
Jak czytać dokumenty PDF w C# używając iTextSharp:
Full Comparison
Looking for a detailed feature-by-feature breakdown? See how IronPDF stacks up against Itext on pricing, HTML support, and licensing.
Obsługa plików PDF jest częstym zadaniem w programowaniu w języku C#, od wyodrębniania tekstu po modyfikowanie dokumentów. iText 7 od dawna jest najczęściej wybieraną biblioteką do tego celu, ale jej złożona składnia i stroma krzywa uczenia się mogą spowolnić proces tworzenia oprogramowania.
IronPDF oferuje prostszą i bardziej wydajną alternatywę. Dzięki intuicyjnemu API, wbudowanej funkcji konwersji HTML do PDF oraz łatwiejszemu wyodrębnianiu tekstu, IronPDF usprawnia obsługę plików PDF przy użyciu mniejszej ilości kodu. W tym artykule porównamy iText 7 i IronPDF, pokazując, dlaczego IronPDF jest lepszym wyborem dla programistów C#.
Zrozumienie iText 7: przegląd
iText 7 (pierwotnie iTextSharp) to potężna biblioteka open source do pracy z plikami PDF w środowisku .NET. Zapewnia rozbudowane funkcje tworzenia, modyfikowania, szyfrowania i wyodrębniania treści z dokumentów PDF. Wielu programistów korzysta z niego do automatyzacji przepływu dokumentów, generowania raportów oraz obsługi zadań związanych z przetwarzaniem plików PDF na dużą skalę.
Jedną z największych zalet iText 7 jest precyzyjna kontrola nad strukturami plików PDF. Obsługuje adnotacje, pola formularzy, znaki wodne i podpisy cyfrowe, co czyni go solidnym narzędziem do zaawansowanej obróbki dokumentów. Ponadto jest to dobrze udokumentówane i szeroko stosowane rozwiązanie, które cieszy się silnym wsparciem społeczności i dostępnością licznych zasobów stron trzecich.
Instalacja iText 7
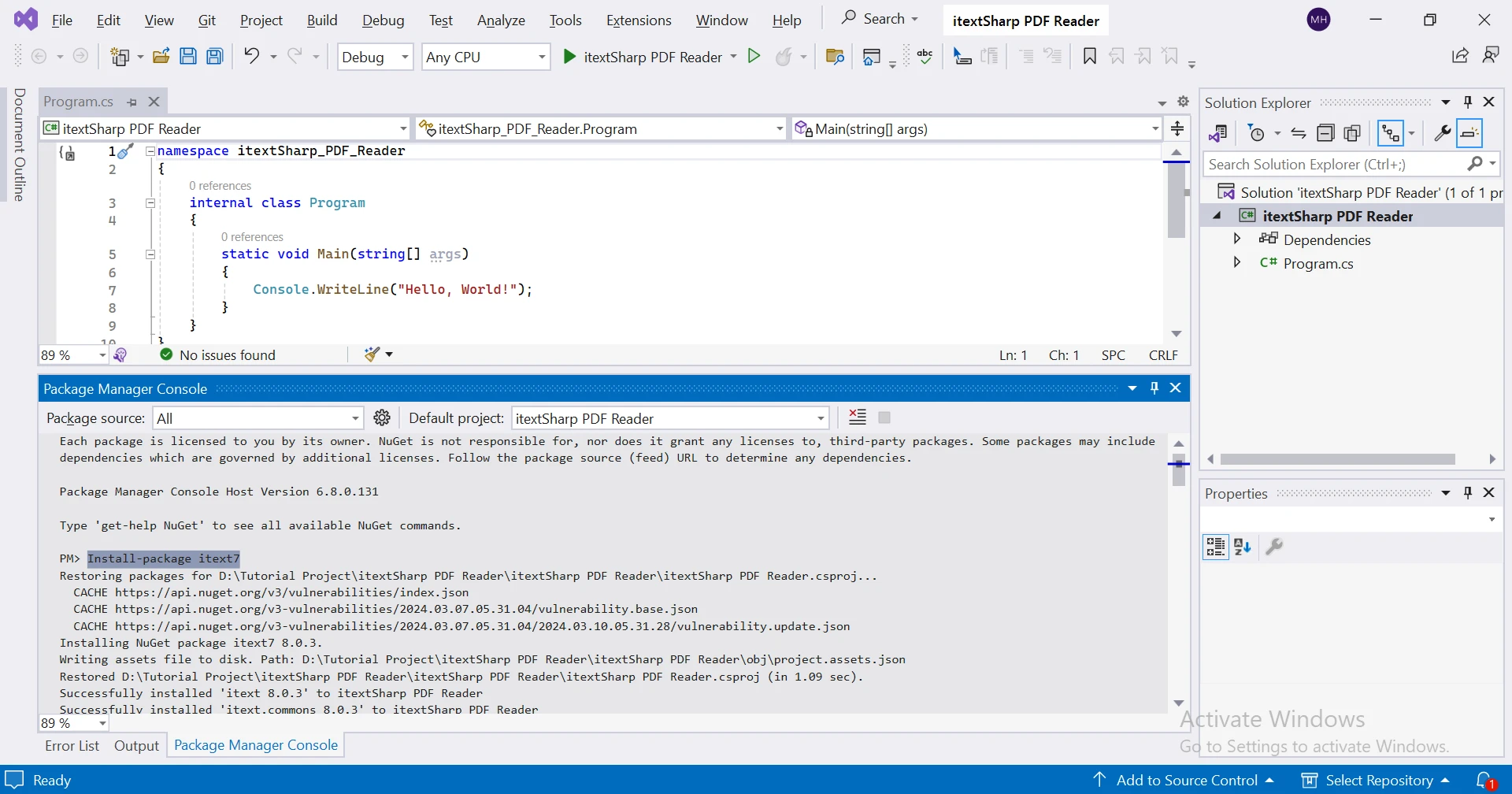
Aby zainstalować iText 7 w projekcie .NET, można użyć menedżera pakietów NuGet w Visual Studio:
Korzystanie z konsoli menedżera pakietów NuGet:
Install-Package itext7
Jednak iText 7 wiąże się z pewnymi wyzwaniami. Jego złożony interfejs API wymaga więcej kodu do typowych zadań, takich jak wyodrębnianie tekstu lub scalanie plików PDF, a także nie ma wbudowanej obsługi konwersji HTML na PDF, co utrudnia przepływ pracy między stroną internetową a dokumentem. Ponadto licencja AGPL wymaga od firm zakupu licencji komercyjnej, aby uniknąć wymogów dotyczących dystrybucji open source.
