
Python 请求庫(開發者如何工作)
Python 因其簡潔性和可讀性而廣受讚譽,使其成為開發人員進行網路爬蟲和與 API 互動的熱門選擇。實現此類互動的關鍵庫之一是 Python Requests 庫。 Requests 是一個用於 Python 的 HTTP 請求庫,它允許你直接發送 HTTP 請求。 在本文中,我們將深入探討 Python Requests 庫的特性,透過實際範例探索其用法,並介紹IronPDF,展示如何將其與 Requests 結合使用,以從 Web 資料建立和操作 PDF。
Requests 庫簡介
Python Requests 函式庫的建立是為了讓 HTTP 請求更簡單、更人性化。 它將請求的複雜性抽象化為一個簡單的 API,以便您可以專注於與網路上的服務和資料進行互動。 無論您需要取得網頁、與 REST API 互動、停用 SSL 憑證驗證,還是向伺服器發送數據,Requests 庫都能滿足您的需求。
主要特點
1.簡潔性:文法易於使用和理解。
- HTTP 方法:支援所有 HTTP 方法 - GET、POST、PUT、DELETE 等。 3.會話物件:在請求之間維護 cookie。 4.身份驗證:簡化新增身份驗證標頭的操作。 5.代理:支援 HTTP 代理。 6.超時:有效管理請求逾時。
- SSL 驗證:預設驗證 SSL 憑證。
正在安裝 Requests
要開始使用 Requests,您需要先安裝它。 這可以透過 pip 實現:
pip install requestspip install requests基本用法
以下是如何使用 Requests 取得網頁的簡單範例:
