IronPDF vs iTextSharp: C에서 PDF 파일 읽기
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
PDF를 다루는 것은 텍스트 추출에서 문서 수정에 이르기까지 C# 개발의 흔한 작업입니다. iText는 오랫동안 이 작업을 위한 라이브러리로 사용되어 왔지만 복잡한 구문과 가파른 학습 곡선이 개발 속도를 늦출 수 있습니다.
IronPDF는 더 간단하고 효율적인 대안을 제공합니다. 직관적인 API, 내장된 HTML-에서-PDF 변환, 더 쉬운 텍스트 추출 등을 통해 IronPDF는 더 적은 코드로 PDF 처리를 간소화합니다. 이 기사에서는 C# 개발자를 위한 IronPDF가 더 현명한 선택인 이유를 보여주며 iText와 IronPDF를 비교할 것입니다.
iText 이해: 개요
iText(본래 iText)는 .NET에서 PDF 작업을 위한 강력한 오픈소스 라이브러리입니다. 이는 PDF 문서에서 생성, 수정, 암호화, 내용을 추출하기 위한 포괄적인 기능을 제공합니다. 많은 개발자들이 문서 워크플로 자동화, 보고서 생성, 대규모 PDF 처리 작업을 위해 이를 신뢰합니다.
iText의 가장 큰 강점 중 하나는 PDF 구조에 대한 세밀한 제어입니다. 주석, 양식 필드, 워터마크, 디지털 서명을 지원하여 고급 문서 조작을 위한 강력한 도구로 만듭니다. 추가적으로, 문서화가 잘 되어 있고 널리 사용되며 커뮤니티 지원이 강력하고 수많은 서드파티 리소스가 있습니다.
iText 설치
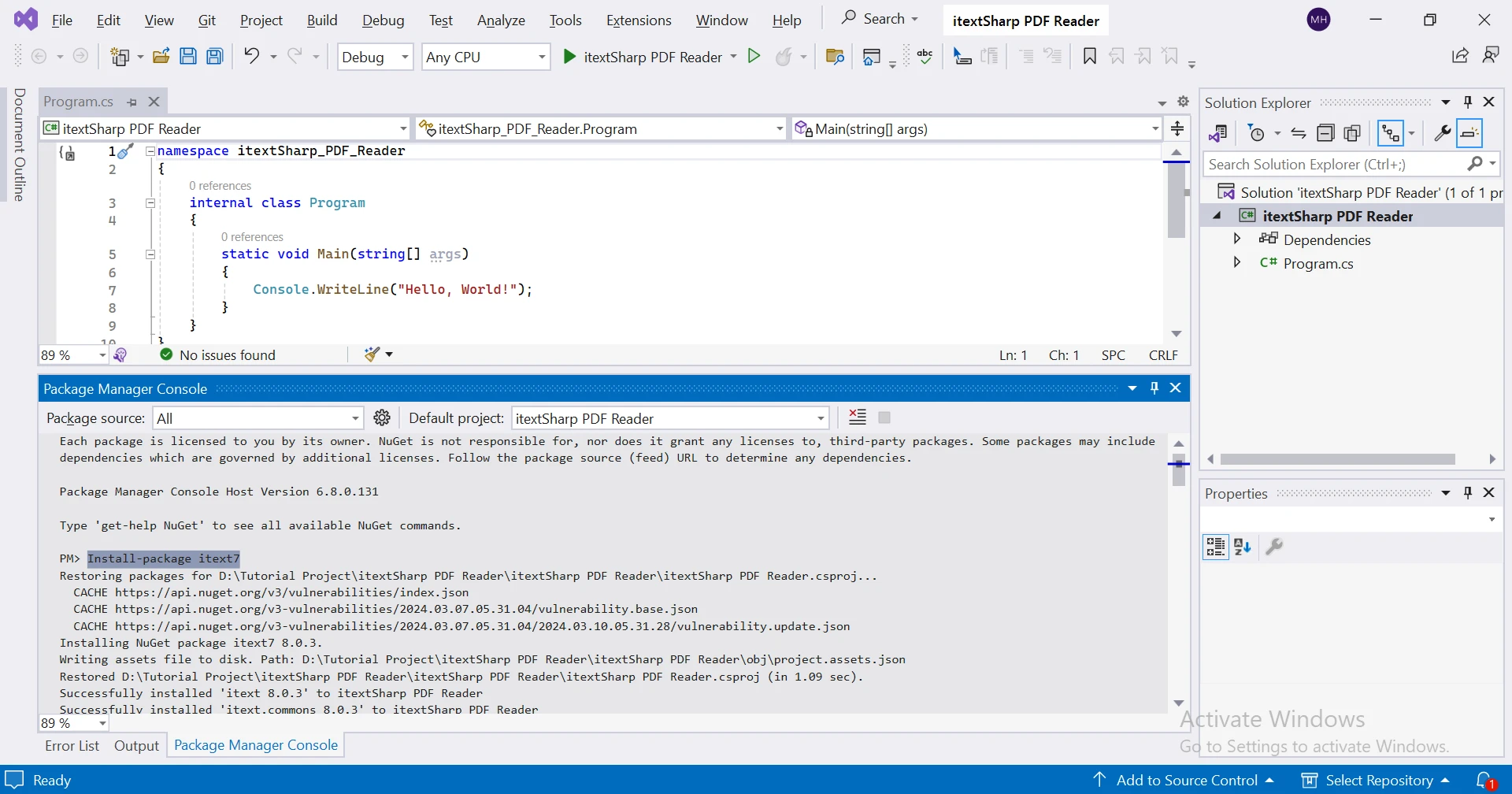
