
如何在 Python 中从 PDF 文件中提取特定文本
本文将演示如何借助IronPDF for Python库从PDF文档中提取文本元素。
IronPDF
Python是一种编程语言,使开发人员能够简单快捷地创建图形用户界面。 与其他语言相比,Python对程序员来说也更加动态。 因此,将IronPDF库添加到Python中是一个简单的过程。 可以使用包括PyQt、wxWidgets、Kivy在内的大量预安装工具,以及许多其他包和Python库,快速安全地构建一个完整的GUI。 IronPDF结合了Python,还允许集成来自其他框架的功能,如.NET Core。
IronPDF使Web开发变得更容易。 主要原因是Python Web开发范式如Django、Flask和Pyramid的广泛采用。 Reddit、Mozilla和Spotify只是使用这些框架的网站和在线服务的几个例子。
IronPDF。 功能
- 使用 IronPDF,PDF 文件可以从多种来源创建,包括 HTML、HTML5、ASPX 和 Razor/MVC 视图。 它提供将HTML 页面和图像转换为 PDF 文件的能力。
- 创建交互式 PDF、填写和提交交互式表单、拆分和合并 PDF 文件、提取文本和图像、在 PDF 文件中搜索文本、将 PDF 光栅化为图像、更改字体大小、使用 ChatGPT 进行自然语言处理,以及转换 PDF 页面的属性只是 IronPDF 工具包可以帮助的一些活动。
- IronPDF提供支持用户代理、代理、Cookie、HTTP标头和表单变量的HTML登录表单验证。
- IronPDF 使用用户名和密码为用户提供对受保护文档的访问。
- 只需几行代码,IronPDF即可从字符串、流或URL等各种来源打印PDF文件。
安装Python
环境配置
确保已在计算机上安装Python。 要下载和安装与您的操作系统兼容的最新版本 Python,请访问官方 Python 网站。 在安装Python后创建一个虚拟环境,以便将项目的需求隔离开来。 使用venv模块创建和管理虚拟环境,为您的转换项目提供一个整洁、独立的工作空间。
