
Cómo Analizar Un Archivo PDF en Python
1.0 Introducción
Las bibliotecas modernas han simplificado la creación de PDFs. Al elegir una biblioteca para proyectos PDF, considere las capacidades de creación, lectura y conversión para una integración y rendimiento óptimos. Python ofrece herramientas como IronPDF que pueden analizar eficientemente PDFs existentes.
2.0 IronPDF
Python es un lenguaje de programación que permite a los desarrolladores construir interfaces gráficas de usuario de forma rápida y sencilla. Ofrece mayor dinamismo para los programadores en comparación con otros lenguajes. Por lo tanto, integrar la biblioteca IronPDF con Python es un proceso sencillo.
Para construir rápidamente y de manera segura una GUI completamente funcional, los desarrolladores pueden utilizar varias herramientas preinstaladas, incluidas PyQt, wxWidgets, Kivy y muchos otros paquetes y bibliotecas. Cabe destacar que IronPDF no es una biblioteca PDF pura de Python; en su lugar, permite la inclusión de varias características de otros marcos como .NET Core.
IronPDF simplifica el diseño y desarrollo web con Python, particularmente debido a la popularidad de los paradigmas de desarrollo web con Python como Django, Flask y Pyramid. Sitios web y servicios en línea notables, incluidos Reddit, Mozilla y Spotify, han utilizado estos marcos. Puede aprender más sobre Python en IronPDF en el sitio web de IronPDF for Python.
2.1 Características de IronPDF
- IronPDF es capaz de generar archivos PDF desde varias fuentes, incluidas HTML, HTML5, ASPX y Razor/MVC View. Proporciona funcionalidad para crear PDFs desde páginas HTML e imágenes.
- El conjunto de herramientas de IronPDF ofrece una gama de herramientas para tareas como crear PDFs interactivos, llenar y enviar formularios interactivos, dividir y combinar archivos PDF, extraer texto e imágenes de archivos PDF, buscar ciertas palabras dentro de un archivo PDF, rasterizar páginas PDF a imágenes, convertir PDF a HTML.
- Con soporte para agentes de usuario, proxies, cookies, encabezados HTTP y variables de forma, IronPDF permite la validación de formularios de inicio de sesión HTML.
- El acceso a documentos protegidos en IronPDF se otorga mediante el uso de nombres de usuario y contraseñas.
- IronPDF ayuda a generar archivos PDF e imprimir con solo unas pocas líneas de código desde varias fuentes como cadenas, flujos, URLs, etc.
3.0 Configuración de Python
3.1 Configuración del entorno
Asegúrese de que Python esté instalado en su PC. Visita el sitio web oficial de Python para descargar e instalar la última versión de Python adecuada para tu sistema operativo. Una vez instalado Python, configura un entorno virtual para aislar las dependencias de tu proyecto. Use el módulo "venv" para crear y administrar entornos virtuales, proporcionando a su proyecto de conversión un espacio de trabajo limpio e independiente.
3.2 Nuevo proyecto en PyCharm
Vamos a utilizar PyCharm, un IDE para escribir código en Python, para esta demostración.
Haga clic en "Nuevo Proyecto" después de iniciar el IDE de PyCharm.
 La pantalla de bienvenida de PyCharm
La pantalla de bienvenida de PyCharm
Cuando selecciona "Nuevo Proyecto", aparecerá una nueva ventana que le permitirá especificar la ubicación del proyecto y su entorno. Esta nueva ventana se puede ver en la captura de pantalla a continuación.
 La pantalla de nuevo proyecto en PyCharm
La pantalla de nuevo proyecto en PyCharm
Haga clic en el botón Crear para iniciar un nuevo proyecto, después de configurar la ubicación del Proyecto y la ruta del entorno. Esto abrirá una nueva ventana donde se puede desarrollar el programa. Este tutorial recomendó Python 3.9.
 Un archivo principal abierto en PyCharm
Un archivo principal abierto en PyCharm
3.3 Requisitos de la biblioteca IronPDF
IronPDF, una biblioteca de Python, depende principalmente de .NET 6.0. Como resultado, para hacer uso de IronPDF for Python, su PC debe tener instalado el entorno de ejecución de .NET 6.0. Antes de que los usuarios de Linux y Mac puedan usar este módulo de Python, es posible que .NET deba ser instalado. Puede obtener el entorno de ejecución requerido desde el sitio web de .NET.
