
C#でiTextSharpを使用してPDFドキュメントを読む方法:
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
C#開発においてPDFを扱うことは、テキストの抽出から文書の修正まで、一般的なタスクです。 iText 7は長い間、この目的に使われてきた定番のライブラリですが、その複雑な構文と急な学習曲線が開発を遅らせることがあります。
IronPDFは、よりシンプルで効率的な代替手段を提供します。直感的なAPI、組み込みのHTMLからPDFへの変換、テキスト抽出の簡素化により、IronPDFはより少ないコードでPDFの処理を効率化します。 この記事では、iText 7とIronPDFを比較し、C#開発者にとってIronPDFが賢明な選択である理由を紹介します。
iText 7を理解する: 概要
iText 7(元々はiTextSharp)は、.NETでPDFを扱うための強力なオープンソースライブラリです。 PDFドキュメントの作成、修正、暗号化、コンテンツの抽出に対する広範な機能を提供しています。 多くの開発者が、ドキュメントのワークフローを自動化したり、レポートを生成したり、大規模なPDF処理タスクを処理するためにこれに依拠しています。
iText 7の最大の強みの1つは、そのPDF構造に対する細かな制御です。 注釈、フォームフィールド、ウォーターマーク、デジタル署名をサポートしており、先進的なドキュメント操作のための強力なツールです。 さらに、文書化がよく行われており、広く使用されていて、強力なコミュニティサポートと多くのサードパーティリソースが利用可能です。
iText 7のインストール
.NETプロジェクトにiText 7をインストールするには、Visual StudioのNuGetパッケージ マネージャーを使用できます:
NuGet パッケージ マネージャー コンソールを使用:
Install-Package itext7
しかし、iText 7には課題があります。 その複雑なAPIは、テキスト抽出やPDFの結合のような一般的なタスクにより多くのコードを必要とし、HTMLからPDFへの組み込みサポートが欠如しているため、Webからドキュメントへのワークフローがより困難です。 さらに、AGPLライセンスは、オープンソースの配布要件を回避するために、企業が商用ライセンスを購入することを求めます。
より洗練された高レベルAPIと最新の機能を求める開発者にとって、IronPDFは魅力的な選択肢です。
IronPDFの紹介: 優れたソリューション
IronPDFは、PDFの抽出、操作、および生成をシンプルかつ効率的にするため for .NETライブラリです。 多くの操作に対して大規模なコーディングを必要とするiText 7とは異なり、IronPDFは、開発者が最小の努力でPDFの読み取り、編集、および修正を行えるようにします。
PDFの抽出においては、IronPDFは、数行のコードでPDFからテキスト、画像、および構造化データを簡単に引き出すことを可能にし、テキスト抽出タスクを簡易に効率化します。 PDFの操作に関しては、IronPDFは結合、分割、ウォーターマーク、および編集をサポートし、複雑な低レベル操作を必要としません。
さらに、IronPDFはネイティブのHTMLからPDFへの変換を含んでおり、ウェブページや既存のHTMLコンテンツから簡単にPDFを生成することを容易にします。 また、JavaScriptレンダリング、デジタル署名、および暗号化をサポートし、最新アプリケーションのための包括的なツールキットを提供します。
よりクリーンなAPI、優れたドキュメント化、商業サポートを備えたIronPDFは、C#でのPDF処理を簡単にする開発者に優しい代替手段です。 以下のセクションで、両ライブラリが主要なPDFタスクをどのように処理するかを比較し、C#開発者にとってIronPDFがより良い体験を提供する理由を紹介します。
インストール
C#プロジェクトでIronPDFを始めるのは、NuGet パッケージ マネージャーで以下の行を実行するのと同じくらい簡単です:
Install-Package IronPdf
または、ツール > NuGet パッケージ マネージャー > ソリューションのNuGetパッケージの管理に移動して、IronPDFを検索します。
その後、"インストール"をクリックするだけで、IronPDFがすぐにプロジェクトに追加されます!