.NET 프로젝트에서 iText를 설치하려면 Visual Studio에서 NuGet 패키지 관리자를 사용할 수 있습니다:
NuGet 패키지 관리자 콘솔 사용:
Install-Package itext7
그러나 iText에는 과제가 있습니다. 복잡한 API는 텍스트 추출 또는 PDF 병합과 같은 일반 작업에 더 많은 코드를 요구하며, HTML에서 PDF로의 변환에 대한 기본 지원이 없어 웹에서 문서로의 워크플로를 더 어렵게 만듭니다. 게다가, AGPL 라이선스는 기업들이 오픈 소스 배포 요구를 피하기 위해 상용 라이선스를 구매해야 합니다.
효율적인 고급 API와 현대적 기능을 원하는 개발자들에게 IronPDF는 매력적인 대안을 제공합니다.
IronPDF 소개: 우수한 솔루션
IronPDF는 PDF 추출, 조작, 및 생성을 쉽게 하고 효율적으로 설계된 .NET 라이브러리입니다. iText와 달리 많은 작업에 대해 광범위한 코딩이 필요한 IronPDF는 개발자가 최소한의 노력으로 PDF를 읽고, 수정하고, 편집할 수 있습니다.
PDF 추출에 있어 IronPDF는 몇 줄의 코드만으로 PDF에서 텍스트, 이미지 및 구조화된 데이터를 쉽게 가져오도록 하여 텍스트 추출 작업을 단순화합니다. PDF 조작에 대해 IronPDF는 복잡한 저수준 작업 없이 PDF를 병합, 분할, 워터마크 추가 및 편집을 지원합니다.
추가적으로, IronPDF에는 기본 HTML에서 PDF로의 변환이 포함되어 있어 웹 페이지나 기존의 HTML 콘텐츠에서 PDF를 생성하는 것이 간단합니다. 또한 JavaScript 렌더링, 디지털 서명 및 암호화를 지원하여 현대 애플리케이션을 위한 균형 잡힌 도구 키트를 제공합니다.