3.4 Configuración de la biblioteca IronPDF
Es necesario instalar el paquete "IronPDF" para crear, editar y abrir archivos con la extensión ".pdf". Para instalar el paquete en PyCharm, abre una ventana de terminal y escribe el siguiente comando:
pip install ironpdfpip install ironpdfLa captura de pantalla a continuación muestra la configuración del paquete 'ironpdf'.
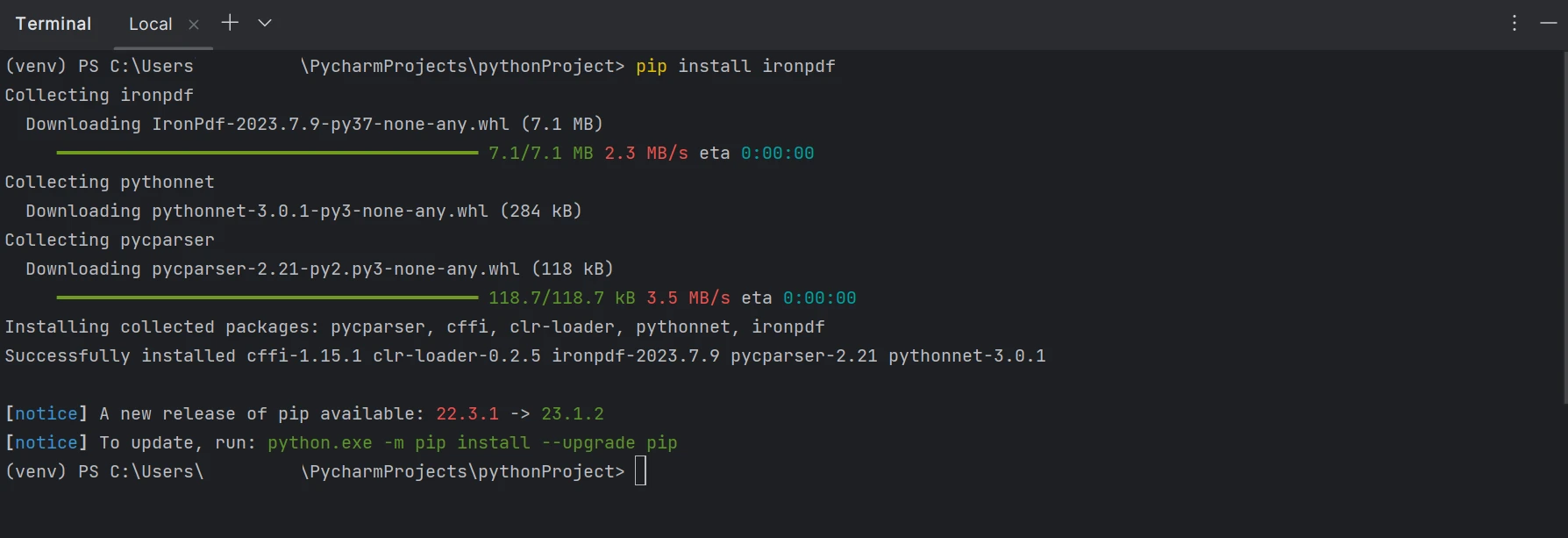 Un terminal que muestra la instalación de IronPDF usando pip
Un terminal que muestra la instalación de IronPDF usando pip
4.0 Analizar PDF con IronPDF
Con la ayuda de las bibliotecas IronPDF, es posible extraer texto de archivos PDF. IronPDF proporciona varias técnicas para la extracción de texto. El primer enfoque consiste en recuperar todo el contenido de la página como una cadena única. El segundo enfoque implica leer el contenido página por página, comenzando desde la primera página. El siguiente fragmento de código demuestra un patrón para inspeccionar archivos PDF actuales utilizando IronPDF.
Existen dos métodos disponibles para extraer datos de un PDF:
- Extraer del PDF por página.
- Extraer todo el PDF como texto.
