
A Comparison of Splitting PDF in C# Between iTextSharp and IronPDF
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
PDF (Portable Document Format) files are widely used for sharing and presenting documents, and there are times when you may need to split a PDF into multiple files. Whether you want to extract specific pages, divide a large document into smaller sections, or create individual files for each chapter, splitting PDFs can be a valuable task in various scenarios.
In this article, we'll learn how to split PDFs using C#. C# is a versatile and powerful language, and there are several libraries available that make it relatively straightforward to manipulate PDFs. We will explore the following two libraries for splitting PDFs in C#.
How to Split PDF in C# Using iText
- First, install the iText library.
- Create a PdfReader from the input PDF file.
- Use a PdfDocument to work with the PDF content.
- Calculate the number of pages for each split file.
- Set initial page range values.
- Use a loop to process each split file.
- Create a new PdfDocument for the current split file.
- Copy pages from the original document to the new one.
- Update page range values for the next iteration.
- Save the completed output PDF.
- Repeat until all files are created.
- Continue the process for the specified number of split files.
IronPDF
IronPDF is a powerful C# library designed for working with PDF files. It provides features for creating, modifying, and extracting content from PDF documents. Developers can generate PDFs from scratch, edit existing PDFs, and merge or split them. Additionally, IronPDF excels at converting HTML content to PDF format, making it useful for generating reports or documentation. With support for digital signatures, security features, and high-quality output, IronPDF simplifies PDF-related tasks in .NET applications.
iText
iText (iText) is a widely used library for working with PDF files in the .NET framework. It provides powerful features for creating, modifying, and extracting content from PDF documents programmatically. Developers can use iText to add text, images, tables, and other graphical elements to PDFs. Additionally, it supports document assembly, digital signatures, and compliance with archival and accessibility standards. Originally a Java library, iText was ported to .NET and has an active community of developers and users.
Installing the IronPDF Library
To install the IronPDF NuGet package using Package Manager Console in Visual Studio, follow these steps:
- In Visual Studio, go to Tools -> NuGet Package Manager -> Package Manager Console.
-
Use the following command to install the IronPDF NuGet package:
Install-Package IronPdf
This will download and install the IronPDF package along with its dependencies into your project. Once the installation is complete, you can start using IronPDF in your C# project for PDF-related tasks.
Alternatively, you can install IronPDF using the NuGet Package Manager in Visual Studio, or add the package directly to your project file. Another option is downloading the package from the official website and manually adding it to your project. Each method provides a straightforward way to integrate IronPDF into your C# project for PDF-related functionalities.
Installing the iText Library
To install iText using Package Manager Console in Visual Studio, you can follow these steps:
- In Visual Studio, go to Tools -> NuGet Package Manager -> Package Manager Console.
-
Use the following command to install the iText NuGet package:
Install-Package itext7Install-Package itext7SHELL
This will download and install the iText package along with its dependencies into your project. Once the installation is complete, you can start using iText in your C# project for working with PDFs.
Split PDF Documents in C# Using IronPDF
We can split a PDF file into multiple PDF files using IronPDF. It provides a simple way to achieve this. The following code will take the source PDF file as input and split it into multiple PDF files.
