
C# String Enthält (Wie es für Entwickler funktioniert)
In der heutigen Entwicklungswelt gehört die Arbeit mit PDFs zu den gängigen Anforderungen für Anwendungen, die mit Dokumenten, Formularen oder Berichten umgehen müssen. Egal, ob Sie eine E-Commerce-Plattform, ein Dokumentenverwaltungssystem aufbauen oder einfach nur Rechnungen bearbeiten müssen, das Extrahieren und Suchen von Texten aus PDFs kann entscheidend sein. Dieser Artikel wird Sie durch die Nutzung von C# string.Contains() mit IronPDF führen, um Text in PDF-Dateien in Ihren .NET-Projekten zu suchen und zu extrahieren.
Zeichenfolgenvergleich und angegebene Teilzeichenfolge
Bei der Durchführung von Suchen müssen Sie möglicherweise Zeichenfolgenvergleiche basierend auf speziellen Teilzeichenfolgenanforderungen durchführen. In solchen Fällen bietet C# Optionen wie string.Contains(), das eine der einfachsten Formen des Vergleichs ist.
Wenn Sie angeben müssen, ob Sie die Groß- und Kleinschreibung ignorieren möchten oder nicht, können Sie die StringComparison-Enumeration verwenden. Dies ermöglicht es Ihnen, die Art des Zeichenfolgenvergleichs auszuwählen – wie etwa eine ordinale oder eine groß-/kleinschreibungsunabhängige Vergleichsweise.
Wenn Sie mit bestimmten Positionen in der Zeichenfolge arbeiten möchten, wie der ersten oder der letzten Zeichenposition, können Sie immer Substring verwenden, um bestimmte Teile der Zeichenfolge für die weitere Verarbeitung zu isolieren.
Wenn Sie nach leeren Zeichenfolgenüberprüfungen oder anderen Sonderfällen suchen, stellen Sie sicher, diese Szenarien innerhalb Ihrer Logik zu behandeln.
Wenn Sie mit großen Dokumenten arbeiten, ist es nützlich, die Startposition Ihrer Textextraktion zu optimieren, um nur relevante Teile anstelle des gesamten Dokuments zu extrahieren. Dies kann besonders nützlich sein, wenn Sie eine Überlastung von Speicher und Bearbeitungszeit vermeiden möchten.
Wenn Sie sich nicht sicher über den besten Ansatz für Vergleichsregeln sind, bedenken Sie, wie die Methode ausgeführt wird und wie Sie möchten, dass Ihre Suche in unterschiedlichen Szenarien funktioniert (z.B. mehrere Begriffe abgleichen, Leerzeichen berücksichtigen, etc.).
Wenn Ihre Anforderungen über einfache Teilzeichenfolgenüberprüfungen hinausgehen und erweiterte Mustererkennung erfordern, überlegen Sie den Einsatz von regulären Ausdrücken, die erhebliche Flexibilität beim Arbeiten mit PDFs bieten.
Wenn Sie dies noch nicht getan haben, probieren Sie noch heute die kostenlose Testversion von IronPDF aus, um deren Fähigkeiten zu erkunden und zu sehen, wie es Ihre Aufgaben bei der PDF-Verarbeitung optimieren kann. Ob Sie eine Dokumentenverwaltungssystem aufbauen, Rechnungen verarbeiten oder einfach nur Daten aus PDFs extrahieren müssen, IronPDF ist das perfekte Werkzeug für diese Aufgabe.
Was ist IronPDF und warum sollten Sie es verwenden?
IronPDF ist eine leistungsstarke Bibliothek, die entwickelt wurde, um Entwicklern im .NET-Ökosystem bei der Arbeit mit PDFs zu helfen. Es ermöglicht Ihnen das Erstellen, Lesen, Bearbeiten und Manipulieren von PDF-Dateien einfach, ohne dass Sie auf externe Tools oder komplexe Konfigurationen angewiesen sind.
IronPDF Überblick
IronPDF bietet ein breites Spektrum an Funktionen für die Arbeit mit PDFs in C#-Anwendungen. Einige wichtige Funktionen umfassen:
- Textextraktion: Extrahieren von Klartext oder strukturierten Daten aus PDFs.
- PDF-Bearbeitung: Vorhandene PDFs können durch Hinzufügen, Löschen oder Bearbeiten von Text, Bildern und Seiten verändert werden.
