
IronPDF vs iTextSharp: Lendo arquivos PDF em C
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
O processamento de PDFs é uma tarefa comum no desenvolvimento em C#, desde a extração de texto até a modificação de documentos. iText tem sido por muito tempo uma biblioteca muito utilizada para isso, mas sua sintaxe complexa e curva de aprendizado íngreme podem atrasar o desenvolvimento.
O IronPDF oferece uma alternativa mais simples e eficiente. Com uma API intuitiva, conversão integrada de HTML para PDF e extração de texto facilitada, o IronPDF simplifica o manuseio de PDFs com menos código. Neste artigo, vamos comparar iText e IronPDF, demonstrando por que o IronPDF é a escolha mais inteligente para desenvolvedores C#.
Compreendendo o iText: Uma Visão Geral
iText (originalmente iText) é uma poderosa biblioteca de código aberto para trabalhar com PDFs em .NET. Oferece funções abrangentes para criar, modificar, criptografar e extrair conteúdo de documentos PDF. Muitos desenvolvedores dependem dele para automatizar fluxos de trabalho de documentos, gerar relatórios e lidar com tarefas de processamento de PDFs em larga escala.
Uma das maiores forças do iText é seu controle granular sobre as estruturas de PDF. Ele oferece suporte a anotações, campos de formulário, marcas d'água e assinaturas digitais, tornando-se uma ferramenta robusta para manipulação avançada de documentos. Além disso, é bem documentado e amplamente utilizado, com forte apoio da comunidade e inúmeros recursos de terceiros disponíveis.
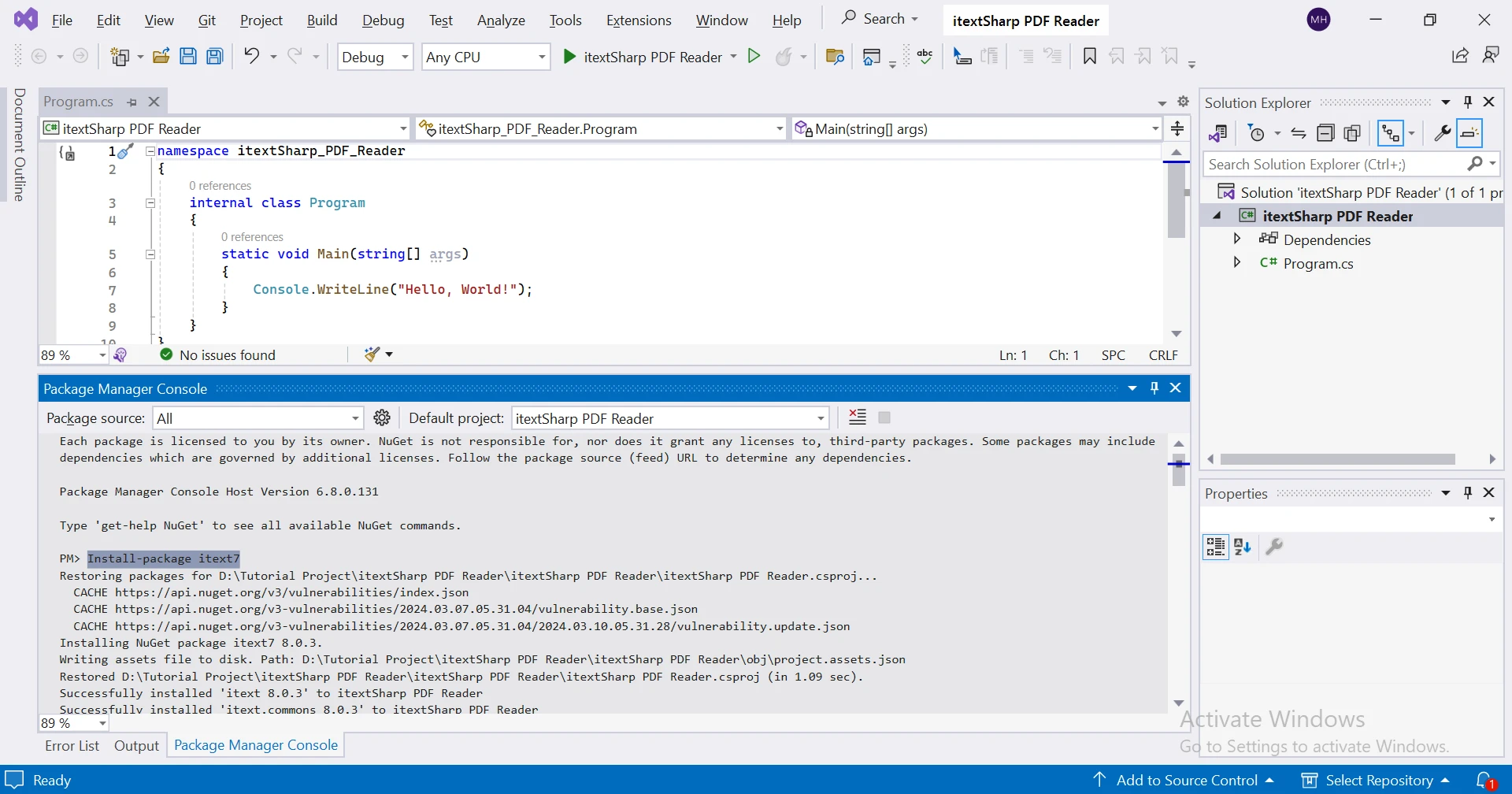
Installing iText
Para instalar o iText em um projeto .NET, você pode usar o Gerenciador de Pacotes NuGet no Visual Studio:
Utilizando o Console do Gerenciador de Pacotes NuGet :
Install-Package itext7