using IronPdf;
class Program
{
static void Main(string[] args)
{
string file = "input.pdf";
// The folder to save the split PDFs
string outputFolder = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingIronPDF(file, outputFolder, numberOfSplitFiles);
}
static void SplitPdfUsingIronPDF(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
// Load the input PDF
PdfDocument sourceFile = PdfDocument.FromFile(inputPdfPath);
// Initialize page range values
int firstPage = 1;
int lastPage = 2;
int totalPageInOneFile = sourceFile.PageCount / numberOfSplitFiles;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Copy multiple pages into a new document
PdfDocument newSplitPDF = sourceFile.CopyPages(firstPage, lastPage);
// Generate the output file path
string name = $@"{outputFolder}\SplitPDF_IronPDF_{i}.pdf";
// Save the new split PDF
newSplitPDF.SaveAs(name);
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}using IronPdf;
class Program
{
static void Main(string[] args)
{
string file = "input.pdf";
// The folder to save the split PDFs
string outputFolder = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingIronPDF(file, outputFolder, numberOfSplitFiles);
}
static void SplitPdfUsingIronPDF(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
// Load the input PDF
PdfDocument sourceFile = PdfDocument.FromFile(inputPdfPath);
// Initialize page range values
int firstPage = 1;
int lastPage = 2;
int totalPageInOneFile = sourceFile.PageCount / numberOfSplitFiles;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Copy multiple pages into a new document
PdfDocument newSplitPDF = sourceFile.CopyPages(firstPage, lastPage);
// Generate the output file path
string name = $@"{outputFolder}\SplitPDF_IronPDF_{i}.pdf";
// Save the new split PDF
newSplitPDF.SaveAs(name);
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}Imports IronPdf
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim file As String = "input.pdf"
' The folder to save the split PDFs
Dim outputFolder As String = "output_split"
Dim numberOfSplitFiles As Integer = 3 ' Specify how many parts you want to split the PDF into
' Call the SplitPdf method to split the PDF
SplitPdfUsingIronPDF(file, outputFolder, numberOfSplitFiles)
End Sub
Private Shared Sub SplitPdfUsingIronPDF(ByVal inputPdfPath As String, ByVal outputFolder As String, ByVal numberOfSplitFiles As Integer)
' Load the input PDF
Dim sourceFile As PdfDocument = PdfDocument.FromFile(inputPdfPath)
' Initialize page range values
Dim firstPage As Integer = 1
Dim lastPage As Integer = 2
'INSTANT VB WARNING: Instant VB cannot determine whether both operands of this division are integer types - if they are then you should use the VB integer division operator:
Dim totalPageInOneFile As Integer = sourceFile.PageCount / numberOfSplitFiles
For i As Integer = 1 To numberOfSplitFiles
' Copy multiple pages into a new document
Dim newSplitPDF As PdfDocument = sourceFile.CopyPages(firstPage, lastPage)
' Generate the output file path
Dim name As String = $"{outputFolder}\SplitPDF_IronPDF_{i}.pdf"
' Save the new split PDF
newSplitPDF.SaveAs(name)
' Update page range values for the next iteration
firstPage = lastPage + 1
lastPage += totalPageInOneFile
Next i
End Sub
End ClassCode Explanation
The purpose of this code is to split a given PDF file into multiple smaller PDF files using the IronPDF library. The SplitPdfUsingIronPDF method is defined to achieve this functionality.
Method Parameters
inputPdfPath: A string representing the path to the input PDF file (e.g., "input.pdf").outputFolder: A string representing the output folder where the split PDF files will be saved (e.g., "output_split").numberOfSplitFiles: An integer indicating how many smaller PDF files the original PDF will be split into.
Splitting Process
Inside the SplitPdfUsingIronPDF method:
- A
PdfDocumentobject namedsourceFileis created by loading the PDF from the specifiedinputPdfPath. - Two integer variables,
firstPageandlastPage, are initialized. These represent the page range for splitting. totalPageInOneFileis calculated by dividing the total page count of the source PDF by the specifiednumberOfSplitFiles.- A loop iterates from 1 to
numberOfSplitFiles: - A new
PdfDocumentobject namednewSplitPDFis created. - Pages from
firstPagetolastPage(inclusive) are copied from thesourceFiletonewSplitPDF. - The resulting smaller PDF is saved with a filename like "SplitPDF_IronPDF_1.pdf" (for the first split) in the specified output folder.
- The
firstPageandlastPagevalues are updated for the next iteration.
Note
You should replace "input.pdf" with the actual path to your input PDF file. Ensure that the IronPDF library is properly installed and referenced in your project.