Dla programistów poszukujących bardziej usprawnionego, wysokopoziomowego API z nowoczesnymi funkcjami, IronPDF stanowi atrakcyjną alternatywę.
Przedstawiamy IronPDF: doskonałe rozwiązanie
IronPDF to biblioteka .NET zaprojektowana w celu uproszczenia i usprawnienia procesu wyodrębniania, przetwarzania i generowania plików PDF. W przeciwieństwie do iText 7, który wymaga rozbudowanego kodowania dla wielu operacji, IronPDF pozwala programistom na odczytywanie, edytowanie i modyfikowanie plików PDF przy minimalnym wysiłku.
W przypadku ekstrakcji plików PDF IronPDF ułatwia pobieranie tekstu, obrazów i danych strukturalnych z plików PDF za pomocą zaledwie kilku wierszy kodu, co pozwala z łatwością usprawnić zadania związane z ekstrakcją tekstu. Jeśli chodzi o obróbkę plików PDF, IronPDF obsługuje scalanie, dzielenie, dodawanie znaków wodnych i edycję plików PDF bez konieczności wykonywania skomplikowanych operacji niskopoziomowych.
Ponadto IronPDF oferuje natywną konwersję HTML do PDF, co ułatwia generowanie plików PDF ze stron internetowych lub istniejącej treści HTML. Obsługuje również renderowanie JavaScript, podpisy cyfrowe i szyfrowanie, zapewniając wszechstronny zestaw narzędzi dla nowoczesnych aplikacji.
Dzięki bardziej przejrzystemu API, lepszej dokumentacji i wsparciu komercyjnemu IronPDF jest przyjazną dla programistów alternatywą, która upraszcza obsługę plików PDF w języku C#. W kolejnych sekcjach porównamy, w jaki sposób obie biblioteki radzą sobie z kluczowymi zadaniami związanymi z plikami PDF oraz dlaczego IronPDF zapewnia lepsze doświadczenia programistom C#.
Instalacja
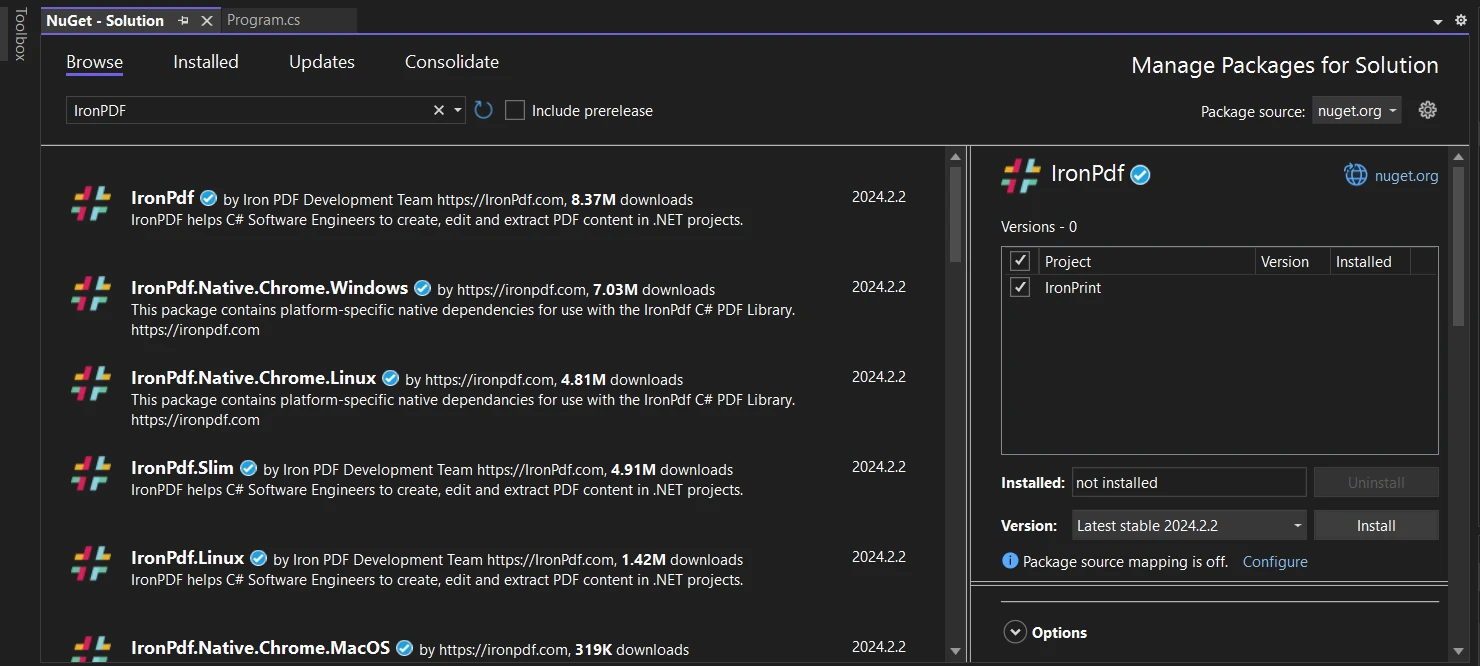
Aby uruchomić IronPDF w projektach C#, wystarczy wykonać następujący wiersz w menedżerze pakietów NuGet:
Install-Package IronPdf
Można też przejść do menu Narzędzia > Menedżer pakietów NuGet > Zarządzaj pakietami NuGet dla rozwiązania i wyszukać IronPDF.
