

C# Extract Text From PDF (Code Example Tutorial)
PDF (Portable Document Format) files play a vital role in countless industries, enabling businesses to securely share, store, and manage documents. For developers, working with PDFs often involves creating, reading, converting, and extracting content to support client needs. Extracting text from PDFs is essential for tasks like data analysis, document indexing, content migration, or enabling accessibility features. Modern libraries like IronPDF make these tasks easier than ever, offering powerful tools for manipulating PDF files with minimal effort.
This guide focuses on one of the most common requirements: extracting text from a PDF in C#. We'll walk you through setting up a project in Visual Studio, installing IronPDF, and using it to perform text extraction with concise code examples. Along the way, we'll highlight IronPDF's robust features, including its ability to create, manipulate, and convert PDF files using .NET. Whether you're building document-heavy applications or simply need efficient PDF handling, this tutorial will get you started.
How to Extract Text From PDF in C#
- Download Extract Text from PDF C# library
- Create a New Project in Visual Studio
- Install Library to your Project
- Perform Text Extraction from the PDF file
- View your Text Output from PDF Document
1. IronPDF Features
IronPDF is a robust PDF converter that can perform nearly any operation that a browser can. Creating, reading, and manipulating PDF documents is simple with the .NET library for developers. IronPDF converts HTML-to-PDF documents using the Chrome engine. IronPDF supports HTML, ASPX, Razor HTML, and MVC View, among other web components. The Microsoft .NET application is supported by IronPDF (both ASP.NET Web applications and traditional Windows applications). IronPDF can also be used to create a visually appealing PDF document.
We can make a PDF document from HTML5, JavaScript, CSS, and images with IronPDF. Additionally, the files can have headers and footers. Thanks to IronPDF, we can easily read a PDF document. IronPDF also has a comprehensive PDF converting engine and a powerful HTML-to-PDF converter that can handle PDF documents.
- PDF Creation: Generate PDFs from HTML, JavaScript, CSS, images, or URLs. Add headers, footers, bookmarks, watermarks, and other custom elements to enhance the design.
- HTML-to-PDF Conversion: Convert HTML, Razor/MVC Views, and media-type CSS files directly into PDF format.
- Interactive PDF Features: Build, fill, and submit interactive PDF forms.
- Text and Image Extraction: Extract text or images from existing PDF documents for data processing or reuse.
- Document Manipulation: Merge, split, and rearrange pages in new or existing PDF files.
- Image and Page Handling: Rasterize PDF pages to images and convert images to PDF format.
- Work with Custom login credentials: IronPDF is capable of creating a document from a URL. It also supports custom network login credentials, user agents, proxies, cookies, HTTP headers, and form variables for login behind HTML login forms.
- Search and Accessibility: Search for text within PDF documents and ensure they meet accessibility standards.
- Conversion Versatility: Transform PDFs into other formats like HTML and work with CSS files to generate PDFs.
- Standalone Functionality: Operates independently without requiring Adobe Acrobat or additional third-party tools.
2. Creating a New Project in Visual Studio
Open the Visual Studio software and go to the File menu. Select "New Project", and then select "Console Application". In this article, we are going to use a console application to generate PDF documents.
