
如何使用iTextSharp在C#中讀取PDF文檔:
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
處理 PDF 是 C# 開發中常見的工作,從抽取文字到修改文件。 iText 7 長久以來一直是這方面的常用函式庫,但其複雜的語法和陡峭的學習曲線可能會拖慢開發速度。
IronPDF提供了更簡單、更有效率的選擇。IronPDF 具備直覺式 API、內建 HTML 至 PDF 轉換功能,以及更簡易的文字擷取功能,能以更少的程式碼簡化 PDF 處理流程。 在本文中,我們將比較 iText 7 和 IronPDF,說明為什麼 IronPDF 是 C# 開發人員更明智的選擇。
瞭解 iText 7:概述
iText 7(原 iTextSharp)是一個功能強大的開放源碼函式庫,用於在 .NET 中處理 PDF。 它提供了從 PDF 文件中建立、修改、加密和擷取內容的廣泛功能。 許多開發人員都仰賴它來自動化文件工作流程、產生報告以及處理大規模的 PDF 處理工作。
iText 7 的最大優勢之一是其對 PDF 結構的精細控制。 它支援註解、表單欄位、水印和數位簽章,使其成為進階文件處理的強大工具。 此外,這些工具文件完備、使用廣泛,並擁有強大的社群支援和眾多的第三方資源。
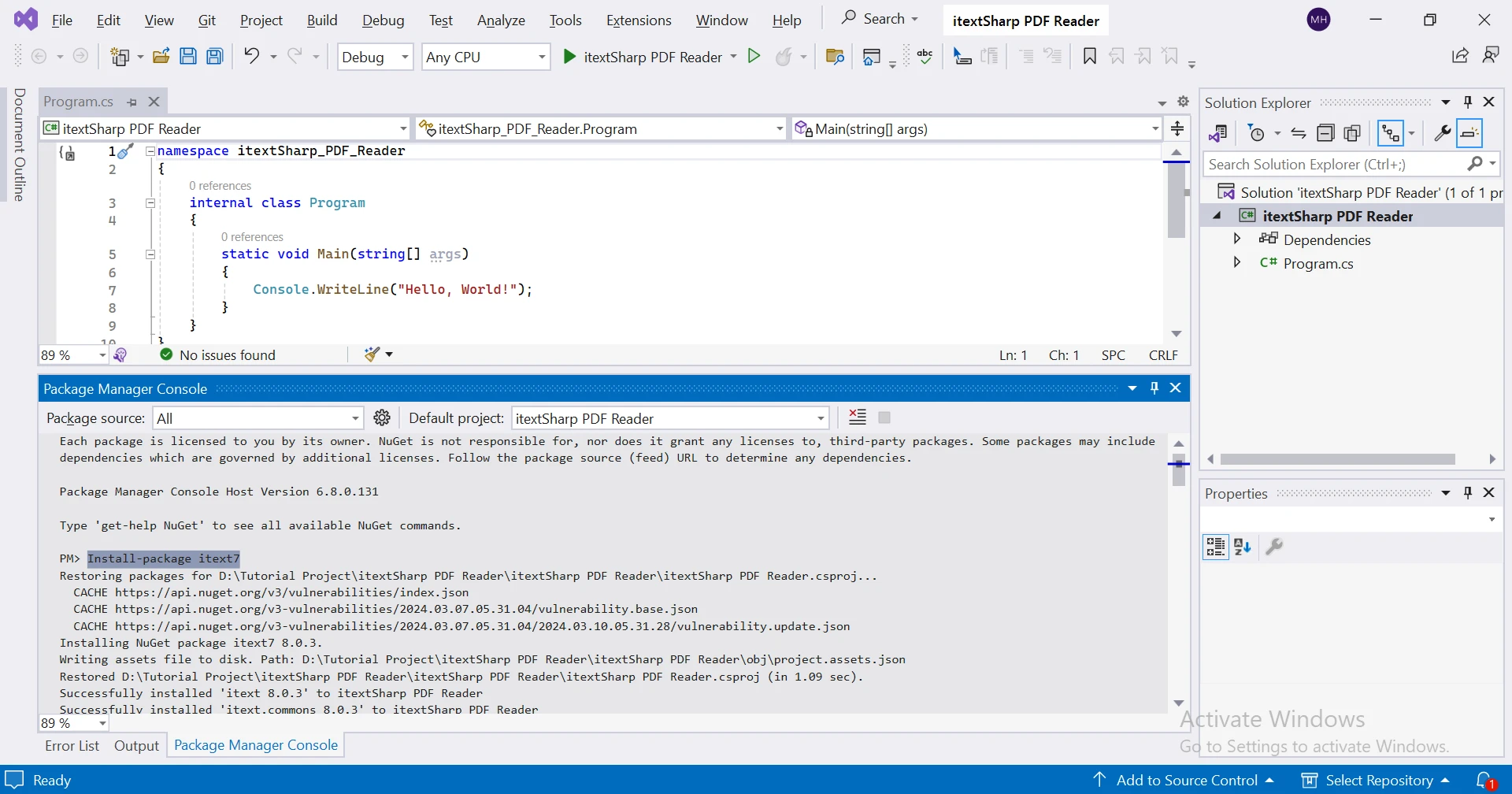
安裝 iText 7
若要在 .NET 專案中安裝 iText 7,您可以使用 Visual Studio 中的 NuGet Package Manager:
使用 NuGet 套件管理員控制台:
Install-Package itext7
然而,iText 7 也帶來了挑戰。 其複雜的 API 需要更多程式碼才能執行文字萃取或合併 PDF 等常見工作,而且缺乏 HTML 至 PDF 轉換的內建支援,使得網頁至文件的工作流程變得更加困難。 此外,其 AGPL 授權要求企業購買商業授權,以避免開放原始碼散佈的要求。