더 깨끗한 API, 더 나은 문서화 및 상업 지원으로 IronPDF는 C#에서 PDF 조작을 단순화하는 개발자 친화적인 대안입니다. 다음 섹션에서는 두 라이브러리가 주요 PDF 작업을 어떻게 처리하는지 비교하고 IronPDF가 C# 개발자에게 왜 더 나은 경험을 제공하는지 설명합니다.
설치
NuGet 패키지 관리자에서 다음 명령을 실행하면 IronPDF를 C# 프로젝트에서 쉽게 사용할 수 있습니다:
Install-Package IronPdf
또는 Tools > NuGet Package Manager > Manage NuGet Packages for Solution으로 이동하여 IronPDF를 검색하세요.
그런 다음 간단히 "설치" 버튼을 클릭하면 IronPDF가 프로젝트에 빠르게 추가됩니다!
IronPDF 대 iText PDF 처리: 코드 비교
IronPDF를 사용하여 텍스트 추출
IronPDF는 훨씬 더 개발자 친화적인 API로 PDF 텍스트 추출, 조작 및 읽기를 단순화합니다. iText는 저수준 조작을 요구하는 반면, IronPDF는 몇 줄의 코드로 텍스트 추출을 허용합니다.
IronPDF의 강력한 텍스트 추출 도구를 활용하는 과정을 보여드리겠습니다. 다음 PDF 문서의 내용을 추출합니다.
코드 예제
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
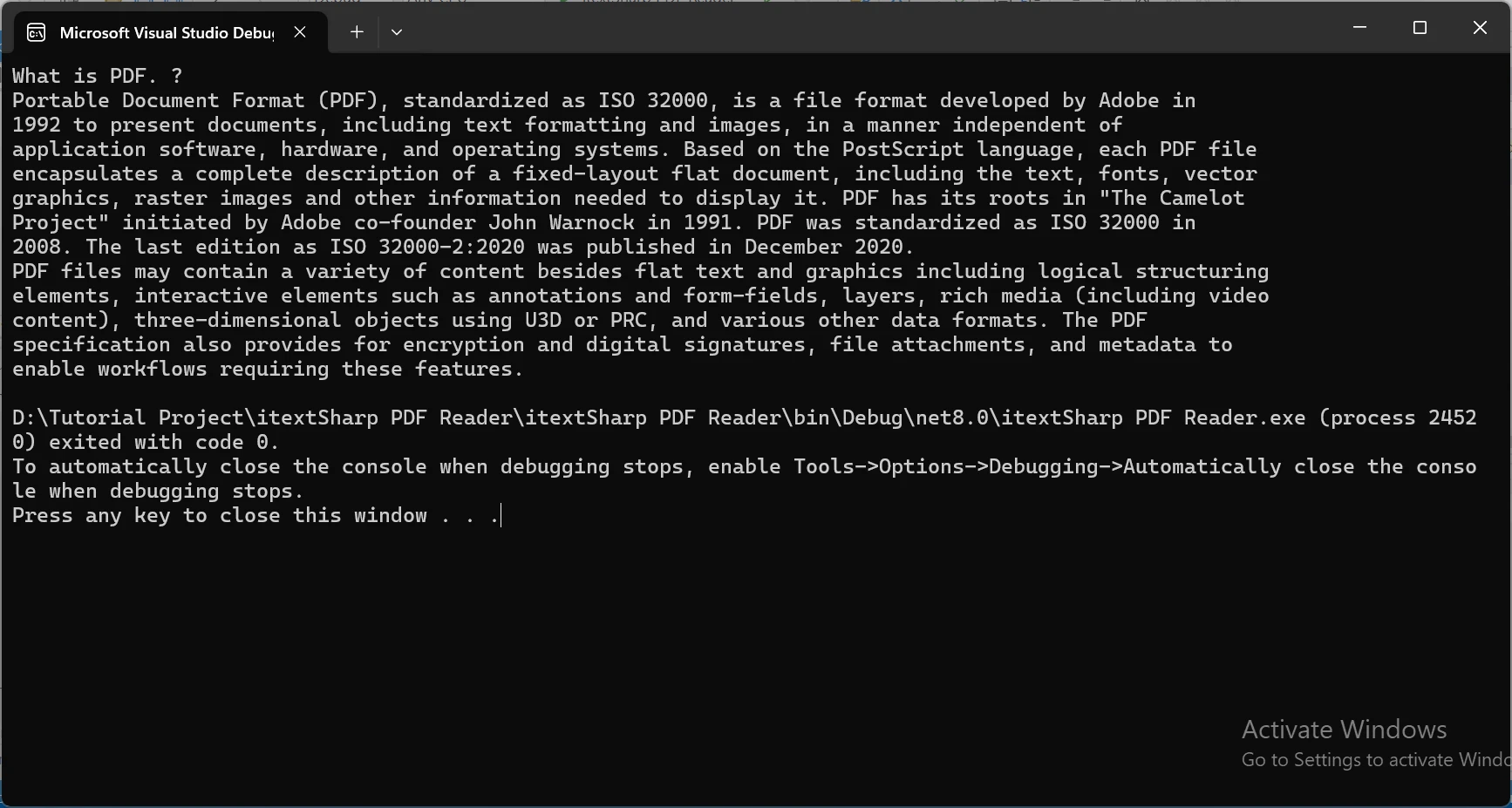
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
' Load the PDF document
Dim pdf = New PdfDocument(pdfPath)
' Extract all text from the loaded PDF document
Dim extractedText As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End Class산출
설명:
IronPDF는 고급 API로 저수준 작업 없이 PDF 텍스트 추출을 단순화합니다. IronPDF는 몇 줄의 코드만으로 PDF 문서에서 모든 텍스트를 효율적으로 추출할 수 있으며, iText와 같은 라이브러리는 종종 수동 페이지 반복 및 복잡한 처리가 필요합니다.
