Comment Lire des Documents PDF en C# en utilisant iTextSharp:
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
La gestion des PDF est une tâche courante dans le développement C#, allant de l'extraction de texte à la modification de documents. iText 7 a longtemps été une bibliothèque de référence pour cela, mais sa syntaxe complexe et sa courbe d'apprentissage abrupte peuvent ralentir le développement.
IronPDF offre une alternative plus simple et plus efficace. Avec une API intuitive, une conversion HTML en PDF intégrée et une extraction de texte facilitée, IronPDF rationalise la gestion des PDF avec moins de code. Dans cet article, nous comparerons iText 7 et IronPDF, en démontrant pourquoi IronPDF est le choix le plus judicieux pour les développeurs C#.
Comprendre iText 7 : Un aperçu
iText 7 (à l'origine iTextSharp) est une puissante bibliothèque open-source pour travailler avec les PDF en .NET. Il offre des fonctions étendues pour créer, modifier, crypter et extraire du contenu des documents PDF. De nombreux développeurs s'appuient sur cela pour automatiser les flux de travail de documents, générer des rapports et gérer des tâches de traitement de PDF à grande échelle.
L'une des plus grandes forces d'iText 7 est son contrôle granulaire sur les structures PDF. Il prend en charge les annotations, les champs de formulaire, les filigranes et les signatures numériques, ce qui en fait un outil robuste pour la manipulation de documents avancée. De plus, il est bien documenté et largement utilisé, avec un solide support communautaire et de nombreuses ressources tierces disponibles.
Installer iText 7
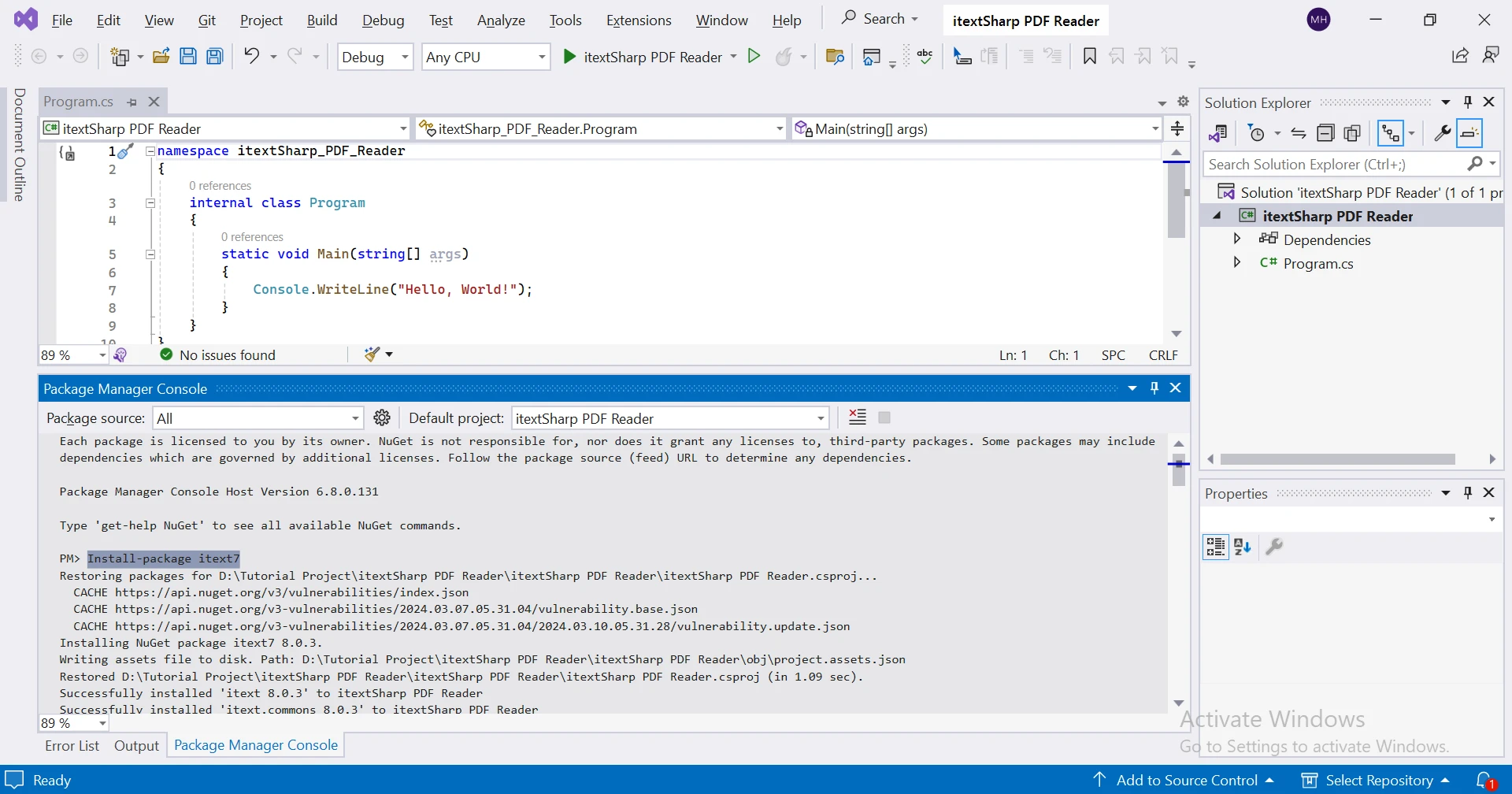
Pour installer iText 7 dans un projet .NET, vous pouvez utiliser le Package Manager NuGet dans Visual Studio :
En utilisant la console du Package Manager NuGet :
Install-Package itext7
Cependant, iText 7 s'accompagne de défis. Son API complexe exige plus de code pour des tâches courantes comme l'extraction de texte ou la fusion de PDF et ne dispose pas de support intégré pour la conversion HTML en PDF, rendant les flux de travail web-to-document plus difficiles. De plus, sa licence AGPL oblige les entreprises à acheter une licence commerciale pour éviter les exigences de distribution open-source.