對於尋求更精簡、具備現代功能的高階 API 的開發人員而言,IronPDF 提供了一個令人信服的選擇。
介紹 IronPDF:卓越的解決方案
 。
。
IronPDF 是一個 .NET 函式庫,旨在讓 PDF擷取、操作和產生變得簡單且有效率。 IronPDF 與 iText 7 不同,iText 7 的許多操作都需要大量的編碼,而 IronPDF 則允許開發人員以最小的工作量來閱讀、編輯和修改 PDF。
在 PDF 擷取方面,IronPDF 只需幾行程式碼即可輕鬆從 PDF 中抽取文字、圖片和結構化資料,讓您輕鬆簡化文字擷取任務。 談到 PDF 操作,IronPDF 支援 合併、分割、水印,以及編輯 PDF,而不需要複雜的低階操作。
此外,IronPDF 還包含本機 HTML-to-PDF 轉換,讓您可以輕鬆地從網頁或現有的 HTML 內容產生 PDF。 IronPDF 是一套完整的軟體開發工具包,它也支援 JavaScript 渲染、數位簽章和加密,為現代應用程式提供了一套完善的工具包。
IronPDF 擁有更簡潔的 API、更完善的說明文件以及商業支援,是開發人員友善的選擇,可簡化 C# 中的 PDF 處理。 在以下幾節中,我們將比較兩個函式庫如何處理 PDF 的關鍵任務,以及 IronPDF 為 C# 開發人員提供更好體驗的原因。
安裝
要在您的 C# 專案中安裝並運行 IronPDF,只需在 NuGet Package Manager 中執行以下一行即可:
Install-Package IronPdf
或者,也可以前往 Tools > NuGet Package Manager > Manage NuGet Packages for Solution,然後搜尋 IronPDF。
 。
。
然後,只需按一下"安裝",IronPDF 即會立即加入您的專案中!