PDF処理におけるIronPDFとiText 7: コードの比較
IronPDFを使用したテキストの抽出
IronPDFは、より開発者に優しいAPIで、PDFテキストの抽出、操作、および読み取りを簡素化します。 低レベル操作を必要とするiText 7とは異なり、IronPDFは数行のコードでテキスト抽出が可能です。
IronPDFの強力なテキスト抽出ツールを実際に使用してみるために、次のPDFドキュメントを使用してその中のコンテンツを抽出します。
コード例
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
' Load the PDF document
Dim pdf = New PdfDocument(pdfPath)
' Extract all text from the loaded PDF document
Dim extractedText As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End Class出力
説明:
IronPDFは、高レベルAPIでPDFテキスト抽出を簡素化し、低レベルの操作を不要にします。 数行でIronPDFはPDFから全テキストを抽出し、iText 7よりプロセスを簡略化します。
この例では、PdfDocument クラスが PDF を読み込み、ExtractAllText() メソッドがすべてのテキストをすばやく抽出し、プロセスを合理化します。 これは、個々のページやテキスト要素を手動で処理する必要のあるiText 7に比べて大きな利点です。
IronPDFを他のタスクに拡張する:
基本的なテキスト抽出の例を基に、IronPDFの高レベルAPIは、使いやすさと効率性を維持しつつ、他の一般的なPDFタスクを簡素化します:
特定のページからのテキストの抽出:特定のページまたは範囲からテキストを抽出する必要がある場合、 IronPDF を使用すると簡単に実行できます。 たとえば、最初のページからテキストを抽出するには:
var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
' Access text from the first page
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)PDF 操作:複数の PDF からテキストまたはデータを抽出した後、それらを 1 つのドキュメントに結合する必要がある場合があります。 IronPDFは複数のPDFを簡単に結合します:
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
' Merge the PDFs into a single document
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")PDF から HTML への変換:さらに抽出や操作を行うために PDF を HTML に戻す必要がある場合、 IronPDFこの機能も提供されます。
var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
' Convert the PDF to an HTML string
Dim htmlContent As String = pdf.ToHtmlString()IronPDFを用いることで、テキストの抽出は始まりにすぎません。 ライブラリのシンプルで強力なAPIは、さまざまなPDF操作タスクにわたって拡張され、直感的で使いやすい形式でワークフローに統合することができます。
iText 7と共にPDFを読む
iText 7では、PDFリーダー、ストリーム、およびバイトレベルのデータ処理を操作する必要があります。 テキストを抽出することは簡単ではなく、PDFページを反復し様々な構造を手動で扱うことが含まれます。 このコード例では、IronPDFセクションで使用したのと同じPDFドキュメントを使用します。
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
' Method to extract text from a PDF
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
' Use PdfReader to load the PDF
Using reader As New PdfReader(pdfPath)
' Open the PDF document for processing
