
String em C# contém (Como funciona para desenvolvedores)
No mundo do desenvolvimento atual, trabalhar com PDFs é um requisito comum para aplicativos que precisam lidar com documentos, formulários ou relatórios. Seja para criar uma plataforma de comércio eletrônico, um sistema de gerenciamento de documentos ou simplesmente para processar faturas, extrair e pesquisar texto em PDFs pode ser crucial. Este artigo irá orientá-lo sobre como usar o método string.Contains() do C# com o IronPDF para pesquisar e extrair texto de arquivos PDF em seus projetos .NET .
Comparação de strings e substring especificada
Ao realizar buscas, pode ser necessário comparar strings com base em requisitos específicos de substrings. Nesses casos, o C# oferece opções como string.Contains(), que é uma das formas mais simples de comparação.
Se precisar especificar se deseja ignorar ou não a diferenciação entre maiúsculas e minúsculas, você pode usar a enumeração StringComparison. Isso permite que você escolha o tipo de comparação de strings que deseja, como comparação ordinal ou comparação que ignora maiúsculas e minúsculas.
Se você deseja trabalhar com posições específicas na string, como a posição do primeiro ou do último caractere, você sempre pode usar a função Substring para isolar certas partes da string para processamento posterior.
Se você estiver procurando por verificações de strings vazias ou outros casos extremos, certifique-se de lidar com esses cenários em sua lógica.
Se você estiver lidando com documentos extensos, é útil otimizar o ponto de partida da extração de texto, extraindo apenas as partes relevantes em vez do documento inteiro. Isso pode ser particularmente útil se você estiver tentando evitar sobrecarregar a memória e o tempo de processamento.
Se você não tiver certeza sobre a melhor abordagem para as regras de comparação, considere o método específico que ele executa e como você deseja que sua pesquisa se comporte em diferentes cenários (por exemplo, correspondência de vários termos, tratamento de espaços, etc.).
Se suas necessidades forem além de simples verificações de substrings e exigirem correspondência de padrões mais avançada, considere o uso de expressões regulares, que oferecem flexibilidade significativa ao trabalhar com PDFs.
Se ainda não o fez, experimente hoje mesmo o teste gratuito do IronPDF para explorar as suas funcionalidades e ver como ele pode simplificar as suas tarefas de processamento de PDFs. Seja para criar um sistema de gerenciamento de documentos, processar faturas ou simplesmente extrair dados de PDFs, o IronPDF é a ferramenta perfeita para o trabalho.
O que é o IronPDF e por que você deveria usá-lo?
IronPDF é uma biblioteca poderosa projetada para ajudar desenvolvedores que trabalham com PDFs no ecossistema .NET . Ele permite criar, ler, editar e manipular arquivos PDF facilmente, sem precisar recorrer a ferramentas externas ou configurações complexas.
Visão geral do IronPDF
O IronPDF oferece uma ampla gama de recursos para trabalhar com PDFs em aplicativos C#. Algumas das principais características incluem:
- Extração de texto: Extrai texto simples ou dados estruturados de PDFs.
- Edição de PDF: Modifique PDFs existentes adicionando, excluindo ou editando texto, imagens e páginas.
- Conversão para PDF: Converta páginas HTML ou ASPX para PDF ou vice-versa.
- Manipulação de formulários: Extrair ou preencher campos de formulários em PDF interativos.
O IronPDF foi projetado para ser simples de usar, mas também flexível o suficiente para lidar com cenários complexos envolvendo PDFs. Ele funciona perfeitamente com o .NET Core e o .NET Framework, tornando-o ideal para qualquer projeto baseado em .NET.
Instalando o IronPDF
Para usar o IronPDF , instale-o através do Gerenciador de Pacotes NuGet no Visual Studio:
Install-Package IronPdf
How to Search Text in PDF Files Using C
Antes de mergulharmos na busca em PDFs, vamos primeiro entender como extrair texto de um PDF usando o IronPDF.
Extração básica de texto de PDF com IronPDF
O IronPDF fornece uma API simples para extrair texto de documentos PDF. Isso permite que você pesquise facilmente conteúdo específico dentro de PDFs.
O exemplo a seguir demonstra como extrair texto de um PDF usando o IronPDF:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Optionally, print the extracted text to the console
Console.WriteLine(text)
End Sub
End ClassNeste exemplo, o método ExtractAllText() extrai todo o texto do documento PDF. Esse texto pode então ser processado para buscar palavras-chave ou frases específicas.