PDF 處理中的 IronPDF vs iText 7:程式碼比較
使用 IronPDF 擷取文字。
IronPDF 以更方便開發人員使用的 API 簡化 PDF 文字的擷取、操作和閱讀。 IronPDF 與 iText 7 不同,iText 7 需要低階操作,而 IronPDF 只需幾行程式碼即可進行文字擷取。
為了展示 IronPDF 功能強大的文字擷取工具的實作,我將以下列 PDF 文件為例,擷取其中的內容。
!a href="/static-assets/pdf/blog/itextsharp-pdf-reader/itextsharp-pdf-reader-5.webp">Sample PDF for text extraction
程式碼範例
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
' Load the PDF document
Dim pdf = New PdfDocument(pdfPath)
' Extract all text from the loaded PDF document
Dim extractedText As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End Class輸出
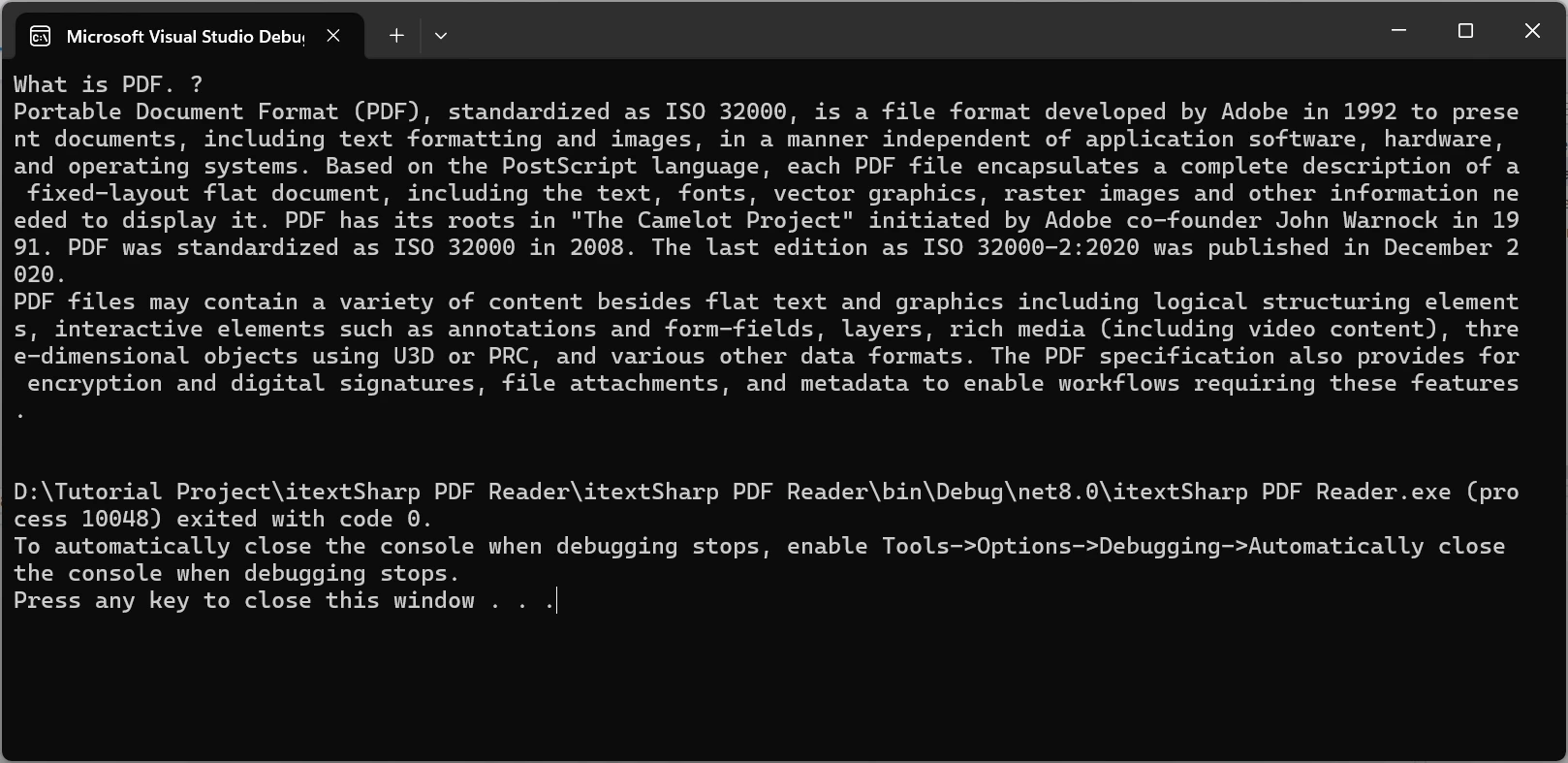
 。
。
說明:
IronPDF 以其高階 API 簡化 PDF 文字擷取,省去低階操作。 只需幾行程式碼,IronPDF 就能有效率地從 PDF 文件中擷取所有文字,不像 iText 7 之類的函式庫,通常需要手動迭代頁面並進行複雜的處理。
在本例中,PdfDocument 類別載入 PDF,而 ExtractAllText() 方法快速提取所有文本,從而簡化了流程。 與 iText 7 相比,這是一大優勢,因為在 iText 7 中,您需要手動處理個別頁面和文字元素。
在 IronPDF 的基礎上擴展其他任務:
在基本文字萃取範例的基礎上,IronPDF 的高階 API 簡化了其他常見的 PDF 任務,同時保持易用性與效率:
從特定頁面提取文本:如果您需要從特定頁面或範圍內提取文本,IronPDF 可以讓您輕鬆完成此操作。 例如,從第一頁抽取文字:
var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
' Access text from the first page
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)PDF 處理:從多個 PDF 文件中提取文字或資料後,您可能想要將它們合併到一個文件中。 IronPDF 讓合併多個 PDF 變得簡單:
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
' Merge the PDFs into a single document