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)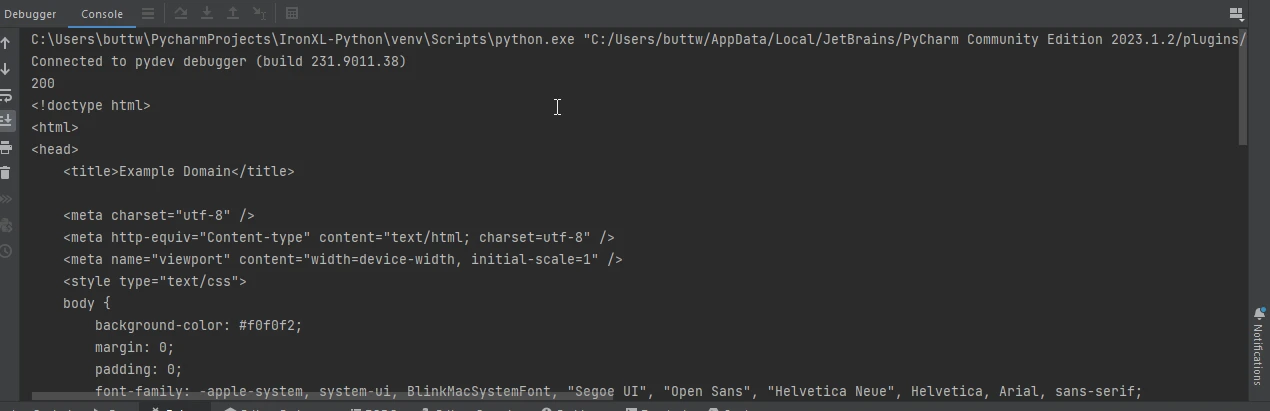
在URL中發送參數
通常情況下,你需要傳遞參數給 URL 。 Python 的 Requests 模組使用 params 關鍵字可以輕鬆實現這一點:
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)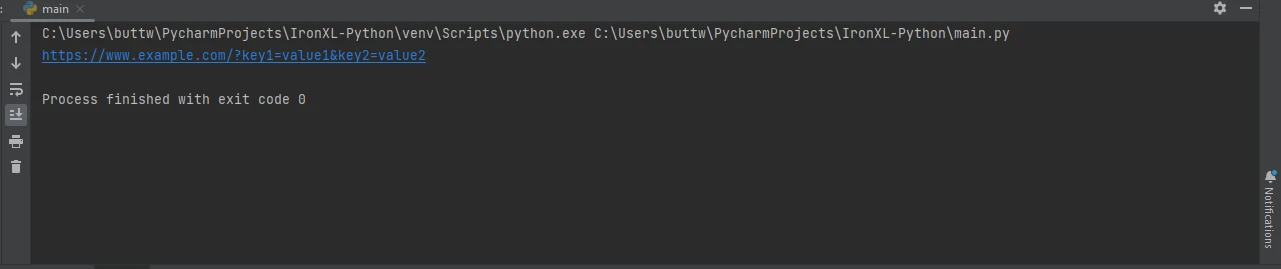
處理 JSON 數據
與 API 互動通常涉及 JSON 資料。 Requests 透過內建的 JSON 支援簡化了這個過程:
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)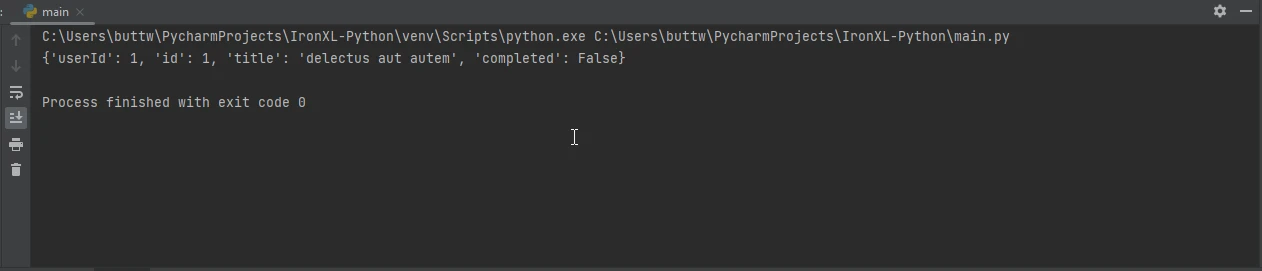
使用標頭
HTTP 請求頭至關重要。 您可以像這樣向請求新增自訂標頭:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)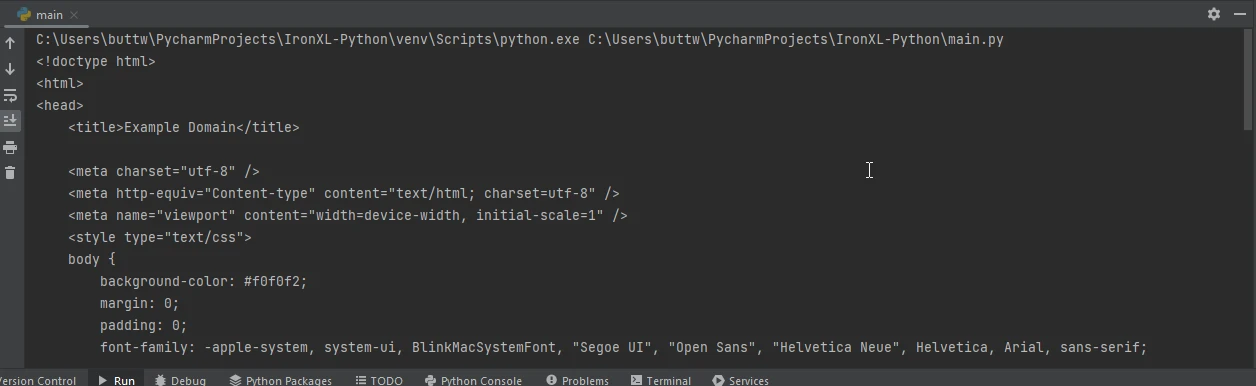
文件上傳
Requests 也支援檔案上傳。 以下是上傳文件的方法:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)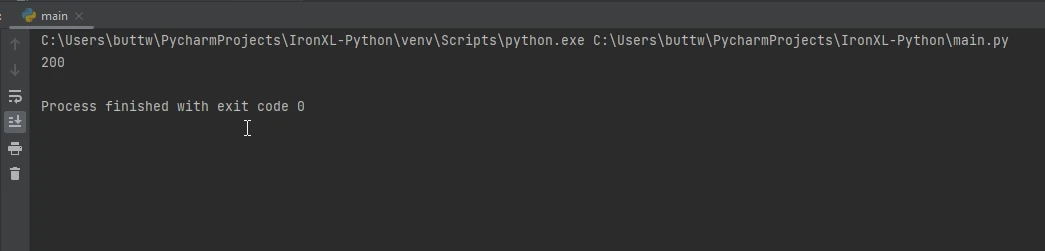
隆重介紹適用於 Python 的IronPDF
IronPDF是一個功能強大的 PDF 生成庫,可用於在 Python 應用程式中建立、編輯和操作 PDF。 當您需要從 HTML 內容產生 PDF 時,它尤其有用,因此它是建立報告、發票或任何其他需要以便攜式格式分發的文件的絕佳工具。