Usando string.Contains() para pesquisa de texto
Depois de extrair o texto do PDF, você pode usar o método string.Contains() integrado do C# para procurar palavras ou frases específicas.
O método string.Contains() retorna um valor Booleano indicando se uma string especificada existe dentro de uma string. Isso é particularmente útil para buscas básicas de texto.
Veja como você pode usar string.Contains() para procurar uma palavra-chave no texto extraído:
bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)Exemplo Prático: Como Verificar se uma String C# Contém Palavras-chave em um Documento PDF
Vamos analisar isso mais detalhadamente com um exemplo prático. Suponha que você queira verificar se um determinado número de fatura existe em um documento de fatura em PDF.
Aqui está um exemplo completo de como você pode implementar isso:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
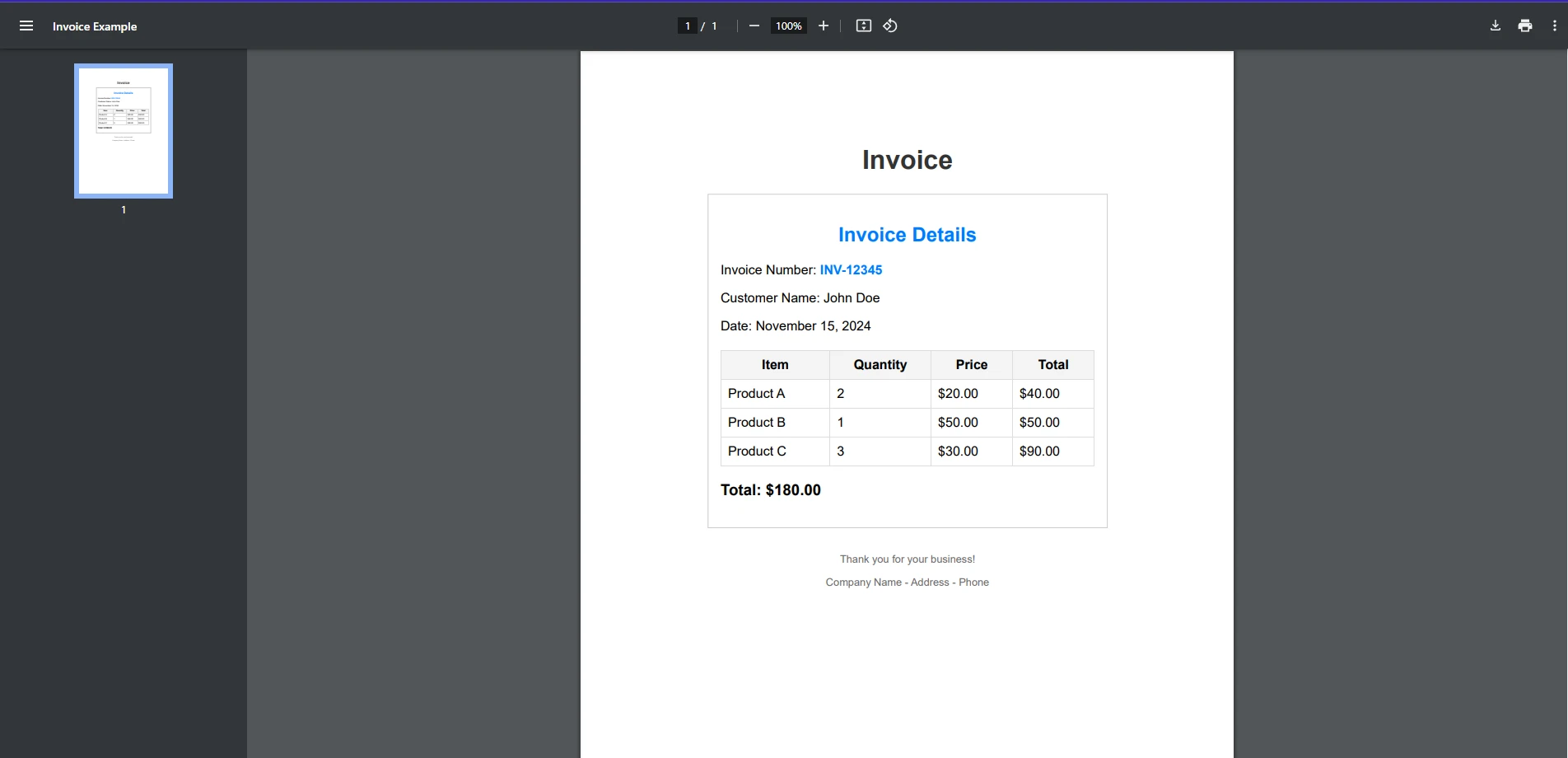
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
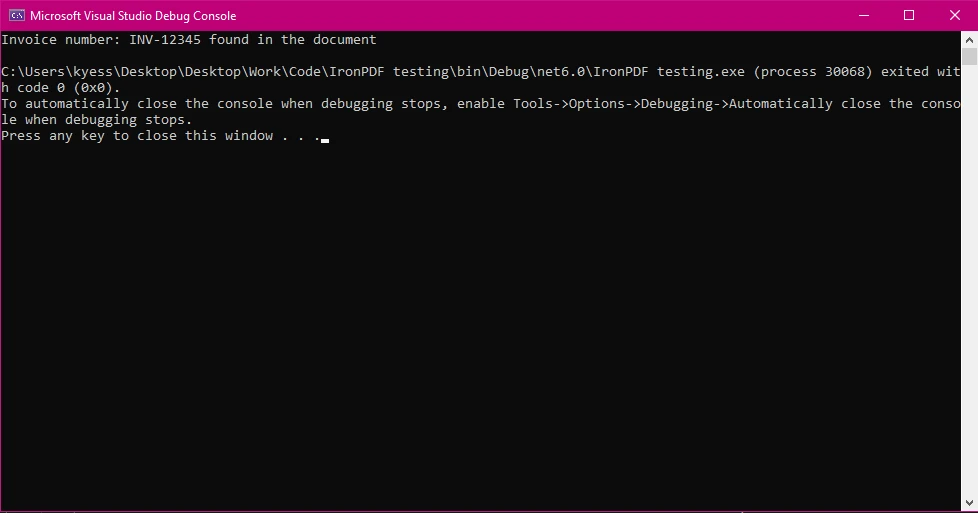
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for the specific invoice number
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
' Provide output based on whether the search term was found
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End ClassEntrada PDF
Saída do console
Neste exemplo:
- Carregamos o arquivo PDF e extraímos seu texto.
- Em seguida, usamos
string.Contains()para procurar o número da faturaINV-12345no texto extraído. - A busca não diferencia maiúsculas de minúsculas devido ao
StringComparison.OrdinalIgnoreCase.
Aprimorando a busca com expressões regulares
Enquanto string.Contains() funciona para buscas de substrings simples, você pode querer realizar buscas mais complexas, como encontrar um padrão ou uma série de palavras-chave. Para isso, você pode usar expressões regulares.
