
C#削減(對開發者如何理解其工作)
文字處理是任何 .NET 開發人員的基本技能。 無論您是要清理使用者輸入的字串、格式化資料以供分析,或是處理從文件中萃取的文字,擁有合適的工具都能讓您的工作與眾不同。 在處理 PDF 時,由於其非結構化的特性,有效率地管理和處理文字可能是一項挑戰。 這正是 IronPDF(一個用 C# 處理 PDF 的強大程式庫)發揮作用的地方。
在本文中,我們將探討如何利用 C# 的 Trim() 方法結合 IronPDF 來有效地清理和處理 PDF 文件中的文字。
瞭解 C# Trim()
什麼是文字修剪?
Trim() 方法會移除字串首尾的空白或指定字元。 舉例來說
string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!"string text = " Hello World! ";
string trimmedText = text.Trim(); // Output: "Hello World!"Dim text As String = " Hello World! "
Dim trimmedText As String = text.Trim() ' Output: "Hello World!"您也可以針對特定字元進行操作,例如從字串中刪除 # 符號:
string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important"string text = "###Important###";
string trimmedText = text.Trim('#'); // Output: "Important"Dim text As String = "###Important###"
Dim trimmedText As String = text.Trim("#"c) ' Output: "Important"從特定位置裁剪
C# 提供了 TrimStart() 和 TrimEnd() 來從字串的開頭或結尾刪除字元。 舉例來說
string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World"string str = "!!Hello World!!";
string trimmedStart = str.TrimStart('!'); // "Hello World!!"
string trimmedEnd = str.TrimEnd('!'); // "!!Hello World"Dim str As String = "!!Hello World!!"
Dim trimmedStart As String = str.TrimStart("!"c) ' "Hello World!!"
Dim trimmedEnd As String = str.TrimEnd("!"c) ' "!!Hello World"常見陷阱與解決方案
1.空引用異常
對 null 字串呼叫 Trim() 會引發錯誤。 為了避免這種情況,請使用 null-coalescing 運算符或條件檢查:
string text = null;
string safeTrim = text?.Trim() ?? string.Empty;string text = null;
string safeTrim = text?.Trim() ?? string.Empty;Dim text As String = Nothing
Dim safeTrim As String = If(text?.Trim(), String.Empty)2.不變性開銷
由於 C# 中的字串是不可變的,因此在循環中重複執行 Trim() 操作會降低效能。 對於大型資料集,請考慮使用 Span<T> 或重複使用變數。
3.過度修剪有效字元
不小心刪除必要的字元是常見的錯誤。 在處理非空白內容時,請務必指定要修剪的精確字元。
4.Unicode空白
預設的 Trim() 方法無法處理某些 Unicode 空白字元(例如 \u2003)。 針對這一點,請在修剪參數中明確包含它們。
高效修剪的進階技術
Regex 整合
對於複雜的模式,請將 Trim() 與正規表示式結合使用。 例如,取代多個空格:
string cleanedText = Regex.Replace(text, @"^\s+|\s+$", "");string cleanedText = Regex.Replace(text, @"^\s+|\s+$", "");Dim cleanedText As String = Regex.Replace(text, "^\s+|\s+$", "")效能最佳化
處理大篇幅文字時,請避免重複修剪作業。 使用 StringBuilder 進行預處理:
var sb = new StringBuilder(text);
// Custom extension method to trim once
// Assuming a Trim extension method exists for StringBuilder
sb.Trim();var sb = new StringBuilder(text);
// Custom extension method to trim once
// Assuming a Trim extension method exists for StringBuilder
sb.Trim();Dim sb = New StringBuilder(text)
' Custom extension method to trim once
' Assuming a Trim extension method exists for StringBuilder
sb.Trim()處理特定文化場景
雖然 Trim() 不區分區域設置,但在極少數情況下,您可以使用 CultureInfo 進行區域設置相關的修剪。
為什麼要在 PDF 處理中使用修剪?
從 PDF 擷取文字時,經常會遇到前導字元和尾隨字元,例如特殊符號、不必要的空格或格式化假象。 舉例來說
- 格式不一致:PDF 結構可能導致不必要的換行或特殊字符。
- 拖尾空白字元會使文字輸出雜亂無章,尤其是在對齊報告資料時。
- 符號的開頭和結尾(例如,
*,-)經常出現在 OCR 產生的內容中。
使用 Trim() 可以清理目前字串對象,並為其進行進一步操作做好準備。
為什麼選擇 IronPDF 進行 PDF 處理?