이 예에서 PdfDocument 클래스가 PDF를 로드하고 ExtractAllText() 메서드는 모든 텍스트를 빠르게 추출하여 프로세스를 간소화합니다. 이는 iText에서 개별 페이지 및 텍스트 요소를 수동으로 처리해야 할 필요성을 극복하는 큰 이점입니다.
IronPDF를 통한 다른 작업 확장:
기초 텍스트 추출 예제를 기반으로, IronPDF의 고급 API는 다른 일반적인 PDF 작업을 단순화하면서도 사용의 용이성과 효율성을 유지합니다:
특정 페이지에서 텍스트 추출: 특정 페이지나 범위에서 텍스트를 추출해야 할 때 IronPDF는 이를 쉽게 할 수 있게 합니다. 예를 들어, 첫 번째 페이지에서 텍스트를 추출하려면:
var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
' Access text from the first page
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)PDF 조작: 여러 PDF에서 텍스트나 데이터를 추출한 후에는 그들을 하나의 문서로 결합하고 싶을 수 있습니다. IronPDF는 여러 PDF를 병합하는 것을 간단하게 만듭니다:
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
' Merge the PDFs into a single document
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")PDF에서 HTML로 변환: PDF를 HTML로 다시 변환하여 추가 추출 또는 조작을 필요로 할 때, IronPDF는 이 기능도 제공합니다:
var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
' Convert the PDF to an HTML string
Dim htmlContent As String = pdf.ToHtmlString()IronPDF로 텍스트 추출은 시작에 불과합니다. 라이브러리의 간단하고 강력한 API는 다양한 PDF 조작 작업에 확장되어 직관적이고 워크플로에 쉽게 통합될 수 있도록 합니다.
iText를 사용하여 PDF 읽기
iText는 PDF 리더, 스트림 및 바이트 수준의 데이터 처리를 사용하여 작업해야 합니다. 텍스트 추출은 간단하지 않으며, PDF 페이지를 반복하고 다양한 구조를 수동으로 처리해야 합니다. 이 코드 예제에서는 IronPDF 섹션에서 사용한 동일한 PDF 문서를 사용할 것입니다.
