
C# String Contains (Jak to działa dla deweloperów)
W dzisiejszym świecie programowania praca z PDF-ami jest powszechnym wymaganiem dla aplikacji, które muszą obsługiwać dokumenty, formularze lub raporty. Niezależnie od tego, czy tworzysz platformę e-commerce, system zarządzania dokumentami czy tylko musisz przetwarzać faktury, wyodrębnianie i wyszukiwanie tekstu z PDF-ów może być kluczowe. Ten artykuł przeprowadzi Cię przez sposób użycia C# string.Contains() z IronPDF, aby wyszukiwać i wyodrębniać tekst z plików PDF w Twoich projektach .NET.
Porównywanie łańcuchów znaków i określone podłańcuchy
Podczas wykonywania wyszukiwań, możesz potrzebować porównań łańcuchów znaków na podstawie określonych wymagań dotyczących podłańcuchów znaków. W takich przypadkach C# oferuje opcje takie jak string.Contains(), które jest jedną z najprostszych form porównywania.
Jeśli potrzebujesz określić, czy chcesz zignorować wielkość liter, możesz użyć enumeracji StringComparison. Pozwala to wybrać rodzaj porównania łańcuchów znaków, na przykład porównanie porządkowe lub porównanie bez uwzględniania wielkości liter.
Jeśli chcesz pracować z określonymi pozycjami w łańcuchu znaków, takimi jak pierwsza lub ostatnia pozycja znaku, zawsze możesz użyć Substring, aby wyizolować określone fragmenty łańcucha do dalszego przetwarzania.
Jeśli szukasz pustych łańcuchów znaków lub innych przypadków brzegowych, upewnij się, że obsługujesz te scenariusze w swojej logice.
Jeśli masz do czynienia z dużymi dokumentami, warto zoptymalizować początkową pozycję wyodrębniania tekstu, aby wyodrębniać tylko odpowiednie fragmenty, a nie cały dokument. To może być szczególnie przydatne, jeśli próbujesz uniknąć przeciążenia pamięci i czasu przetwarzania.
Jeśli nie masz pewności co do najlepszej metody reguł porównania, rozważ, jak określona metoda działa i jak chcesz, aby twoje wyszukiwanie zachowywało się w różnych scenariuszach (np. dopasowywanie wielu terminów, obsługa spacji itp.).
Jeśli twoje potrzeby wykraczają poza proste sprawdzenie podłańcuchów znaków i wymagają bardziej zaawansowanego dopasowania wzorców, rozważ użycie wyrażeń regularnych, które zapewniają znaczną elastyczność przy pracy z PDF-ami.
Jeśli jeszcze tego nie zrobiono, wypróbuj darmową wersję próbną IronPDF już dziś, aby zbadać jego możliwości i zobaczyć, jak może usprawnić Twoje zadania związane z PDF. Niezależnie od tego, czy tworzysz system zarządzania dokumentami, przetwarzasz faktury, czy po prostu potrzebujesz wyodrębnić dane z PDF-ów, IronPDF jest idealnym narzędziem do tej pracy.
Czym jest IronPDF i dlaczego warto go używać?
IronPDF to potężna biblioteka zaprojektowana, aby pomóc deweloperom pracującym z PDF-ami w ekosystemie .NET. Pozwala tworzyć, czytać, edytować i manipulować plikami PDF z łatwością, bez konieczności polegania na zewnętrznych narzędziach ani skomplikowanych konfiguracjach.
Przegląd IronPDF
IronPDF oferuje szeroki zakres funkcji do pracy z PDF-ami w aplikacjach C#. Niektóre kluczowe funkcje obejmują:
- Wyodrębnianie tekstu: Wyodrębnianie zwykłego tekstu lub danych strukturalnych z PDF-ów.
- Edycja PDF: Modyfikacja istniejących PDF-ów poprzez dodawanie, usuwanie lub edytowanie tekstu, obrazów i stron.
- Konwersja PDF: Konwersja stron HTML lub ASPX do PDF lub w odwrotnym kierunku.