No entanto, o iText apresenta desafios. Sua API complexa exige mais código para tarefas comuns, como extração de texto ou fusão de PDFs, e não oferece suporte integrado para conversão de HTML para PDF, o que dificulta os fluxos de trabalho da web para documentos. Além disso, sua licença AGPL exige que as empresas comprem uma licença comercial para evitar os requisitos de distribuição de código aberto.
Para desenvolvedores que buscam uma API mais simplificada e de alto nível com recursos modernos, o IronPDF apresenta uma alternativa atraente.
Apresentando o IronPDF: Uma solução superior
IronPDF é uma biblioteca .NET projetada para tornar a extração, manipulação e geração de PDFs simples e eficiente. Ao contrário do iText, que requer extensa codificação para muitas operações, o IronPDF permite que os desenvolvedores leiam, editem e modifiquem PDFs com esforço mínimo.
Para extração de PDFs, o IronPDF facilita a extração de texto, imagens e dados estruturados de PDFs com apenas algumas linhas de código, simplificando suas tarefas de extração de texto. No que diz respeito à manipulação de PDFs, o IronPDF suporta a fusão , divisão , adição de marcas d'água e edição de PDFs sem exigir operações complexas de baixo nível.
Além disso, o IronPDF inclui conversão nativa de HTML para PDF , facilitando a geração de PDFs a partir de páginas da web ou conteúdo HTML existente. Ele também oferece suporte à renderização de JavaScript , assinaturas digitais e criptografia , fornecendo um conjunto de ferramentas completo para aplicações modernas.
Com uma API mais limpa, melhor documentação e suporte comercial, o IronPDF é uma alternativa amigável para desenvolvedores que simplifica o manuseio de PDFs em C#. Nas seções seguintes, compararemos como ambas as bibliotecas lidam com tarefas importantes de PDF e por que o IronPDF oferece uma experiência melhor para desenvolvedores C#.