Pour les développeurs recherchant une API plus simplifiée et de haut niveau avec des fonctionnalités modernes, IronPDF offre une alternative intéressante.
Présentation d'IronPDF : Une solution supérieure
IronPDF est une bibliothèque .NET conçue pour rendre l'extraction de PDF, la manipulation et la génération simples et efficaces. Contrairement à iText 7, qui nécessite une programmation étendue pour de nombreuses opérations, IronPDF permet aux développeurs de lire, éditer et modifier des PDF avec un minimum d'effort.
Pour l'extraction de PDF, IronPDF facilite la récupération de texte, d'images et de données structurées à partir de PDF avec seulement quelques lignes de code, simplifiant vos tâches d'extraction de texte avec aisance. En ce qui concerne la manipulation de PDF, IronPDF prend en charge la fusion, la division, le filigranage et l'édition de PDF sans exiger d'opérations bas niveau complexes.
En outre, IronPDF inclut une conversion HTML en PDF native, ce qui simplifie la génération de PDF à partir de pages web ou de contenu HTML existant. Il prend également en charge le rendu JavaScript, les signatures numériques et le cryptage, fournissant une boîte à outils complète pour les applications modernes.
Avec une API plus propre, une documentation améliorée et un support commercial, IronPDF est une alternative conviviale pour les développeurs, simplifiant la gestion des PDF en C#. Dans les sections suivantes, nous comparerons comment ces deux bibliothèques gèrent les tâches clés de PDF et pourquoi IronPDF offre une meilleure expérience pour les développeurs C#.
Installation
Pour faire fonctionner IronPDF dans vos projets C#, il suffit de lancer la ligne suivante dans le Package Manager NuGet :
Install-Package IronPdf
Ou, alternativement, allez dans Outils > Package Manager NuGet > Gérer les paquets NuGet pour la solution, et recherchez IronPDF.
Ensuite, il suffit de cliquer sur " Installer " et IronPDF sera ajouté à votre projet en un rien de temps !
IronPDF vs iText 7 dans le traitement des PDF : Comparaison de code
Utiliser IronPDF pour extraire du texte
IronPDF simplifie l'extraction de texte de PDF, la manipulation et la lecture avec une API beaucoup plus conviviale pour les développeurs. À la différence d'iText 7, qui nécessite des opérations bas niveau, IronPDF permet l'extraction de texte en seulement quelques lignes de code.