Następnie wystarczy kliknąć "Zainstaluj", a IronPDF zostanie dodany do Twojego projektu w mgnieniu oka!
IronPDF a iText 7 w przetwarzaniu plików PDF: porównanie kodu
Wykorzystanie IronPDF do wyodrębniania tekstu
IronPDF upraszcza wyodrębnianie, edycję i odczytywanie tekstu z plików PDF dzięki API znacznie bardziej przyjaznemu dla programistów. W przeciwieństwie do iText 7, który wymaga operacji niskopoziomowych, IronPDF umożliwia wyodrębnianie tekstu za pomocą zaledwie kilku linii kodu.
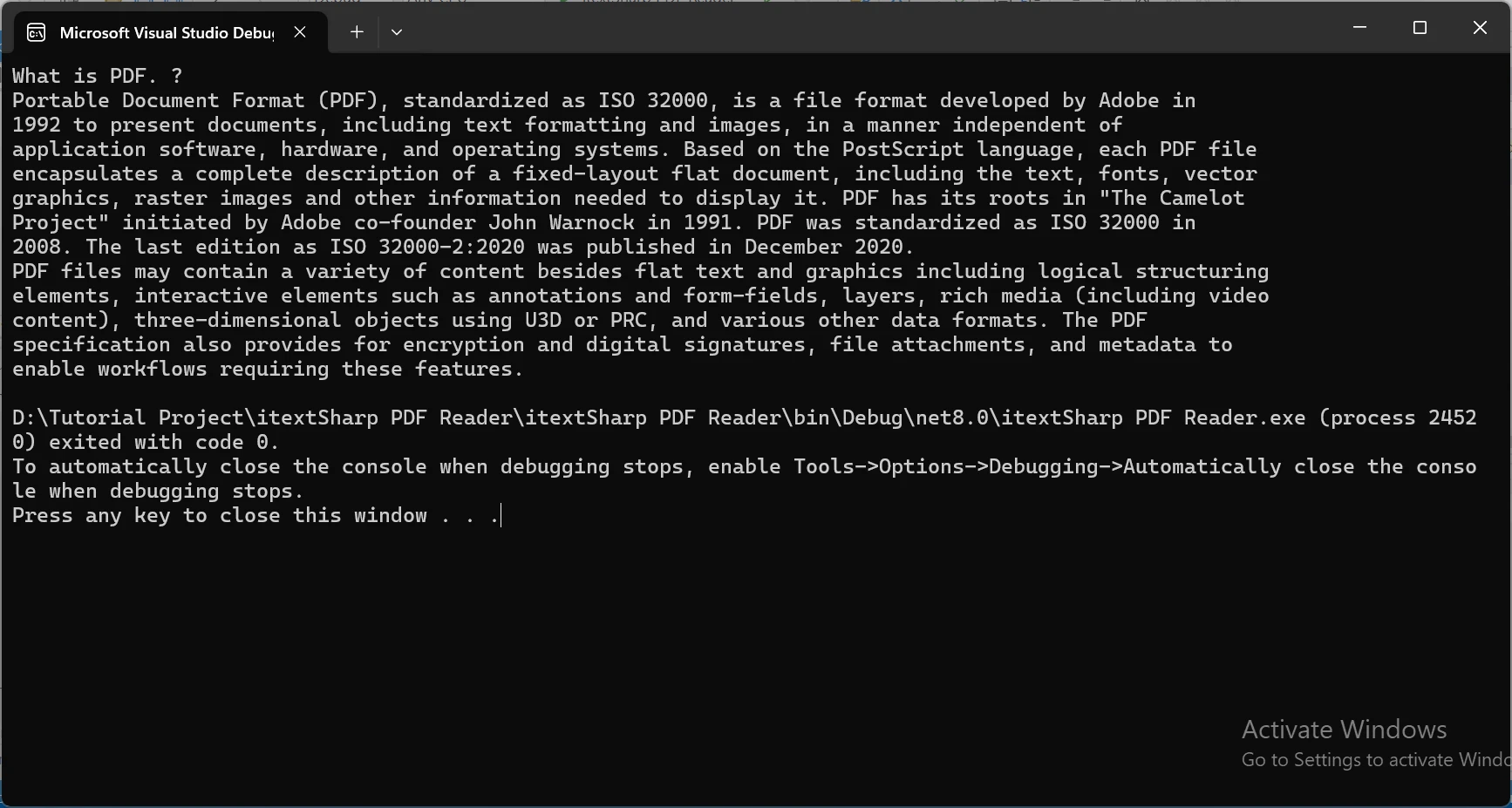
Aby zademonstrować działanie potężnego narzędzia do wyodrębniania tekstu IronPDF, wykorzystam poniższy dokument PDF i wyodrębnię z niego zawartość.