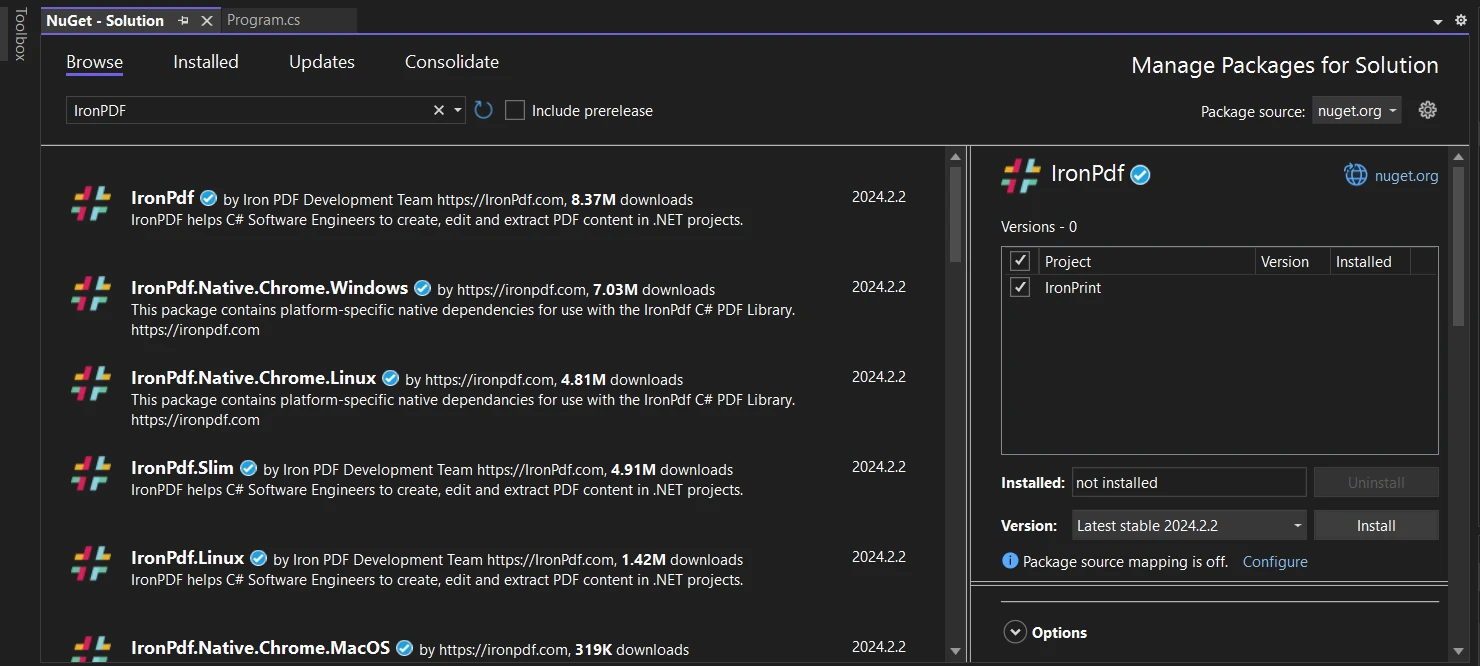
Instalação
Para instalar e executar o IronPDF em seus projetos C#, basta executar a seguinte linha no Gerenciador de Pacotes NuGet :
Install-Package IronPdf
Ou, alternativamente, acesse Ferramentas > Gerenciador de Pacotes NuGet > Gerenciar Pacotes NuGet para a Solução e procure por IronPDF.
Em seguida, basta clicar em "Instalar" e o IronPDF será adicionado ao seu projeto num instante!
IronPDF vs iText no Processamento de PDF: Comparação de Código
Utilizando o IronPDF para extrair texto
O IronPDF simplifica a extração, manipulação e leitura de texto em PDFs com uma API muito mais amigável para desenvolvedores. Ao contrário do iText, que requer operações de baixo nível, o IronPDF permite a extração de texto em apenas algumas linhas de código.
