
C# Trim(開発者向けの仕組み)
テキストの操作は、あらゆる.NET開発者にとって不可欠なスキルです。 ユーザー入力の文字列を整理したり、分析のためにデータをフォーマットしたり、ドキュメントから抽出されたテキストを処理したりする場合、適切なツールを持っていることが違いを生みます。 PDFを扱う際には、その非構造的な性質のために、テキストの管理と処理が困難になることがあります。 そこで、C#でPDFを扱う強力なライブラリであるIronPDFが活躍します。
この記事では、IronPDFと組み合わせてC#のTrim()メソッドを効果的に使用して、PDFドキュメントからテキストを整理および処理する方法を探ります。
C# Trim()の理解
テキストトリミングとは?
Trim()メソッドは、文字列の先頭と末尾から空白または指定された文字を削除します。 例えば:
string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!"string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!"Dim text As String = " Hello World! "
Dim trimmedText As String = text.Trim() ' Output: "Hello World!"文字列から # 記号を削除するなど、特定の文字をターゲットにすることもできます。
string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important"string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important"Dim text As String = "###Important###"
Dim trimmedText As String = text.Trim("#"c) ' Output: "Important"特定の位置からのトリミング
C# では、文字列の先頭または末尾から文字を削除するための TrimStart() と TrimEnd() が提供されています。 例えば:
string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World"string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World"Dim str As String = "!!Hello World!!"
Dim trimmedStart As String = str.TrimStart("!"c) ' "Hello World!!"
Dim trimmedEnd As String = str.TrimEnd("!"c) ' "!!Hello World"一般的な落とし穴と解決策
1. Null参照例外
null 文字列で Trim() を呼び出すと、エラーが発生します。 これを避けるには、ヌル合体演算子または条件チェックを使用してください。
string text = null;
string safeTrim = text?.Trim() ?? string.Empty;string text = null;
string safeTrim = text?.Trim() ?? string.Empty;Dim text As String = Nothing
Dim safeTrim As String = If(text?.Trim(), String.Empty)2. 不変性のオーバーヘッド
C# の文字列は不変であるため、ループ内で操作を繰り返し実行するとパフォーマンスが低下する可能性があります。 大規模なデータセットの場合は、Span<t> を使用するか、変数を再利用することを検討してください。
3. 有効な文字の過剰トリミング