Aqui está um exemplo usando uma expressão regular para pesquisar qualquer formato de número de fatura válido no texto do PDF:
using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
' Check if a match was found
If match.Success Then
Console.WriteLine($"Invoice number found: {match.Value}")
Else
Console.WriteLine("No matching invoice number found.")
End If
End Sub
End ClassEste código irá procurar por quaisquer números de fatura que sigam o padrão INV-XXXXX, onde XXXXX é uma sequência de dígitos.
Melhores práticas para trabalhar com PDFs em .NET
Ao trabalhar com PDFs, especialmente documentos grandes ou complexos, existem algumas boas práticas a serem consideradas:
Otimizando a extração de texto
- Lidar com PDFs grandes: Se você estiver trabalhando com PDFs grandes, é uma boa ideia extrair o texto em partes menores (por página) para reduzir o uso de memória e melhorar o desempenho.
- Lidar com codificações especiais: esteja atento às codificações e aos caracteres especiais no PDF. O IronPDF geralmente lida bem com isso, mas layouts ou fontes complexos podem exigir ajustes adicionais.
Integrando o IronPDF em projetos .NET
O IronPDF integra-se facilmente com projetos .NET . Após baixar e instalar a biblioteca IronPDF via NuGet, basta importá-la para seu código C#, como mostrado nos exemplos acima.
A flexibilidade do IronPDF permite criar fluxos de trabalho sofisticados para processamento de documentos, tais como:
- Pesquisar e extrair dados de formulários.
- Converter HTML para PDF e extrair conteúdo.
- Criação de relatórios com base em informações inseridas pelo usuário ou em dados de bancos de dados.