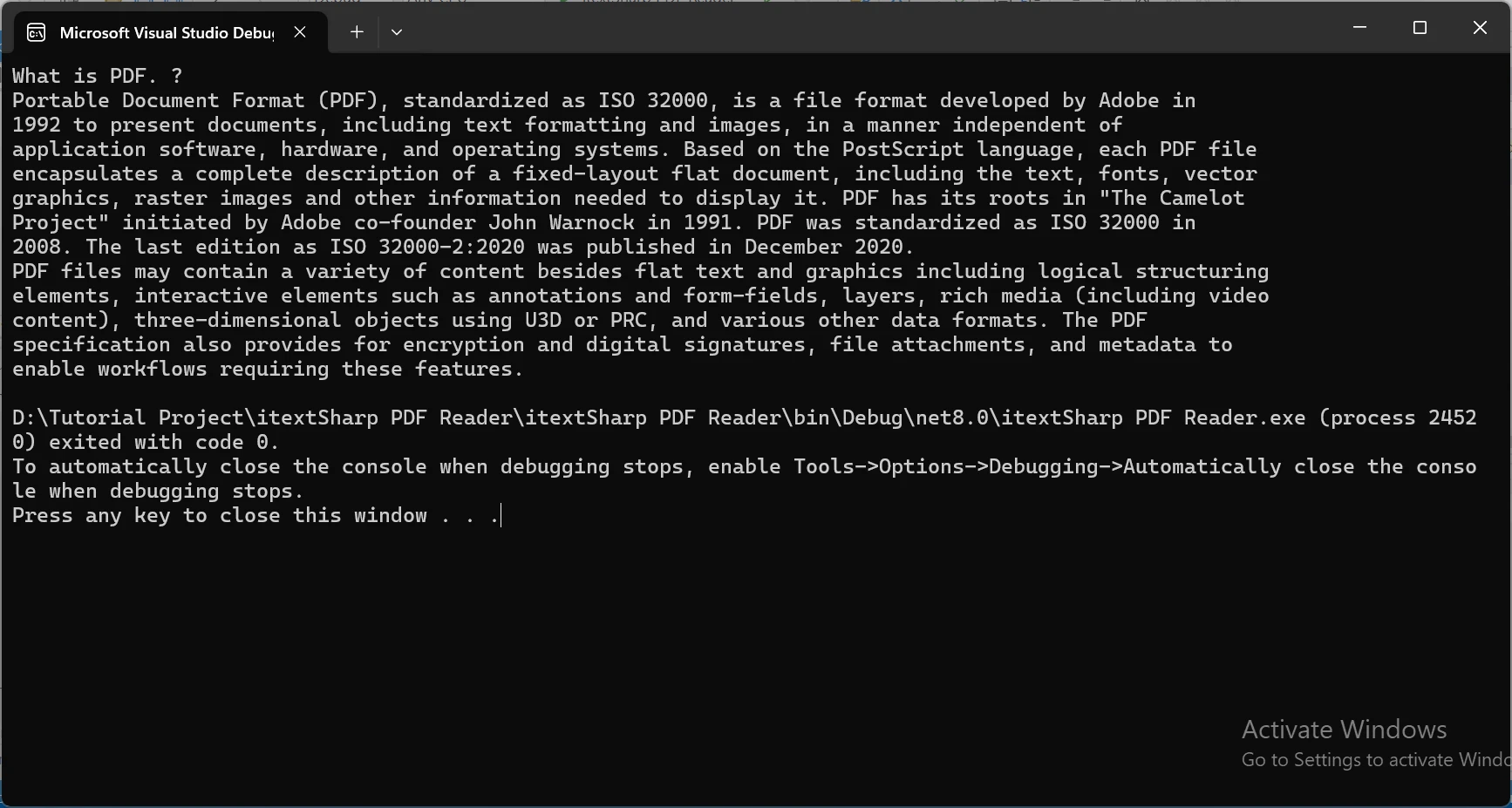
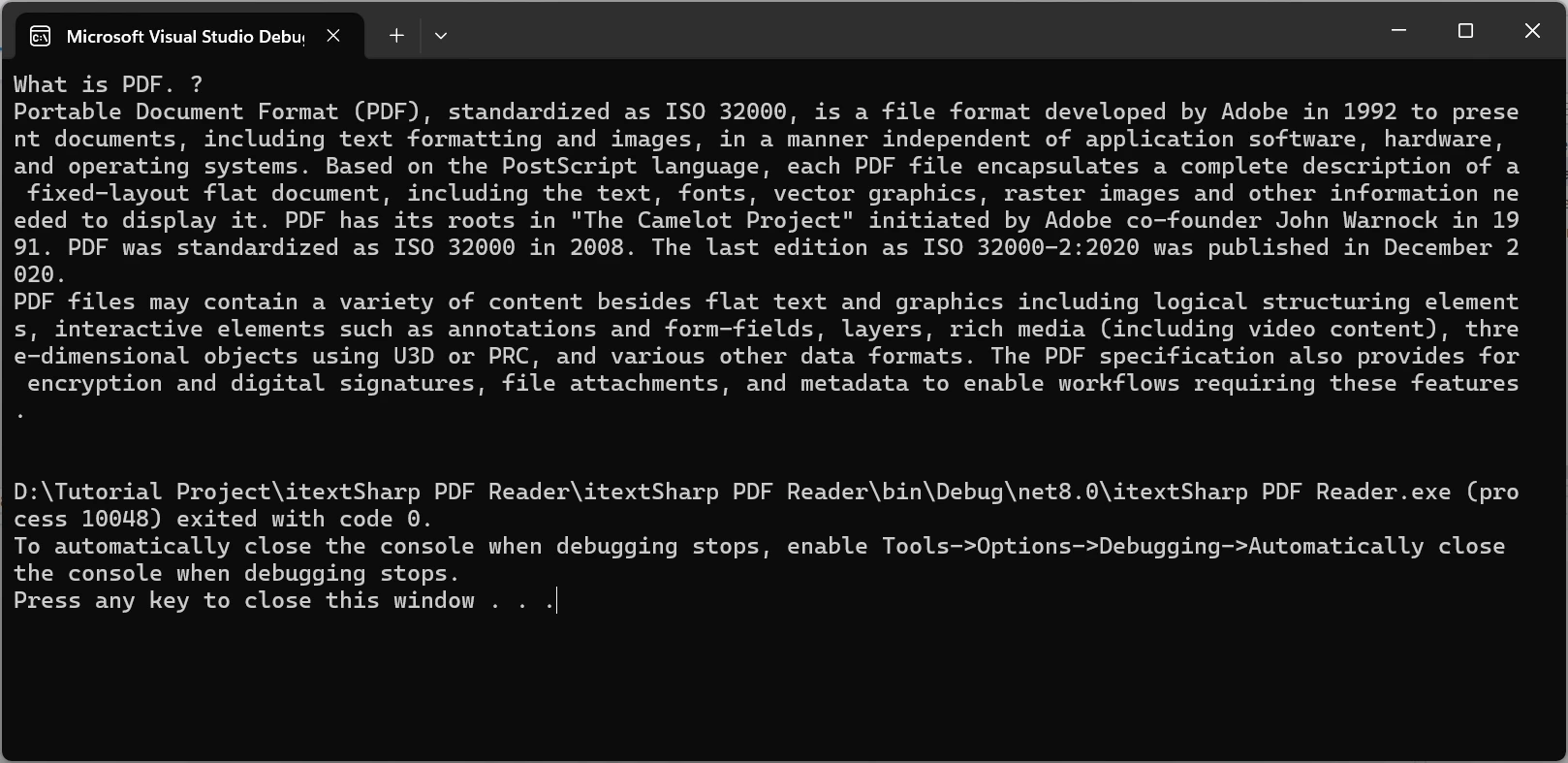
Para demonstrar a poderosa ferramenta de extração de texto do IronPDF em ação, utilizarei o seguinte documento PDF e extrairei seu conteúdo.
Exemplo de código
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
' Load the PDF document
Dim pdf = New PdfDocument(pdfPath)
' Extract all text from the loaded PDF document
Dim extractedText As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End ClassSaída
Explicação:
O IronPDF simplifica a extração de texto de PDFs com sua API de alto nível, eliminando a necessidade de operações de baixo nível. Em apenas algumas linhas de código, o IronPDF pode extrair eficientemente todo o texto de um documento PDF, ao contrário de bibliotecas como o iText, que muitas vezes exigem iteração manual de páginas e manipulação complexa.
No exemplo, a classe PdfDocument carrega o PDF e o método ExtractAllText() rapidamente extrai todo o texto, simplificando o processo. Este é um grande benefício em relação ao iText, onde você precisaria manipular manualmente páginas individuais e elementos de texto.