安裝IronPDF
若要安裝IronPDF,請使用 pip:
pip install ironpdf
使用IronPDF和 Requests
將 Requests 與IronPDF結合使用,可從網路取得資料並直接轉換為 PDF 文件。 這對於從網路資料建立報告或將網頁儲存為 PDF 檔案尤其有用。
以下是如何使用 Requests 取得網頁,然後使用IronPDF將其儲存為 PDF 的範例:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
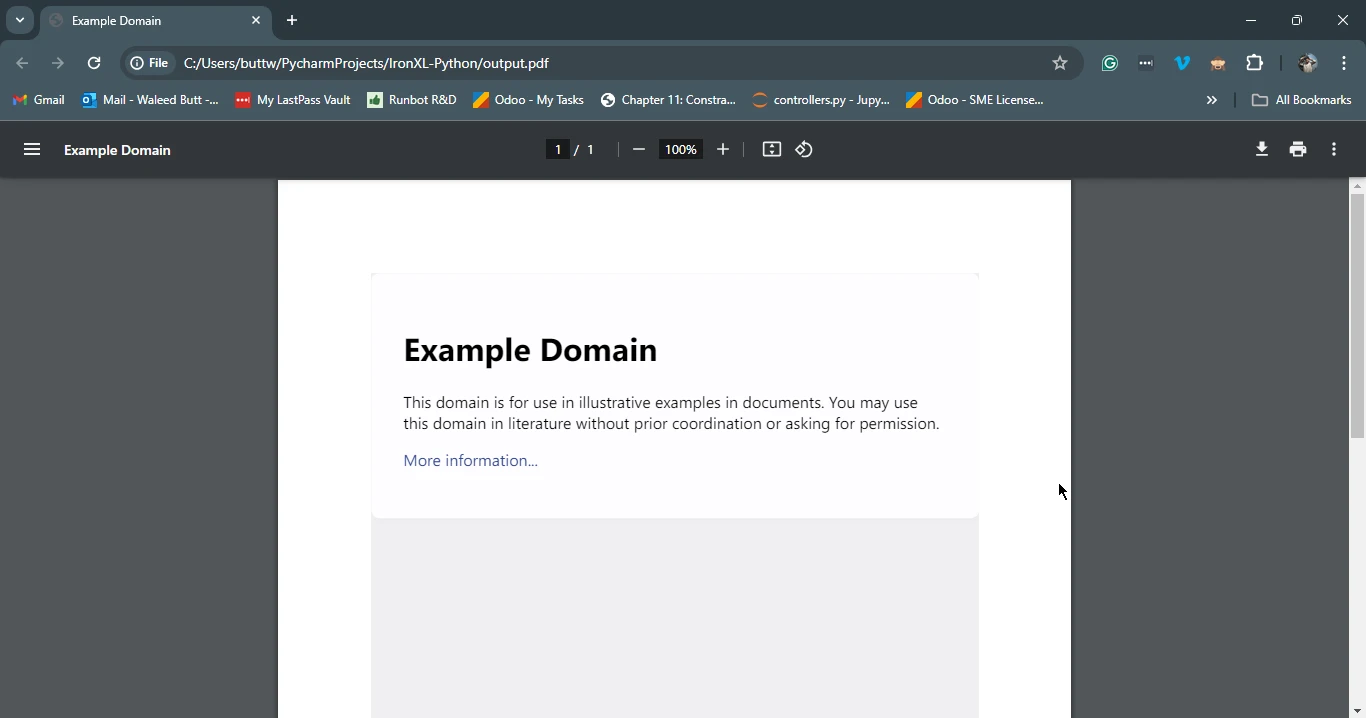
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')腳本首先使用 Requests 取得指定 URL 的 HTML 內容。 然後,它使用IronPDF將此回應物件的 HTML 內容轉換為 PDF,並將生成的 PDF 儲存到文件中。
結論
Requests 函式庫是任何需要與 Web API 互動的 Python 開發人員的必備工具。它的簡潔性和易用性使其成為發出 HTTP 請求的首選。 與IronPDF結合使用時,它開啟了更多可能性,讓您可以從網路獲取資料並將其轉換為專業品質的 PDF 文件。 無論您是建立報告、發票還是存檔 Web 內容,Requests 和IronPDF的結合都能為您的 PDF 產生需求提供強大的解決方案。
有關IronPDF許可的更多信息,請參閱IronPDF許可頁面。 您也可以瀏覽我們關於HTML轉PDF轉換的詳細教學課程,以取得更多資訊。
















