using IronPdf;
// Disable local disk access or cross-origin requests
Installation.EnableWebSecurity = true;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create a PDF from a HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");
// Advanced Example with HTML Assets
// Load external html assets: Images, CSS and JavaScript.
// An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
var myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
myAdvancedPdf.SaveAs("html-with-assets.pdf");
¿Cómo se puede usar C# string.Contains() para buscar texto en archivos PDF?
Puede usar C# string.Contains() junto con IronPDF para buscar texto específico dentro de archivos PDF. Primero, extraiga el texto del PDF usando la función de extracción de texto de IronPDF, y luego aplique string.Contains() para encontrar el texto deseado.
¿Cuáles son los beneficios de usar IronPDF para la extracción de texto de PDF en .NET?
IronPDF proporciona una API fácil de usar para extraer texto de PDFs, lo cual es esencial para aplicaciones que necesitan manejar documentos de manera eficiente. Simplifica el proceso, permitiendo a los desarrolladores centrarse en implementar la lógica de negocio en lugar de lidiar con la manipulación compleja de PDFs.
¿Cómo garantizar búsquedas de texto insensibles a mayúsculas en PDFs con C#?
Para realizar búsquedas de texto sin distinción de mayúsculas y minúsculas en PDFs, use IronPDF para extraer el texto, y luego aplique el método de C# string.Contains() con StringComparison.OrdinalIgnoreCase para ignorar la sensibilidad a mayúsculas y minúsculas durante la búsqueda.
¿Qué escenarios requieren el uso de expresiones regulares en lugar de string.Contains()?
Cuando necesita buscar patrones complejos o múltiples palabras clave dentro de texto extraído de un PDF, las expresiones regulares son más adecuadas que string.Contains(). Ofrecen capacidades avanzadas de coincidencia de patrones que no están disponibles con búsquedas de subcadena simples.
¿Cómo se puede optimizar el rendimiento al extraer texto de documentos PDF grandes?
Para optimizar el rendimiento al extraer texto de PDFs grandes, considere procesar el documento en secciones más pequeñas, como página por página. Este enfoque reduce el uso de memoria y mejora el rendimiento del sistema al prevenir la sobrecarga de recursos.
¿Es IronPDF compatible con tanto .NET Core como .NET Framework?
Sí, IronPDF es compatible con tanto .NET Core como .NET Framework, haciéndolo versátil para varias aplicaciones .NET. Esta compatibilidad asegura que pueda integrarse en diferentes tipos de proyectos sin problemas de compatibilidad.
¿Cómo se comienza a usar una biblioteca PDF en un proyecto .NET?
Para comenzar a usar IronPDF en un proyecto .NET, instálelo a través del Administrador de Paquetes de NuGet en Visual Studio. Una vez instalado, puede importarlo a su base de código C# y utilizar sus funciones, como extracción de texto y manipulación de PDF, para satisfacer sus necesidades de manejo de documentos.
¿Cuáles son las características clave de IronPDF para la manipulación de PDF?
IronPDF ofrece una gama de funciones para la manipulación de PDF, incluyendo extracción de texto, edición de PDF y conversión. Estas funciones ayudan a los desarrolladores a manejar PDFs de manera efectiva, agilizando procesos como el manejo de formularios y la generación de documentos en aplicaciones .NET.
¿Cómo puede IronPDF simplificar el manejo de PDFs en aplicaciones .NET?
IronPDF simplifica el manejo de PDFs proporcionando una API integral que permite a los desarrolladores crear, editar y extraer datos de archivos PDF con facilidad. Esto elimina la necesidad de configuraciones complejas y permite flujos de trabajo de procesamiento de documentos eficientes dentro de aplicaciones .NET.
¿Cómo se instala IronPDF en un proyecto .NET?
IronPDF se puede instalar en un proyecto .NET usando el Administrador de Paquetes de NuGet en Visual Studio. Use el comando: Install-Package IronPDF para agregar IronPDF a su proyecto y comenzar a utilizar sus capacidades de manipulación de PDF.
Jacob Mellor es Director de Tecnología de Iron Software y un ingeniero visionario pionero en la tecnología C# PDF. Como desarrollador original de la base de código principal de Iron Software, ha dado forma a la arquitectura de productos de la empresa desde su creación, ...
En el mundo del desarrollo actual, trabajar con PDFs es un requisito común para aplicaciones que necesitan manejar documentos, formularios o informes. Ya sea que esté construyendo una plataforma de comercio electrónico, un sistema de gestión de documentos, o solo necesite procesar facturas, extraer y buscar texto de PDFs puede ser crucial. Este artículo le guiará a través de cómo usar C# string.Contains() con IronPDF para buscar y extraer texto de archivos PDF en sus proyectos .NET.
