScript或JS模組執行,來創建可擴展、快速和高效的網路應用程式。 由於Node.js是事件驅動的非阻塞I/O模組,它非常適合開發能同時管理多個連接且具有互動性表單元素的即時應用程式。
Node.js常被用來創建各種應用程式,包括網頁伺服器、API、資料結構流應用程式、即時聊天應用程式、物聯網(IoT)設備等。 總而言之,由於Node.js的高效性、速度以及在前端和後端的JavaScript相容性,使其成為完整開發堆疊的單一語言,因此受歡迎程度不斷上升。 查看此解釋網站的文檔頁面以了解關於Node.js的更多資訊。
如何在Node.js中解析PDF文件
- 要解析可讀流的PDF,請下載Node.js包。
- 安裝IronPDF for Node.js程式庫。
- 創建一個新的PDF或匯入現有的解析後的文件數據。
- 使用
extractText方法來提取每一行文字。 - 查看解析後的PDF內容以進行原始PDF閱讀。
IronPDF for Node.js
截至我最後的知識更新在2022年1月,IronPDF主要是一個.BNET程式庫,專為在.NET Framework內工作的需求而構建,使開發者可以使用C#或VB.NET操作PDF文件。 然而,當時並沒有專門為Node.js設計的IronPDF版本。
隨著IronPDF的擴展來支持和包括Node.js的綁定,這可能意味著在Node.js應用程式中創建、編輯和處理PDF文檔的工具現在在IronPDF for Node.js中提供。
IronPDF功能
- 從HTML到PDF生成:將HTML內容轉換為PDF文檔的能力。
- 添加、改變或移除PDF文件中的文字、形狀、圖片和其他元素被稱為文字和圖片操作。
- 合併,從PDF文件中提取頁面,拆分PDF文件,以及加密和解密它們都是PDF文件修改的例子。
- 表單處理包括完成表單、獲取表單數據以及通過程式使用PDF表單。
- PDF安全性是使用數位簽名、加密和密碼保護PDF文檔。
- 檢索和修改PDF文件被稱為頁面元數據處理。
如果IronPDF擴展其產品範圍以包括Node.js版本,這可能為開發Node.js應用程式的開發者提供使用IronPDF的PDF操作功能的一種方式。 這對於習慣於在.NET環境中使用IronPDF相似功能的開發者可能是有幫助的。
關於IronPDF的功能、相容性和對Node.js的支持的最新和最全面的資訊,應該始終查看官方文檔、發佈說明或來自IronPDF團隊的更新。 在這裡查看更多關於IronPDF和每次發佈中的新功能。 要了解有關IronPDF的更多資訊,請參考這個官方文檔頁面。
套件要求
- Visual Studio Code作為IDE
- Node.js
- 可以使用Yarn或npm進行包管理,這對於包安裝是必需的。
安裝Node.js的IronPDF套件
啟動命令提示符或終端:打開命令提示符或終端。 根據您的操作系統,有多種方式可以訪問它:
- Windows: PowerShell或命令提示符
- macOS上的終端
- Linux上的終端
要安裝包,使用包名和npm install命令。 例如,要安裝包@ironsoftware/ironpdf,在終端中運行以下命令:
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf如果不同,請使用您想安裝的包名替換@ironsoftware/ironpdf。
 安裝IronPDF
安裝IronPDF
解析PDF文件以提取數據
從實驗中,您可以看到IronPDF提供了很多功能來促進在Node.js中處理PDF。 它專注於生成、查看以及修改任何所需格式的PDF文檔。 PDF文件相當容易解析。
const { PdfDocument } = require("@ironsoftware/ironpdf");
const pdfProcess = async () => {
// Load the existing PDF document
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Extract text data from the loaded PDF
const data = await pdf.extractText();
// Output the extracted text to the console
console.log(data);
};
pdfProcess();fromFile功能的重要性由上述代碼顯示。 fromFile方法讀取PDF文檔並將PDF文件轉換成PdfDocument對象,從現有文件系統中載入文件。 因此,PdfDocument保存了PDF的元數據。 用戶可以根據需要使用pdf對像中的文件元數據。 該對像解析後的文檔數據是包含在PDF頁面對象中的文字和圖形。 extractText功能用於從提供的PDF文件中提取所有文本。之後,提取的文本被作為字符串存儲,並準備進行其他處理,例如創建JSON格式。