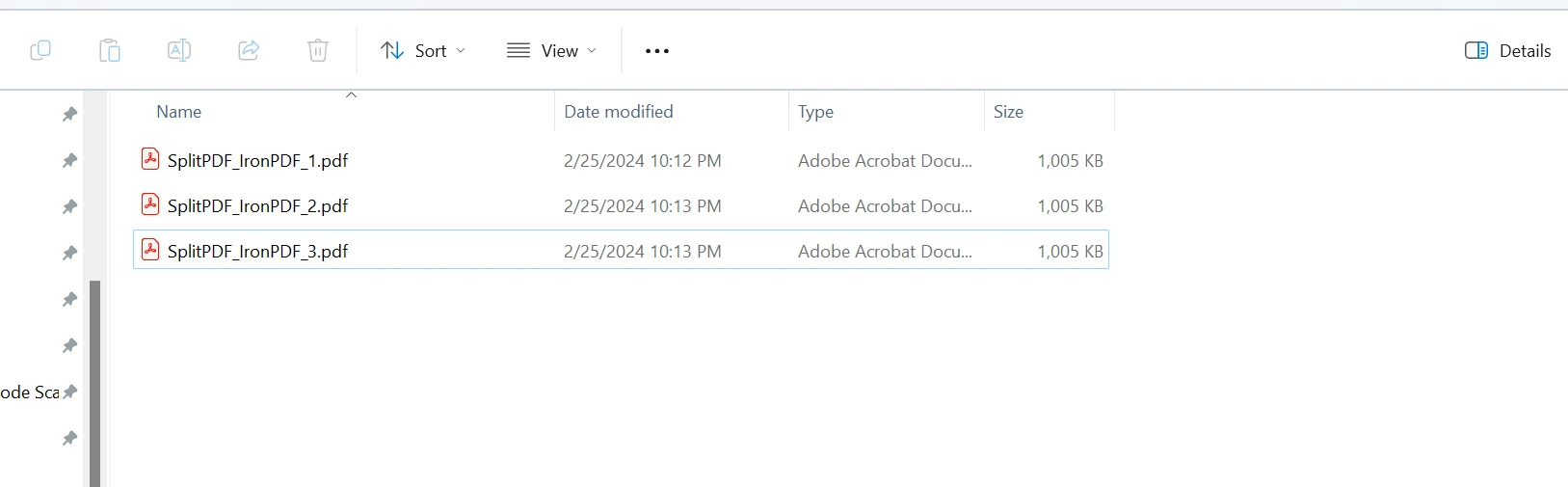
The output files are created as:
Split PDFs in C# Using iText
Now, we will use iText to split our PDF document into multiple PDF files. The following code will take the source file as input and split that PDF document into multiple smaller files.
using System;
using iText.Kernel.Pdf;
class Program
{
static void Main(string[] args)
{
string inputPath = "input.pdf";
// Output PDF files path (prefix for the generated files)
string outputPath = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles);
}
static void SplitPdfUsingiTextSharp(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
using (PdfReader reader = new PdfReader(inputPdfPath))
{
using (PdfDocument doc = new PdfDocument(reader))
{
// Calculate the number of pages for each split file
int totalPageInOneFile = doc.GetNumberOfPages() / numberOfSplitFiles;
int firstPage = 1;
int lastPage = totalPageInOneFile;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Generate the output file path
string filename = $@"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf";
// Create a new document and attach a writer for the specified output file
using (PdfDocument pdfDocument = new PdfDocument(new PdfWriter(filename)))
{
// Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument);
}
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}
}
}using System;
using iText.Kernel.Pdf;
class Program
{
static void Main(string[] args)
{
string inputPath = "input.pdf";
// Output PDF files path (prefix for the generated files)
string outputPath = "output_split";
int numberOfSplitFiles = 3; // Specify how many parts you want to split the PDF into
// Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles);
}
static void SplitPdfUsingiTextSharp(string inputPdfPath, string outputFolder, int numberOfSplitFiles)
{
using (PdfReader reader = new PdfReader(inputPdfPath))
{
using (PdfDocument doc = new PdfDocument(reader))
{
// Calculate the number of pages for each split file
int totalPageInOneFile = doc.GetNumberOfPages() / numberOfSplitFiles;
int firstPage = 1;
int lastPage = totalPageInOneFile;
for (int i = 1; i <= numberOfSplitFiles; i++)
{
// Generate the output file path
string filename = $@"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf";
// Create a new document and attach a writer for the specified output file
using (PdfDocument pdfDocument = new PdfDocument(new PdfWriter(filename)))
{
// Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument);
}
// Update page range values for the next iteration
firstPage = lastPage + 1;
lastPage += totalPageInOneFile;
}
}
}
}
}Imports System
Imports iText.Kernel.Pdf
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim inputPath As String = "input.pdf"
' Output PDF files path (prefix for the generated files)
Dim outputPath As String = "output_split"
Dim numberOfSplitFiles As Integer = 3 ' Specify how many parts you want to split the PDF into