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")PDF 轉 HTML 轉換:如果您需要將 PDF 文件轉換回 HTML 格式以便進一步提取或處理,IronPDF 也提供了此功能:
var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
' Convert the PDF to an HTML string
Dim htmlContent As String = pdf.ToHtmlString()有了 IronPDF,文字擷取只是一個開始。 這個函式庫的 API 簡單且功能強大,可延伸至多種 PDF 處理任務,所有的格式都非常直覺,且容易整合至您的工作流程中。
使用 iText 7 閱讀 PDF。
iText 7 需要使用 PDF閱讀器、串流和位元組級資料處理。 擷取文字的過程並不簡單,因為需要反覆瀏覽 PDF 頁面,並手動處理各種結構。 在本代碼範例中,我們將使用與 IronPDF 部分相同的 PDF 文件。
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
' Method to extract text from a PDF
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
' Use PdfReader to load the PDF
Using reader As New PdfReader(pdfPath)
' Open the PDF document for processing
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
' Iterate through each page and extract text
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
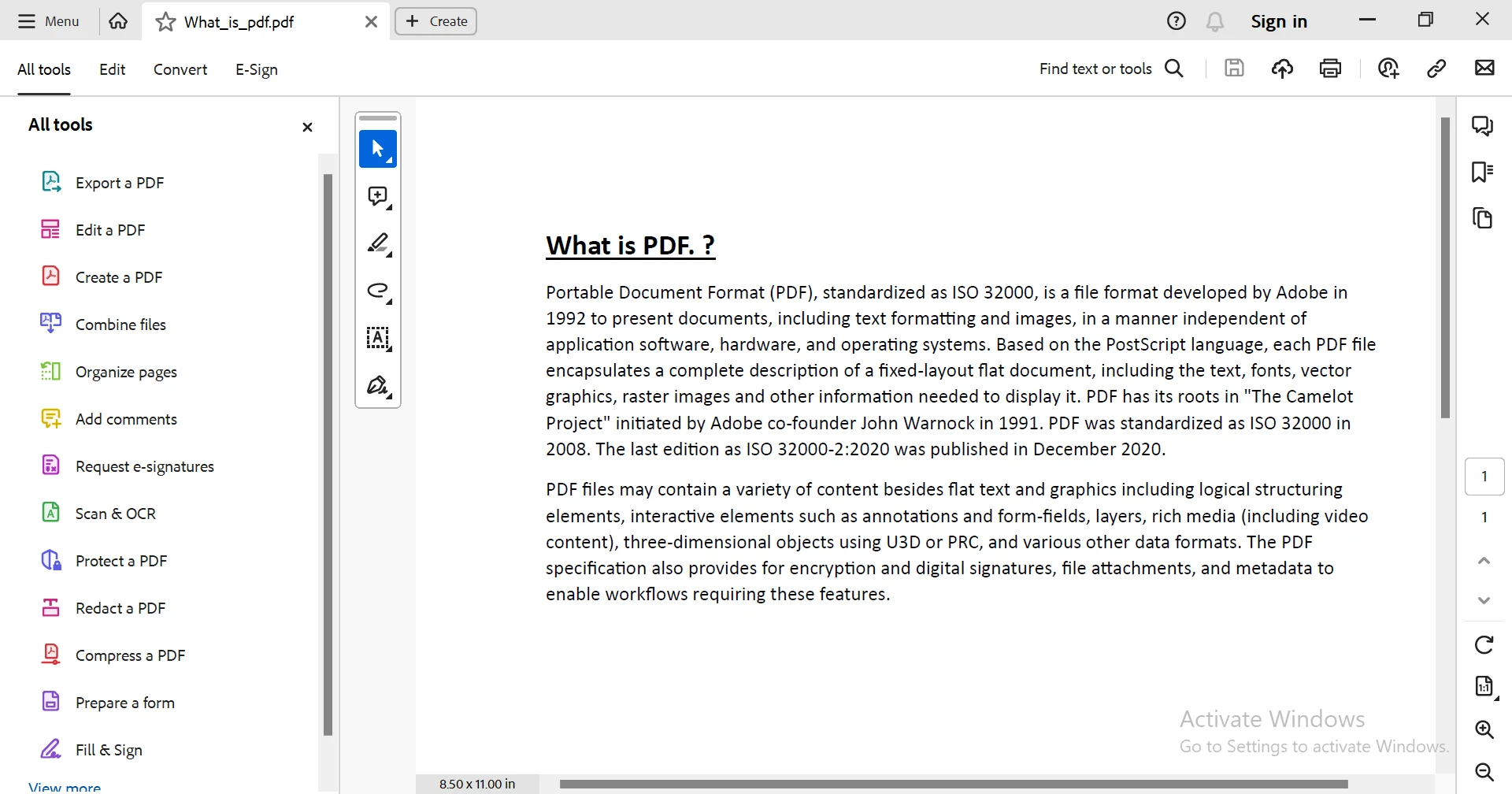
End Class輸出
!a href="/static-assets/pdf/blog/itextsharp-pdf-reader/itextsharp-pdf-reader-7.webp">iText 7 控制台輸出。
說明:
PdfReader載入 PDF 檔案以供閱讀。PdfDocument物件允許遍歷頁面。PdfTextExtractor.GetTextFromPage()從每一頁檢索文字。- 最終的文字會儲存在字串中並顯示出來。
此方法可行,但需要手動反覆處理,對結構化文件或掃描的 PDF 而言可能較為麻煩。
比較 iText 7 與 IronPDF。
iText 7 需要進行詳細的編碼才能執行 PDF 作業,而 IronPDF 則使用簡單直接的方法簡化了這些工作。 例如,使用 iText 7 從 PDF 中提取文字涉及多個步驟和大量代碼,而 IronPDF 只需幾行即可完成。 此外,IronPDF 對 HTML 至 PDF 轉換的支援更加強大,可以無縫處理複雜的 HTML、CSS 和 JavaScript。