- PDF-Konvertierung: HTML- oder ASPX-Seiten in PDF konvertieren oder umgekehrt.
- Formularverarbeitung: Formularfelder in interaktiven PDF-Formularen extrahieren oder ausfüllen.
IronPDF ist darauf ausgelegt, einfach zu bedienen, aber auch flexibel genug zu sein, um komplexe Szenarien mit PDFs zu bewältigen. Es funktioniert nahtlos mit .NET Core und .NET Framework, was es zu einer perfekten Ergänzung für jedes .NET-basierte Projekt macht.
Installation von IronPDF
Um IronPDF zu verwenden, installieren Sie es über den NuGet-Paket-Manager in Visual Studio:
Install-Package IronPdf
So suchen Sie Text in PDF-Dateien mit C
Bevor wir in das Suchen von PDFs eintauchen, lassen Sie uns zuerst verstehen, wie man mit IronPDF Text aus einem PDF extrahiert.
Grundlegende PDF-Textextraktion mit IronPDF
IronPDF bietet eine einfache API, um Text aus PDF-Dokumenten zu extrahieren. Dies ermöglicht es Ihnen, leicht nach bestimmten Inhalten in PDFs zu suchen.
Das folgende Beispiel zeigt, wie man mit IronPDF Text aus einem PDF extrahiert:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Optionally, print the extracted text to the console
Console.WriteLine(text)
End Sub
End ClassIn diesem Beispiel extrahiert die Methode ExtractAllText() den gesamten Text aus dem PDF-Dokument. Dieser Text kann dann verarbeitet werden, um nach bestimmten Schlagwörtern oder Phrasen zu suchen.
Verwendung von string.Contains() für die Textsuche
Sobald Sie den Text aus dem PDF extrahiert haben, können Sie die eingebaute Methode string.Contains() von C# verwenden, um nach bestimmten Wörtern oder Phrasen zu suchen.
Die Methode string.Contains() gibt einen booleschen Wert zurück, der angibt, ob eine bestimmte Zeichenkette innerhalb einer anderen Zeichenkette existiert. Dies ist besonders nützlich für einfache Textsuche.
Hier ist, wie Sie string.Contains() verwenden können, um nach einem Schlagwort in dem extrahierten Text zu suchen:
bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)Praktisches Beispiel: Prüfen, ob eine C#-Zeichenkette Schlüsselwörter in einem PDF-Dokument enthält
Lassen Sie uns dies mit einem praktischen Beispiel weiter aufschlüsseln. Angenommen, Sie möchten überprüfen, ob eine bestimmte Rechnungsnummer in einem PDF-Rechnungsdokument existiert.
Hier ein vollständiges Beispiel, wie Sie dies implementieren könnten:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
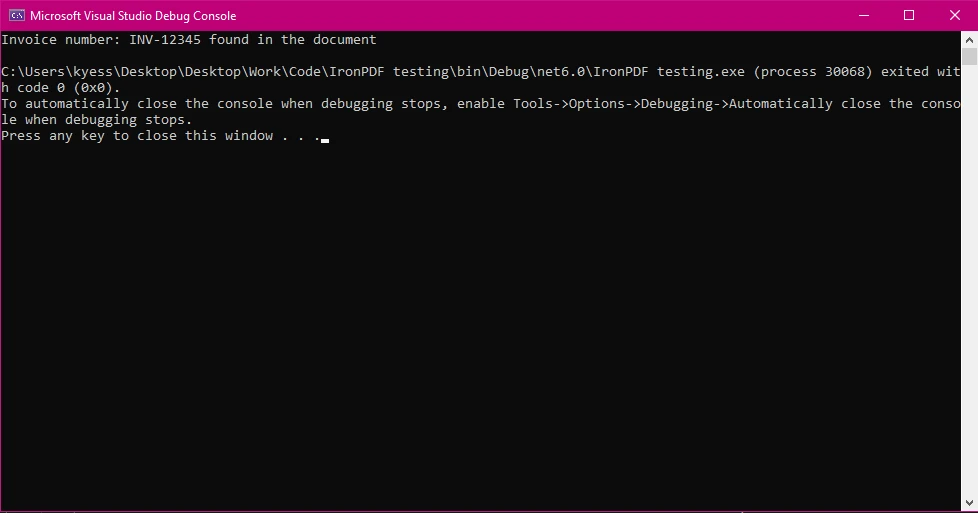
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for the specific invoice number
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
' Provide output based on whether the search term was found
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End ClassEingabe-PDF
Konsolenausgabe
In diesem Beispiel:
- Wir laden die PDF-Datei und extrahieren den Text.