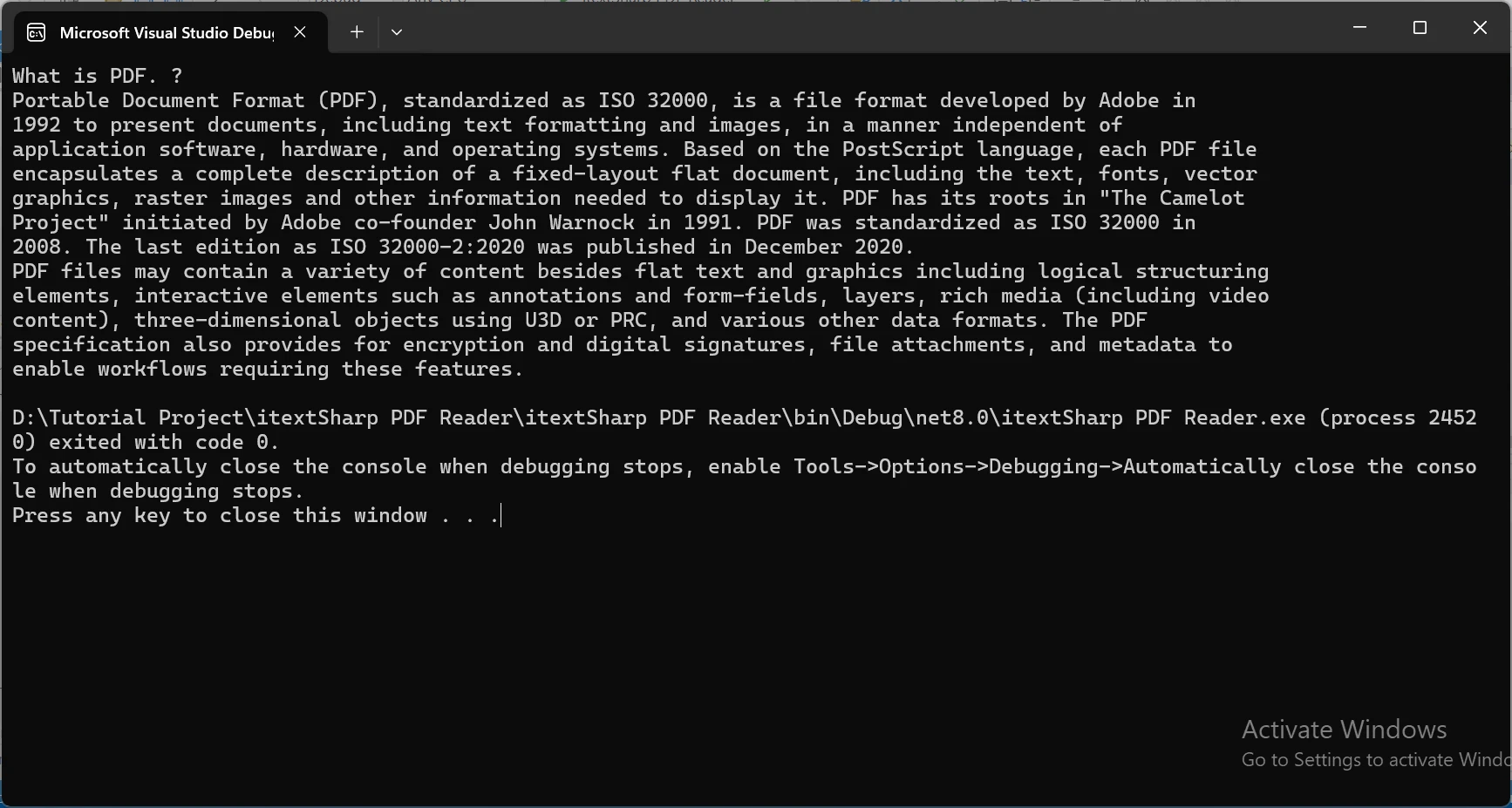
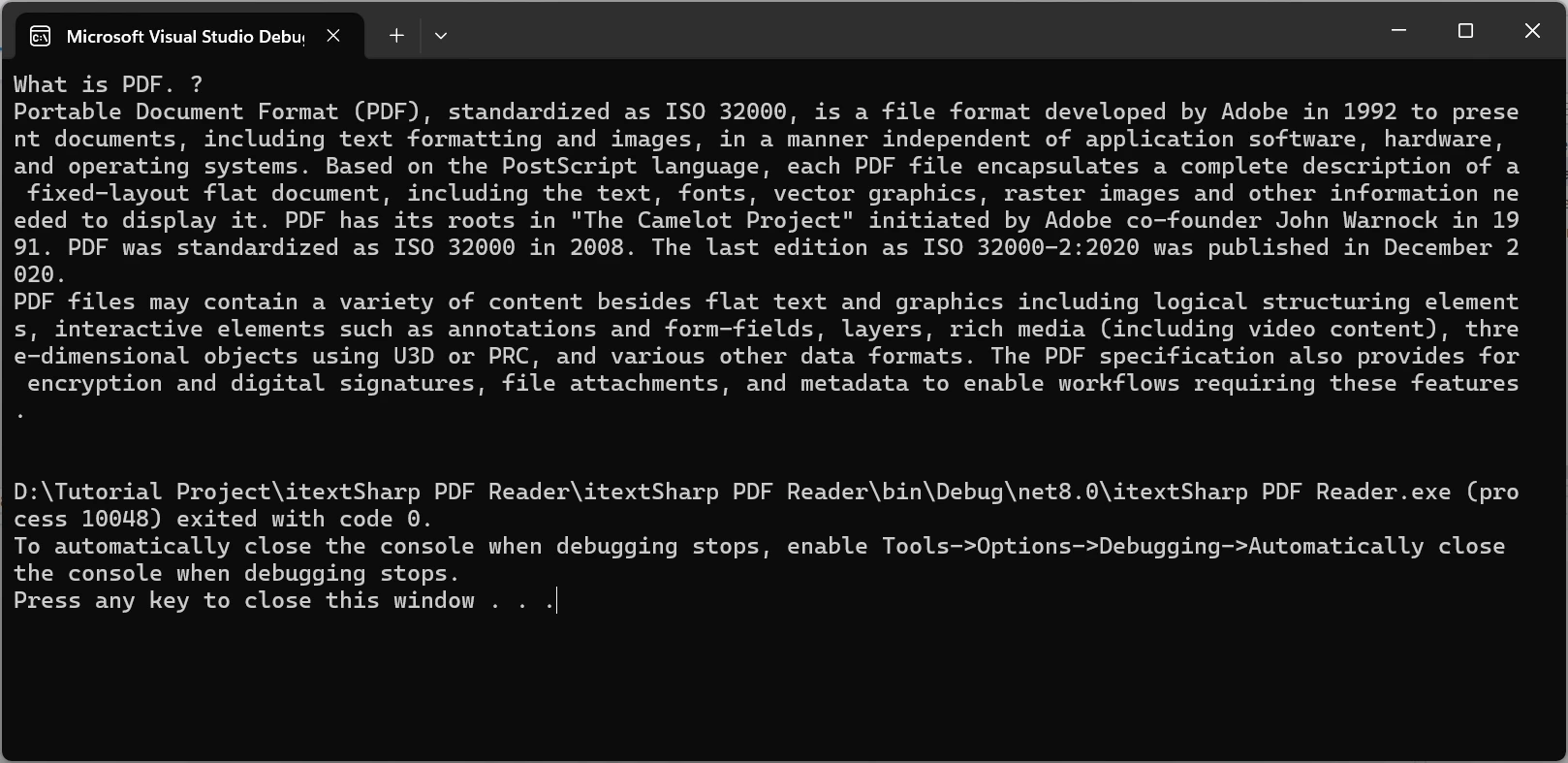