Przykład kodu
using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}using IronPdf;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
// Load the PDF document
var pdf = new PdfDocument(pdfPath);
// Extract all text from the loaded PDF document
string extractedText = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(extractedText);
}
}Imports IronPdf
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
' Load the PDF document
Dim pdf = New PdfDocument(pdfPath)
' Extract all text from the loaded PDF document
Dim extractedText As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(extractedText)
End Sub
End ClassWynik
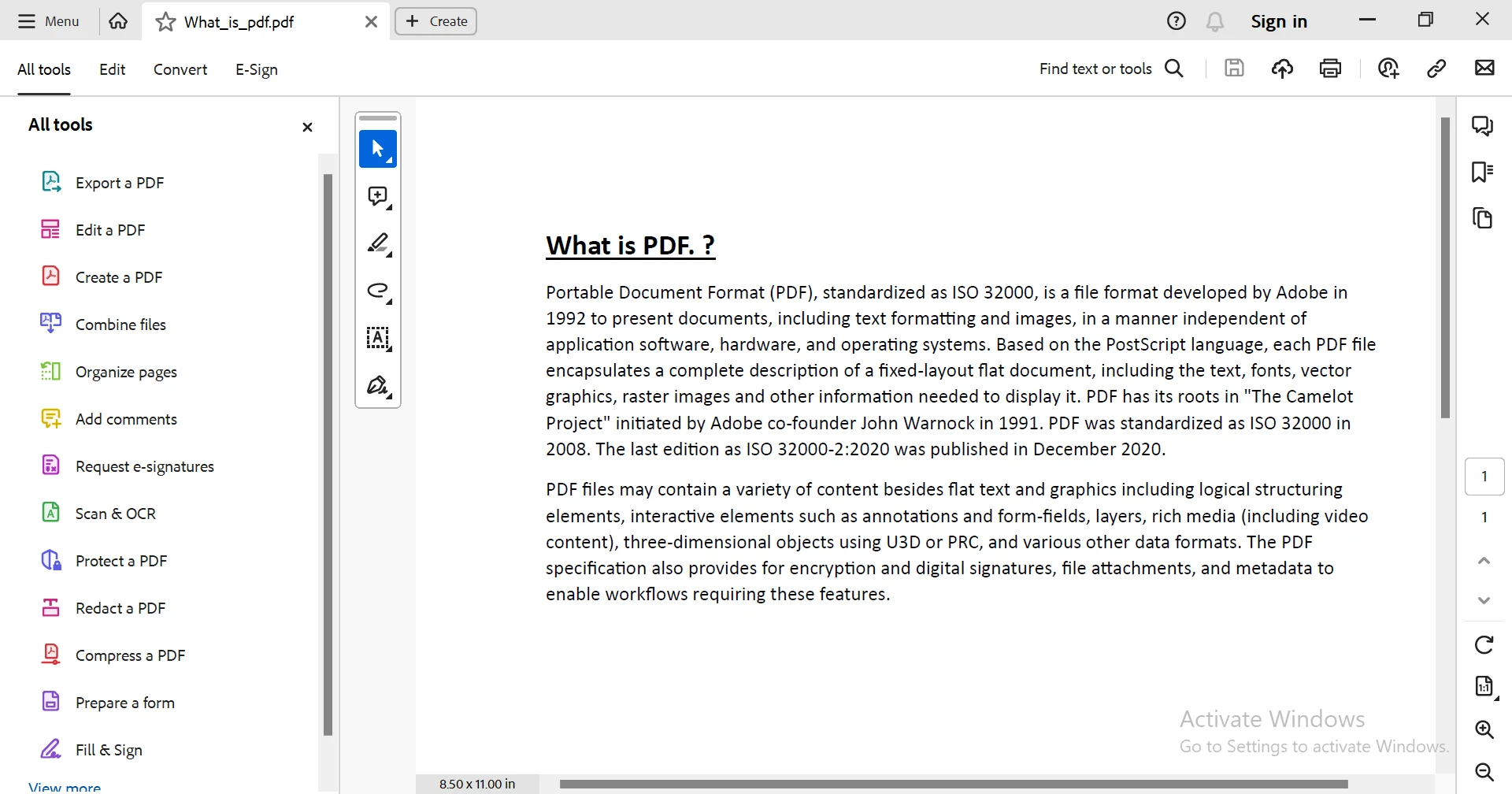