必要な文字を誤って削除するのは一般的なミスです。 空白でない内容を扱う場合、正確にトリムする文字を指定してください。
4. Unicodeの空白
デフォルトの Trim() メソッドは、特定の Unicode 空白文字 (例: \u2003) を処理しません。 これに対処するには、トリムパラメーターに明示的に含めてください。
効率的なトリミングのための高度な技術
正規表現の統合
複雑なパターンの場合は、Trim() を正規表現と組み合わせます。 例えば、複数のスペースを置換するには:
string cleanedText = Regex.Replace(text, @"^\s+|\s+$", "");string cleanedText = Regex.Replace(text, @"^\s+|\s+$", "");Dim cleanedText As String = Regex.Replace(text, "^\s+|\s+$", "")パフォーマンス最適化
大規模なテキストを処理する際は、繰り返しトリミング操作を避けます。 前処理にはStringBuilderを使用します。
var sb = new StringBuilder(text);
// Custom extension method to trim once
// Assuming a Trim extension method exists for StringBuilder
sb.Trim();var sb = new StringBuilder(text);
// Custom extension method to trim once
// Assuming a Trim extension method exists for StringBuilder
sb.Trim();Dim sb = New StringBuilder(text)
' Custom extension method to trim once
' Assuming a Trim extension method exists for StringBuilder
sb.Trim()文化固有のシナリオの処理
Trim() はカルチャに依存しませんが、まれにロケールに依存するトリミングに CultureInfo を使用できます。
PDF処理でトリミングを使用する理由
PDFからテキストを抽出する際、特殊な記号や不要なスペース、フォーマットアーティファクトなどの前後の文字に頻繁に遭遇します。 例えば:
- 書式の不一致: PDFの構造は、不要な改行や特殊文字をもたらす可能性があります。
- 後続の空白文字は、特にレポートのためにデータを整列するとき、テキスト出力を乱します。
- OCR で生成されたコンテンツでは、先頭と末尾に記号 (例:
-) が頻繁に出現します。
Trim() を使用すると、現在の文字列オブジェクトをクリーンアップし、後続の操作に備えることができます。
PDF処理にIronPDFを選ぶ理由
IronPDFは.NETのための強力なPDF操作ライブラリで、PDFファイルの操作を簡単にします。 最小限のセットアップとコーディングでPDFからコンテンツを生成、編集、抽出する機能を提供します。 以下はIronPDFが提供する主な特徴のいくつかです:
- HTML から PDF への変換: IronPDF はHTML コンテンツ(CSS、画像、JavaScript を含む)を完全にフォーマットされた PDF に変換できます。 これは、動的なウェブページやレポートをPDFとしてレンダリングするのに特に有用です。
- PDF 編集: IronPDFを使用すると、既存のPDFドキュメントにテキスト、画像、およびグラフィックを追加し、既存のページのコンテンツを編集することができます。
- テキストと画像の抽出: このライブラリを使用すると、PDFからテキストや画像を抽出でき、PDFコンテンツを解析し分析するのが容易になります。