' Call the SplitPdf method to split the PDF
SplitPdfUsingiTextSharp(inputPath, outputPath, numberOfSplitFiles)
End Sub
Private Shared Sub SplitPdfUsingiTextSharp(ByVal inputPdfPath As String, ByVal outputFolder As String, ByVal numberOfSplitFiles As Integer)
Using reader As New PdfReader(inputPdfPath)
Using doc As New PdfDocument(reader)
' Calculate the number of pages for each split file
'INSTANT VB WARNING: Instant VB cannot determine whether both operands of this division are integer types - if they are then you should use the VB integer division operator:
Dim totalPageInOneFile As Integer = doc.GetNumberOfPages() / numberOfSplitFiles
Dim firstPage As Integer = 1
Dim lastPage As Integer = totalPageInOneFile
For i As Integer = 1 To numberOfSplitFiles
' Generate the output file path
Dim filename As String = $"{outputFolder}\SplitPDF_iTextSharp_{i}.pdf"
' Create a new document and attach a writer for the specified output file
Using pdfDocument As New PdfDocument(New PdfWriter(filename))
' Copy pages from the original document to the new document
doc.CopyPagesTo(firstPage, lastPage, pdfDocument)
End Using
' Update page range values for the next iteration
firstPage = lastPage + 1
lastPage += totalPageInOneFile
Next i
End Using
End Using
End Sub
End ClassCode Explanation
This code demonstrates how to split a large PDF file into smaller chunks using iText. Each smaller PDF document will contain a portion of the original document.
Splitting PDF Using iText
- The main functionality is encapsulated in the
SplitPdfUsingiTextSharpmethod. - The above method takes three parameters:
inputPdfPath,outputFolder, andnumberOfSplitFiles.
Using PdfReader and PdfDocument
Inside the SplitPdfUsingiTextSharp method:
- A
PdfReaderobject namedreaderis created by loading the PDF from the specifiedinputPdfPath. - A
PdfDocumentobject nameddocis initialized using thereader. - The total number of pages in the source PDF is divided by
numberOfSplitFilesto determine how many pages each smaller PDF should contain.
Splitting Process
A loop iterates from 1 to numberOfSplitFiles:
- A new smaller PDF file is created with a filename like "SplitPDF_iText_1.pdf" (for the first split) in the specified output folder.
- Inside this new PDF document (
pdfDocument), pages are copied from the originaldoc: firstPagetolastPage(inclusive) are copied.- The smaller PDF is saved.
- The
firstPageandlastPagevalues are updated for the next iteration.
Note
Ensure that the iText library is properly installed and referenced in your project. Replace "input.pdf" with the actual path to your input PDF file.
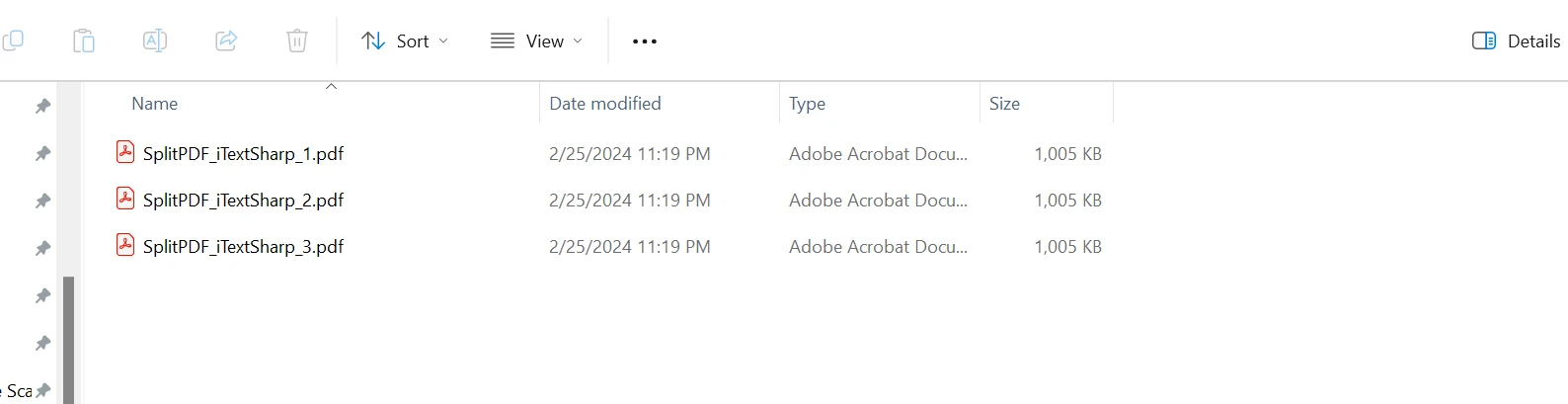
Comparison
To compare the two split methods using iText and IronPDF, let's evaluate them based on several factors:
- Ease of Use:
- iText: The iText method involves creating a PdfReader, PdfDocument, and PdfWriter. It calculates page ranges and copies pages to a new document. This approach requires understanding the iText API.