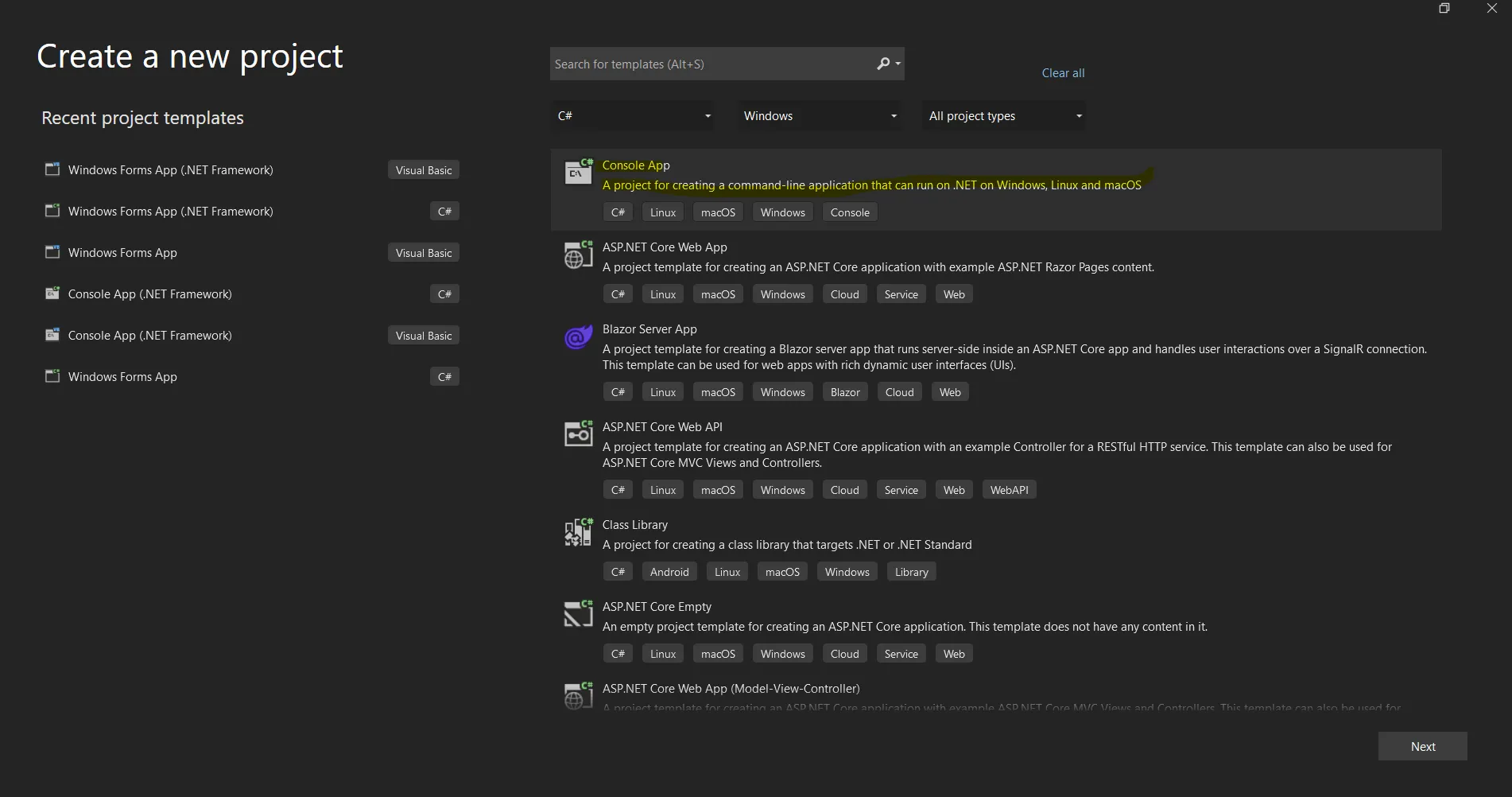 Create a new project in Visual Studio
Create a new project in Visual Studio
Enter the project name and select the file path in the appropriate text box. Then, click the Create button and select the required .NET Framework, as in the screenshot below.