- Obsługa formularzy: Wyodrębnianie lub wypełnianie pól formularzy w interaktywnych formularzach PDF.
IronPDF jest zaprojektowany tak, aby był prosty w użyciu, ale także elastyczny, aby obsługiwać złożone scenariusze związane z PDF-ami. Działa bezproblemowo z .NET Core i .NET Framework, co czyni go idealnym rozwiązaniem dla każdego projektu opartego na .NET.
Instalacja IronPDF
Aby użyć IronPDF, zainstaluj go za pomocą Menedżera pakietów NuGet w Visual Studio:
Install-Package IronPdf
How to Search Text in PDF Files Using C#
Zanim przejdziemy do wyszukiwania w PDF-ach, najpierw zrozummy, jak wyodrębnić tekst z PDF za pomocą IronPDF.
Podstawowe wyodrębnianie tekstu z PDF za pomocą IronPDF
IronPDF oferuje prosty interfejs API do wyodrębniania tekstu z dokumentów PDF. Pozwala to łatwo wyszukiwać określone treści w PDF-ach.
Poniższy przykład pokazuje, jak wyodrębnić tekst z PDF za pomocą IronPDF:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Optionally, print the extracted text to the console
Console.WriteLine(text)
End Sub
End ClassW tym przykładzie, metoda ExtractAllText() wyodrębnia cały tekst z dokumentu PDF. Ten tekst można następnie przetwarzać w celu wyszukiwania określonych słów kluczowych lub fraz.
Używanie string.Contains() do wyszukiwania tekstu