Wyjaśnienie:
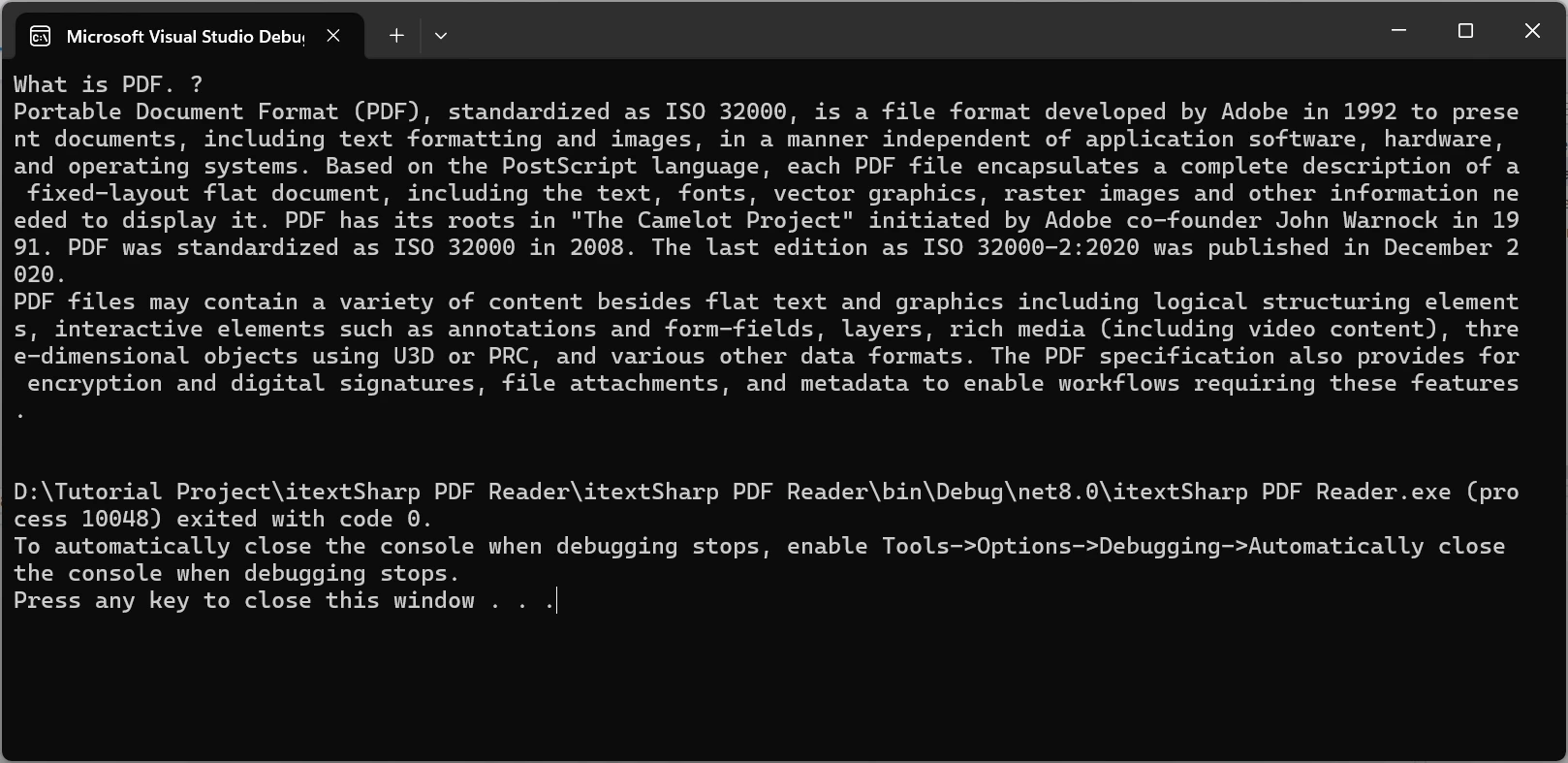
IronPDF upraszcza wyodrębnianie tekstu z plików PDF dzięki zaawansowanemu interfejsowi API, eliminując potrzebę wykonywania operacji niskopoziomowych. Wystarczy kilka linii kodu, aby IronPDF mógł skutecznie wyodrębnić cały tekst z dokumentu PDF, w przeciwieństwie do bibliotek takich jak iText 7, które często wymagają ręcznego przeglądania stron i skomplikowanej obsługi.
W przykładzie klasa PdfDocument ładuje plik PDF, a metoda ExtractAllText() szybko wyodrębnia cały tekst, usprawniając proces. Jest to duża zaleta w porównaniu z iText 7, gdzie trzeba by ręcznie obsługiwać poszczególne strony i elementy tekstowe.