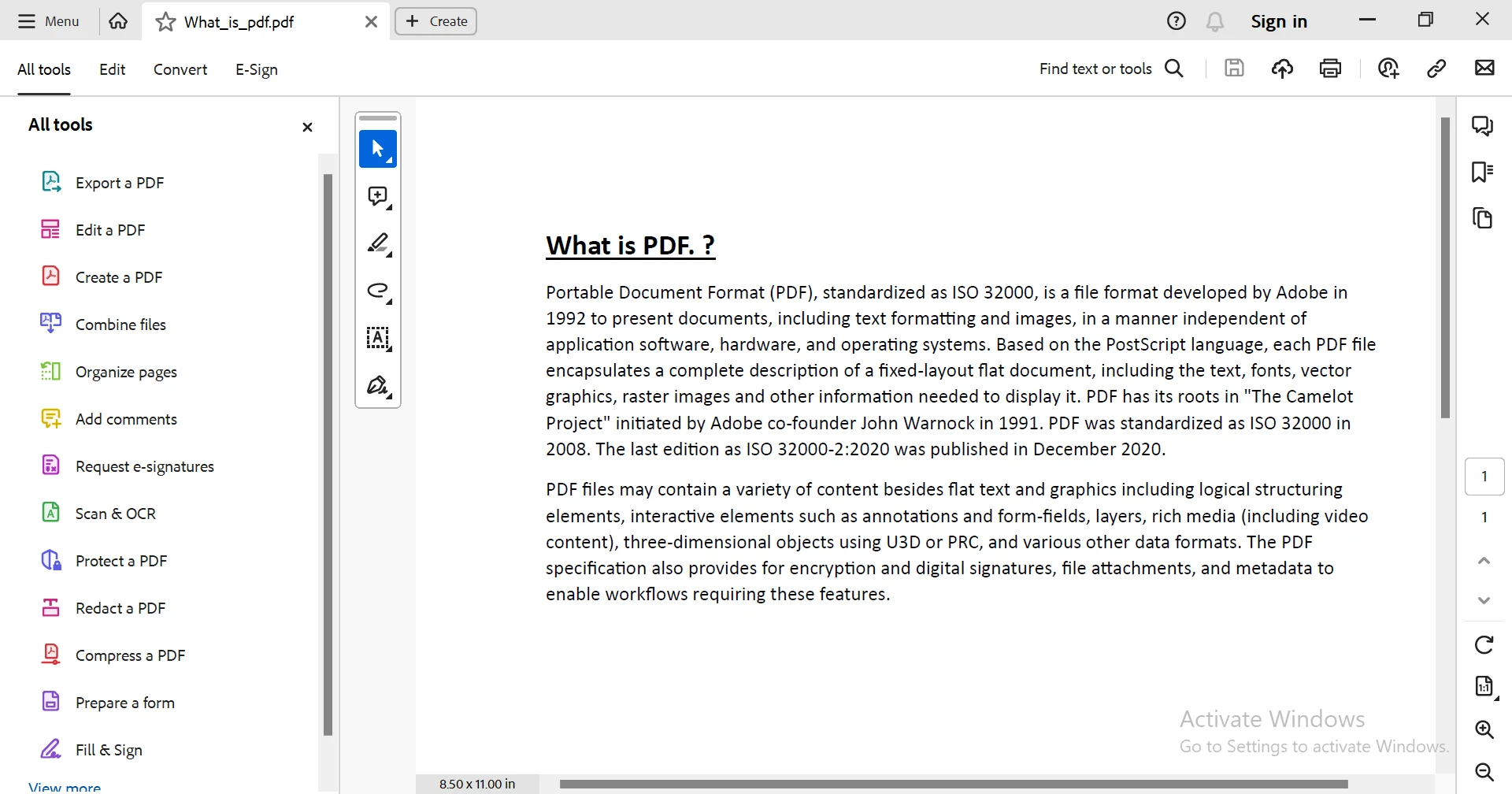
Pour démontrer l'outil puissant d'extraction de texte d'IronPDF en action, je prendrai le document PDF suivant et en extraire le contenu.