Conclusão
O IronPDF facilita e torna mais eficiente o trabalho com PDFs, especialmente quando você precisa extrair e pesquisar texto em PDFs. Ao combinar o método string.Contains() de C# com as capacidades de extração de texto do IronPDF, você pode rapidamente buscar e processar PDFs em suas aplicações .NET.
Se ainda não o fez, experimente hoje mesmo o teste gratuito do IronPDF para explorar as suas funcionalidades e ver como ele pode simplificar as suas tarefas de processamento de PDFs. Seja para criar um sistema de gerenciamento de documentos, processar faturas ou simplesmente extrair dados de PDFs, o IronPDF é a ferramenta perfeita para o trabalho.
Para começar a usar o IronPDF, baixe a versão de avaliação gratuita e experimente em primeira mão seus poderosos recursos de manipulação de PDFs. Visite o site da IronPDF para começar hoje mesmo.
Perguntas frequentes
Como usar o método `string.Contains()` em C# para pesquisar texto em arquivos PDF?
Você pode usar o método `string.Contains()` do C# em conjunto com o IronPDF para buscar textos específicos em arquivos PDF. Primeiro, extraia o texto do PDF usando o recurso de extração de texto do IronPDF e, em seguida, aplique `string.Contains()` para encontrar o texto desejado.
Quais são os benefícios de usar o IronPDF para extração de texto de PDFs em .NET?
O IronPDF oferece uma API fácil de usar para extrair texto de PDFs, o que é essencial para aplicações que precisam lidar com documentos de forma eficiente. Ele simplifica o processo, permitindo que os desenvolvedores se concentrem na implementação da lógica de negócios em vez de lidar com a complexa manipulação de PDFs.
Como garantir que as buscas de texto em PDFs não diferenciem maiúsculas de minúsculas usando C#?
Para realizar buscas de texto em PDFs sem distinção entre maiúsculas e minúsculas, use o IronPDF para extrair o texto e, em seguida, aplique o método string.Contains() do C# com StringComparison.OrdinalIgnoreCase para ignorar a distinção entre maiúsculas e minúsculas durante a busca.
Em que cenários é necessário usar expressões regulares em vez de string.Contains()?
Quando você precisa pesquisar padrões complexos ou várias palavras-chave em um texto extraído de um PDF, as expressões regulares são mais adequadas do que string.Contains(). Elas oferecem recursos avançados de correspondência de padrões que não estão disponíveis com pesquisas simples de substrings.
Como otimizar o desempenho ao extrair texto de documentos PDF grandes?
Para otimizar o desempenho na extração de texto de PDFs grandes, considere processar o documento em seções menores, como página por página. Essa abordagem reduz o uso de memória e melhora o desempenho do sistema, evitando a sobrecarga de recursos.
O IronPDF é compatível tanto com o .NET Core quanto com o .NET Framework?
Sim, o IronPDF é compatível tanto com o .NET Core quanto com o .NET Framework, o que o torna versátil para diversas aplicações .NET. Essa compatibilidade garante que ele possa ser integrado a diferentes tipos de projetos sem problemas de compatibilidade.
Como começar a usar uma biblioteca PDF em um projeto .NET?
Para começar a usar o IronPDF em um projeto .NET, instale-o através do Gerenciador de Pacotes NuGet no Visual Studio. Após a instalação, você pode importá-lo para seu código C# e utilizar seus recursos, como extração de texto e manipulação de PDF, para atender às suas necessidades de gerenciamento de documentos.
Quais são as principais funcionalidades do IronPDF para manipulação de PDFs?
O IronPDF oferece uma gama de recursos para manipulação de PDFs, incluindo extração de texto, edição e conversão. Esses recursos ajudam os desenvolvedores a lidar com PDFs de forma eficaz, otimizando processos como o processamento de formulários e a geração de documentos em aplicativos .NET.
Como o IronPDF pode simplificar o processamento de PDFs em aplicações .NET?
O IronPDF simplifica o manuseio de PDFs ao fornecer uma API abrangente que permite aos desenvolvedores criar, editar e extrair dados de arquivos PDF com facilidade. Isso elimina a necessidade de configurações complexas e possibilita fluxos de trabalho eficientes de processamento de documentos em aplicativos .NET.
Como instalar o IronPDF em um projeto .NET?
O IronPDF pode ser instalado em um projeto .NET usando o Gerenciador de Pacotes NuGet no Visual Studio. Use o comando: Install-Package IronPDF para adicionar o IronPDF ao seu projeto e começar a utilizar seus recursos de manipulação de PDF.