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
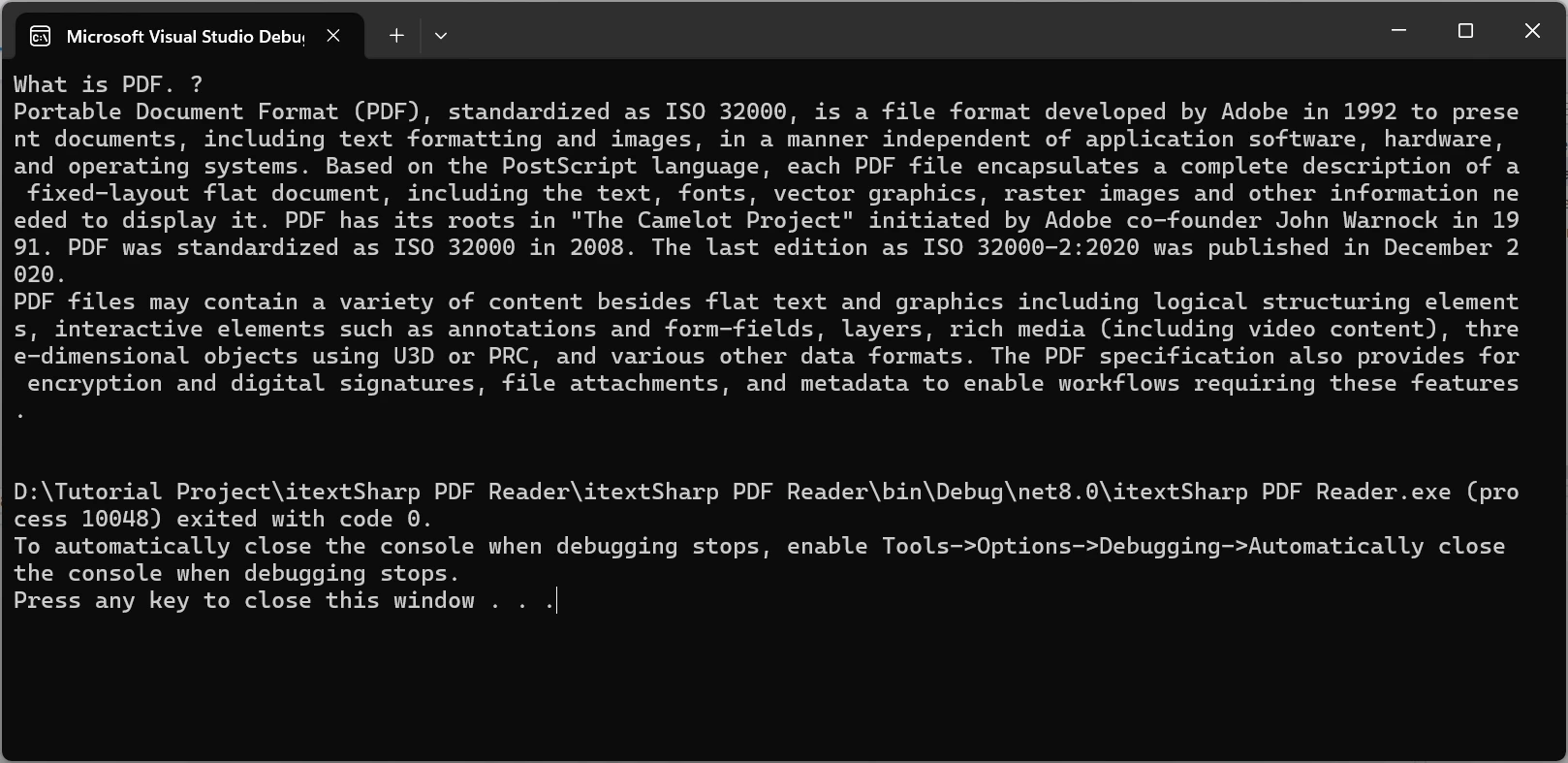
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
' Method to extract text from a PDF
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
' Use PdfReader to load the PDF
Using reader As New PdfReader(pdfPath)
' Open the PDF document for processing
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
' Iterate through each page and extract text
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
End Class산출
설명:
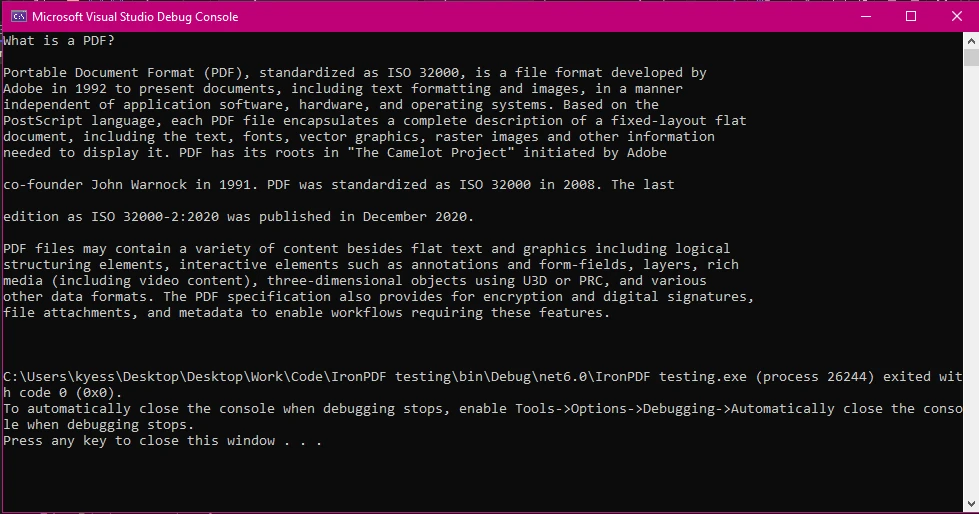
PdfReader는 읽기를 위해 PDF 파일을 로드합니다.PdfDocument객체는 페이지를 통해 반복할 수 있게 합니다.PdfTextExtractor.GetTextFromPage()는 각 페이지에서 텍스트를 가져옵니다.- 최종 텍스트는 문자열로 저장되고 표시됩니다.