Expandindo o IronPDF para outras tarefas:
Partindo do exemplo básico de extração de texto, a API de alto nível do IronPDF simplifica outras tarefas comuns em PDFs, mantendo a facilidade de uso e a eficiência:
Extração de texto de páginas específicas: Se você precisar extrair texto de uma página ou intervalo específico, o IronPDF permite que você faça isso facilmente. Por exemplo, para extrair texto da primeira página:
var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
' Access text from the first page
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)Manipulação de PDFs: Depois de extrair texto ou dados de vários PDFs, você pode querer combiná-los em um único documento. O IronPDF simplifica a fusão de vários PDFs:
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
' Merge the PDFs into a single document
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")Conversão de PDF para HTML: Se você precisar converter um PDF de volta para HTML para extração ou manipulação posterior, o IronPDF também oferece essa funcionalidade:
var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
' Convert the PDF to an HTML string
Dim htmlContent As String = pdf.ToHtmlString()Com o IronPDF, a extração de texto é apenas o começo. A API simples e poderosa da biblioteca abrange uma ampla gama de tarefas de manipulação de PDF, tudo em um formato intuitivo e fácil de integrar ao seu fluxo de trabalho.
Lendo PDFs com iText
O iText requer trabalhar com leitores de PDF, fluxos e processamento de dados em nível de byte. Extrair texto não é uma tarefa simples, pois envolve percorrer páginas de PDF e lidar manualmente com diversas estruturas. Para este exemplo de código, usaremos o mesmo documento PDF que usamos na seção IronPDF .
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
' Method to extract text from a PDF
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
' Use PdfReader to load the PDF
Using reader As New PdfReader(pdfPath)
' Open the PDF document for processing
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
' Iterate through each page and extract text
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
End ClassSaída
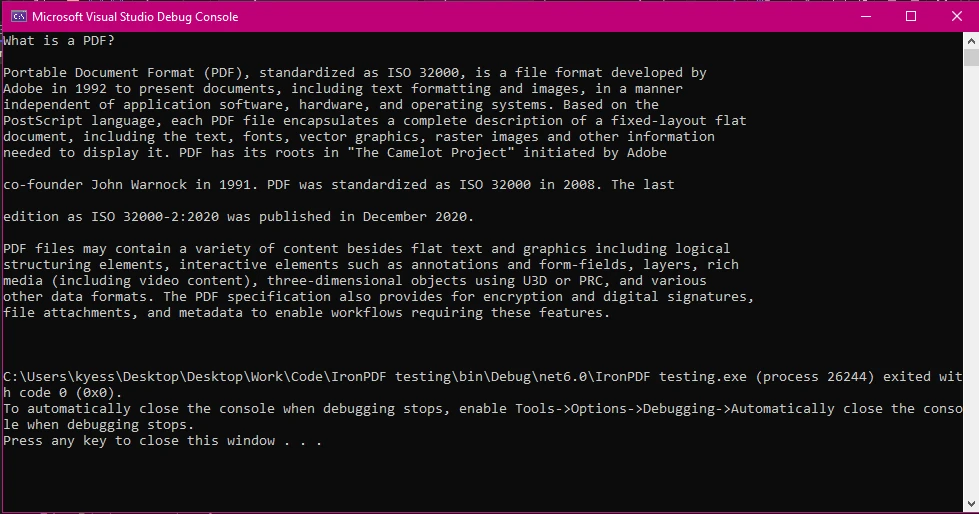
Explicação:
- O
PdfReadercarrega o arquivo PDF para leitura. - O objeto
PdfDocumentpermite iterar pelas páginas. PdfTextExtractor.GetTextFromPage()recupera texto de cada página.- O texto final é armazenado em uma string e exibido.
Este método funciona, mas requer iteração manual e pode ser trabalhoso para documentos estruturados ou PDFs digitalizados.