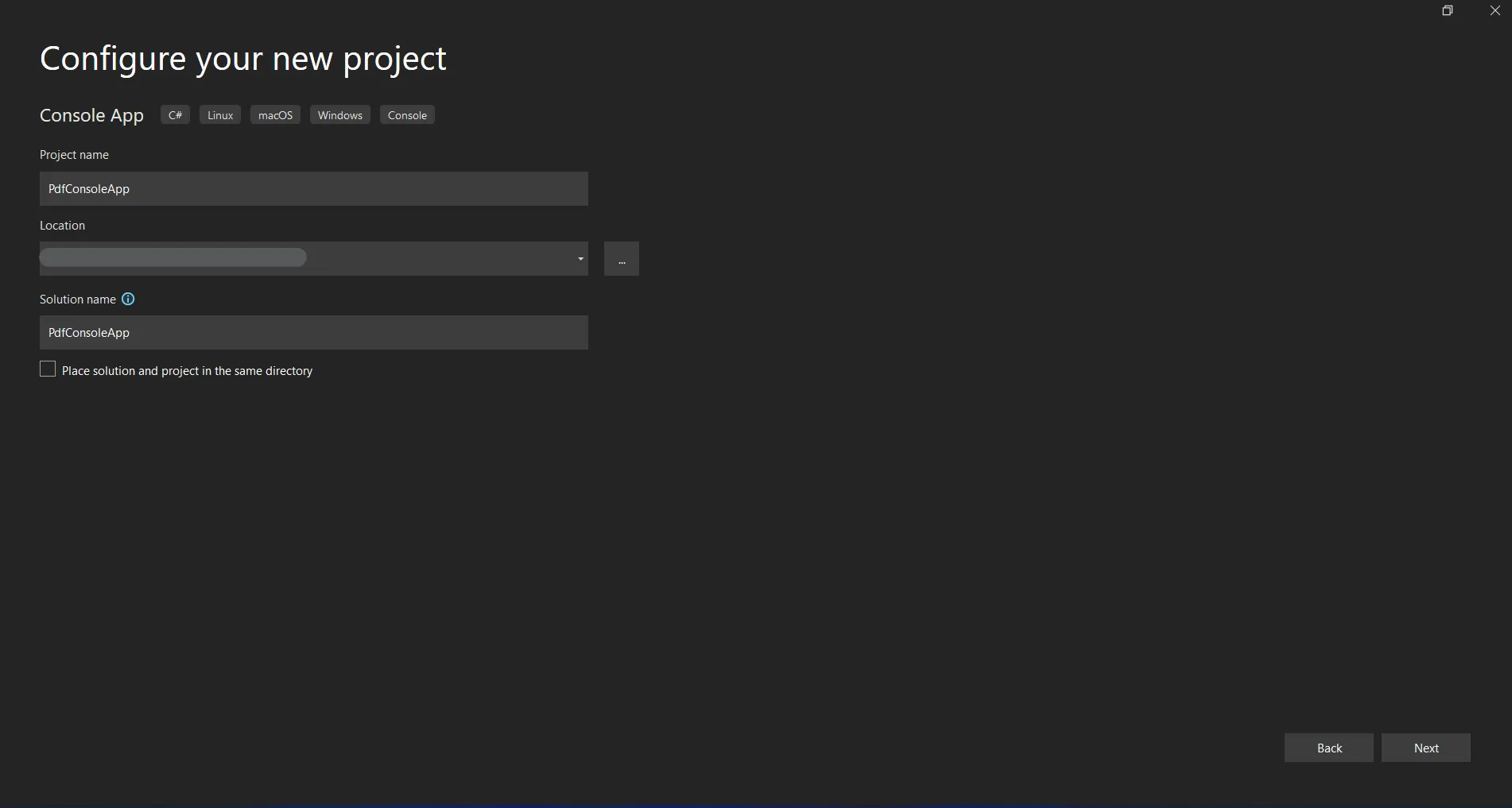 Configure new project in Visual Studio
Configure new project in Visual Studio
The Visual Studio project will now generate the structure for the selected application, and if you have selected the Console, Windows, and Web Application, it will open the program.cs file where you can enter the code and build/run the application.