이 방법은 작동하지만 구조화된 문서나 스캔된 PDF의 경우 수동 반복이 필요하며 번거로울 수 있습니다.
iText와 IronPDF 비교
iText는 PDF 작업을 수행하기 위해 상세한 코딩을 요구하지만, IronPDF는 직관적인 방법으로 이러한 작업을 간소화합니다. 예를 들어, iText로 PDF에서 텍스트를 추출하는 것은 여러 단계와 광범위한 코드가 필요하지만, IronPDF로는 몇 줄만으로 이를 수행합니다. 게다가 IronPDF의 HTML에서 PDF로의 변환 지원은 더 강력하여 복잡한 HTML, CSS, 및 JavaScript를 무리 없이 처리합니다.
주요 요점
- IronPDF는 더 직관적이고 간소화된 API로 PDF 읽기 및 조작 작업을 단순화하여 일반 작업을 수행하는 데 필요한 코드를 줄입니다.
- IronPDF의 텍스트 추출은 iText의 보다 복잡한 반복 프로세스에 비해 구현이 더 쉬워 개발자 시간을 절약합니다.
- IronPDF의 영구 라이선스는 iText의 AGPL 라이선스에 비해 비즈니스 친화적으로 더 적은 제한을 제공합니다.
- IronPDF는 빠른 문제 해결을 위해 더 접근 가능한 더 나은 문서를 제공하여 개발자가 방대한 리소스를 통해 검색하지 않고도 빠른 솔루션을 얻을 수 있게 합니다.