PyCharm 中的新举措
对于本次演示,推荐使用PyCharm作为开发Python代码的IDE。
启动PyCharm IDE后,选择"New Project"。
 PyCharm
PyCharm
在选择"New Project"时将打开一个新窗口,允许您设置项目的位置和环境。 您可以在下图中看到这一点。
 新建项目
新建项目
选择项目位置和环境路径后,点击Create按钮来开始一个新项目。 随后程序可以在一个新窗口中创建并打开。 对于本教程,将使用Python 3.9。
 创建Python项目
创建Python项目
IronPDF。库需求
Python库IronPDF主要使用.NET 6.0。因此,计算机上必须安装.NET 6.0运行时才能使用IronPDF for Python。 Linux和Mac用户可能需要先安装.NET才能使用此Python模块。 访问该来自 Microsoft 的下载页面以获取所需的运行时环境。
IronPDF。库安装
要生成、修改和打开".pdf"扩展的文件,必须安装"ironpdf"包。 打开一个终端窗口并输入以下命令在PyCharm中安装该包:
pip install ironpdfpip install ironpdf下图展示了安装ironpdf包的过程。
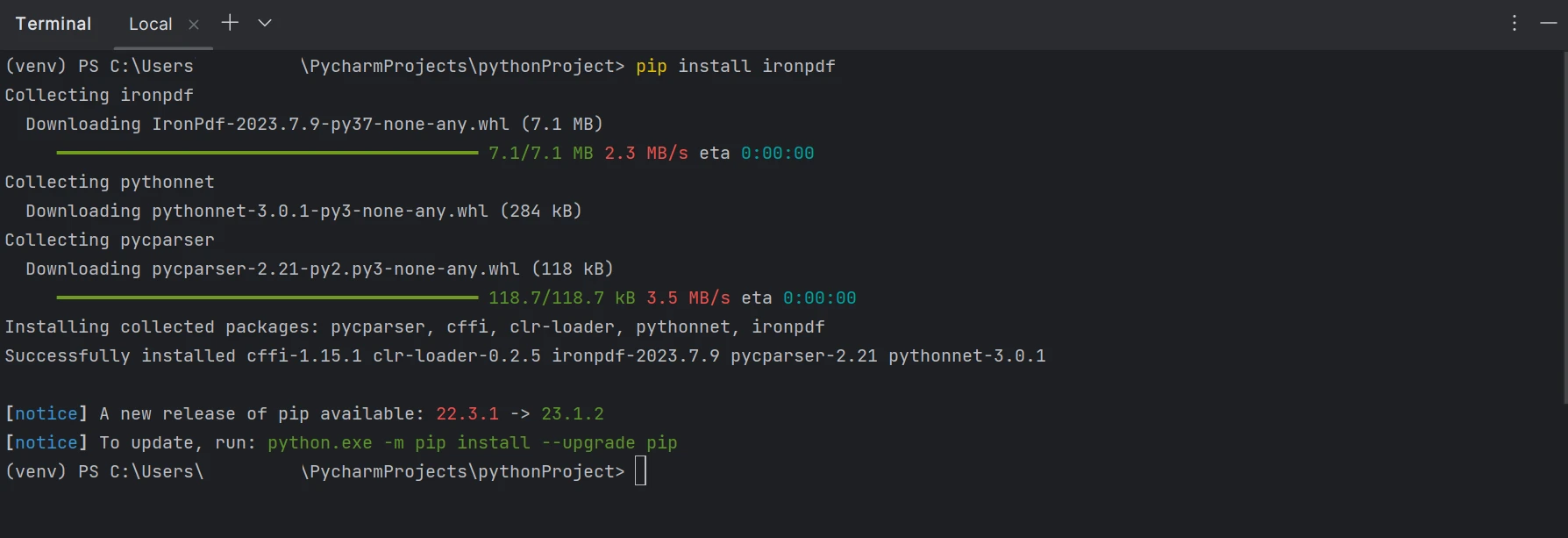 安装IronPDF
安装IronPDF
从PDF文件中提取特定数据
可以借助IronPDF库从PDF文件中提取文本。 IronPDF提供了多种文本提取方法。 第一种方法是将整个页面内容作为一个字符串进行检索。 第二种策略是在整个页面的内容第一页开始逐页获取。 可使用IronPDF库来探查现有的PDF文件。 以下代码片段展示了如何使用IronPDF来检查实时的PDF文件。
有两种从PDF中提取信息的选项:
- 按页从PDF中提取数据
将整个PDF转换为文本
- 此文章的示例 PDF 文件可以在下方获得。
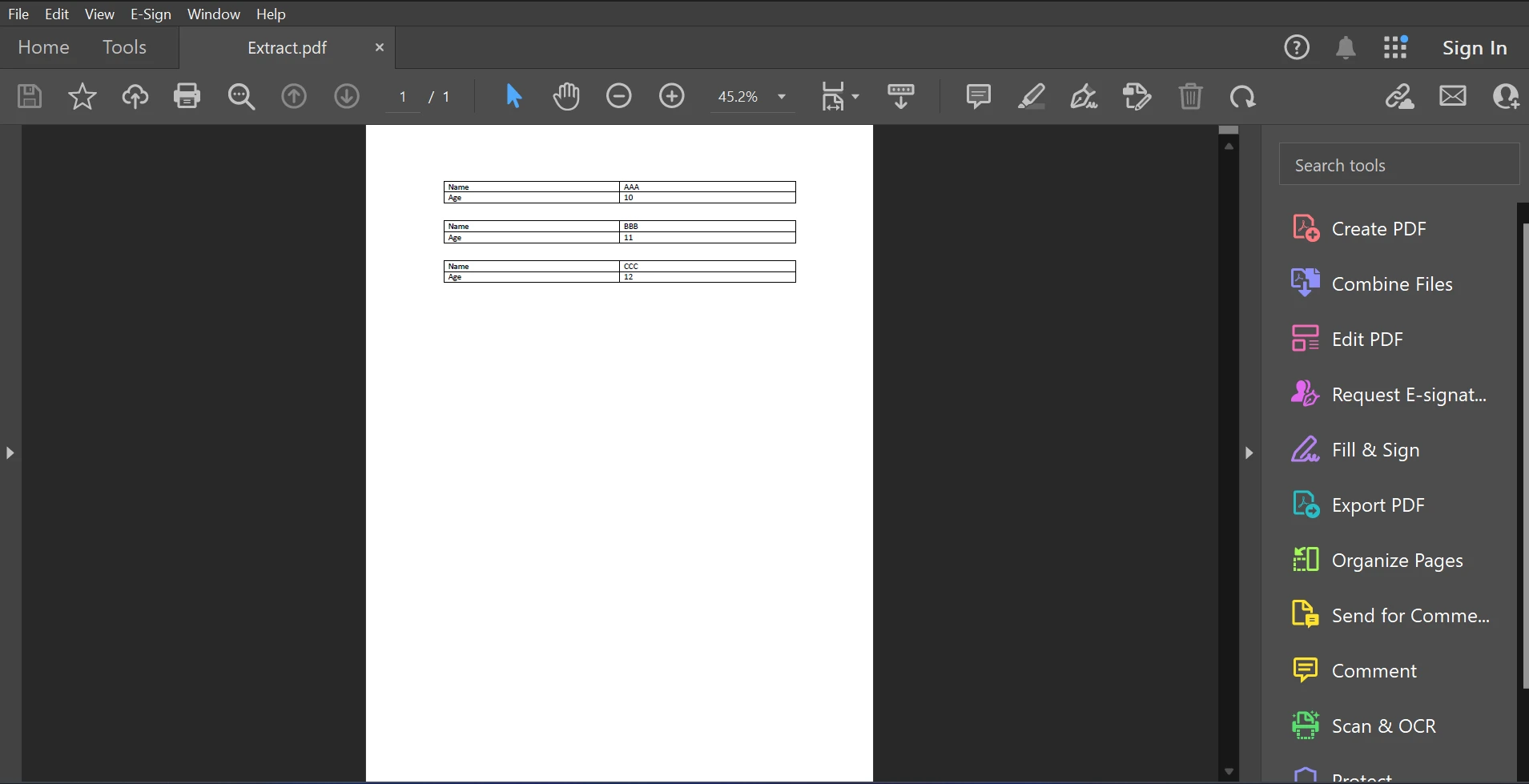 输入PDF
输入PDF
逐页从PDF中提取数据