Rozszerzenie funkcji IronPDF o inne zadania:
Opierając się na podstawowym przykładzie wyodrębniania tekstu, zaawansowany interfejs API IronPDF upraszcza inne typowe zadania związane z plikami PDF, zachowując jednocześnie łatwość obsługi i wydajność:
Pobieranie tekstu z określonych stron: Jeśli chcesz pobrać tekst z określonej strony lub zakresu, IronPDF pozwala to łatwo zrobić. Na przykład, aby wyodrębnić tekst z pierwszej strony:
var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);var pdf = new PdfDocument("sample.pdf");
// Access text from the first page
string pageText = pdf.Pages[0].Text;
Console.WriteLine(pageText);Dim pdf = New PdfDocument("sample.pdf")
' Access text from the first page
Dim pageText As String = pdf.Pages(0).Text
Console.WriteLine(pageText)Manipulacja plikami PDF: Po wyodrębnieniu tekstu lub danych z wielu plików PDF możesz chcieć połączyć je w jeden dokument. IronPDF ułatwia łączenie wielu plików PDF:
var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");var pdf1 = new PdfDocument("file1.pdf");
var pdf2 = new PdfDocument("file2.pdf");
// Merge the PDFs into a single document
var combinedPdf = PdfDocument.Merge(pdf1, pdf2);
combinedPdf.SaveAs("combined_output.pdf");Dim pdf1 = New PdfDocument("file1.pdf")
Dim pdf2 = New PdfDocument("file2.pdf")
' Merge the PDFs into a single document
Dim combinedPdf = PdfDocument.Merge(pdf1, pdf2)
combinedPdf.SaveAs("combined_output.pdf")Konwersja plików PDF do HTML: Jeśli chcesz przekonwertować plik PDF z powrotem do formatu HTML w celu dalszego wyodrębniania lub przetwarzania danych, IronPDF oferuje również tę funkcję:
var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();var pdf = new PdfDocument("sample.pdf");
// Convert the PDF to an HTML string
string htmlContent = pdf.ToHtmlString();Dim pdf = New PdfDocument("sample.pdf")
' Convert the PDF to an HTML string
Dim htmlContent As String = pdf.ToHtmlString()Dzięki IronPDF wyodrębnianie tekstu to dopiero początek. Proste, ale potężne API biblioteki obejmuje szeroki zakres zadań związanych z obróbką plików PDF, a wszystko to w formacie, który jest intuicyjny i łatwy do zintegrowania z Twoim przepływem pracy.
Odczytywanie plików PDF za pomocą iText 7
iText 7 wymaga pracy z czytnikami PDF, strumieniami i przetwarzaniem danych na poziomie bajtów. Wyodrębnianie tekstu nie jest proste, ponieważ wymaga iteracji przez strony PDF i ręcznej obsługi różnych struktur. W tym przykładzie kodu użyjemy tego samego dokumentu PDF, co w sekcji poświęconej IronPDF.
using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}using iText.Kernel.Pdf;
using iText.Kernel.Pdf.Canvas.Parser;
class Program
{
static void Main()
{
string pdfPath = "sample.pdf";
string extractedText = ExtractTextFromPdf(pdfPath);
Console.WriteLine(extractedText);
}
// Method to extract text from a PDF
static string ExtractTextFromPdf(string pdfPath)
{
// Use PdfReader to load the PDF
using (PdfReader reader = new PdfReader(pdfPath))
// Open the PDF document for processing
using (iText.Kernel.Pdf.PdfDocument pdfDoc = new iText.Kernel.Pdf.PdfDocument(reader))
{
string text = "";
// Iterate through each page and extract text
for (int i = 1; i <= pdfDoc.GetNumberOfPages(); i++)
{
text += PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) + Environment.NewLine;
}
return text;
}
}
}Imports iText.Kernel.Pdf
Imports iText.Kernel.Pdf.Canvas.Parser
Friend Class Program
Shared Sub Main()
Dim pdfPath As String = "sample.pdf"
Dim extractedText As String = ExtractTextFromPdf(pdfPath)
Console.WriteLine(extractedText)
End Sub
' Method to extract text from a PDF
Private Shared Function ExtractTextFromPdf(ByVal pdfPath As String) As String
' Use PdfReader to load the PDF
Using reader As New PdfReader(pdfPath)
' Open the PDF document for processing
Using pdfDoc As New iText.Kernel.Pdf.PdfDocument(reader)
Dim text As String = ""
' Iterate through each page and extract text
Dim i As Integer = 1
Do While i <= pdfDoc.GetNumberOfPages()
text &= PdfTextExtractor.GetTextFromPage(pdfDoc.GetPage(i)) & Environment.NewLine
i += 1
Loop
Return text
End Using
End Using
End Function
End ClassWynik
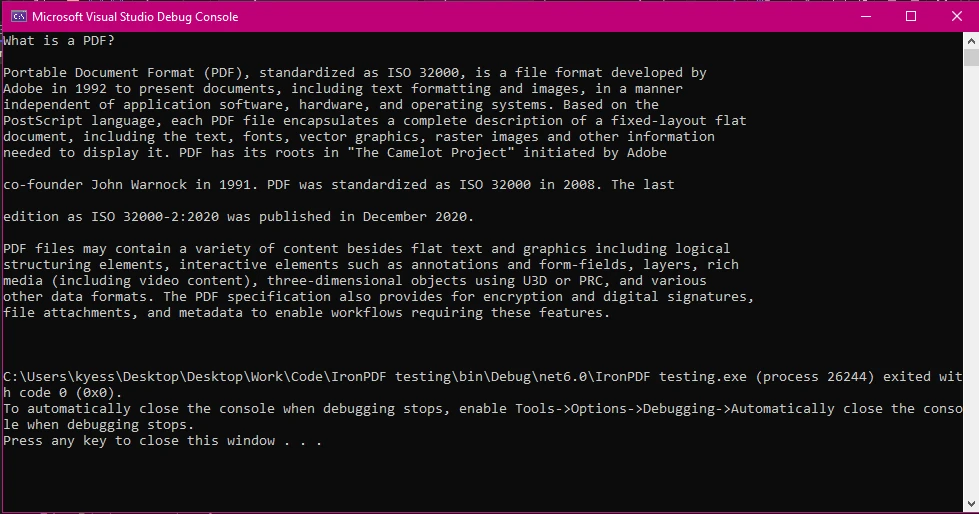
Wyjaśnienie:
PdfReaderładuje plik PDF do odczytu.- Obiekt
PdfDocumentumożliwia iterację po stronach. PdfTextExtractor.GetTextFromPage()pobiera tekst z każdej strony.- Ostateczny tekst jest zapisywany w ciągu znaków i wyświetlany.