IronPDF是適用於 .NET 的強大 PDF 操作函式庫,其設計目的在於讓 PDF 檔案的處理變得更輕鬆。 它提供的功能可讓您以最少的設定和編碼工作,從 PDF 中產生、編輯和擷取內容。 以下是 IronPDF 提供的一些主要功能:
- HTML 到 PDF 的轉換: IronPDF 可以將 HTML 內容(包括 CSS、圖片和 JavaScript)轉換為格式完整的 PDF。 這對於呈現動態網頁或 PDF 格式的報告尤其有用。
- PDF 編輯:使用 IronPDF,您可以透過新增文字、影像和圖形,以及編輯現有頁面的內容,來操作現有的 PDF 文件。
- 文字和圖像萃取:該函式庫可讓您從 PDF 中萃取文字和圖像,讓您輕鬆解析和分析 PDF 內容。
- 表格填寫: IronPDF 支援在 PDF 中填寫 表格欄位,這對於產生客製化文件非常有用。
- 水印:也可以在 PDF 文件中加入 水印,以進行品牌或版權保護。
使用 IronPDF 執行裁剪任務的優點
IronPDF 擅長處理非結構化 PDF 資料,可輕鬆有效地抽取、清理及處理文字。 使用個案包括
- 清理擷取的資料:在將資料儲存在資料庫之前,先移除不必要的空白或字元。
- 準備分析資料:修剪和格式化資料,以提高可讀性。
Implementing Text Trimming with IronPDF in C#
設定您的 IronPDF 專案。
首先透過 NuGet 安裝 IronPDF:
1.在 Visual Studio 中開啟您的專案。 2.在 NuGet Package Manager Console 中執行下列指令:
Install-Package IronPdf
1.如果您尚未擁有 IronPDF 授權,請下載 免費試用版,以釋放它的全部潛力。
逐步示例:從 PDF 中修剪文字
以下是一個完整的範例,示範如何從 PDF 中提取文字並使用 Trim() 刪除指定字元:
using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
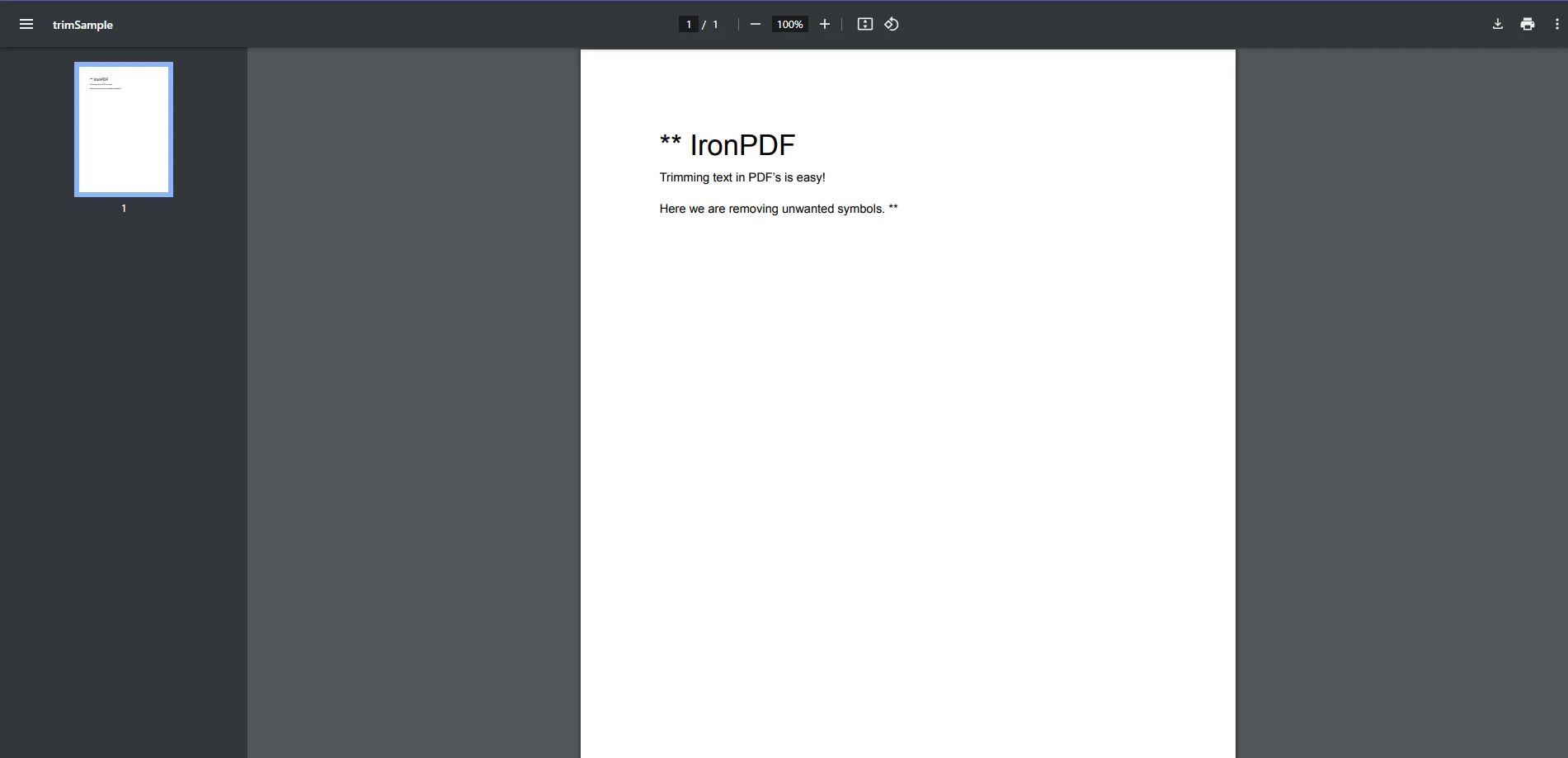
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
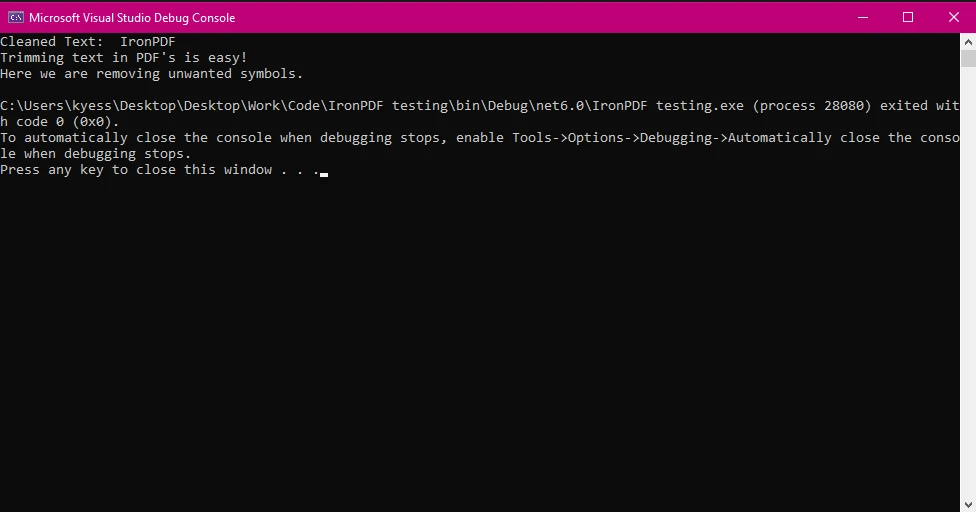
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}using IronPdf;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("trimSample.pdf");
// Extract text from the PDF