IronPDF로 워크플로 최적화하기
IronPDF는 단순히 PDF 읽기를 넘어서는 강력한 기능 모음을 제공합니다. 이 기능들은 개발자가 PDF 워크플로를 최적화하려는 경우에 강력한 솔루션이 됩니다. 다음은 IronPDF가 개발 프로세스를 향상시키는 방법입니다:
1. PDF에서 텍스트 추출
IronPDF는 PDF 파일에서 텍스트를 쉽게 추출할 수 있게 하여 문서 분석, 데이터 추출 또는 콘텐츠 색인 작업에 이상적입니다. IronPDF를 사용하면 복잡한 구문 분석을 처리하지 않고도 PDF에서 텍스트를 빠르게 추출하여 응용 프로그램에서 사용할 수 있습니다.
2. PDF 생성
IronPDF를 사용하면 보고서, 송장 또는 기타 문서 유형을 생성하든 쉽게 PDF를 처음부터 생성할 수 있습니다. 또한 이 도구는 HTML에서 PDF로의 변환을 지원하여 기존의 웹 콘텐츠를 활용하여 잘 형식화된 PDF를 생성할 수 있습니다. 이는 웹 페이지나 동적 HTML 콘텐츠를 다운로드 가능한 PDF 파일로 변환해야 하는 시나리오에 완벽합니다.
3. 고급 PDF 기능
기본적인 텍스트 추출과 PDF 생성 외에도, IronPDF는 PDF 양식 채우기, 주석 추가, 문서 콘텐츠 조작과 같은 고급 기능을 지원합니다. 이러한 기능은 양식 및 피드백이 워크플로의 정기적인 일부인 법률, 금융, 교육 분야에서 유용합니다.
4. 배치 처리
IronPDF는 대량의 PDF 파일을 처리하는 데 적합합니다. 수백 개의 문서에서 정보 추출하거나 여러 HTML 파일을 PDF로 변환하든, IronPDF는 이러한 작업을 자동화하고 효율적으로 처리하여 시간과 노력을 절약할 수 있습니다.
5. 자동화 및 효율성
IronPDF는 종종 시간 소모적이고 반복적인 PDF 조작 작업을 단순화합니다. PDF 텍스트 추출, 양식 채우기, 배치 변환과 같은 작업을 자동화하여 개발자가 프로젝트의 더 복잡한 부분에 집중할 수 있도록 하면서, IronPDF는 부담을 덜어줍니다.
기술 지원 및 커뮤니티 리소스
개발자가 IronPDF를 최대한 활용할 수 있도록 도구는 강력한 지원 및 커뮤니티 리소스로 뒷받침됩니다:
- 기술 지원: IronPDF는 이메일과 티켓 시스템을 통해 직접 지원을 제공하여 구현 또는 기술적 문제에 대한 도움을 제공합니다.
- 커뮤니티 리소스: IronPDF 웹사이트는 광범위한 문서, 튜토리얼, 블로그 게시물을 포함하고 있습니다. 개발자는 GitHub 및 Stack Overflow에서 솔루션을 찾고 지식을 공유할 수 있으며, 커뮤니티는 모범 사례 및 문제 해결 팁을 활발히 논의합니다.
결론
이 기사에서는 IronPDF의 .NET 개발자를 위한 강력하고 사용자 친화적인 PDF 처리 라이브러리로서의 역량을 탐구했습니다. iText와 비교하여 IronPDF가 텍스트 추출 및 PDF 조작과 같은 복잡한 작업을 어떻게 단순화하는지 강조했습니다. IronPDF의 깔끔한 API와 고급 기능들, 예를 들어 편집, 워터마킹, 디지털 서명 등은 현대의 PDF 워크플로를 위한 우수한 솔루션이 됩니다.
iText는 일반적인 PDF 작업에 복잡한 코딩이 필요하지만, IronPDF는 최소한의 코드로 복잡한 작업을 수행할 수 있도록 하여 개발자들의 시간과 노력을 절약해 줍니다. 스캔 문서 작업, HTML에서 PDF 생성, 맞춤형 워터마크 추가 등 무엇을 하든 간에, IronPDF는 모든 것을 직관적이고 효율적으로 처리할 수 있는 방법을 제공합니다.