Gdy już wyodrębniesz tekst z PDF, możesz użyć wbudowanej metody string.Contains() w C#, aby wyszukiwać określone słowa lub frazy.
Metoda string.Contains() zwraca wartość logiczną, wskazującą, czy określony łańcuch znaków istnieje w obrębie innego łańcucha znaków. Jest to szczególnie przydatne przy podstawowym wyszukiwaniu tekstu.
Oto, jak można użyć string.Contains() do wyszukiwania słowa kluczowego w wyodrębnionym tekście:
bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)Praktyczny przykład: Jak sprawdzić, czy łańcuch C# zawiera słowa kluczowe w dokumencie PDF
Rozbijmy to dalej na praktyczny przykład. Załóżmy, że chcesz sprawdzić, czy w dokumencie faktury PDF istnieje określony numer faktury.
Oto pełny przykład, jak można to zaimplementować:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
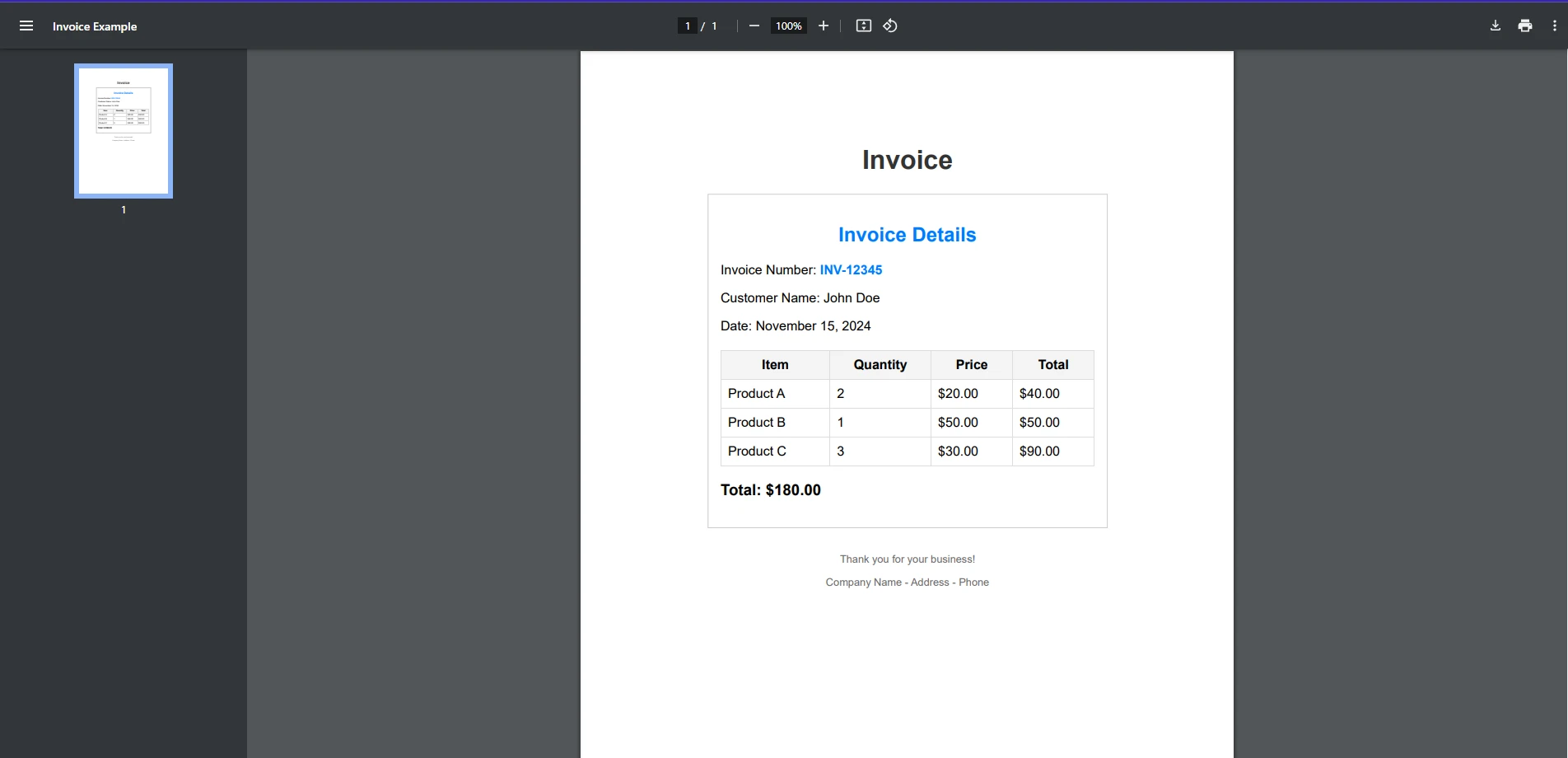
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
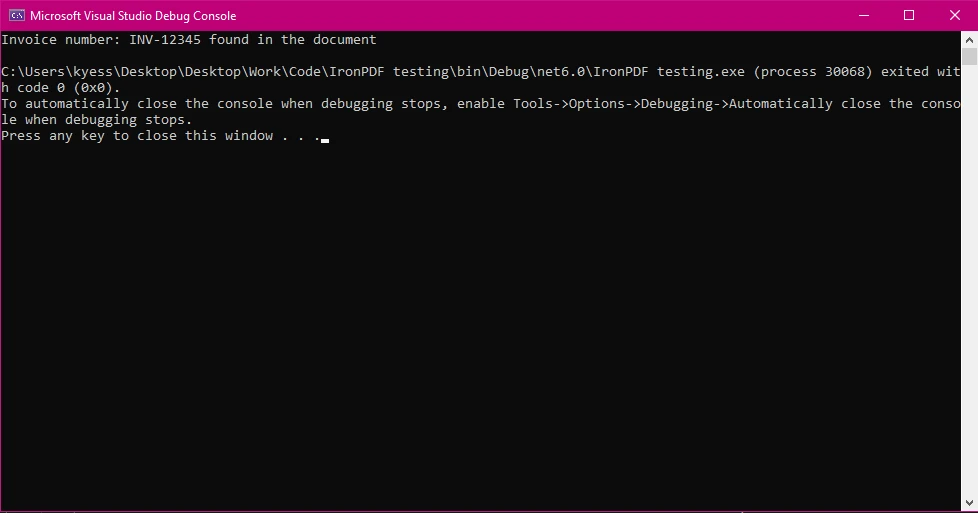
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for the specific invoice number
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
' Provide output based on whether the search term was found
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End ClassWejście PDF
Wynik konsoli
W tym przykładzie:
- Ładujemy plik PDF i wyodrębniamy jego tekst.