- Anschließend verwenden wir
string.Contains(), um im extrahierten Text nach der RechnungsnummerINV-12345zu suchen. - Die Suche unterscheidet nicht zwischen Groß- und Kleinschreibung aufgrund von
StringComparison.OrdinalIgnoreCase.
Verbesserung der Suche mit regulären Ausdrücken
Während string.Contains() für einfache Teilstringsuchen funktioniert, möchten Sie vielleicht komplexere Suchen durchführen, z. B. nach einem Muster oder einer Reihe von Schlüsselwörtern. Hierfür können Sie reguläre Ausdrücke nutzen.
Hier ist ein Beispiel, das einen regulären Ausdruck verwendet, um nach einem beliebigen Format für Rechnungsnummern im PDF-Text zu suchen:
using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
' Check if a match was found
If match.Success Then
Console.WriteLine($"Invoice number found: {match.Value}")
Else
Console.WriteLine("No matching invoice number found.")
End If
End Sub
End ClassDieser Code sucht nach Rechnungsnummern, die dem Muster INV-XXXXX entsprechen, wobei XXXXX eine Reihe von Ziffern ist.
Best Practices für die Arbeit mit PDFs in .NET
Bei der Arbeit mit PDFs, insbesondere großen oder komplexen Dokumenten, gibt es einige bewährte Methoden, die Sie berücksichtigen sollten:
Optimierung der Textextraktion
- Umgang mit großen PDFs: Wenn Sie mit großen PDFs arbeiten, ist es ratsam, den Text in kleineren Abschnitten (seitenweise) zu extrahieren, um den Speicherverbrauch zu reduzieren und die Leistung zu verbessern.
- Umgang mit Sonderzeichen: Achten Sie auf die Kodierungen und Sonderzeichen in der PDF-Datei. IronPDF handhabt dies im Allgemeinen gut, aber komplexe Layouts oder Schriftarten erfordern möglicherweise zusätzliche Handhabung.
Einbindung von IronPDF in .NET-Projekte
IronPDF lässt sich einfach in .NET-Projekte integrieren. Nach dem Herunterladen und Installieren der IronPDF-Bibliothek über NuGet importieren Sie diese einfach in Ihre C#-Codebasis, wie in den obigen Beispielen gezeigt.
Die Flexibilität von IronPDF ermöglicht es Ihnen, umfangreiche Dokumentenverarbeitungs-Workflows zu erstellen, wie z.B.:
- Suche und Extraktion von Daten aus Formularen.
- Konvertierung von HTML nach PDF und Extraktion von Inhalten.
- Erstellung von Berichten auf Grundlage von Benutzereingaben oder Datenbanken.
Abschluss
IronPDF macht die Arbeit mit PDFs einfach und effizient, insbesondere wenn Sie Text in PDFs extrahieren und durchsuchen müssen. Durch die Kombination der string.Contains()-Methode von C# mit den Textextraktionsfunktionen von IronPDF können Sie PDFs in Ihren .NET Anwendungen schnell durchsuchen und verarbeiten.
Wenn Sie dies noch nicht getan haben, probieren Sie noch heute die kostenlose Testversion von IronPDF aus, um deren Fähigkeiten zu erkunden und zu sehen, wie es Ihre Aufgaben bei der PDF-Verarbeitung optimieren kann. Ob Sie eine Dokumentenverwaltungssystem aufbauen, Rechnungen verarbeiten oder einfach nur Daten aus PDFs extrahieren müssen, IronPDF ist das perfekte Werkzeug für diese Aufgabe.
Um mit IronPDF zu beginnen, laden Sie die kostenlose Testversion herunter und erleben Sie seine leistungsstarken PDF-Manipulationsfunktionen aus erster Hand. Besuchen Sie die IronPDF-Website, um noch heute zu beginnen.
Häufig gestellte Fragen
Wie kann man C# string.Contains() verwenden, um Text in PDF-Dateien zu suchen?