C# 프로젝트에서 PDF 워크플로를 간소화하고 생산성을 높이고 싶다면, IronPDF가 이상적인 선택입니다.
IronPDF를 다운로드하고 직접 확인해 보시기 바랍니다. 무료 체험판을 통해, IronPDF를 응용 프로그램에 통합하고 오늘날 그 강력한 기능을 처음 손쉽게 시작하여 혜택을 누릴 수 있습니다.
아래를 클릭하여 무료 체험판을 시작하세요:
자주 묻는 질문
C#에서 PDF 처리를 위해 IronPDF를 사용하는 이점은 무엇입니까?
IronPDF는 더 직관적인 API를 제공하고 HTML에서 PDF로의 변환을 지원하며, 텍스트 추출, 병합, PDF 분할과 같은 작업을 간소화합니다. 이는 iText 7보다 적은 코드가 필요하며 비즈니스 친화적인 영구 라이선스 모델을 제공합니다.
C#에서 웹 페이지를 PDF로 변환할 수 있습니까?
IronPDF의 RenderUrlAsPdf 메소드를 사용하여 웹 페이지를 직접 PDF 문서로 변환할 수 있습니다. 이 과정은 내부적으로 HTML에서 PDF로 변환을 처리하여 간소화합니다.
IronPDF는 대규모 PDF 처리 작업 자동화에 적합합니까?
예, IronPDF는 자동화와 대량 처리를 잘 처리하여 C# 프로젝트에서 대량의 PDF를 효율적으로 처리하기에 이상적입니다.
IronPDF를 사용하여 PDF의 특정 페이지 범위에서 텍스트를 추출할 수 있습니까?
IronPDF는 특정 페이지 또는 페이지 범위에서 텍스트를 추출하는 기능을 제공하여 PDF 콘텐츠를 세밀하게 다룰 수 있습니다.
IronPDF가 개발자에게 제공하는 지원 리소스는 무엇입니까?
IronPDF는 포괄적인 문서, 튜토리얼, 활성 커뮤니티를 제공하며 이메일 및 티켓 시스템을 통한 직접적인 기술 지원도 가능합니다.
IronPDF가 C# 프로젝트에 통합되는 방법은 무엇입니까?
IronPDF는 Visual Studio의 NuGet 패키지 관리자를 사용하여 'Install-Package IronPdf' 명령을 실행하여 C# 프로젝트에 쉽게 통합할 수 있습니다.
IronPDF의 라이선스 옵션은 무엇인가요?
IronPDF는 비즈니스 친화적인 영구 라이선스 모델을 제공하여 iText 7의 AGPL 라이선스와 관련된 오픈 소스 배포 요구 사항을 피합니다.
IronPDF가 C# 프로젝트에서 개발자 생산성을 어떻게 향상시킵니까?
IronPDF는 사용자 친화적인 API를 통해 복잡한 PDF 작업을 간소화하여 필요한 코드 양을 줄이고 개발 과정을 빠르게 하여 C# 프로젝트에서 생산성을 향상시킵니다.
IronPDF는 PDF를 HTML로 변환하는 것을 지원합니까?
네, IronPDF는 PDF를 HTML 문자열로 변환하는 기능을 제공하여 웹 응용 프로그램에서 PDF 콘텐츠의 표시와 조작을 용이하게 합니다.
PDF 조작을 위한 IronPDF의 주요 기능은 무엇입니까?
IronPDF는 PDF 생성, 텍스트 추출, HTML에서 PDF로의 변환, 병합, 분할, 워터마킹, 디지털 서명 등을 지원하며, 사용하기 쉬운 API를 제공합니다.