- フォーム入力: IronPDFはPDFのフォームフィールド入力をサポートしており、カスタマイズされたドキュメントの生成に便利です。
- 透かし: PDFドキュメントに透かしを追加して、ブランディングや著作権保護をすることも可能です。
トリミング作業にIronPDFを使用する利点
IronPDFは非構造化PDFデータの処理に優れ、効率的にテキストを抽出、整理、および処理するのが容易です。 ユースケースには次のようなものがあります:
- 抽出したデータの整理: データベースに格納する前に不要な空白や文字を削除します。
- 分析のためのデータ準備: データの可読性を高めるためにトリミングしてフォーマットします。
C#でIronPDFを使ったテキストトリミングの実装
IronPDFプロジェクトの設定
まず、NuGetを介してIronPDFをインストールします。
- Visual Studioでプロジェクトを開きます。
- NuGet パッケージマネージャーコンソールで次のコマンドを実行します。
Install-Package IronPdf
- ライセンスをすでに持っていない場合、IronPDFの無料トライアルをダウンロードして、そのフル機能をロック解除します。
ステップバイステップの例: PDFからのテキストのトリミング
以下は、PDF からテキストを抽出し、Trim() を使用して指定された文字を削除してクリーンアップする方法の完全な例です。
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
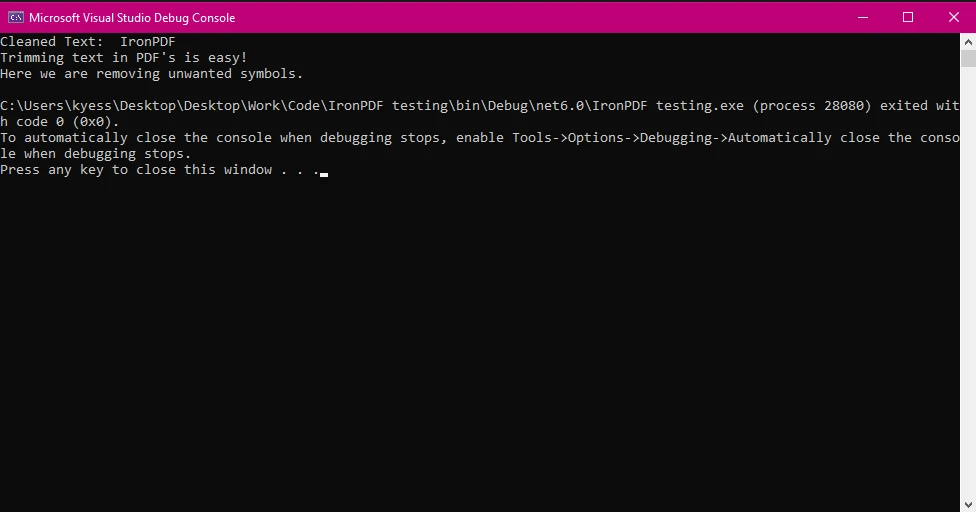
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("trimSample.pdf")
' Extract text from the PDF
Dim extractedText As String = pdf.ExtractAllText()
' Trim whitespace and unwanted characters
Dim trimmedText As String = extractedText.Trim("*"c)
' Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}")
End Sub
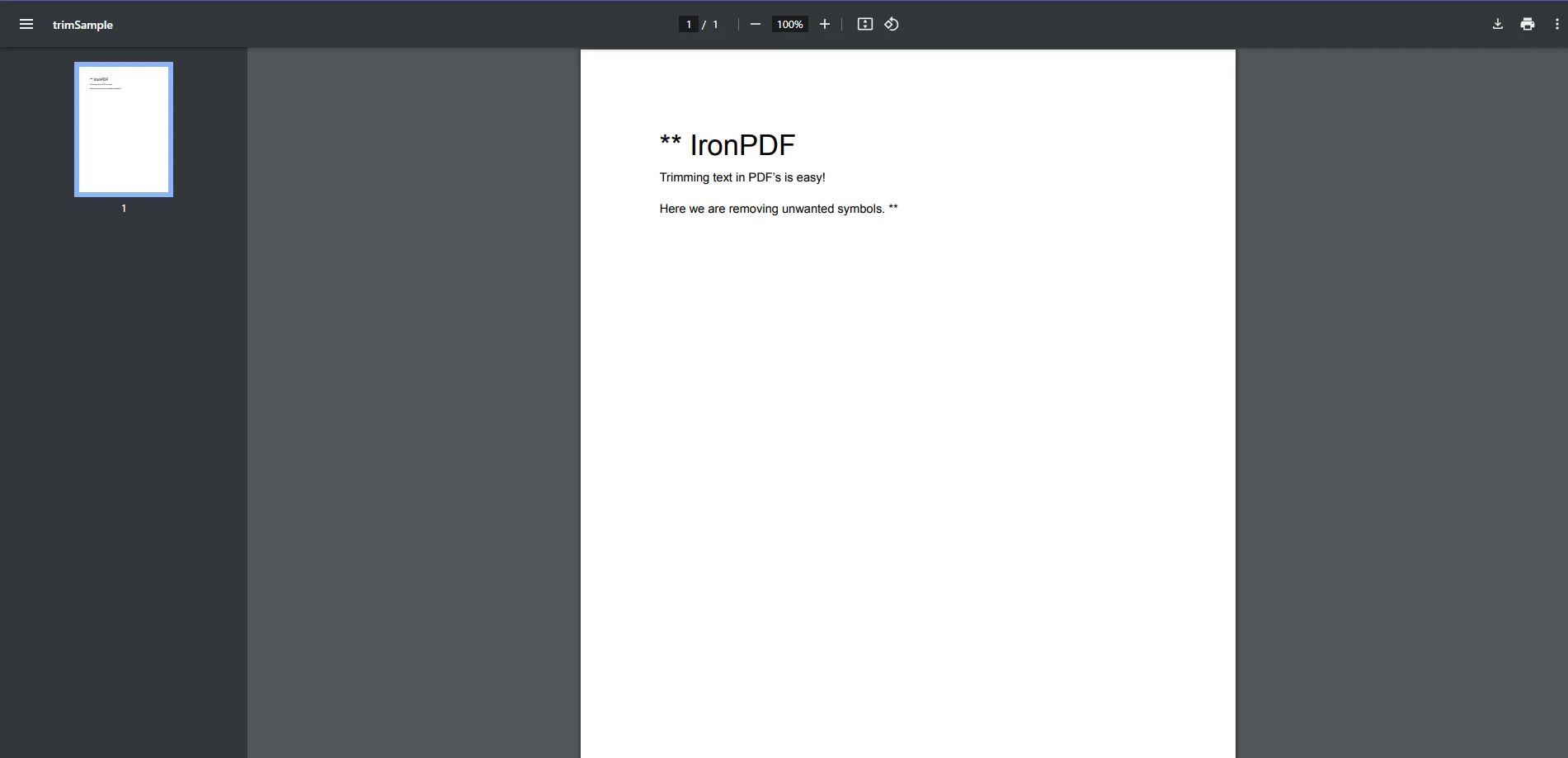
End Class入力PDF:
コンソール出力:
実際のアプリケーションの探求
請求書処理の自動化
PDF請求書からテキストを抽出し、不要な内容をトリミングし、合計や請求書IDのような重要な詳細を解析します。 例:
- IronPDFを使用して請求書データを読み取ります。
- フォーマットの一貫性を保つために空白をトリムします。
OCR出力の清掃
光学文字認識(OCR)はしばしばノイズの多いテキストを生成します。 IronPDFのテキスト抽出とC#のトリミング機能を使用して、さらなる処理や分析のために出力を清掃できます。
結論
効率的なテキスト処理は、特にPDFからの非構造化データを扱う際に、.NET開発者にとって重要なスキルです。 Trim() メソッド、特に public string Trim() を IronPDF の機能と組み合わせると、先頭と末尾の空白、指定された文字、さらには Unicode 文字を削除してテキストをクリーンアップおよび処理する信頼性の高い方法が提供されます。
TrimEnd() のようなメソッドを適用して末尾の文字を削除したり、末尾のトリム操作を実行したりすることで、ノイズの多いテキストをレポート、自動化、分析に使用できるコンテンツに変換できます。 この方法により、開発者は既存の文字列を正確にトリミングし、PDFを含むワークフローを効率化することができます。