Exemple de code
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
' Load the PDF document
Dim pdf = New PdfDocument(pdfPath)
' Extract all text from the loaded PDF document
Dim extractedText As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
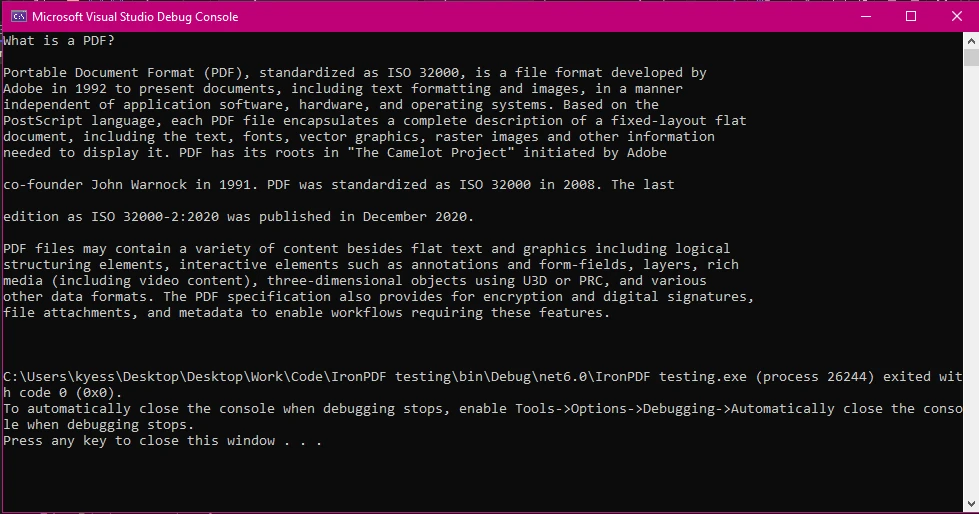
End ClassSortie
Explication :
IronPDF simplifie l'extraction de texte de PDF avec son API de haut niveau, éliminant ainsi le besoin d'opérations bas niveau. En quelques lignes de code, IronPDF peut extraire efficacement tout le texte d'un document PDF, contrairement aux bibliothèques comme iText 7, qui nécessitent souvent une itération manuelle des pages et une gestion complexe.
Dans l'exemple, la classe PdfDocument charge le PDF et la méthode ExtractAllText() extrait rapidement tout le texte, rationalisant ainsi le processus. C'est un avantage majeur par rapport à iText 7, où vous devrez gérer manuellement les pages individuelles et les éléments de texte.
Développer avec IronPDF pour d'autres tâches :
En se basant sur l'exemple d'extraction de texte de base, l'API de haut niveau d'IronPDF simplifie d'autres tâches PDF courantes, tout en maintenant la facilité d'utilisation et l'efficacité :
Extraction de texte à partir de pages spécifiques : Si vous devez extraire du texte d'une page ou d'une plage de pages spécifique, IronPDF vous permet de le faire facilement. Par exemple, pour extraire du texte de la première page :
var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
' Access text from the first page
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)Manipulation de fichiers PDF : Après avoir extrait du texte ou des données de plusieurs fichiers PDF, vous souhaiterez peut-être les combiner en un seul document. IronPDF rend simple la fusion de plusieurs PDF :
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
' Merge the PDFs into a single document
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")Conversion PDF vers HTML : Si vous devez reconvertir un PDF en HTML pour une extraction ou une manipulation ultérieure, IronPDF offre également cette fonctionnalité :
var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
' Convert the PDF to an HTML string
Dim htmlContent As String = pdf.ToHtmlString()Avec IronPDF, l'extraction de texte n'est que le début. L'API simple et puissante de la bibliothèque s'étend à une vaste gamme de tâches de manipulation de PDF, le tout dans un format intuitif et facile à intégrer à votre flux de travail.
Lecture des PDF avec iText 7
iText 7 nécessite de travailler avec des lecteurs PDF, des flux et un traitement de données au niveau des octets. L'extraction de texte n'est pas simple, car elle implique l'itération des pages PDF et la gestion de diverses structures manuellement. Pour cet exemple de code, nous utiliserons le même document PDF que dans la section IronPDF.
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
' Method to extract text from a PDF
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
' Use PdfReader to load the PDF
Using reader As New PdfReader(pdfPath)
' Open the PDF document for processing
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
' Iterate through each page and extract text
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
End ClassSortie
Explication :
- Le
PdfReadercharge le fichier PDF pour la lecture. - L'objet
PdfDocumentpermet de parcourir les pages. PdfTextExtractor.GetTextFromPage()récupère le texte de chaque page.- Le texte final est stocké dans une chaîne et affiché.
Cette méthode fonctionne mais nécessite une itération manuelle et peut être lourde pour des documents structurés ou des PDF scannés.
Comparaison d'iText 7 et IronPDF
Alors qu'iText 7 nécessite un codage détaillé pour effectuer des opérations sur les PDF, IronPDF simplifie ces tâches avec des méthodes simples. Par exemple, extraire du texte d'un PDF avec iText 7 nécessite plusieurs étapes et un code étendu, tandis qu'IronPDF y parvient en seulement quelques lignes. De plus, le support d'IronPDF pour la conversion HTML en PDF est plus robuste, gérant de manière transparente le HTML complexe, le CSS et le JavaScript.