Comparación de cadenas y subcadena especificada
Al realizar búsquedas, es posible que necesite realizar una comparación de cadenas basada en requisitos de subcadenas específicas. En tales casos, C# ofrece opciones como string.Contains(), que es una de las formas más simples de comparación.
Si necesita especificar si desea ignorar la sensibilidad de mayúsculas o no, puede usar la enumeración StringComparison. Esto le permite elegir el tipo de comparación de cadenas que desea, como comparación ordinal o comparación insensible a mayúsculas.
Si desea trabajar con posiciones específicas en la cadena, como la primera o última posición de caracteres, siempre puede usar Substring para aislar ciertas porciones de la cadena para un procesamiento posterior.
Si está buscando verificaciones de cadena vacías u otros casos extremos, asegúrese de manejar estos escenarios dentro de su lógica.
Si está manejando documentos grandes, es útil optimizar la posición de inicio de su extracción de texto, para extraer solo porciones relevantes en lugar de todo el documento. Esto puede ser particularmente útil si está tratando de evitar sobrecargar la memoria y el tiempo de procesamiento.
Si no está seguro del mejor enfoque para las reglas de comparación, considere cómo desea que se comporte su búsqueda en diferentes escenarios (por ejemplo, coincidiendo con múltiples términos, manejando espacios, etc.).
Si sus necesidades van más allá de simples verificaciones de subcadenas y requieren coincidencias de patrones más avanzadas, considere usar expresiones regulares, que ofrecen una flexibilidad significativa al trabajar con PDFs.
Si aún no lo ha hecho, pruebe la prueba gratuita de IronPDF hoy para explorar sus capacidades y ver cómo puede agilizar sus tareas de manejo de PDF. Ya sea que esté construyendo un sistema de gestión de documentos, procesando facturas o simplemente necesite extraer datos de PDFs, IronPDF es la herramienta perfecta para el trabajo.
¿Qué es IronPDF y por qué debería usarlo?
IronPDF es una poderosa biblioteca diseñada para ayudar a los desarrolladores a trabajar con PDFs en el ecosistema .NET. Te permite crear, leer, editar y manipular archivos PDF fácilmente sin tener que depender de herramientas externas o configuraciones complejas.
Descripción general de IronPDF
IronPDF proporciona una amplia gama de características para trabajar con PDFs en aplicaciones C#. Algunas características clave incluyen:
Extracción de texto: extrae texto simple o datos estructurados de archivos PDF.
Edición de PDF: modifique archivos PDF existentes agregando, eliminando o editando texto, imágenes y páginas.
Conversión de PDF: Convierte páginas HTML o ASPX a PDF o viceversa.
Manejo de formularios: extraiga o complete campos de formulario en formularios PDF interactivos.
IronPDF está diseñado para ser fácil de usar, pero también lo suficientemente flexible como para manejar escenarios complejos que implican PDFs. Funciona perfectamente con .NET Core y .NET Framework, siendo una ajuste perfecto para cualquier proyecto basado en .NET.
Instalación de IronPDF
Para usar IronPDF, instálalo a través del Gestor de Paquetes NuGet en Visual Studio:
Install-Package IronPdf
Cómo buscar texto en archivos PDF con C
Antes de sumergirnos en la búsqueda de PDFs, primero entendamos cómo extraer texto de un PDF usando IronPDF.
Extracción básica de texto PDF con IronPDF
IronPDF proporciona una API simple para extraer texto de documentos PDF. Esto permite buscar fácilmente contenido específico dentro de los PDFs.
El siguiente ejemplo demuestra cómo extraer texto de un PDF usando IronPDF:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}
Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Optionally, print the extracted text to the console
Console.WriteLine(text)
End Sub
End Class
$vbLabelText $csharpLabel
En este ejemplo, el método ExtractAllText() extrae todo el texto del documento PDF. Este texto puede ser procesado para buscar palabras clave o frases específicas.
Uso de string.Contains() para la búsqueda de texto
Una vez que se ha extraído el texto del PDF, puede usar el método incorporado string.Contains() de C# para buscar palabras o frases específicas.
El método string.Contains() devuelve un valor booleano que indica si una cadena especificada existe dentro de una cadena. Esto es particularmente útil para búsquedas básicas de texto.
