
如何在Python中從掃描的PDF中提取文本
從PDF檔案中提取文字,特別是掃描的文件,可能會面臨挑戰。 然而,使用正確的工具和技術可以簡化這一過程。 本教程將指導您如何使用IronPDF,一個Python程式庫,從掃描的PDF文件中提取文字。本文將涵蓋如何設置您的環境,應用光學字符識別(OCR),以及有效地執行文字提取。
1. IronPDF介紹
 Python PDF程式庫
Python PDF程式庫
IronPDF 是一個多功能且強大的程式庫,專為在Python環境中進行PDF操作和處理而設計。 IronPDF以其能夠無縫整合到Python應用程式中而聞名,提供一系列超越基本PDF讀取和寫入的功能。 它可將HTML轉換為PDF,從網頁或原始HTML代碼呈現PDF文件,並編輯現有的PDF文件。
此外,其光學字符識別(OCR)功能對於從掃描的PDF文件中提取文字非常有用。 這是一個開發者用於處理各種PDF相關任務的首選工具。 無論是用於創建、修改或從PDF文件中提取資料,IronPDF都是一個強大且可靠的解決方案,滿足Python開發人員在各種應用中的多樣需求。
2. 先決條件
在深入了解從PDF中提取文字的過程之前,確保具備一些先決條件和必要的程式庫是很重要的。 這將保障您在進行時擁有順暢且有效的工作流程。
- Python環境:確保您的電腦系統上已安裝Python。 Python是一種多用途的程式語言,其廣泛的程式庫支持使其成為文字提取等任務的理想之選。 如果您尚未安裝Python,可以從Python官方網站下載。 請確保下載與您的作業系統相容的Python版本。
- .NET 6.0 SDK 安裝:由於IronPDF for Python利用了建基於 .NET 6.0 的IronPDF .NET 程式庫,所以在您的系統上安裝 .NET 6.0 SDK 是至關重要的。 此SDK提供了IronPDF程式庫正常運行所需的運行時和程式庫。 您可以從Microsoft .NET官方網站下載並安裝 .NET 6.0 SDK。
- IronPDF for Python 程式庫:IronPDF 是一個強大的用於在Python中處理PDF文件的程式庫。 它不僅促進文字提取,還提供了如PDF創建、編輯和轉換等功能。
- 掃描的PDF文件:準備好一份掃描的PDF文件以進行文字提取。 此文件應該最好是清晰且易讀的,因為掃描PDF的質量會顯著影響OCR的準確性和提取文字的質量。
- 基本Python的理解:具有Python編程的基本理解是有益的。 熟悉類似變量、循環和基本文件操作的概念將幫助您更有效地讀懂代碼並理解文字提取過程。
- 合適的開發環境:雖然不是絕對必要的,但擁有一個開發環境如Visual Studio Code、PyCharm或者Jupyter Notebook會使您的編碼過程更易管理。 這些環境提供類似語法高亮、代碼完成以及除錯工具等功能,對於處理Python腳本非常有幫助。
擁有這些先決條件,您已經準備好開始使用IronPDF for Python程式庫從掃描的PDF文件中提取文字。 接下來的步驟將指導您如何安裝IronPDF、加載您的PDF文件、應用OCR、提取文字,並按照您的具體需求利用提取的數據。
3. 從掃描的PDF中提取文字的逐步指南
步驟1:安裝IronPDF