供下方的示例代码展示了如何使用页面编号从PDF文件中获取数据。
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)该代码片段展示了如何使用FromFile函数读取PDF文件并构建PDF对象。 该对象可用于访问PDF中的文本和图像。 通过将页码作为参数传递给ExtractTextFromPage函数,可以从特定页面检索文本。 此方法将返回包含所选页面上所有单词的字符串。 然后,在Python中使用split函数将提取的文本中的所有新行分割开。 随后,检查提取的文本中每一行是否包含所需的关键词。 如果关键词匹配,它将在命令提示符中显示特定行。 否则,它将忽略该行并继续下一行。文本提取输出将如下面所示。
将整个PDF转换为文本
以下代码示例展示了第一种方法以快速简便地获取所有PDF内容作为字符串。
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)上面的示例代码演示了如何使用FromFile函数从现有文件路径读取PDF并将其转换为PDF文件对象。 因此,我们可以使用此PDF读取器对象查看PDF中的文本和图像。 对象的ExtractAllText函数将用于从PDF中提取数据到纯文本,转换为字符串,并使用与上述类似的逻辑找到特定关键字以在终端显示结果。 结果显示如下。
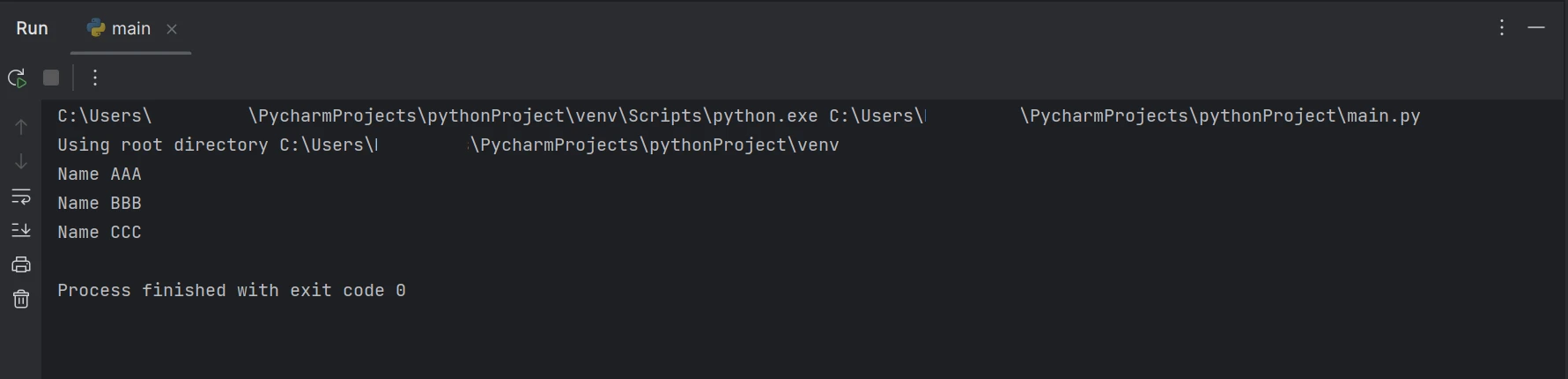 输出
输出
上述代码/输出显示给定的PDF文档包含名字和年龄,但结果仅显示PDF文档中的名字。
结论
IronPDF库提供了强大的安全机制,以减少威胁并确保数据安全。 它不会限制在任何一个浏览器中,并且与所有常用的浏览器兼容。 通过几行代码,程序员可以快速生成和阅读PDF文件。 IronPDF库提供了一系列许可选项,包括免费的开发者许可证以及附加的开发许可,可以购买以满足开发者的各种需求。
永久许可证、30 天退款保证、一年的软件维护和升级选项已包含在Lite 套件中。 这些许可证可在所有环境中使用。 此外,IronPDF还提供了一些具有某些再分发限制的免费许可证。 一份试用许可证允许用户在没有水印的情况下评估产品。