主要心得
- IronPDF 透過更直覺、更精簡的 API 簡化 PDF 閱讀與操作任務,只需更少的程式碼即可執行一般操作。
- 相較於 iTextSharp 較複雜的迭代過程,IronPDF 的文字擷取更容易實作,可節省開發人員的時間。
- 與 iTextSharp 的 AGPL 授權相比,IronPDF 的永久授權更適合商業用途,提供較少的限制。
- IronPDF 有更好的文件,更方便快速排除故障,非常適合想要快速解決問題而又不想篩選過多資源的開發人員。
使用 IronPDF 優化您的工作流程。
IronPDF 提供了一套強大的功能,不僅限於 PDF 閱讀。 這些功能使其成為希望優化 PDF 工作流程的開發人員的強大解決方案。 以下是 IronPDF 如何提升您的開發流程:
1.從 PDF 中萃取文字。
IronPDF 可從 PDF 檔案中輕鬆擷取文字,非常適合涉及文件分析、資料擷取或內容索引的工作流程。 有了 IronPDF,您可以快速從 PDF 中抽取文字,並在應用程式中使用,而無需處理複雜的解析。
2.製作 PDF 文件。
IronPDF 可讓您輕鬆從零開始生產 PDF,無論您是要建立報表、發票或其他類型的文件。 該工具也支援 HTML 至 PDF 的轉換,讓您可以利用現有的網頁內容,並產生格式良好的 PDF。 這非常適合需要將網頁或動態 HTML 內容轉換為可下載 PDF 檔案的情境。
3.進階 PDF 功能
除了基本的文字萃取和 PDF 創作之外,IronPDF 還支援進階功能,例如填寫 PDF 表單、新增註解以及操作文件內容。 這些功能對法律、金融或教育等行業非常有用,在這些行業中,表單和回饋是工作流程的常規部分。
4.批次處理。
IronPDF 非常適合處理大量 PDF 檔案。 無論您是要從數百個文件中抽取資訊,或是將多個 HTML 檔案轉換為 PDF,IronPDF 都能將這些任務自動化並有效率地處理,節省時間與精力。
5.自動化與效率。
IronPDF 簡化了通常耗時且重複的 PDF 操作任務。透過自動化 PDF 文字萃取、表格填寫或批次轉換等工作,開發人員可以專注於專案中更複雜的部分,而讓 IronPDF 處理繁重的工作。
技術支援與社群資源
為了確保開發人員能充分發揮 IronPDF 的功能,該工具有強大的支援和社群資源作為後盾:
- 技術支援: IronPDF 透過電子郵件和票務系統提供直接的支援,針對任何實施或技術上的挑戰提供協助。
- 社區資源: IronPDF 網站包含廣泛的文件、教學和部落格文章。 開發人員也可以透過 GitHub 和 Stack Overflow 找到解決方案並分享知識,社群會積極討論最佳實務和疑難排解技巧。
結論
在這篇文章中,我們探討了 IronPDF 作為 .NET 開發人員的強大、人性化 PDF 處理函式庫的功能。 我們將其與 iText 7 作比較,強調 IronPDF 如何簡化複雜的工作,例如文字萃取和 PDF 操作。 IronPDF 簡潔的 API 和先進的功能(包括編輯、水印和數位簽名)使其成為現代 PDF 工作流程的優秀解決方案。