首先,您需要在您的Python環境中安裝IronPDF程式庫。 這通常是使用Python的套件管理工具pip完成的。打開您的命令行界面並運行以下命令:
pip install ironpdf
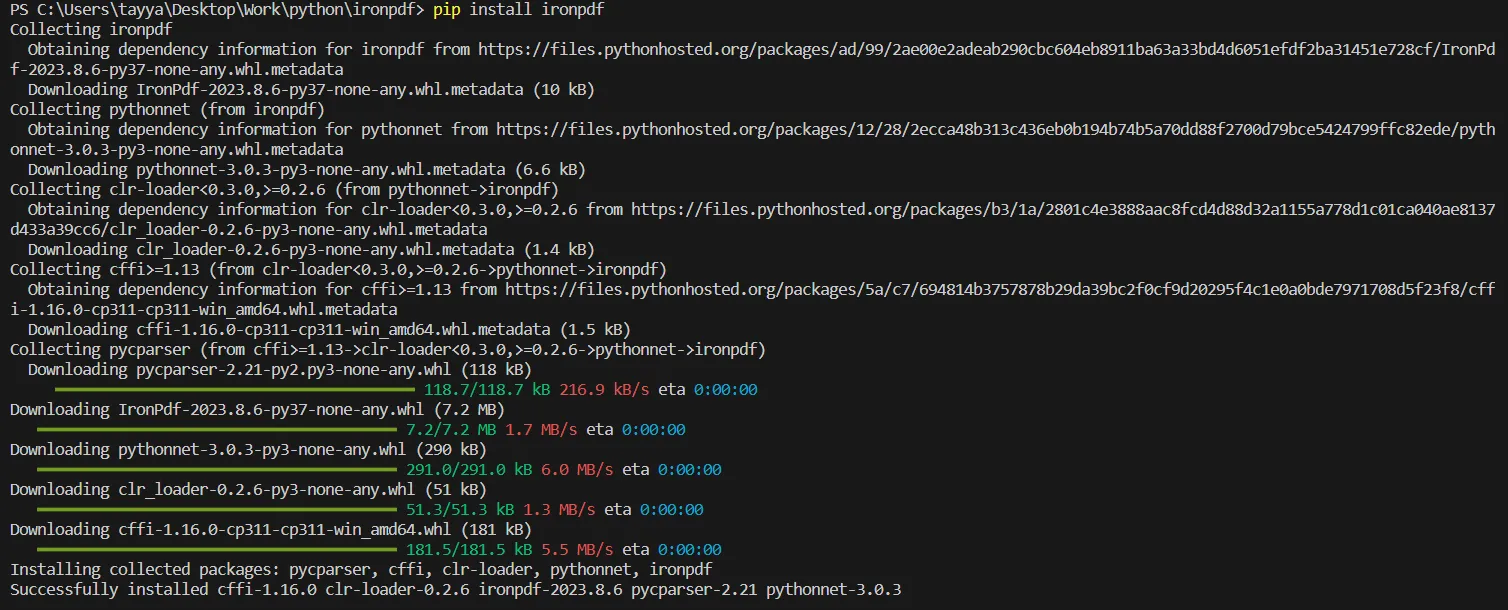 安裝IronPDF套件
安裝IronPDF套件
步驟2:匯入IronPDF
安裝後,將IronPDF程式庫匯入到您的Python腳本中。 此步驟對於存取IronPDF提供的功能至關重要:
import ironpdfimport ironpdf通過匯入IronPDF,您現在可以在您的腳本中使用其類別和方法。
步驟3:應用您的授權金鑰
IronPDF需要授權金鑰才能獲得完整功能。 如果您購買了授權,請按如下方式應用您的授權金鑰:
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"用您的實際IronPDF授權金鑰替換"YOUR-LICENSE-KEY-HERE"。 此步驟對於解鎖IronPDF的所有功能並避免任何限制至關重要。
步驟4:加載掃描的PDF文件
要提取文字,首先將PDF文件加載到您的腳本中:
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")這裡,應替換"scannedpdf.pdf"為您打算處理的PDF文件的實際文件路徑。 該命令讀取PDF文件並準備進行文字提取。
步驟5:從PDF文件中提取文字
有了加載的PDF,您現在可以使用IronPDF的ExtractAllText()方法來提取文字,如以下代碼所示:
text = pdf.ExtractAllText()text = pdf.ExtractAllText()這行代碼處理整個PDF文件並提取其文字內容,並將其儲存到text變數中。
步驟6:處理並利用提取的文字
提取後,文字數據可以在text變數中使用。 您可以將此文字輸出到控制台或根據您的需要進一步處理它:
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted text此步驟可以涉及各種操作,如將提取的文字保存到文件、進行文字數據分析,或將其整合到數據庫或網頁應用中。 在這裡,您可以看到上述代碼的輸出結果。
輸出文字
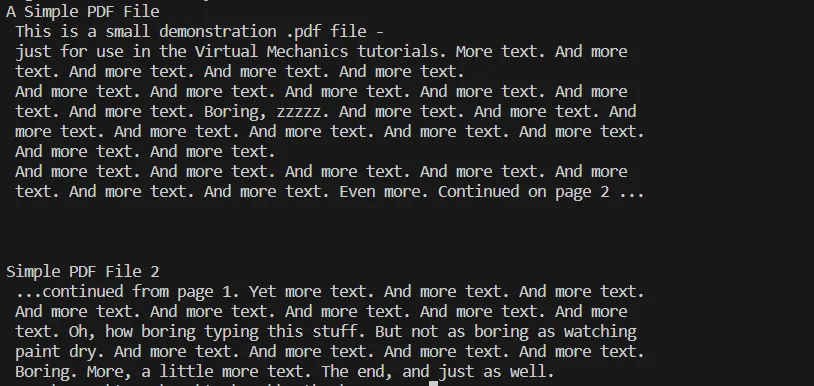 提取PDF文件文字過程的控制台輸出
提取PDF文件文字過程的控制台輸出
步驟7:其他操作(可選)
IronPDF的功能範圍超出了文字提取。 根據您的專案需求,您可以探索額外的功能,例如編輯PDF、將PDF轉換為不同格式,甚至從HTML生成PDF。
4. 進階技術
4.1 處理非文字元素
掃描的PDF通常包含非文字元素如圖片或圖表。雖然OCR專注於文字,但您可能希望對這些元素進行不同的處理。 您可能需要額外的Python程式庫來處理或忽略非文字內容。
4.2 提升OCR準確性
文字提取的準確性可能會因掃描文檔的質量而異。 為了提升OCR的結果,請確保您的掃描PDF質量高,並且文字盡可能清晰。
4.3 轉換為其他格式
從PDF提取文字後,您可能希望將其轉換為其他格式,如CSV、JSON或XML以進行進一步處理。 IronPDF允許此類轉換,為您提供靈活的數據處理選項。