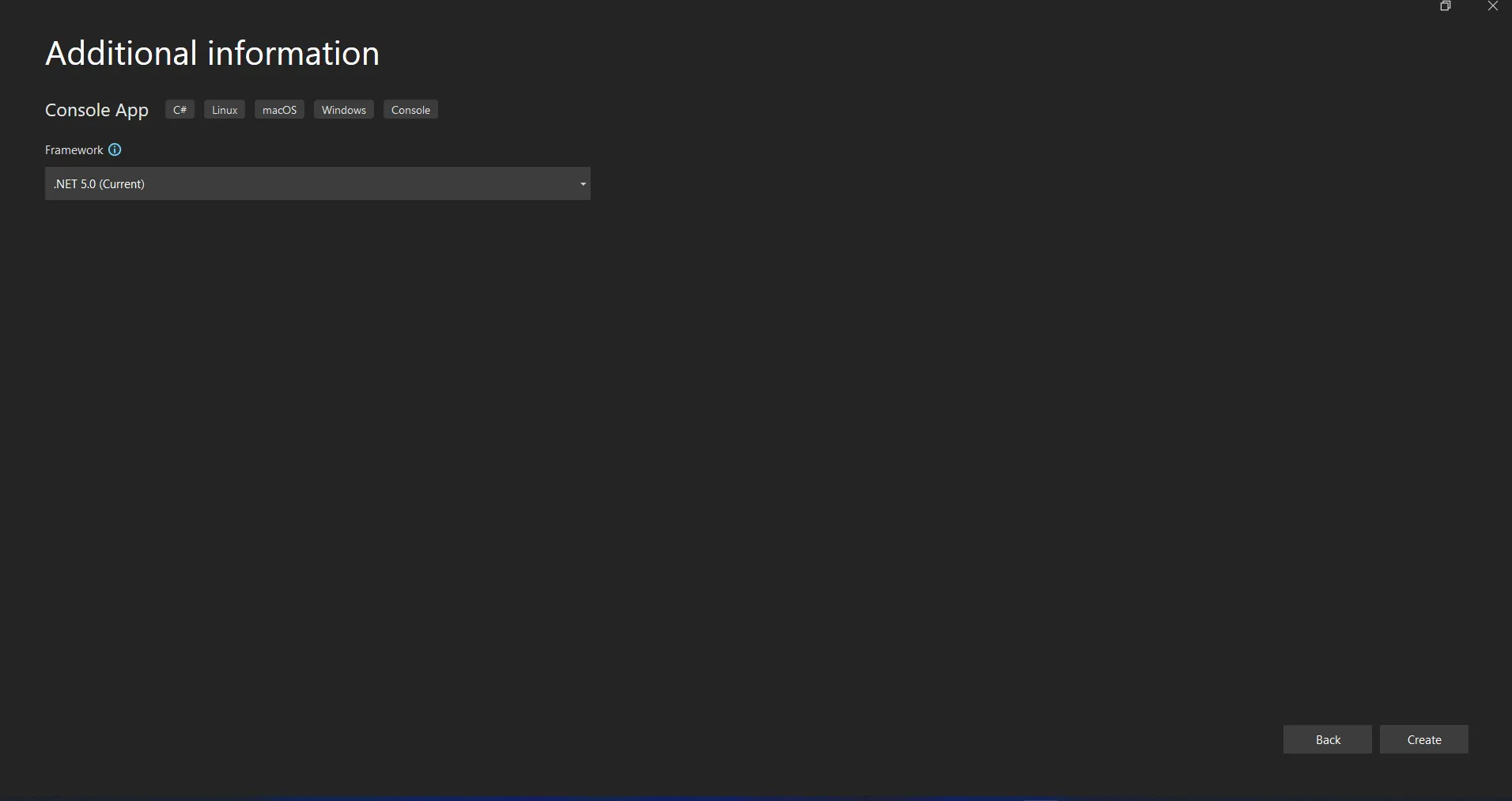 Selecting .NET Core
Selecting .NET Core
Next, we can add the library to test the code.
3. Install the IronPDF Library
The IronPDF Library can be downloaded and installed in four ways.
These are:
- Using Visual Studio.
- Using the Visual Studio Command-Line.
- Direct download from the NuGet website.
- Direct download from the IronPDF website.
3.1 Using Visual Studio
The Visual Studio software provides the NuGet Package Manager option to install the package directly to the solution. The below screenshot shows how to open the NuGet Package Manager.