A continuación se muestra cómo puede usar string.Contains() para buscar una palabra clave dentro del texto extraído:
Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)
$vbLabelText $csharpLabel
Ejemplo práctico: Cómo comprobar si una cadena en C# contiene palabras clave en un documento PDF
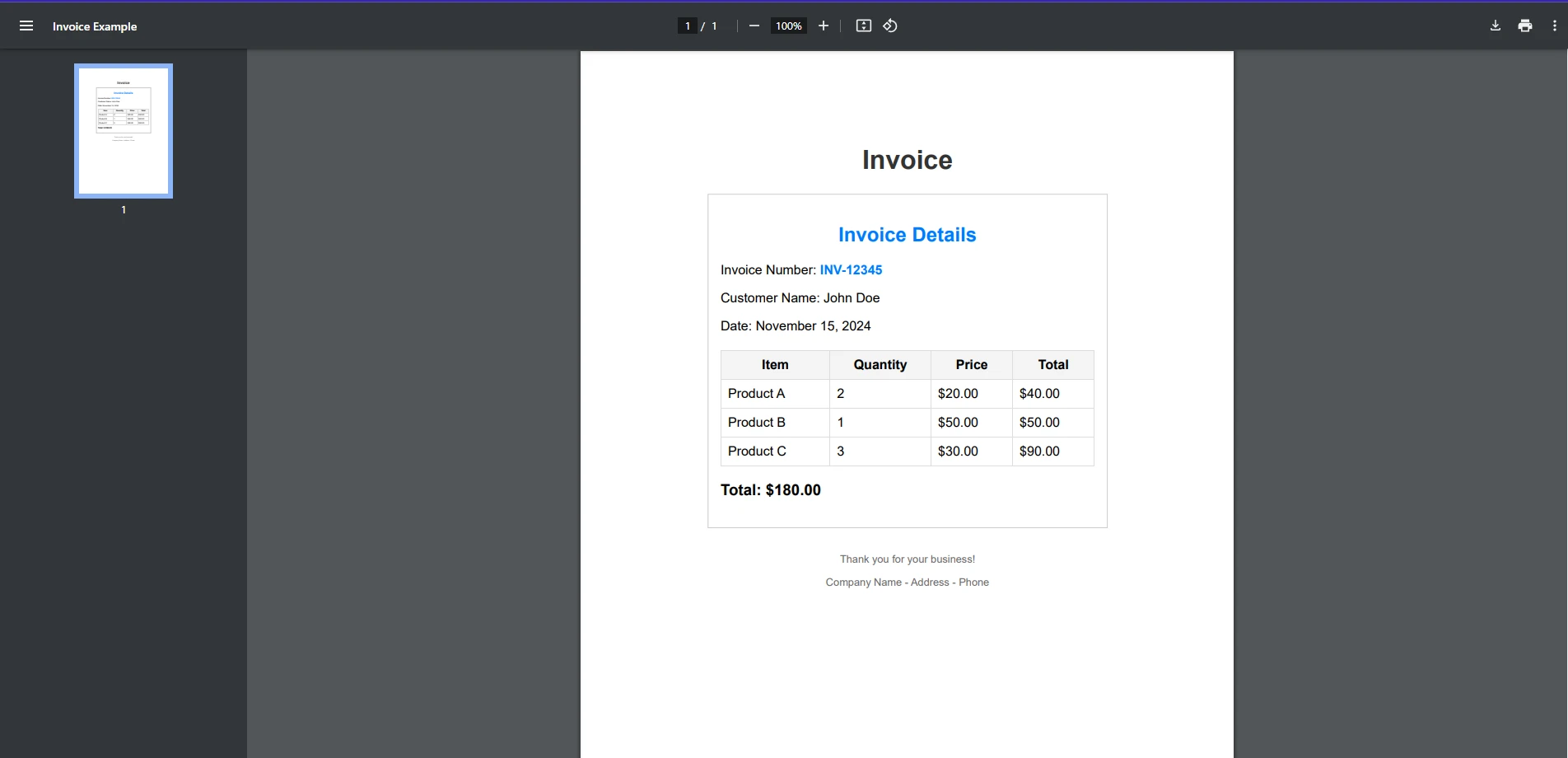
Vamos a desglosar esto más con un ejemplo práctico. Supongamos que desea saber si un número de factura específico existe en un documento de factura PDF.