A continuación se muestra el archivo PDF que vamos a usar para este artículo. Tiene dos páginas.
 Un PDF con el número de página en la parte superior de cada página
Un PDF con el número de página en la parte superior de cada página
4.0.1 EXTRACCIÓN DE TEXTO POR PÁGINAS
El código de muestra proporcionado a continuación demuestra cómo usar el número de página para recuperar datos de un archivo PDF.
from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)from ironpdf import PdfDocument
# Open a PDF file and create a PDF document object
pdfDocument = PdfDocument.FromFile("F:\\PDF\\1.pdf")
# Extract text from the first page (index 0)
AllText = pdfDocument.ExtractTextFromPage(0)
# Print the extracted text from the first page
print(AllText)El fragmento de código demuestra el uso de la función FromFile para leer un archivo PDF y crear un objeto de documento PDF. Este objeto permite el acceso a textos e imágenes dentro del PDF. Para extraer el texto de una página particular, se puede utilizar el método ExtractTextFromPage proporcionando el número de página como parámetro. Este método devolverá una cadena que contiene todas las palabras en la página especificada. La salida se mostrará como a continuación.
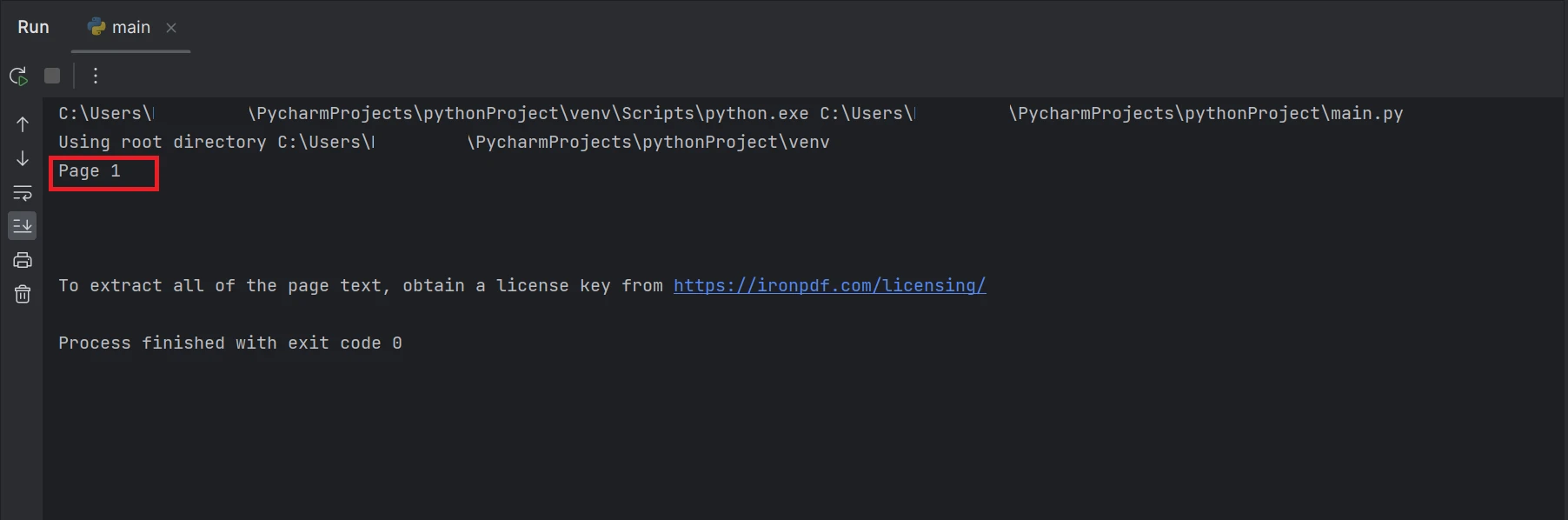 Una captura de pantalla del terminal con salida de texto "Página 1"
Una captura de pantalla del terminal con salida de texto "Página 1"
El cuadro rectangular que se resaltó en el resultado es el texto extraído de los datos del archivo PDF en la página número 1, que tiene el índice 0.