string extractedText = pdf.ExtractAllText();
// Trim whitespace and unwanted characters
string trimmedText = extractedText.Trim('*');
// Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}");
}
}Imports IronPdf
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("trimSample.pdf")
' Extract text from the PDF
Dim extractedText As String = pdf.ExtractAllText()
' Trim whitespace and unwanted characters
Dim trimmedText As String = extractedText.Trim("*"c)
' Display the cleaned text
Console.WriteLine($"Cleaned Text: {trimmedText}")
End Sub
End Class輸入 PDF:
控制台輸出:
探索真實世界的應用程式
自動化發票處理
從 PDF 發票中擷取文字、修剪不必要的內容,並解析總計或發票 ID 等重要細節。 範例:
- 使用 IronPDF 讀取發票資料。
- 修剪空格以保持格式一致。
清理 OCR 輸出
光學字元識別 (OCR) 通常會產生雜訊文字。 透過 IronPDF 的文字萃取和 C# 修剪功能,您可以清理輸出內容,以便進一步處理或分析。
結論
有效率的文字處理是 .NET 開發人員的重要技能,尤其是在處理 PDF 的非結構化資料時。 Trim() 方法,特別是公共 string Trim() 方法,結合 IronPDF 的功能,提供了一種可靠的方法來清理和處理文本,刪除前導和尾隨空格、指定字符,甚至 Unicode 字符。
透過應用諸如 TrimEnd() 之類的方法來刪除尾隨字符,或者執行尾隨修剪操作,您可以將嘈雜的文本轉換為可用於報告、自動化和分析的內容。 上述方法可讓開發人員精確地清理現有字串,強化涉及 PDF 的工作流程。
將IronPDF強大的 PDF 操作功能與 C# 多功能的 Trim() 方法結合,您可以節省開發需要精確文字格式的解決方案的時間和精力。 以往需要數小時才能完成的任務,例如移除不需要的空白、清理 OCR 產生的文字或標準化擷取的資料,現在幾分鐘就能完成。