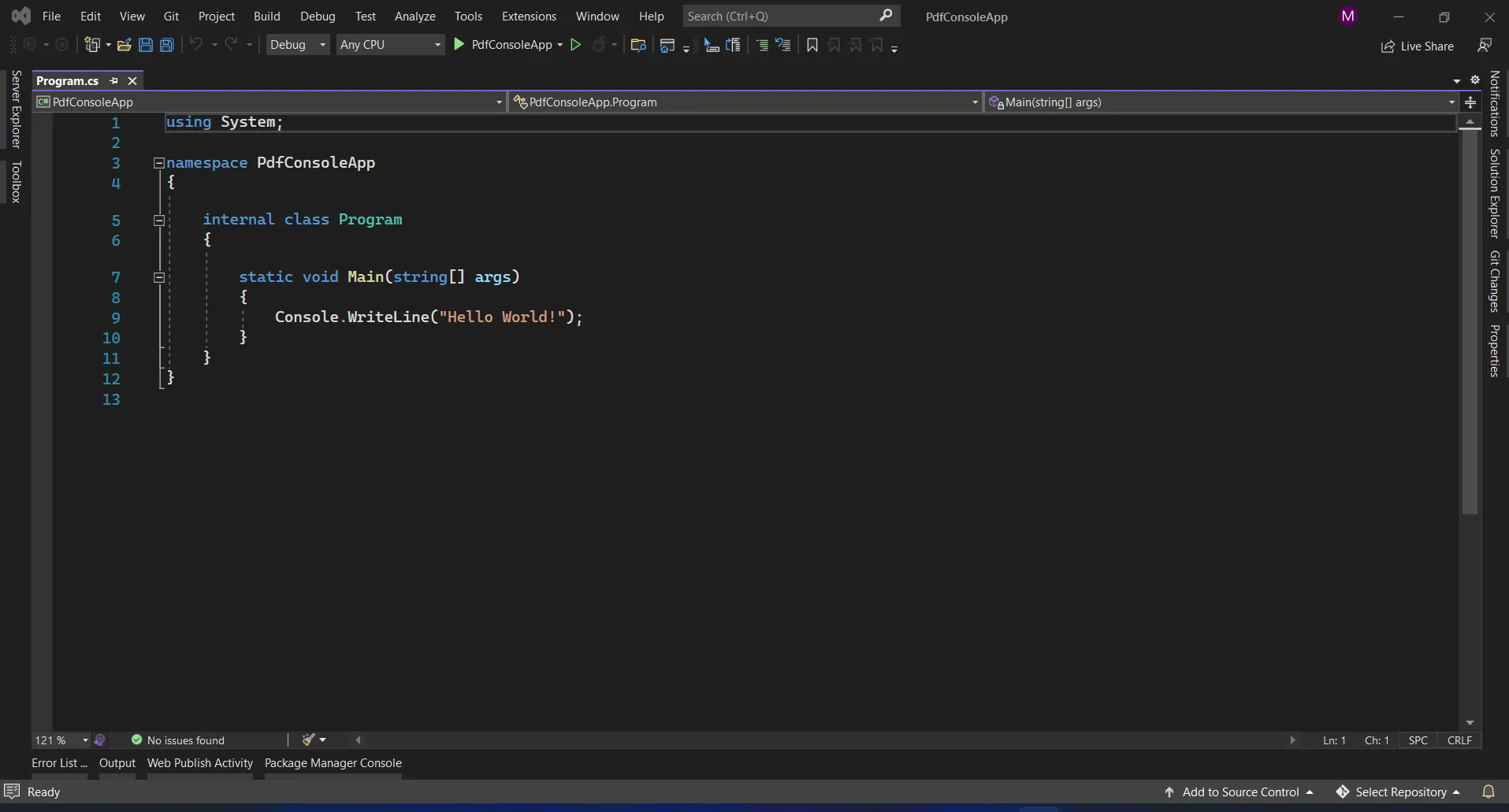 Visual Studio program.cs file
Visual Studio program.cs file
It provides the search box to show the list of packages from the NuGet website. In the package manager, we need to search for the keyword "IronPDF", as in the screenshot below.