5. 排除常見問題
當與OCR和文字提取工作時,您可能會遇到如下問題:
- 由於掃描質量差導致OCR準確性低。
- 如果OCR無法識別某些字符可能導致文字丟失。
- 加載大型PDF文件時發生錯誤。
要排除這些問題,確保掃描的PDF文件清晰且質量高,考慮將大型文件分成更小的文件,並確認您的IronPDF程式庫是最新的。
結論
使用IronPDF Python 程式庫可以無縫地從掃描的PDF文件中提取文字。 按照本教程中概述的步驟,您可以將不可搜尋的掃描文檔轉換為豐富的文字格式,可以快速處理和分析。 請記住小心處理每一頁PDF並應用OCR以將掃描PDF轉換為可搜尋的PDF文件。隨著提取文字,資料操作和利用的可能性是無盡的,為創新的解決方案和順暢的工作流程鋪平道路。
總而言之,這篇文章涵蓋了IronPDF的安裝與設置,PDF文件的加載,應用OCR技術使掃描的PDF可搜尋,實際的文字提取過程以及處理多個PDF頁面。 它還觸及了一些進階技術和排除常見問題。 有了這些知識,您可以使用Python從PDF文件中提取文字數據。
IronPDF提供免費試用來獲得完整功能訪問,允許用戶評估PDF操作和文字提取能力。 試用期後,付費授權從$799開始,滿足專業和商業用途的全面功能。 IronPDF在開發期間是免費的,使開發人員可以免費整合和測試其功能。
常見問題解答
如何設置環境以便使用 Python 從掃描的 PDF 中提取文字?
要設置環境,使用 Python 的套件管理器安裝 .NET 6.0 SDK 和 IronPDF 庫,運行 pip install ironpdf。確保您已經有可用的 Python 環境和合適的開發環境,如 Visual Studio Code 或 PyCharm。
什麼是光學字符識別(OCR),以及如何在 Python 中應用?
光學字符識別(OCR)是一種技術,用於將掃描的紙張文檔或 PDF 等不同類型的文檔轉換為可編輯和可搜索的數據。在 Python 中,您可以使用 IronPDF 加載掃描的 PDF 並利用庫的 OCR 功能來提取文本。
如何確保從掃描的 PDF 中精確地提取文本?
為了確保精確的文本提取,使用高質量的掃描 PDF,因為隨著更清晰和更好的掃描,OCR 的準確性會提高。使用 IronPDF,您可以應用 OCR 來提取文本並根據需要進一步處理。
使用 IronPDF 從掃描的 PDF 中提取文字涉及哪些步驟?
步驟包括安裝 IronPDF,導入庫,應用授權密鑰,加載您的掃描 PDF,應用 OCR,並使用 ExtractAllText() 方法提取文本。
我可以將提取的文本轉換為 CSV、JSON 或 XML 等格式嗎?
是的,從掃描的 PDF 中提取文本後,您可以將其轉換為 CSV、JSON 或 XML 等多種格式,以進行進一步分析或數據操作。
如果文本提取失敗,有哪些常見的故障排除步驟?
如果文本提取失敗,請檢查掃描 PDF 的質量。確保 IronPDF 正確安裝,並且您的開發環境設置正確。此外,確認使用了正確的方法和 OCR 功能。
IronPDF 有試用版本嗎?
是的,IronPDF 為用戶提供免費試用版以測試其功能。試用期後,需購買授權才能獲得完整功能。
