A continuación se presenta un ejemplo completo de cómo implementar esto:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
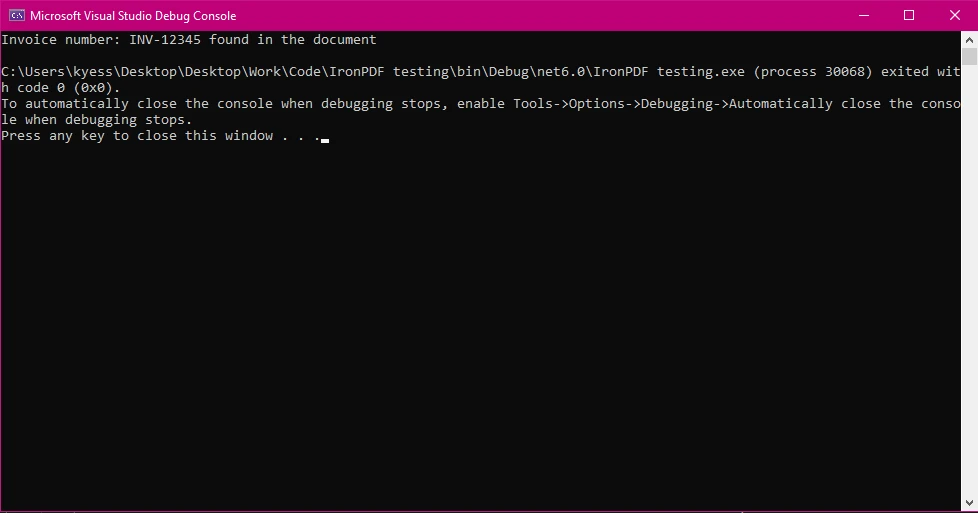
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}
Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for the specific invoice number
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
' Provide output based on whether the search term was found
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End Class
$vbLabelText $csharpLabel
PDF de entrada
Salida de consola
En este ejemplo:
Cargamos el archivo PDF y extraemos su texto.
Luego, usamos string.Contains() para buscar el número de factura INV-12345 en el texto extraído.
La búsqueda no distingue entre mayúsculas y minúsculas debido a StringComparison.OrdinalIgnoreCase.
Mejorar la búsqueda con expresiones regulares
Si bien string.Contains() funciona para búsquedas de subcadenas simples, es posible que desees realizar búsquedas más complejas, como encontrar un patrón o una serie de palabras clave. Para esto, puedes usar expresiones regulares.
Aquí hay un ejemplo usando una expresión regular para buscar cualquier formato de número de factura válido en el texto del PDF:
using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}
using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}
Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
' Check if a match was found
If match.Success Then
Console.WriteLine($"Invoice number found: {match.Value}")
Else
Console.WriteLine("No matching invoice number found.")
End If
End Sub
End Class
$vbLabelText $csharpLabel
Este código buscará cualquier número de factura que siga el patrón INV-XXXXX, donde XXXXX es una serie de dígitos.
Mejores prácticas para trabajar con PDF en .NET
Al trabajar con PDFs, especialmente documentos grandes o complejos, hay algunas mejores prácticas a tener en cuenta:
Optimización de la extracción de texto
Manejar archivos PDF grandes: si trabaja con archivos PDF grandes, es una buena idea extraer el texto en fragmentos más pequeños (por página) para reducir el uso de memoria y mejorar el rendimiento.
Manejar codificaciones especiales: tenga en cuenta las codificaciones y los caracteres especiales en el PDF. IronPDF generalmente maneja esto bien, pero los diseños complejos o fuentes pueden requerir un manejo adicional.
Integración de IronPDF en proyectos .NET
IronPDF se integra fácilmente con proyectos .NET. Después de descargar e instalar la biblioteca IronPDF a través de NuGet, simplemente impórtala en tu base de código C#, como se muestra en los ejemplos anteriores.
La flexibilidad de IronPDF te permite construir flujos de trabajo de procesamiento de documentos sofisticados, tales como:
Buscar y extraer datos de formularios.
Convertir HTML a PDF y extraer contenido.
Crear informes basados en la entrada del usuario o datos de bases de datos.
Conclusión
IronPDF hace que trabajar con PDFs sea fácil y eficiente, especialmente cuando necesitas extraer y buscar texto en PDFs. Al combinar el método string.Contains() de C# con las capacidades de extracción de texto de IronPDF, puede buscar y procesar rápidamente archivos PDF en sus aplicaciones .NET .
Si aún no lo has hecho, prueba el prueba gratuita de IronPDF hoy para explorar sus capacidades y ver cómo puede agilizar tus tareas de manejo de PDF. Ya sea que estés construyendo un sistema de gestión de documentos, procesando facturas o simplemente necesites extraer datos de PDFs, IronPDF es la herramienta perfecta para el trabajo.
Para comenzar con IronPDF, descarga el prueba gratuita y experimenta sus potentes características de manipulación de PDF de primera mano. Visita el sitio web de IronPDF para comenzar hoy.