Comparing iText and IronPDF
Enquanto o iText requer codificação detalhada para realizar operações com PDF, o IronPDF simplifica essas tarefas com métodos diretos. Por exemplo, extrair texto de um PDF com iText envolve várias etapas e extensa codificação, enquanto o IronPDF realiza isso em apenas algumas linhas. Além disso, o suporte do IronPDF para conversão de HTML para PDF é mais robusto, lidando perfeitamente com HTML, CSS e JavaScript complexos.
Principais conclusões
- O IronPDF simplifica as tarefas de leitura e manipulação de PDFs com uma API mais intuitiva e otimizada, exigindo menos código para executar operações comuns.
- A extração de texto do IronPDF é mais fácil de implementar em comparação com o processo de iteração mais complexo do iText, economizando tempo dos desenvolvedores.
- O licenciamento perpétuo do IronPDF é mais amigável aos negócios, oferecendo menos restrições comparado à licença AGPL do iText.
- O IronPDF possui uma documentação melhor e mais acessível para resolução rápida de problemas, sendo ideal para desenvolvedores que desejam soluções rápidas sem precisar vasculhar recursos excessivos.
Otimizando seu fluxo de trabalho com o IronPDF
O IronPDF oferece um conjunto de recursos poderosos que vão além da simples leitura de PDFs. Essas características fazem dela uma solução robusta para desenvolvedores que buscam otimizar seus fluxos de trabalho com PDFs. Veja como o IronPDF pode aprimorar seu processo de desenvolvimento:
1. Extração de texto de PDFs
O IronPDF permite a extração fácil de texto de arquivos PDF, sendo ideal para fluxos de trabalho que envolvem análise de documentos, extração de dados ou indexação de conteúdo. Com o IronPDF, você pode extrair rapidamente texto de PDFs e usá-lo em seus aplicativos sem precisar lidar com análises complexas.
2. Criação de PDF
O IronPDF facilita a geração de PDFs do zero, seja para criar relatórios, faturas ou outros tipos de documentos. A ferramenta também suporta a conversão de HTML para PDF, permitindo que você aproveite o conteúdo da web existente e gere PDFs bem formatados. Esta solução é perfeita para situações em que você precisa converter páginas da web ou conteúdo HTML dinâmico em arquivos PDF para download.
3. Recursos avançados de PDF
Além da extração básica de texto e da criação de PDFs, o IronPDF oferece recursos avançados, como preenchimento de formulários em PDF, adição de anotações e manipulação do conteúdo do documento. Essas funcionalidades são úteis em setores como o jurídico, o financeiro ou o educacional, onde formulários e feedbacks fazem parte da rotina do fluxo de trabalho.
4. Processamento em lote
O IronPDF é ideal para processar um grande número de arquivos PDF. Seja para extrair informações de centenas de documentos ou converter vários arquivos HTML em PDFs, o IronPDF pode automatizar essas tarefas e executá-las com eficiência, economizando tempo e esforço.
5. Automação e Eficiência
O IronPDF simplifica tarefas de manipulação de PDFs que costumam ser demoradas e repetitivas. Ao automatizar tarefas como extração de texto de PDFs, preenchimento de formulários ou conversão em lote, os desenvolvedores podem se concentrar em aspectos mais complexos de seus projetos, enquanto o IronPDF cuida do trabalho pesado.
Suporte técnico e recursos da comunidade
Para garantir que os desenvolvedores possam aproveitar ao máximo o IronPDF, a ferramenta conta com forte suporte e recursos da comunidade:
- Suporte técnico: A IronPDF oferece suporte direto por e-mail e sistema de tickets, fornecendo assistência para quaisquer desafios técnicos ou de implementação.
- Recursos da comunidade: O site do IronPDF inclui extensa documentação, tutoriais e posts de blog. Os desenvolvedores também podem encontrar soluções e compartilhar conhecimento por meio do GitHub e do Stack Overflow, onde a comunidade discute ativamente as melhores práticas e dicas de solução de problemas.
Conclusão
Neste artigo, exploramos os recursos do IronPDF como uma biblioteca poderosa e fácil de usar para manipulação de PDFs para desenvolvedores .NET . Comparamos com o iText, destacando como o IronPDF simplifica tarefas complexas como extração de texto e manipulação de PDF. A API intuitiva e os recursos avançados do IronPDF, incluindo edição, marca d'água e assinaturas digitais, fazem dele uma solução superior para fluxos de trabalho modernos com PDFs.