IronPDF 與 iText 7 不同,前者需要複雜的編碼才能執行一般的 PDF 任務,而 IronPDF 則只需最少的程式碼即可執行複雜的操作,為開發人員節省時間與精力。 無論您是處理掃描的文件、從 HTML 產生 PDF,或是新增自訂水印,IronPDF 都能提供直覺且有效率的處理方式。
如果您希望簡化 PDF 工作流程並提高 C# 專案的生產力,IronPDF 將是您的理想選擇。
我們邀請您 下載 IronPDF 並親自試用。 透過免費試用,您可以親身體驗將 IronPDF 整合到您的應用程式中是多麼容易,並立即開始受益於其強大的功能。
點選下方開始免費試用:
常見問題
使用 IronPDF 處理 PDF 相比 iText 7 有哪些優勢?
IronPDF 提供更直觀的 API,支持 HTML 到 PDF 的轉換,並簡化了文本提取、合併和分割 PDF 等任務。它所需的代碼少於 iText 7 並提供對企業友好的永久許可模式。
如何在 C# 中將網頁轉換為 PDF?
您可以使用 IronPDF 的 RenderUrlAsPdf 方法將網頁直接轉換成 PDF 文檔。這簡化了內部處理 HTML 到 PDF 的轉換過程。
IronPDF 適合自動化大型 PDF 處理任務嗎?
是的,IronPDF 非常適合自動化和批處理,使其成為在 C# 項目中高效處理大量 PDF 的理想選擇。
我可以使用 IronPDF 從 PDF 的特定頁面範圍提取文本嗎?
IronPDF 提供從特定頁面或頁面範圍提取文本的功能,允許精確處理 PDF 內容。
IronPDF 為開發者提供哪些資源支持?
IronPDF 提供全面的文檔、教程和活躍的社區。此外,還有通過電子郵件和工單系統提供的直接技術支持,以協助開發人員。
IronPDF 如何處理與 C# 項目的集成?
可以通過在 Visual Studio 的 NuGet 包管理器中使用命令 'Install-Package IronPDF' 輕鬆將 IronPDF 集成到 C# 項目中。
IronPDF 的許可選項有哪些?
IronPDF 提供一種商業友好的永久許可模式,避免了 iText 7 的 AGPL 許可證所需的開源分發要求。
IronPDF 如何提高 C# 項目中的開發者生產力?
IronPDF 通過其用戶友好的 API 簡化了複雜的 PDF 任務,減少所需代碼量並加速開發過程,增強了 C# 項目中的生產力。
IronPDF 支持將 PDF 轉換為 HTML 嗎?
是的,IronPDF 提供將 PDF 轉換為 HTML 字符串的功能,有助於在 Web 應用中顯示和操作 PDF 內容。
IronPDF 的 PDF 操作的關鍵功能有哪些?
IronPDF 支持多種功能,包括 PDF 創建、文本提取、HTML 到 PDF 的轉換、合併、分割、水印和數字簽名,所有這些都具有易於使用的 API。