4.0.2 EXTRACTO DE TODAS LAS PÁGINAS
El primer enfoque para obtener rápida y fácilmente todo el contenido del PDF como una cadena se muestra en el ejemplo de código que sigue.
from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)from ironpdf import PdfDocument
# Create a PDF file object from the file path
pdf = PdfDocument.FromFile('F:\\PDF\\1.pdf')
# Extract all text from the entire PDF
all_text = pdf.ExtractAllText()
# Print the extracted text from the entire PDF
print(all_text)El código de ejemplo que se muestra arriba explica cómo leer un PDF desde una ruta de archivo existente y convertirlo en un objeto de archivo PDF usando la función FromFile. El texto simple del PDF se extraerá y se convertirá en una cadena utilizando la función ExtractAllText del objeto e imprimirá el texto extraído en la terminal. El resultado se mostrará como a continuación.
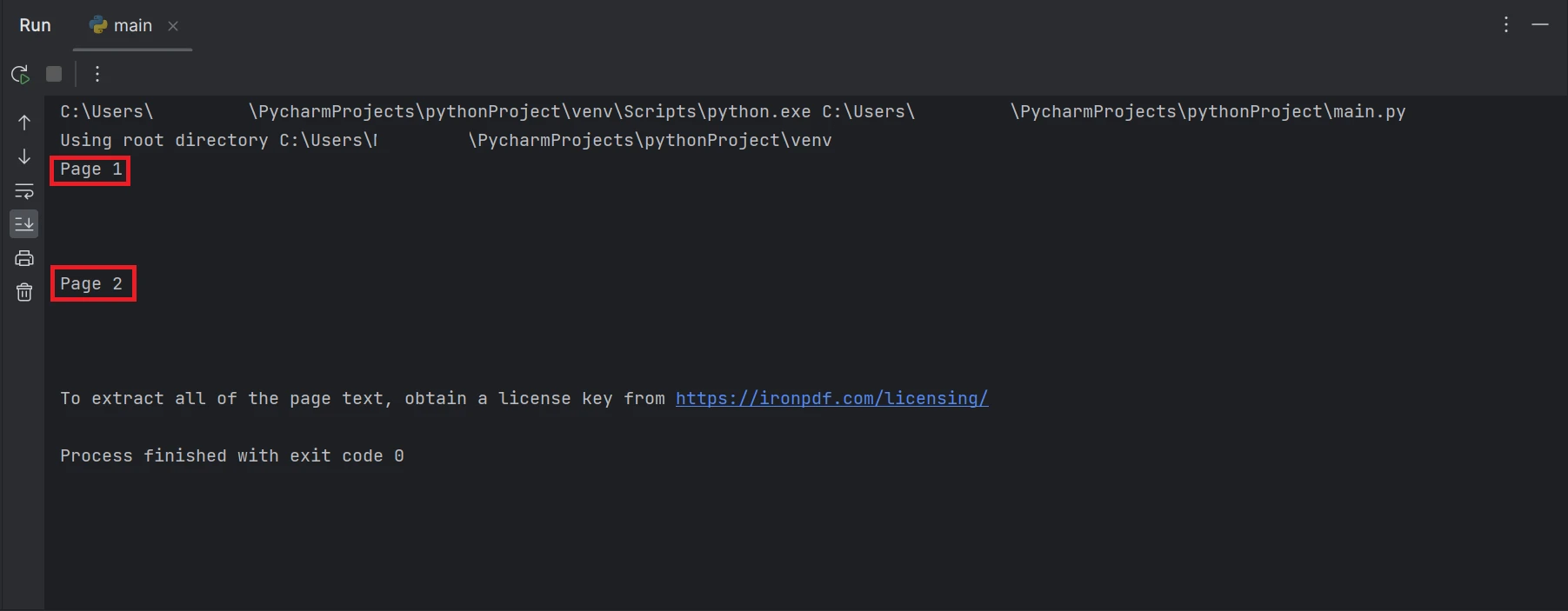 Una captura de pantalla del terminal con salida de texto "Página 1", y "Página 2"
Una captura de pantalla del terminal con salida de texto "Página 1", y "Página 2"
Los cuadros rectangulares que se resaltan en el resultado contienen el texto extraído de todas las páginas del archivo PDF.
Somos capaces de crear PDFs usando C# con la ayuda de IronPDF. Para aprender más sobre IronPDF, visite el sitio web de IronPDF.