Points clés à retenir
- IronPDF simplifie les tâches de lecture et de manipulation de PDF avec une API plus intuitive et rationalisée, nécessitant moins de code pour accomplir les opérations courantes.
- L'extraction de texte avec IronPDF est plus facile à mettre en œuvre par rapport au processus d'itération plus complexe d'iTextSharp, économisant du temps aux développeurs.
- Le modèle de licence perpétuelle d'IronPDF est plus convivial pour les entreprises, offrant moins de contraintes par rapport à la licence AGPL d'iTextSharp.
- IronPDF a une meilleure documentation, plus accessible pour un dépannage rapide, ce qui en fait un outil idéal pour les développeurs cherchant des solutions rapides sans passer au crible des ressources excessives.
Optimisation de votre flux de travail avec IronPDF
IronPDF offre une suite de fonctionnalités puissantes allant au-delà de la simple lecture de PDF. Ces fonctionnalités en font une solution robuste pour les développeurs cherchant à optimiser leurs flux de travail PDF. Voici comment IronPDF peut améliorer votre processus de développement :
1. Extraction de texte depuis des PDF
IronPDF permet une extraction facile du texte des fichiers PDF, le rendant idéal pour les flux de travail impliquant l'analyse de documents, l'extraction de données ou l'indexation de contenu. Avec IronPDF, vous pouvez rapidement extraire du texte de PDF et l'utiliser dans vos applications sans avoir à gérer un parsing complexe.
2. Création de PDF
IronPDF simplifie la génération de PDF à partir de zéro, que vous créiez des rapports, des factures ou d'autres types de documents. L'outil prend également en charge la conversion HTML en PDF, vous permettant de tirer parti de contenu web existant et de générer des PDF bien formatés. Ceci est parfait pour les scénarios où vous devez convertir des pages web ou du contenu HTML dynamique en fichiers PDF téléchargeables.
3. Fonctionnalités PDF avancées
Au-delà de l'extraction de texte de base et de la création de PDF, IronPDF prend en charge des fonctionnalités avancées telles que le remplissage de formulaires PDF, l'ajout d'annotations et la manipulation de contenu de documents. Ces capacités sont utiles dans des secteurs comme le juridique, le financier ou l'éducation où les formulaires et les commentaires font régulièrement partie du flux de travail.
4. Traitement par lot
IronPDF est bien adapté pour traiter de grands nombres de fichiers PDF. Que vous extrayiez des informations de centaines de documents ou que vous convertissiez plusieurs fichiers HTML en PDF, IronPDF peut automatiser ces tâches et les gérer efficacement, économisant à la fois du temps et des efforts.
5. Automatisation et efficacité
IronPDF simplifie les tâches de manipulation de PDF qui sont souvent chronophages et répétitives. En automatisant les tâches comme l'extraction de texte de PDF, le remplissage de formulaires ou la conversion par lots, les développeurs peuvent se concentrer sur des aspects plus complexes de leurs projets tout en laissant IronPDF s'occuper du gros du travail.
Support technique et ressources communautaires
Pour garantir que les développeurs puissent tirer le meilleur parti d'IronPDF, l'outil est soutenu par un solide support et des ressources communautaires :
- Support technique : IronPDF offre un support direct par e-mail et un système de tickets, fournissant de l'aide pour tout défi d'implémentation ou technique.
- Ressources communautaires : Le site web d'IronPDF inclut une documentation étendue, des tutoriels et des articles de blog. Les développeurs peuvent également trouver des solutions et partager leurs connaissances via GitHub et Stack Overflow, où la communauté discute activement des meilleures pratiques et fournit des conseils de dépannage.
Conclusion
Dans cet article, nous avons exploré les capacités d'IronPDF en tant que bibliothèque de gestion de PDF puissante et conviviale pour les développeurs .NET. Nous l'avons comparée à iText 7, en soulignant comment IronPDF simplifie les tâches complexes telles que l'extraction de texte et la manipulation de PDF. L'API claire et les fonctionnalités avancées d'IronPDF, y compris l'édition, le filigrane et les signatures numériques, en font une solution supérieure pour les flux de travail PDF modernes.