IronPDF の強力な PDF 操作機能と C# の多用途な Trim() メソッドを組み合わせることで、正確なテキスト書式設定を必要とするソリューションの開発にかかる時間と労力を節約できます。 従来数時間を要したタスク、例えば不要な空白の削除、OCRで生成されたテキストの清掃、抽出データの標準化などが、今や数分で完了できます。
今日、PDF処理能力を次のレベルに引き上げ—IronPDFの無料トライアルをダウンロードし、それが.NET開発経験をどのように変革するかを直接確認してください。 初心者であろうと、経験豊富な開発者であろうと、IronPDFはよりスマートで、より速く、より効率的なソリューションを構築するためのパートナーです。
よくある質問
C# で HTML を PDF に変換するにはどうすればいいですか?
IronPDF の RenderHtmlAsPdf メソッドを使用して、HTML 文字列を PDF に変換できます。RenderHtmlFileAsPdf を使用して HTML ファイルを PDF に変換することもできます。
C#のTrim()メソッドとは何で、どのように使用されますか?
C#のTrim()メソッドは、文字列の先頭と末尾から空白または指定された文字を削除するもので、テキストデータをクリーンアップするのに役立ちます。文書の処理では、抽出したテキストから不要なスペースや文字を削除するのに役立ちます。
C#でTrim()を使用する際、null文字列をどのように扱いますか?
null文字列に対してTrim()を安全に呼び出すには、null合体演算子や条件チェックを使用します。例えば、string safeTrim = text?.Trim() ?? string.Empty;のようにします。
C#でTrimStart()とTrimEnd()メソッドは何に使われますか?
TrimStart()とTrimEnd()は、文字列の先頭または末尾から文字を削除するためのC#メソッドです。それらは、より正確なトリミング作業に役立ちます。
文書処理において、テキストトリミングが重要なのはなぜですか?
トリミングは、PDFから抽出したテキストをきれいにし、先頭と末尾の空白、特殊記号、およびフォーマットアーティファクトを除去するために重要です。特に非構造化データを扱う際に重要です。
C#のTrim()を使用する際の一般的な問題は何ですか?
一般的な問題として、null参照例外、変更不可能性によるパフォーマンス低下、有効な文字の過度なトリミング、Unicode空白の処理があります。
IronPDFはPDFからのテキストトリミングをどのように支援しますか?
IronPDFはPDFからテキストを抽出するためのツールを提供し、開発者がデータを格納または解析する際にトリミングしてクリーンにできるようにします。.NETアプリケーション内でC#のTrim()と組み合わせて効果的なテキスト操作を行えます。
C#のTrim()はUnicode空白を効果的に処理できますか?
デフォルトのTrim()メソッドは、特定のUnicode空白を処理しません。これを解決するには、それらを明示的にトリムパラメーターに含める必要があります。
C#で効率的なトリミングのための高度な技術とは何ですか?
高度な技術には、正規表現と組み合わせて複雑なパターンを扱うことや、大規模なテキスト処理作業でパフォーマンスを最適化するためにStringBuilderを使用することがあります。
.NETライブラリをPDF処理に選ぶ理由は?
強力な.NETライブラリは、HTMLからPDFへの変換、PDF編集、テキストおよび画像の抽出、フォーム入力、透かし入れなどの機能を提供し、包括的なドキュメント処理に欠かせません。
C#のTrim()を実際のドキュメント処理シナリオにどのように適用できますか?
C#のTrim()は、請求書処理の自動化において重要な詳細をクリーンに解析したり、IronPDFの抽出機能を用いてOCR出力をクリーンにしてさらなる分析を行うなど、.NET開発のワークフローを強化します。