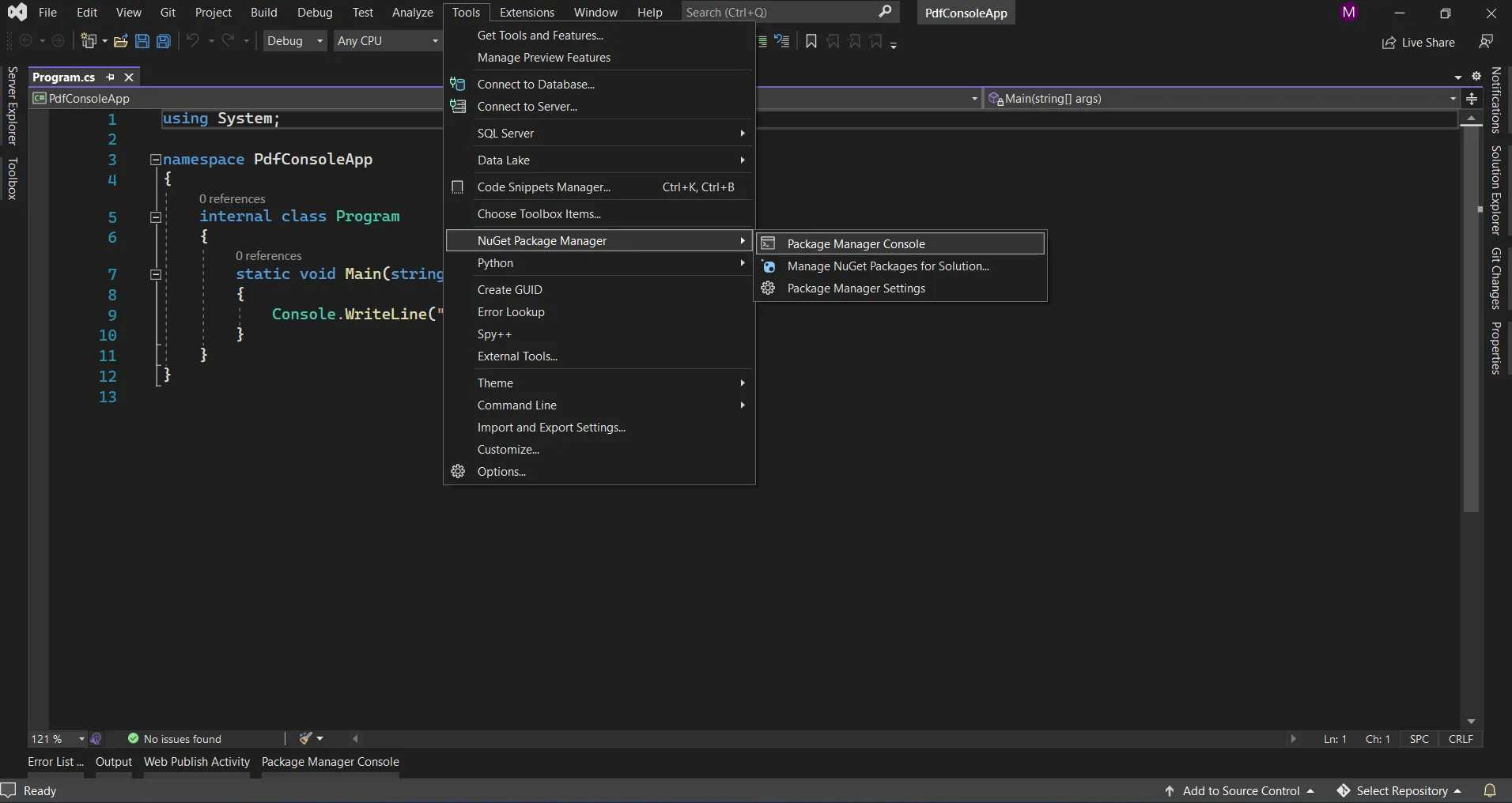 NuGet Package Manager
NuGet Package Manager
In the above image, we can see the list of the related search items. We need to select the required option to install the package to the solution.
3.2 Using the Visual Studio Command-Line
In Visual Studio, go to Tools > NuGet Package Manager > Package Manager Console
Enter the following line in the package manager console tab:
Install-Package IronPdf
Now the package will download/install to the current project and be ready to use.