请查看可用的 IronPDF 许可证以获取有关商业许可证的更多信息。
常见问题解答
如何使用 Python 从 PDF 中提取特定文本?
您可以使用 IronPDF 的 Python 库从 PDF 中提取文本。它提供了逐页提取文本的功能,使用 ExtractTextFromPage 能够从整个文档中提取文本,使用 ExtractAllText。
在 Python 项目中设置 IronPDF 的步骤是什么?
首先,如果尚未安装,请安装 .NET 6.0 运行时。然后,在您的开发环境(如 PyCharm)中设置 Python。使用 pip install ironpdf 安装 IronPDF,开始将 PDF 功能集成到您的项目中。
IronPDF 是否与 Django 和 Flask 等框架兼容?
是的,IronPDF 很好地与 Django 和 Flask 等 Python Web 开发框架集成,提供了处理 Web 应用程序中 PDF 的各种选项。
使用 IronPDF 和 Python 有哪些许可选项可用?
IronPDF 提供了一系列许可选项,包括用于个人使用的免费开发者许可和提供额外功能与利益的各种商业许可。
我如何安装 IronPDF for Python?
通过在终端或命令提示符中运行命令 pip install ironpdf,使用 pip 包管理器安装 IronPDF。
推荐的开发环境用于使用 IronPDF 和 Python 是什么?
PyCharm 是一个推荐的集成开发环境(IDE),适合用 IronPDF 开发 Python 应用程序,因为它支持全面的功能集和 Python。
IronPDF for Python 的一些关键特性是什么?
IronPDF for Python 提供了一些特性,例如从 HTML 创建 PDF,将图像转换为 PDF,表单处理,文本和图像提取以及 PDF 合并。
对于处理 PDF 文件,IronPDF 的安全性如何?
IronPDF 设计有强大的安全功能,确保安全处理 PDF 文件。它支持加密和密码保护,以保护敏感信息。
