立即讓您的 PDF 處理能力更上一層樓-下載 IronPDF 的免費試用版,親身體驗它如何改變您的 .NET 開發經驗。 無論您是初學者或是經驗豐富的開發人員,IronPDF 都是您的合作夥伴,協助您建立更聰明、更快速、更有效率的解決方案。
常見問題
怎樣在 C# 中將 HTML 轉換為 PDF?
您可以使用 IronPDF 的 RenderHtmlAsPdf 方法將 HTML 字符串轉換為 PDF。您還可以使用 RenderHtmlFileAsPdf 將 HTML 文件轉換為 PDF。
什麼是 C# 的 Trim() 方法及其用法?
C# 中的 Trim() 方法從字符串的開頭和結尾移除空白或指定字符,對於清理文本數據非常有用。在文件處理中,它有助於通過移除不需要的空格和字符來清理提取的文本。
使用 C# 的 Trim() 時如何處理空值字符串?
要在空值字符串上安全地調用 Trim(),使用空合運算符或條件檢查,例如 string safeTrim = text?.Trim() ?? string.Empty;。
TrimStart() 和 TrimEnd() 在 C# 中有什麼用途?
TrimStart() 和 TrimEnd() 是 C# 中用來分別從字符串的開頭或結尾移除字符的方法。它們對於更精確的去除任務非常有用。
為什麼文字修剪在文件處理中很重要?
修剪在文件處理中至關重要,可去除提取文本中的前導和尾隨空白、特殊符號和格式工件,尤其是在處理來自 PDF 的非結構化數據時。
使用 C# Trim() 時有哪些常見問題?
常見問題包括空引用異常、由於不變性引起的性能降級、過度修剪有效字符和處理 Unicode 空白。
IronPDF 如何協助從 PDF 中修剪文本?
IronPDF 提供工具從 PDF 提取文本,允許開發人員在 .NET應用中修剪和清理數據以便存儲或分析。它與 C# 的 Trim() 集成良好,可有效進行文本操作。
C# Trim() 可以有效處理 Unicode 空白嗎?
默認的 Trim() 方法無法處理某些 Unicode 空白字符。要解決這個問題,需在修剪參數中顯式包含它們。
C# 中有哪些高級修剪技術以提高效率?
高級技術包括將 Trim() 與正則表達式結合用於複雜模式,並使用 StringBuilder 來優化大規模文本處理任務中的性能。
為什麼選擇 .NET 庫來處理 PDF?
功能強大的 .NET 庫可提供包括 HTML 到 PDF 轉換、PDF 編輯、文本和圖像提取、表單填寫和水印添加等功能,這些對全面的文件處理至關重要。
C# Trim() 如何應用於實際文件處理場景?
C# Trim() 可通過清理和解析重要訊息自動化發票處理,或通過 IronPDF 的提取功能清理 OCR 輸出以便進一步分析,從而提升 .NET 開發工作流。