5.0 Conclusión
Para minimizar riesgos y asegurar la protección de los datos, la biblioteca IronPDF proporciona medidas de seguridad sólidas. Es compatible con todos los navegadores comúnmente utilizados y no está limitado a ninguno en particular. IronPDF permite a los programadores crear y leer archivos PDF fácilmente con solo unas pocas líneas de código. Para acomodarse a las diversas necesidades de los desarrolladores, la biblioteca IronPDF ofrece una variedad de opciones de licencias, incluyendo una licencia para desarrolladores gratuita y licencias de desarrollo adicionales disponibles para su compra.
El paquete $799 Lite viene con una licencia perpetua, una garantía de devolución de dinero de 30 días, un año de soporte de software y posibilidades de actualización. Más allá de la primera compra, no hay cargos adicionales. Los entornos de producción, pruebas y desarrollo todos hacen uso de estas licencias. IronPDF también ofrece licencias gratuitas con algunas limitaciones de tiempo y redistribución. Durante el período de prueba gratuita, los usuarios pueden probar el producto en uso real sin una marca de agua. Para más detalles sobre el costo y las licencias de la versión de prueba de IronPDF, visite la página de licencias de IronPDF.
Preguntas Frecuentes
¿Cómo puedo analizar documentos PDF usando Python?
Puede analizar documentos PDF en Python usando IronPDF. La biblioteca le permite crear un objeto de documento PDF y usar métodos como ExtractTextFromPage para extraer texto de páginas específicas o ExtractAllText para extraer texto de todo el documento.
¿Cuáles son los requisitos previos para ejecutar IronPDF en un entorno Python?
Para ejecutar IronPDF en un entorno Python, necesita tener el tiempo de ejecución de .NET 6.0 instalado en su sistema, ya que IronPDF depende de .NET para sus operaciones.
¿Se puede usar IronPDF con marcos web populares de Python?
Sí, IronPDF se integra perfectamente con marcos web populares de Python como Django, Flask y Pyramid, lo que lo convierte en una herramienta versátil para proyectos de desarrollo web.
¿Cómo se instala IronPDF en un entorno virtual de Python?
Para instalar IronPDF en un entorno virtual de Python, primero asegúrese de tener Python instalado y cree un entorno virtual. Use el comando pip install ironpdf en la terminal de su IDE para instalar el paquete.
¿Cuáles son algunas características clave de IronPDF para desarrolladores de Python?
IronPDF ofrece características como generar PDFs desde HTML, imágenes, cadenas y flujos, crear PDFs interactivos, rellenar formularios, dividir y combinar PDFs, y extraer texto e imágenes.
¿Es IronPDF compatible con diferentes sistemas operativos?
Sí, IronPDF es compatible con diferentes sistemas operativos. Sin embargo, los usuarios de Linux y Mac deben asegurarse de que .NET esté instalado en sus sistemas para usar el módulo de Python.
¿Qué opciones de licencia están disponibles para IronPDF?
IronPDF ofrece varias opciones de licencia, incluyendo una licencia de desarrollador gratuita con limitaciones y un paquete Lite de pago con licencia perpetua y garantía de devolución de dinero de 30 días. Estas opciones proporcionan flexibilidad según sus necesidades de desarrollo.
¿Cómo puede configurar un nuevo proyecto de IronPDF en PyCharm?
Para configurar un nuevo proyecto de IronPDF en PyCharm, abra el IDE, haga clic en 'New Project' y configure la ubicación y el entorno del proyecto. Use la terminal en PyCharm para instalar IronPDF con pip install ironpdf.
¿Cómo asegura IronPDF la seguridad de los documentos PDF?
IronPDF incorpora medidas de seguridad sólidas para garantizar la seguridad e integridad de los documentos PDF, lo que lo convierte en una opción confiable para aplicaciones que requieren manejo de PDFs.
¿Se puede utilizar IronPDF para extraer imágenes de PDFs?
Sí, IronPDF se puede usar para extraer imágenes de PDFs accediendo al objeto de documento y utilizando los métodos apropiados para recuperar datos de imágenes.
