- Następnie używamy
string.Contains()do wyszukania numeru fakturyINV-12345w wyodrębnionym tekście. - Wyszukiwanie jest niewrażliwe na wielkość liter dzięki
StringComparison.OrdinalIgnoreCase.
Udoskonalanie wyszukiwania za pomocą wyrażeń regularnych
Chociaż string.Contains() działa w przypadku prostych wyszukiwań podłańcuchów znaków, możesz chcieć wykonywać bardziej złożone wyszukiwania, takie jak szukanie wzorca lub serii słów kluczowych. Do tego można użyć wyrażeń regularnych.
Oto przykład użycia wyrażenia regularnego do wyszukiwania w formacie teksu PDF dowolnych prawidłowych numerów faktur:
using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
' Check if a match was found
If match.Success Then
Console.WriteLine($"Invoice number found: {match.Value}")
Else
Console.WriteLine("No matching invoice number found.")
End If
End Sub
End ClassTen kod będzie wyszukiwał numery faktur zgodne ze wzorcem INV-XXXXX, gdzie XXXXX to seria cyfr.
Najlepsze praktyki przy pracy z PDF w .NET
Przy pracy z PDF-ami, szczególnie dużymi lub złożonymi dokumentami, warto zapamiętać kilka najlepszych praktyk:
Optymalizacja wyodrębniania tekstu
- Obsługa dużych PDF-ów: Jeśli masz do czynienia z dużymi PDF-ami, warto wyodrębniać tekst w mniejszych fragmentach (np. według stron), aby zmniejszyć zużycie pamięci i poprawić wydajność.
- Obsługa specjalnych kodowań: Należy zwracać uwagę na kodowania i znaki specjalne w PDF-ie. IronPDF zazwyczaj radzi sobie z tym dobrze, ale złożone układy lub czcionki mogą wymagać dodatkowego przetwarzania.
Integracja IronPDF z projektami .NET
IronPDF łatwo integruje się z projektami .NET. Po pobraniu i zainstalowaniu biblioteki IronPDF poprzez NuGet, po prostu zaimportuj ją do swojej bazy kodu C#, jak pokazano w powyższych przykładach.
Elastyczność IronPDF pozwala na budowanie zaawansowanych procesów przetwarzania dokumentów, takich jak:
- Wyszukiwanie i wyodrębnianie danych z formularzy.
- Konwersja HTML do PDF i wyodrębnianie treści.
- Tworzenie raportów na podstawie danych wprowadzonych przez użytkowników lub pobranych z baz danych.
Wnioski
IronPDF ułatwia i usprawnia pracę z PDF-ami, szczególnie gdy trzeba wyodrębnić i przeszukać teksty w PDF-ach. Łącząc metodę C# string.Contains() z możliwościami wyodrębniania tekstu IronPDF, można szybko przeszukiwać i przetwarzać PDF-y w aplikacjach .NET.
Jeśli jeszcze tego nie zrobiono, wypróbuj dzisiaj darmową wersję próbną IronPDF, aby zobaczyć jego możliwości i jak może usprawnić twoje zadania związane z obsługą PDF. Niezależnie od tego, czy tworzysz system zarządzania dokumentami, przetwarzasz faktury, czy po prostu potrzebujesz wyodrębnić dane z PDF-ów, IronPDF jest idealnym narzędziem do tej pracy.
Aby rozpocząć z IronPDF, pobierz darmową wersję próbną i doświadcz jego potężnych funkcji manipulacji PDF-ami w praktyce. Odwiedź witrynę IronPDF, aby rozpocząć już dziś.
Często Zadawane Pytania
Jak można użyć C# string.Contains() do przeszukiwania tekstu w plikach PDF?