Ao contrário do iText, que requer codificação intrincada para tarefas comuns de PDF, o IronPDF permite a realização de operações complexas com código mínimo, economizando tempo e esforço dos desenvolvedores. Quer você esteja trabalhando com documentos digitalizados, gerando PDFs a partir de HTML ou adicionando marcas d'água personalizadas, o IronPDF oferece uma maneira intuitiva e eficiente de lidar com tudo isso.
Se você busca otimizar seus fluxos de trabalho com PDFs e aumentar a produtividade em seus projetos C#, o IronPDF é a escolha ideal.
Convidamos você a baixar o IronPDF e experimentá-lo você mesmo. Com um período de teste gratuito disponível, você pode experimentar em primeira mão como é fácil integrar o IronPDF em seus aplicativos e começar a aproveitar seus poderosos recursos hoje mesmo.
Clique abaixo para começar seu teste gratuito:
- Comece sua avaliação gratuita com o IronPDF
- Saiba mais sobre os recursos e preços do IronPDF Não espere mais – desbloqueie todo o potencial do gerenciamento perfeito de PDFs com o IronPDF!
Perguntas frequentes
Quais são as vantagens de usar o IronPDF em vez do iText 7 para manipulação de PDFs em C#?
O IronPDF oferece uma API mais intuitiva, suporta conversão de HTML para PDF e simplifica tarefas como extração de texto, mesclagem e divisão de PDFs. Requer menos código que o iText 7 e oferece um modelo de licenciamento perpétuo favorável para empresas.
Como posso converter uma página da web em PDF usando C#?
Você pode usar o método RenderUrlAsPdf do IronPDF para converter uma página da web diretamente em um documento PDF. Isso simplifica o processo, lidando internamente com a conversão de HTML para PDF.
O IronPDF é adequado para automatizar tarefas de processamento de PDFs de grande porte?
Sim, o IronPDF é muito adequado para automação e processamento em lote, sendo ideal para lidar com grandes volumes de PDFs de forma eficiente em projetos C#.
Posso extrair texto de um intervalo específico de páginas em um PDF usando o IronPDF?
O IronPDF oferece funcionalidades para extrair texto de páginas ou intervalos de páginas específicos, permitindo o manuseio preciso do conteúdo de PDFs.
Que recursos de suporte o IronPDF oferece para desenvolvedores?
O IronPDF oferece documentação completa, tutoriais e uma comunidade ativa. Além disso, há suporte técnico direto disponível por e-mail e um sistema de tickets para auxiliar os desenvolvedores.
Como o IronPDF lida com a integração em um projeto C#?
O IronPDF pode ser facilmente integrado a um projeto C# instalando-o através do Gerenciador de Pacotes NuGet no Visual Studio usando o comando 'Install-Package IronPDF'.
Quais são as opções de licenciamento para o IronPDF?
O IronPDF oferece um modelo de licenciamento perpétuo, que é favorável às empresas e evita os requisitos de distribuição de código aberto associados à licença AGPL do iText 7.
Como o IronPDF melhora a produtividade dos desenvolvedores em projetos C#?
O IronPDF simplifica tarefas complexas com PDFs por meio de sua API amigável, reduzindo a quantidade de código necessária e acelerando os processos de desenvolvimento, o que aumenta a produtividade em projetos C#.
O IronPDF suporta a conversão de PDFs para HTML?
Sim, o IronPDF oferece funcionalidades para converter PDFs em strings HTML, facilitando a exibição e manipulação do conteúdo de PDFs em aplicações web.
Quais são as principais funcionalidades do IronPDF para manipulação de PDFs?
O IronPDF oferece suporte a uma ampla gama de recursos, incluindo criação de PDFs, extração de texto, conversão de HTML para PDF, mesclagem, divisão, marca d'água e assinaturas digitais, tudo com uma API fácil de usar.