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
' Iterate through each page and extract text
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
End Class出力
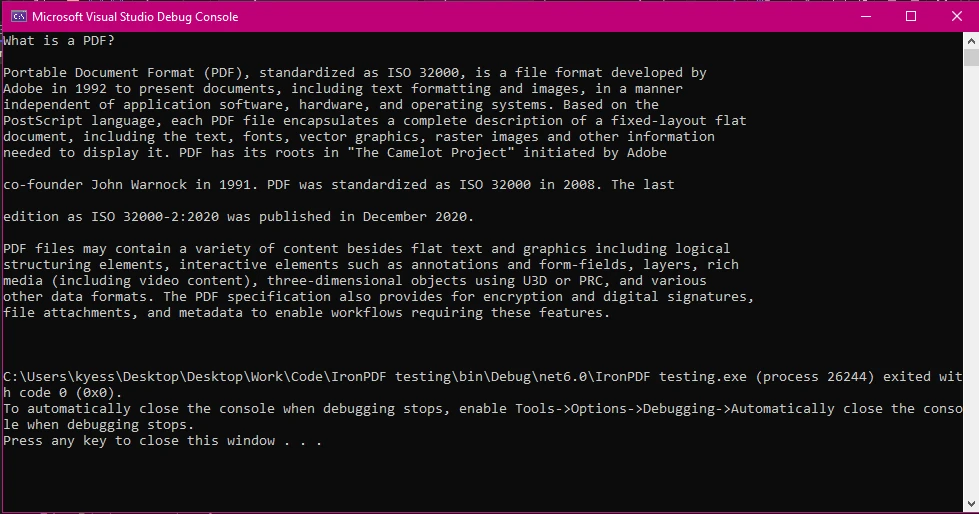
説明:
PdfReaderは PDF ファイルを読み取り用に読み込みます。PdfDocumentオブジェクトを使用すると、ページを反復処理できます。PdfTextExtractor.GetTextFromPage()は各ページからテキストを取得します。- 最終的なテキストは文字列に格納され、表示されます。
この方法は機能しますが、手動の反復が必要で、構造化されたドキュメントやスキャンされたPDFに対して面倒です。
iText 7とIronPDFの比較
iText 7がPDF操作を実行するために詳細なコーディングを必要とする一方で、IronPDFはこれらのタスクを直感的な方法で簡素化します。 例えば、iText 7でPDFからテキストを抽出することは多くのステップと広範なコードを含みますが、IronPDFではこれをわずか数行で実現します。 さらに、IronPDFのHTMLからPDFへの変換のサポートは、複雑なHTML、CSS、およびJavaScriptをシームレスに処理する点でより強力です。
重要なポイント
- IronPDFは、より直感的でストリームラインされたAPIで、PDFの読み取りおよび操作タスクを簡素化し、一般的な操作を行うために必要なコードを削減します。
- IronPDFのテキスト抽出は、より複雑な反復プロセスを伴うiTextSharpよりも実装が簡単で、開発者の時間を節約します。
- IronPDFの永続ライセンスはiTextSharpのAGPLライセンスに比べてよりビジネスフレンドリーで制約が少ないです。
- IronPDFはドキュメントがよりアクセスしやすく、迅速なトラブルシューティングに最適で、過剰なリソースを調査することなく速やかに解決策を求める開発者に理想的です。
IronPDFでワークフローを最適化する
IronPDFは単なるPDF読み取りを超える強力な機能を提供します。 これらの機能は、PDFワークフローを最適化したい開発者にとって、強力なソリューションになります。 IronPDFが開発プロセスをどのように強化できるかを以下に示します:
1. PDFsからのテキスト抽出
IronPDFは、ドキュメントの分析、データ抽出、またはコンテンツのインデックス作成を含むワークフローに理想的で、PDFファイルからのテキスト抽出を容易にします。 IronPDFを使用することで、複雑な解析に取り組むことなく、PDFからテキストをすばやく引き出し、アプリケーションで使用できます。
2. PDFの作成
IronPDFは、レポート、請求書、またはその他のタイプの文書を作成する際、スクラッチからのPDF生成を簡素化します。 また、HTMLからPDFへの変換をサポートしており、既存のWebコンテンツを利用して適切にフォーマットされたPDFを生成できます。 これは、ウェブページや動的HTMLコンテンツをダウンロード可能なPDFファイルに変換する必要があるシナリオに最適です。
3. 高度なPDF機能
基本的なテキスト抽出とPDF作成を超えて、IronPDFは、PDFフォームの記入、注釈の追加、および文書コンテンツの操作などの高度な機能をサポートします。 これらの機能は、法律、金融、または教育のような業界において、フォームとフィードバックがワークフローの定期的な一部となるのに役立ちます。
4. バッチ処理
IronPDFは多数のPDFファイルを処理するのに適しています。 何百ものドキュメントから情報を抽出するか、複数のHTMLファイルをPDFに変換するかにかかわらず、IronPDFはこれらのタスクを自動化して効率的に処理し、時間と労力を節約します。
5. 自動化と効率
IronPDFは、時間がかかり反復的なPDF操作タスクを簡素化します。PDFテキストの抽出、フォーム入力、バッチ変換などのタスクを自動化することで、開発者はプロジェクトのより複雑な側面に集中でき、IronPDFに重い作業を任せることができます。
技術サポートとコミュニティリソース
IronPDFを最大限に活用できるようにするため、ツールは強力なサポートとコミュニティリソースにより支えられています:
- 技術サポート: IronPDFは、メールとチケッティングシステムを介した直接サポートを提供し、実装または技術的な課題に対する支援を行います。