Możesz użyć C# string.Contains() w połączeniu z IronPDF do przeszukiwania konkretnego tekstu wewnątrz plików PDF. Najpierw wyodrębnij tekst z PDF za pomocą funkcji wyodrębniania tekstu IronPDF, a następnie zastosuj string.Contains(), aby znaleźć pożądany tekst.
Jakie są korzyści z używania IronPDF do wyodrębniania tekstu z PDF w .NET?
IronPDF zapewnia łatwe w użyciu API do wyodrębniania tekstu z PDF, co jest istotne dla aplikacji, które muszą efektywnie obsługiwać dokumenty. Upraszcza to proces, pozwalając programistom skupić się na implementacji logiki biznesowej, zamiast zmagania się z zawiłą manipulacją PDF.
Jak zapewnić nieczułe na wielkość liter przeszukiwanie tekstu w PDF za pomocą C#?
Aby wykonać nieczułe na wielkość liter przeszukiwanie tekstu w PDF, użyj IronPDF do wyodrębnienia tekstu, a następnie zastosuj metodę C# string.Contains() z StringComparison.OrdinalIgnoreCase, aby zignorować wielkość liter podczas przeszukiwania.
Jakie scenariusze wymagają użycia regularnych wyrażeń zamiast string.Contains()?
Kiedy potrzebujesz przeszukiwać złożone wzorce lub wiele słów kluczowych w tekście wyodrębnionym z PDF, wyrażenia regularne są bardziej odpowiednie niż string.Contains(). Zapewniają zaawansowane możliwości dopasowywania wzorców, które nie są dostępne przy prostych wyszukiwaniach podciągów.
Jak zoptymalizować wydajność podczas wyodrębniania tekstu z dużych dokumentów PDF?
Aby zoptymalizować wydajność podczas wyodrębniania tekstu z dużych PDF, rozważ przetwarzanie dokumentu w mniejszych sekcjach, takich jak strona po stronie. Takie podejście zmniejsza zużycie pamięci i poprawia wydajność systemu, zapobiegając przeciążeniu zasobów.
Czy IronPDF jest kompatybilny zarówno z .NET Core, jak i .NET Framework?
Tak, IronPDF jest kompatybilny zarówno z .NET Core, jak i .NET Framework, co czyni go wszechstronnym dla różnych aplikacji .NET. Ta kompatybilność zapewnia, że można go zintegrować z różnymi typami projektów bez problemów kompatybilności.
Jak rozpocząć korzystanie z biblioteki PDF w projekcie .NET?
Aby zacząć korzystać z IronPDF w projekcie .NET, zainstaluj go za pomocą Menedżera Pakietów NuGet w Visual Studio. Po zainstalowaniu można go zaimportować do swojego zbioru kodu C# i wykorzystać jego funkcje, takie jak wyodrębnianie tekstu i manipulacja PDF, aby spełnić potrzeby w zakresie obsługi dokumentów.
Jakie są kluczowe funkcje IronPDF do edycji plików PDF?
IronPDF oferuje szereg funkcji do manipulacji PDF, w tym wyodrębnianie tekstu, edycję PDF oraz konwersję. Te funkcje pomagają programistom efektywnie obsługiwać PDF, usprawniając procesy takie jak obsługa formularzy i generowanie dokumentów w aplikacjach .NET.
Jak IronPDF może uprościć obsługę PDF w aplikacjach .NET?
IronPDF upraszcza obsługę PDF, oferując wszechstronne API, które pozwala programistom na łatwe tworzenie, edycję i wyciąganie danych z plików PDF. To eliminuje potrzebę skomplikowanych konfiguracji i umożliwia efektywne przepływy pracy związane z przetwarzaniem dokumentów w aplikacjach .NET.
Jak zainstalować IronPDF w projekcie .NET?
IronPDF można zainstalować w projekcie .NET za pomocą Menedżera Pakietów NuGet w Visual Studio. Użyj polecenia: Install-Package IronPdf aby dodać IronPDF do swojego projektu i zacząć korzystać z jego możliwości manipulacji PDF.