Ta metoda działa, ale wymaga ręcznego powtarzania i może być uciążliwa w przypadku dokumentów o strukturze lub zeskanowanych plików PDF.
Porównanie iText 7 i IronPDF
Podczas gdy iText 7 wymaga szczegółowego kodowania do wykonywania operacji na plikach PDF, IronPDF usprawnia te zadania dzięki prostym metodom. Na przykład wyodrębnianie tekstu z pliku PDF za pomocą iText 7 wymaga wielu kroków i rozbudowanego kodu, podczas gdy IronPDF wykonuje to za pomocą zaledwie kilku wierszy. Ponadto obsługa konwersji HTML na PDF w IronPDF jest bardziej niezawodna i płynnie radzi sobie ze złożonymi kodami HTML, CSS i JavaScript.
Najważniejsze wnioski
- IronPDF upraszcza odczytywanie i edycję plików PDF dzięki bardziej intuicyjnemu i usprawnionemu interfejsowi API, wymagającemu mniejszego nakładu kodu do wykonywania typowych operacji.
- Wyodrębnianie tekstu w IronPDF jest łatwiejsze do wdrożenia w porównaniu z bardziej złożonym procesem iteracyjnym iTextSharp, co pozwala programistom zaoszczędzić czas.
- Licencja wieczysta IronPDF jest bardziej przyjazna dla biznesu, oferując mniej ograniczeń w porównaniu z licencją AGPL iTextSharp.
- IronPDF posiada lepszą dokumentację, która jest bardziej przystępna i ułatwia szybkie rozwiązywanie problemów, co czyni go idealnym rozwiązaniem dla programistów poszukujących szybkich rozwiązań bez konieczności przeglądania nadmiernej ilości zasobów.
Optymalizacja przepływu pracy dzięki IronPDF
IronPDF oferuje Suite zaawansowanych funkcji, które wykraczają poza zwykłe czytanie plików PDF. Cechy te sprawiają, że jest to solidne rozwiązanie dla programistów pragnących zoptymalizować swoje procesy pracy z plikami PDF. Oto, w jaki sposób IronPDF może usprawnić proces tworzenia oprogramowania:
1. Wyodrębnianie tekstu z plików PDF
IronPDF umożliwia łatwe wyodrębnianie tekstu z plików PDF, dzięki czemu idealnie nadaje się do procesów obejmujących analizę dokumentów, ekstrakcję danych lub indeksowanie treści. Dzięki IronPDF możesz szybko pobierać tekst z plików PDF i wykorzystywać go w swoich aplikacjach bez konieczności zajmowania się skomplikowanym parsowaniem.
2. Tworzenie plików PDF
IronPDF ułatwia tworzenie plików PDF od podstaw, niezależnie od tego, czy tworzysz raporty, faktury czy inne rodzaje dokumentów. Narzędzie obsługuje również konwersję HTML do PDF, co pozwala wykorzystać istniejące treści internetowe i generować dobrze sformatowane pliki PDF. Rozwiązanie to idealnie sprawdza się w sytuacjach, gdy konieczne jest przekształcenie stron internetowych lub dynamicznej zawartości HTML w pliki PDF do pobrania.
3. Zaawansowane funkcje plików PDF
Oprócz podstawowego wyodrębniania tekstu i tworzenia plików PDF, IronPDF obsługuje zaawansowane funkcje, takie jak wypełnianie formularzy PDF, dodawanie adnotacji i manipulowanie treścią dokumentów. Funkcje te są przydatne w branżach takich jak prawo, finanse czy edukacja, gdzie formularze i opinie są stałym elementem przepływu pracy.
4. Przetwarzanie wsadowe
IronPDF doskonale nadaje się do przetwarzania dużej liczby plików PDF. Niezależnie od tego, czy wyodrębniasz informacje z setek dokumentów, czy konwertujesz wiele plików HTML do formatu PDF, IronPDF może zautomatyzować te zadania i wykonać je wydajnie, oszczędzając zarówno czas, jak i wysiłek.
5. Automatyzacja i wydajność
IronPDF upraszcza zadania związane z obsługą plików PDF, które często są czasochłonne i powtarzalne. Dzięki automatyzacji zadań, takich jak wyodrębnianie tekstu z plików PDF, wypełnianie formularzy lub konwersja zbiorcza, programiści mogą skupić się na bardziej złożonych aspektach swoich projektów, pozostawiając IronPDF wykonanie najtrudniejszych zadań.
Wsparcie techniczne i zasoby społeczności
Aby zapewnić programistom możliwość maksymalnego wykorzystania możliwości IronPDF, narzędzie jest wspierane przez solidną pomoc techniczną i zasoby społeczności:
- Pomoc techniczna: IronPDF oferuje bezpośrednie wsparcie poprzez e-mail i system zgłoszeń, zapewniając pomoc w przypadku wszelkich wyzwań związanych z wdrożeniem lub kwestiami technicznymi.
- Zasoby społeczności: Witryna IronPDF zawiera obszerną dokumentację, samouczki i wpisy na blogu. Programiści mogą również znaleźć rozwiązania i dzielić się wiedzą za pośrednictwem serwisów GitHub i Stack Overflow, gdzie społeczność aktywnie omawia najlepsze praktyki i porady dotyczące rozwiązywania problemów.