逐頁文字提取
以下是另一種方法的代碼,明確提取PDF文件每頁的文字。
const pdf = await PdfDocument.fromFile("Demo.pdf");
// Get the total number of pages in the PDF
const pageCount = await pdf.getPageCount();
// Loop through each page to extract text
for (let i = 0; i < pageCount; i++) {
const pageText = await pdf.extractText(i);
// Output the text of each page
console.log(pageText);
}該示例代碼從指定目錄中載入記憶體中的PDF進行原始PDF閱讀,然後創建一個名為pdf。 PDF文檔是由若干基本數據對象類型組成的數據結構。PDF文件中的每一頁數據都通過其頁碼或頁索引檢索PDF對象,以保證一個接一個地處理。 首先,我們使用其PDF對象的getPageCount方法來查找提供的PDF總頁數。
extractText函數從每個PDF頁面檢索文本。 提取的文本可以顯示在用戶螢幕上或保存在字符串變數中。 此技術使能夠有組織地從單個PDF頁面中提取文本。 這些技術展示了IronPDF,一個專門用於PDF任務的Node.js庫,如何輕鬆而徹底地從PDF文件中提取文本。 這種可訪問性增強了PDF在各種上下文中的實用性並具有多種實際應用。
 逐頁閱讀PDF
逐頁閱讀PDF
以上兩段代碼實現了相同的輸出,唯一的區別在於根據用戶需求實現的代碼不同。 要了解更多關於IronPDF的信息,請參考這些詳細文檔頁面。
結論
IronPDF程式庫提供了強大的安全措施以降低風險並確保數據安全。 它與所有流行的瀏覽器相容且不限於任何一個。 為適應開發者的各種需求,程式庫提供了廣泛的授權選項,包括免費開發者授權和可購買的額外開發授權。
除了永久授權、一年軟體維護外,$799 Lite套裝同樣包括升級可能性,並附有30天退款保證。 用戶可以通過有水印的試用期在實際應用情況下評估產品。 有關IronPDF的費用、授權和試用版本的詳細資訊,請查看提供的授權頁面。 要瞭解Iron Software提供的其他產品,請查看官方網站。
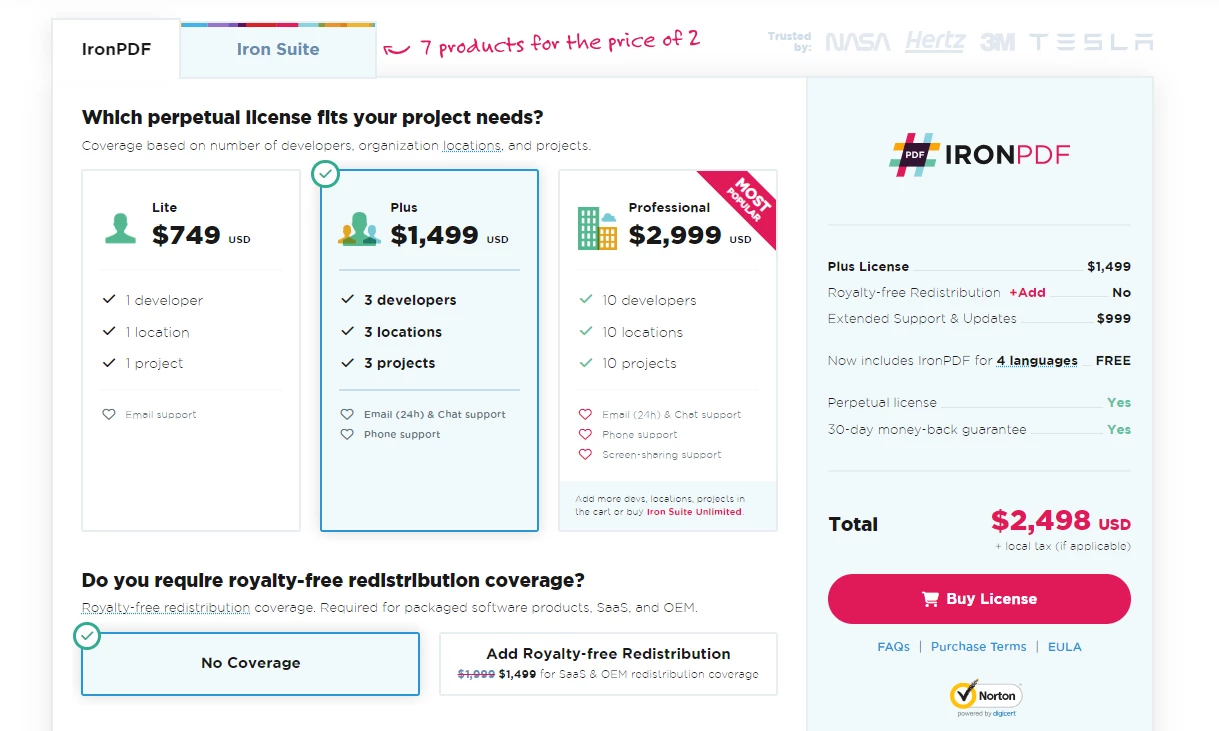 Iron Software價格
Iron Software價格
常見問題解答
我如何在Node.js中解析PDF?
要在Node.js中解析PDF,您可以利用IronPDF庫。首先通過npm install @Iron Software/ironpdf安裝IronPDF包。然後,使用fromFile方法加載PDF並使用extractText方法提取文本。
在Node.js中將HTML轉換為PDF的步驟是什麼?
您可以在Node.js中使用IronPDF將HTML轉換為PDF。對於HTML字符串使用RenderHtmlAsPdf方法,對於HTML文件使用RenderHtmlFileAsPdf方法以高效生成PDF。
如何在Node.js中從每頁PDF中提取文本?
使用IronPDF,您可以通過遍歷頁面從每頁PDF中提取文本。使用getPageCount方法確定頁數,然後使用extractText函數從每頁中提取文本。
IronPDF庫提供了哪些功能供Node.js使用?
IronPDF for Node.js提供了一系列功能,包括HTML到PDF轉換、文本和圖像操作、PDF合並和拆分、加密、數字簽名和表單處理。
我如何確保Node.js中的PDF文件的安全性?
IronPDF提供了全面的安全功能,例如數字簽名、加密和密碼保護,以確保Node.js應用程序中的PDF文件的安全。
選擇Node.js的PDF庫時我應考慮什麼?
選擇Node.js的PDF庫時,請考慮與不同瀏覽器的兼容性、安全選項、易用性、全面的文檔以及許可靈活性。IronPDF提供這些功能,使其成為開發者的強大選擇。
IronPDF在Node.js中有哪些許可選項?
IronPDF提供各種許可選項,包括免費的開發者許可、永久許可以及一年的軟件維護。他們還提供帶有水印版本的試用期,滿足不同開發者的需求。
在Node.js中可以操控PDF中的圖像嗎?
是的,使用IronPDF,您可以在Node.js應用程序中操控PDF中的圖像,這包括添加、提取或修改嵌入在PDF文檔中的圖像。