Contrairement à iText 7, qui nécessite un codage complexe pour les tâches courantes de PDF, IronPDF vous permet d'effectuer des opérations complexes avec un minimum de code, économisant du temps et des efforts aux développeurs. Que vous travailliez avec des documents scannés, que vous génériez des PDF à partir de HTML ou que vous ajoutiez des filigranes personnalisés, IronPDF offre une manière intuitive et efficace de tout gérer.
Si vous cherchez à rationaliser vos flux de travail PDF et à augmenter votre productivité dans vos projets C#, IronPDF est le choix idéal.
Nous vous invitons à télécharger IronPDF et à l'essayer par vous-même. Avec un essai gratuit disponible, vous pouvez découvrir de première main à quel point il est facile d'intégrer IronPDF dans vos applications et de commencer à bénéficier de ses fonctionnalités puissantes dès aujourd'hui.
Cliquez ci-dessous pour commencer votre essai gratuit :
- Commencez votre essai gratuit avec IronPDF
- En savoir plus sur les fonctionnalités et le tarification d'IronPDF N'attendez pas - débloquez le potentiel d'une gestion fluide des PDF avec IronPDF !
[{i: (iText 7, PdfSharp, Spire.PDF, Syncfusion Essential PDF et Aspose.PDF sont des marques déposées de leurs propriétaires respectifs. Ce site n'est pas affilié à, soutenu par ou sponsorisé par iText 7, PdfSharp, Spire.PDF, Syncfusion Essential PDF ou Aspose.PDF. Tous les noms de produits, logos et marques sont la propriété de leurs propriétaires respectifs. Les comparaisons sont à titre informatif uniquement et reflètent les informations publiquement disponibles au moment de l'écriture.)}]
Questions Fréquemment Posées
Quels sont les avantages de l'utilisation d'IronPDF par rapport à iText 7 pour la gestion des PDF en C#?
IronPDF offre une API plus intuitive, prend en charge la conversion HTML-à-PDF et simplifie des tâches telles que l'extraction de texte, le fusionnement et la division des PDF. Il nécessite moins de code que iText 7 et propose un modèle de licence perpétuel adapté aux entreprises.
Comment puis-je convertir une page web en PDF en C#?
Vous pouvez utiliser la méthode RenderUrlAsPdf d'IronPDF pour convertir directement une page web en document PDF. Cela simplifie le processus en gérant la conversion HTML-à-PDF en interne.
IronPDF est-il adapté pour automatiser des tâches de traitement PDF en grande quantité?
Oui, IronPDF est bien adapté à l'automatisation et au traitement par lots, ce qui le rend idéal pour gérer efficacement de grands volumes de PDF dans des projets C#.
Puis-je extraire du texte d'une plage de pages spécifique d'un PDF à l'aide d'IronPDF?
IronPDF fournit des fonctionnalités pour extraire du texte de pages spécifiques ou de plages de pages, permettant une gestion précise du contenu PDF.
Quels ressources de support IronPDF propose-t-il aux développeurs?
IronPDF propose une documentation complète, des tutoriels et une communauté active. De plus, un support technique direct est disponible par email et un système de tickets pour assister les développeurs.
Comment IronPDF s'intègre-t-il dans un projet C#?
IronPDF peut être facilement intégré dans un projet C# en l'installant via le Package Manager NuGet dans Visual Studio en utilisant la commande 'Install-Package IronPDF'.
Quelles sont les options de licence pour IronPDF?
IronPDF propose un modèle de licence perpétuel, qui est adapté aux entreprises et évite les exigences de distribution open-source associées à la licence AGPL de iText 7.
Comment IronPDF améliore-t-il la productivité des développeurs dans les projets C#?
IronPDF simplifie les tâches PDF complexes grâce à son API conviviale, réduisant la quantité de code nécessaire et accélérant les processus de développement, ce qui améliore la productivité dans les projets C#.
IronPDF prend-il en charge la conversion des PDF en HTML?
Oui, IronPDF fournit des fonctionnalités pour convertir des PDF en chaînes HTML, facilitant l'affichage et la manipulation du contenu PDF dans les applications web.
Quelles sont les principales caractéristiques d'IronPDF pour la manipulation des PDF?
IronPDF prend en charge un large éventail de fonctionnalités, notamment la création de PDF, l'extraction de texte, la conversion HTML-à-PDF, le fusionnement, le découpage, le filigranage et les signatures numériques, le tout avec une API facile à utiliser.