Wnioski
W tym artykule omówiliśmy możliwości IronPDF jako potężnej i przyjaznej dla użytkownika biblioteki do obsługi plików PDF dla programistów .NET. Porównaliśmy go z iText 7, podkreślając, w jaki sposób IronPDF upraszcza złożone zadania, takie jak wyodrębnianie tekstu i manipulowanie plikami PDF. Przejrzysty interfejs API i zaawansowane funkcje IronPDF, w tym edycja, dodawanie znaków wodnych i podpisów cyfrowych, sprawiają, że jest to doskonałe rozwiązanie dla nowoczesnych procesów pracy z plikami PDF.
W przeciwieństwie do iText 7, który wymaga skomplikowanego kodowania do typowych zadań związanych z plikami PDF, IronPDF pozwala na wykonywanie złożonych operacji przy minimalnym nakładzie kodu, oszczędzając programistom czas i wysiłek. Niezależnie od tego, czy pracujesz ze skanowanymi dokumentami, generujesz pliki PDF z HTML, czy dodajesz niestandardowe znaki wodne, IronPDF oferuje intuicyjny i wydajny sposób na obsługę wszystkich tych zadań.
Jeśli chcesz usprawnić przepływ pracy z plikami PDF i zwiększyć wydajność w projektach C#, IronPDF jest idealnym wyborem.
Zapraszamy do pobrania IronPDF i wypróbowania go samodzielnie. Dzięki dostępnej bezpłatnej wersji próbnej możesz na własnej skórze przekonać się, jak łatwo zintegrować IronPDF ze swoimi aplikacjami i już dziś zacząć korzystać z jego zaawansowanych funkcji.
Kliknij poniżej, aby rozpocząć bezpłatny okres próbny:
- Rozpocznij bezpłatny okres próbny z IronPDF
- Dowiedz się więcej o funkcjach i cenach IronPDF Nie czekaj – odkryj potencjał płynnej obsługi plików PDF dzięki IronPDF!
Często Zadawane Pytania
Jakie są zalety korzystania z IronPDF zamiast iText 7 do obsługi plików PDF w języku C#?
IronPDF oferuje bardziej intuicyjny interfejs API, obsługuje konwersję HTML do PDF oraz upraszcza zadania, takie jak wyodrębnianie tekstu, scalanie i dzielenie plików PDF. Wymaga mniejszego nakładu kodu niż iText 7 i oferuje przyjazny dla biznesu model licencji wieczystej.
Jak przekonwertować stronę internetową do formatu PDF w języku C#?
Możesz użyć metody RenderUrlAsPdf biblioteki IronPDF, aby przekonwertować stronę internetową bezpośrednio na dokument PDF. Upraszcza to proces, ponieważ konwersja z HTML do PDF odbywa się wewnętrznie.
Czy IronPDF nadaje się do automatyzacji zadań związanych z przetwarzaniem dużych plików PDF?
Tak, IronPDF doskonale nadaje się do automatyzacji i przetwarzania wsadowego, dzięki czemu idealnie sprawdza się w wydajnej obsłudze dużych ilości plików PDF w projektach C#.
Czy za pomocą IronPDF mogę wyodrębnić tekst z określonego zakresu stron w pliku PDF?
IronPDF zapewnia funkcję wyodrębniania tekstu z określonych stron lub zakresów stron, umożliwiając precyzyjną obsługę treści plików PDF.
Jakie zasoby wsparcia oferuje IronPDF dla programistów?
IronPDF oferuje obszerną dokumentację, samouczki oraz aktywną społeczność. Ponadto dostępna jest bezpośrednia pomoc techniczna za pośrednictwem poczty elektronicznej oraz system zgłoszeń, aby wspierać programistów.
W jaki sposób IronPDF radzi sobie z integracją z projektem C#?
IronPDF można łatwo zintegrować z projektem C#, instalując go za pomocą menedżera pakietów NuGet w Visual Studio przy użyciu polecenia „Install-Package IronPdf”.
Jakie są opcje licencyjne dla IronPDF?
IronPDF oferuje model licencji wieczystej, który jest przyjazny dla biznesu i pozwala uniknąć wymagań dotyczących dystrybucji open source związanych z licencją AGPL iText 7.
W jaki sposób IronPDF zwiększa wydajność programistów w projektach C#?
IronPDF upraszcza złożone zadania związane z plikami PDF dzięki przyjaznemu dla użytkownika interfejsowi API, zmniejszając ilość potrzebnego kodu i przyspieszając procesy programistyczne, co zwiększa wydajność w projektach C#.
Czy IronPDF obsługuje konwersję plików PDF do formatu HTML?
Tak, IronPDF oferuje funkcję konwersji plików PDF na ciągi znaków HTML, ułatwiając wyświetlanie i edycję treści PDF w aplikacjach internetowych.
Jakie są kluczowe funkcje IronPDF do edycji plików PDF?
IronPDF obsługuje szeroki zakres funkcji, w tym tworzenie plików PDF, wyodrębnianie tekstu, konwersję HTML do PDF, scalanie, dzielenie, dodawanie znaków wodnych i podpisów cyfrowych, a wszystko to za pomocą łatwego w użyciu interfejsu API.