Sie können C# string.Contains() zusammen mit IronPDF verwenden, um spezifische Texte in PDF-Dateien zu suchen. Extrahieren Sie zuerst den Text aus der PDF-Datei mit der Textextraktionsfunktion von IronPDF und wenden Sie dann string.Contains() an, um den gewünschten Text zu finden.
Welche Vorteile bietet die Verwendung von IronPDF für die PDF-Textextraktion in .NET?
IronPDF bietet eine benutzerfreundliche API zur Extraktion von Texten aus PDFs, die für Anwendungen unerlässlich ist, die Dokumente effizient verarbeiten müssen. Es vereinfacht den Prozess und ermöglicht es Entwicklern, sich auf die Implementierung der Geschäftslogik zu konzentrieren, anstatt sich mit komplexer PDF-Manipulation zu befassen.
Wie kann man case-insensitive Textsuchen in PDFs mit C# sicherstellen?
Um case-insensitive Textsuchen in PDFs durchzuführen, verwenden Sie IronPDF, um den Text zu extrahieren, und wenden Sie dann die C# string.Contains() Methode mit StringComparison.OrdinalIgnoreCase an, um die Groß-/Kleinschreibung während der Suche zu ignorieren.
Welche Szenarien erfordern die Verwendung von regulären Ausdrücken anstelle von string.Contains()?
Wenn Sie nach komplexen Mustern oder mehreren Stichwörtern innerhalb von Texten suchen müssen, die aus einem PDF extrahiert wurden, sind reguläre Ausdrücke besser geeignet als string.Contains(). Sie bieten erweiterte Musterabgleichsfunktionen, die mit einfachen Substringsuchen nicht verfügbar sind.
Wie kann man die Leistung optimieren, wenn man Text aus großen PDF-Dokumenten extrahiert?
Um die Leistung bei der Textextraktion aus großen PDFs zu optimieren, sollten Sie das Dokument in kleineren Abschnitten verarbeiten, z. B. seitenweise. Dieser Ansatz reduziert die Speichernutzung und verbessert die Systemleistung, indem er eine Ressourcenüberlastung verhindert.
Ist IronPDF mit sowohl .NET Core als auch .NET Framework kompatibel?
Ja, IronPDF ist sowohl mit .NET Core als auch mit .NET Framework kompatibel und somit vielseitig für verschiedene .NET-Anwendungen einsetzbar. Diese Kompatibilität stellt sicher, dass es in verschiedene Projekttypen ohne Kompatibilitätsprobleme integriert werden kann.
Wie beginnt man mit der Verwendung einer PDF-Bibliothek in einem .NET-Projekt?
Um IronPDF in einem .NET-Projekt zu verwenden, installieren Sie es über den NuGet Package Manager in Visual Studio. Sobald es installiert ist, können Sie es in Ihren C#-Code einbinden und seine Funktionen wie Textextraktion und PDF-Manipulation nutzen, um Ihre Anforderungen an die Dokumentenverarbeitung zu erfüllen.
Welche Hauptfunktionen bietet IronPDF für die PDF-Manipulation?
IronPDF bietet eine Reihe von Funktionen zur PDF-Manipulation, darunter Textextraktion, PDF-Bearbeitung und -Konvertierung. Diese Funktionen helfen Entwicklern, PDFs effektiv zu handhaben und Prozesse wie Formularbearbeitung und Dokumentenerstellung in .NET-Anwendungen zu optimieren.
Wie kann IronPDF die PDF-Verarbeitung in .NET-Anwendungen vereinfachen?
IronPDF vereinfacht die PDF-Verarbeitung, indem es eine umfassende API bereitstellt, die es Entwicklern ermöglicht, PDF-Dateien einfach zu erstellen, zu bearbeiten und Daten daraus zu extrahieren. Dies beseitigt die Notwendigkeit für komplexe Konfigurationen und ermöglicht effiziente Dokumentenverarbeitungs-Workflows innerhalb von .NET-Anwendungen.
Wie kann man IronPDF in einem .NET-Projekt installieren?
IronPDF kann in einem .NET-Projekt über den NuGet Package Manager in Visual Studio installiert werden. Verwenden Sie den Befehl: Install-Package IronPDF, um IronPDF zu Ihrem Projekt hinzuzufügen und mit der Nutzung seiner PDF-Manipulationsfähigkeiten zu beginnen.