- コミュニティリソース: IronPDFのウェブサイトには、幅広いドキュメント、チュートリアル、およびブログ記事が含まれています。 開発者はまた、GitHubおよびStack Overflowを通じて、コミュニティがベストプラクティスとトラブルシューティングのヒントを積極的に議論している場所で、ソリューションを見つけ知識を共有することもできます。
結論
この記事では、IronPDFの機能を、.NET 開発者にとって強力で使いやすいPDF処理ライブラリとして探究しました。 それをiText 7と比較し、IronPDFがテキスト抽出やPDF操作のような複雑なタスクをいかに簡素化するかを強調しました。 IronPDFのクリーンなAPIおよび編集、ウォーターマーク、デジタル署名などの高度な機能により、現代のPDFワークフローには最適なソリューションになっています。
iText 7は、一般的なPDFタスクに対して詳しいコーディングを必要としますが、IronPDFにより最小のコードで複雑な操作が可能になり、開発者の時間と労力を節約します。 スキャンされたドキュメントの処理、HTMLからのPDF生成、またはカスタムウォーターマークの追加を行う場合も、IronPDFはすべてを直感的かつ効率的に処理します。
C#プロジェクトでPDFワークフローを効率化し生産性を向上させるには、IronPDFが理想的な選択です。
IronPDFをダウンロードして試してみることをお勧めします。 無料トライアルも利用可能で、IronPDFをアプリケーションに統合し、その強力な機能を今日から利用し始めることの簡単さを直接体験できます。
下記をクリックして無料トライアルを開始してください:
よくある質問
C# での PDF 処理には iText 7 よりも IronPDF を使用する利点は何ですか?
IronPDF はより直感的な API を提供し、HTML-to-PDF 変換をサポートし、テキスト抽出、マージ、PDF の分割などのタスクを簡素化します。このライブラリは iText 7 より少ないコードを必要とし、ビジネスに優しい永続ライセンスモデルを提供します。
C# でウェブページを PDF に変換するにはどうしたらいいですか?
IronPDF の RenderUrlAsPdf メソッドを使用して、ウェブページを直接 PDF ドキュメントに変換できます。これにより、内部的に HTML-to-PDF 変換プロセスが簡素化されます。
IronPDF は大規模な PDF 処理タスクの自動化に適していますか?
はい、IronPDF は自動化およびバッチ処理に適しており、C# プロジェクトで大量の PDF を効率的に扱うのに最適です。
IronPDF を使用して PDF の特定のページ範囲からテキストを抽出できますか?
IronPDF は特定のページまたはページ範囲からテキストを抽出する機能を提供しており、PDF コンテンツを正確に処理できます。
IronPDF が開発者向けに提供するサポートリソースは何ですか?
IronPDF は包括的なドキュメント、チュートリアル、活発なコミュニティを提供します。さらに、開発者をサポートするためにメールやチケットシステムによる直接的な技術サポートが利用可能です。
IronPDF は C# プロジェクトへの統合をどのように処理しますか?
IronPDF は Visual Studio の NuGet パッケージマネージャーを使用して、'Install-Package IronPDF' コマンドで簡単に C# プロジェクトに統合できます。
IronPDF のライセンスオプションはどのようになっていますか?
IronPDF はビジネスに優しく、iText 7 の AGPL ライセンスに関連するオープンソース配布要件を回避する永続ライセンスモデルを提供します。
IronPDF は C# プロジェクトでの開発者の生産性をどのように向上させますか?
IronPDF は使いやすい API を通じて複雑な PDF タスクを簡素化し、必要なコード量を削減し、開発プロセスを加速して C# プロジェクトでの生産性を向上させます。
IronPDF は PDF の HTML への変換をサポートしていますか?
はい、IronPDF は PDF の HTML 文字列への変換機能を提供し、ウェブアプリケーションでの PDF コンテンツの表示や操作を容易にします。
IronPDF の PDF 操作の主要な機能は何ですか?
IronPDF は PDF の作成、テキスト抽出、HTML-to-PDF 変換、マージ、分割、透かし、デジタル署名など、使いやすい API で幅広い機能をサポートしています。