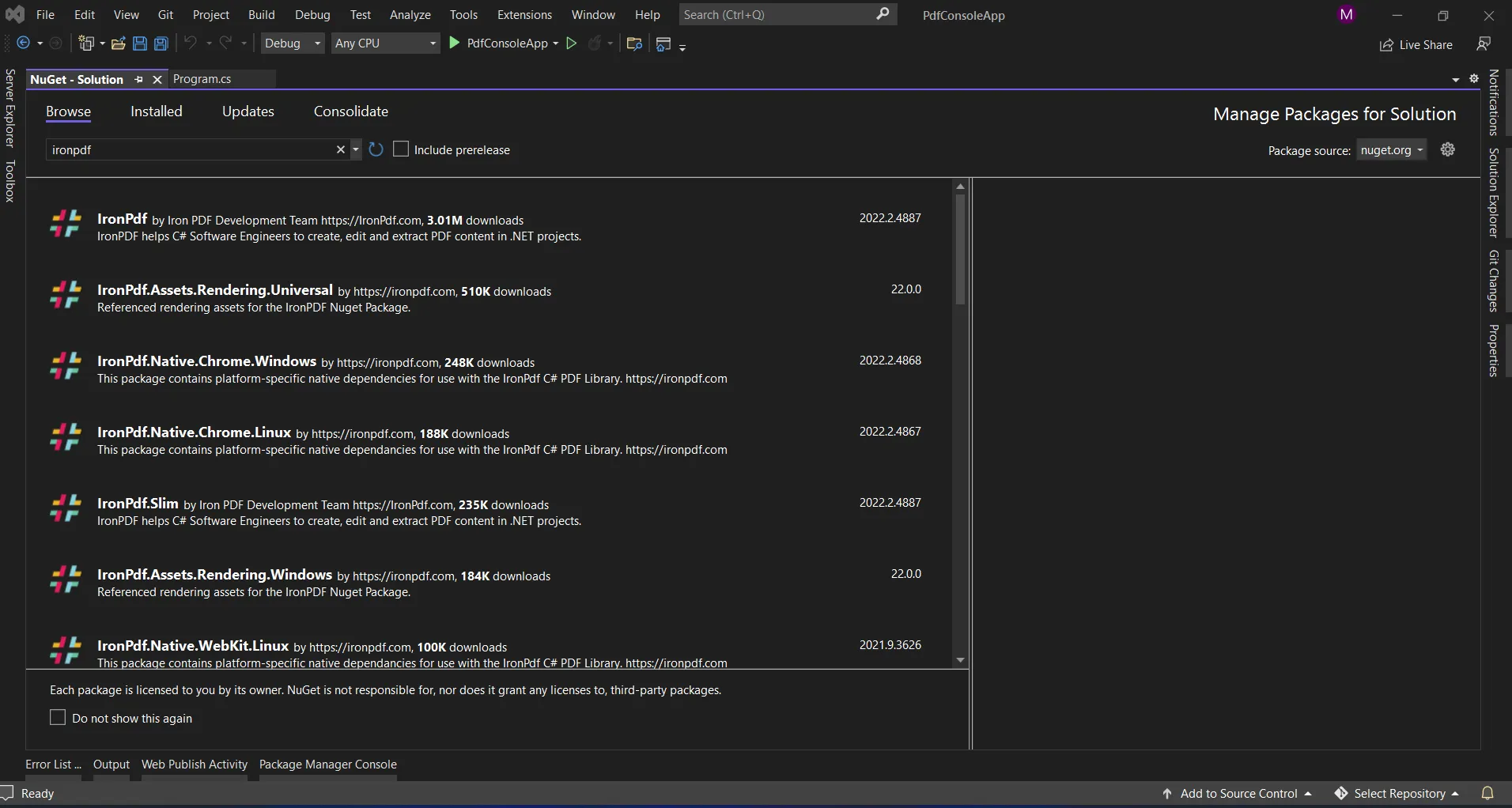 IronPDF library in NuGet Package Manager
IronPDF library in NuGet Package Manager
3.3 Direct download from the NuGet website
The third way is to download the IronPDF NuGet package directly from their website.
- Navigate to the IronPDF package on NuGet.
- Select the download package option from the menu on the right-hand side.
- Double-click the downloaded package. It will be installed automatically.
- Next, reload the solution and start using it in the project.
3.4 Direct download from the IronPDF website
Visit the IronPDF official site to download the latest package directly from their website. Once downloaded, follow the steps below to add the package to the project.
- Right-click the project from the solution window.
- Then, select the options reference and browse the location of the downloaded reference.
- Next, click OK to add the reference.
4. Extract Text Using IronPDF
The IronPDF program allows us to perform text extraction from the PDF file and convert PDF pages into PDF objects. The following is an example of how to use IronPDF to read an existing PDF.
The first approach is to extract text from a PDF and the sample code snippet is below.
using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();Imports IronPdf
' Load an existing PDF document from a file
Private pdfDocument = PdfDocument.FromFile("result.pdf")
' Extract all text from the entire PDF document
Private allText As String = pdfDocument.ExtractAllText()The FromFile static method is used to load the PDF document from an existing file and transform it into PDFDocument objects, as shown in the code above. We can read the text and images accessible on the PDF pages using this object. The object has a method called ExtractAllText which extracts all the text from the whole PDF document, it then holds the extracted text into the string we can use for processing.