- IronPDF: The IronPDF method involves creating a PdfDocument from the source file, copying pages, and saving them to a new file. It has a more straightforward API.
- Code Readability:
- iText: The code involves more steps, making it slightly longer and potentially more complex to read.
- IronPDF: The code is concise and more readable due to fewer steps and method calls.
- Performance:
- iText: Performance may be affected by the repeated creation and disposal of PdfDocument instances.
- IronPDF: The method involves fewer steps and offers better performance due to efficient page copying.
- Memory Usage:
- iText: Creating multiple PdfDocument instances will consume more memory.
- IronPDF: The method is more memory-efficient due to its simplified approach.
Conclusion
In conclusion, both iText and IronPDF offer robust solutions for splitting PDF files in C#, each with its own set of advantages. IronPDF stands out for its simplicity, readability, and potentially better performance due to a more straightforward approach.
Developers seeking a balance between versatility and ease of use may find IronPDF to be a compelling choice. Additionally, IronPDF offers a free trial. Ultimately, the selection between iText and IronPDF depends on individual project requirements and the preferred development style.
Frequently Asked Questions
How can I split a PDF in C# while maintaining the original formatting?
You can use IronPDF to split a PDF in C# while preserving its formatting. IronPDF provides a simple API that allows you to load a PDF and specify the page ranges to split, ensuring the original formatting is maintained in the resultant PDFs.
What are the key differences between iTextSharp and IronPDF for splitting PDFs in C#?
The main differences lie in ease of use and performance. IronPDF offers a more straightforward API with fewer steps, making it easier to split PDFs without losing formatting. On the other hand, iTextSharp requires creating multiple instances like PdfReader, PdfDocument, and PdfWriter, which can be more complex.
Can I extract specific pages from a PDF using C#?
Yes, using IronPDF, you can easily extract specific pages from a PDF in C#. By loading the PDF and specifying the desired page numbers, IronPDF allows you to extract and save these pages as a new PDF document.
How does IronPDF improve code readability compared to other PDF libraries?
IronPDF improves code readability by offering a clear and concise API, reducing the need for multiple classes and objects. This simplifies the code needed for PDF manipulation tasks such as splitting, leading to cleaner and more maintainable code.
Is it possible to test PDF splitting functionality in C# before purchasing a library?
Yes, IronPDF offers a free trial that allows developers to test its PDF splitting functionality and other features. This trial period enables you to evaluate its capabilities and performance before making a purchase decision.
What factors should be considered when choosing a PDF library for splitting documents?
When selecting a PDF library, consider factors such as ease of use, API simplicity, performance, and the ability to maintain original document formatting. IronPDF is often preferred for its user-friendly API and efficient performance.
How can I install IronPDF in a Visual Studio C# project?
To install IronPDF in a Visual Studio C# project, use the NuGet Package Manager Console with the command Install-Package IronPdf. You can also add it via the NuGet Package Manager UI or download it from IronPDF's official website.
Can splitting a PDF affect its quality or formatting?
Splitting a PDF with IronPDF ensures that the quality and formatting of the original document are preserved. IronPDF's efficient processing maintains the integrity of the original content.