Below is the code example for the second method that we can use to extract text from a PDF file, page by page.
using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}Imports IronPdf
' Load an existing PDF document from a file
Private PdfDocument As using
' Loop through each page of the PDF document
For index = 0 To pdf.PageCount - 1
' Extract text from the current page
Dim text As String = pdf.ExtractTextFromPage(index)
Next indexIn the above code, we see that it will first load the whole PDF document and convert it into a PDF object. Then, we obtain the page count of the whole PDF document by using an inbuilt property called PageCount, which retrieves the total number of pages available in the loaded PDF document. Using the "for loop" and ExtractTextFromPage function allows us to pass the page number as a parameter to extract text from the loaded document. It will then hold the exact text into the string variable. Likewise, it will extract text from the PDF page by page with the help of the "for" or the "for each" loop.
5. Conclusion
IronPDF is a versatile and powerful PDF library designed to make working with PDFs in .NET applications seamless. Its robust features enable developers to create, manipulate, and extract content from PDFs without relying on third-party dependencies like Adobe Reader. One of IronPDF's standout capabilities is its ability to extract text from PDF documents. This feature is invaluable for automating tasks like data analysis, document indexing, content migration, and enabling accessibility features. By allowing developers to retrieve and process text programmatically, IronPDF simplifies workflows and opens up new possibilities for handling PDF content.
With straightforward integration and cross-platform support, IronPDF is an excellent choice for developers seeking to handle PDF documents efficiently. Additionally, IronPDF offers a free trial, allowing you to explore its full range of features risk-free before committing. For pricing details and to learn more about licensing options, visit the pricing page.
Frequently Asked Questions
How can I extract text from a PDF document using C#?
You can extract text from a PDF document in C# by using IronPDF. First, load the PDF using the PdfDocument.FromFile method, and then apply the ExtractAllText method to retrieve the text from the document.
What steps are involved in setting up IronPDF in a Visual Studio project?
To set up IronPDF in a Visual Studio project, you can install it via the NuGet Package Manager. Alternatively, you can use the Visual Studio Command-Line or download it directly from the NuGet or IronPDF websites.
What features make IronPDF a comprehensive PDF library?
IronPDF offers a wide range of features including PDF creation, HTML-to-PDF conversion, text and image extraction, document manipulation, and support for interactive PDF forms.
Can IronPDF be used to convert HTML to PDF in C#?
Yes, IronPDF can convert HTML, including Razor/MVC Views and media-type CSS files, directly into PDF format using its integrated Chrome engine.
Is IronPDF compatible with all types of .NET applications?
Yes, IronPDF is compatible with both ASP.NET Web applications and traditional Windows applications, providing versatility for .NET developers.
How does IronPDF facilitate accessibility in PDF documents?
IronPDF enhances accessibility by allowing users to search text within PDF documents and ensuring they adhere to accessibility standards.
Are there any third-party dependencies required for IronPDF?
IronPDF operates independently and does not require third-party tools like Adobe Acrobat, enabling seamless PDF manipulation within your .NET applications.
What are the advantages of using IronPDF for text extraction from PDFs?
IronPDF streamlines workflows by enabling programmatic text extraction, which is useful for data analysis, document indexing, and content migration.
Is a trial version available for IronPDF?
Yes, IronPDF offers a free trial, allowing developers to explore its features and capabilities before making a purchasing decision.
What is the importance of using IronPDF for PDF management in .NET applications?
IronPDF is crucial for PDF management in .NET applications due to its robust feature set, which includes PDF creation, text extraction, and HTML-to-PDF conversion, all without the need for external software like Adobe Acrobat.
Is the C# PDF text extraction code in this article compatible with .NET 10?
Yes. The PdfDocument.FromFile and ExtractText examples in this tutorial work the same way in .NET 10 as they do in earlier .NET versions. After creating a .NET 10 project, install the latest IronPDF package from NuGet and you can run the same code to read PDFs and extract text in modern .NET 10 applications.











