
C# 字符串包含(开发者用法)
在当今的开发场景中,处理 PDF 是需要管理文档、表单或报告的应用程序的常见需求。 无论是构建电商平台、文档管理系统,还是处理发票,从 PDF 中提取和搜索文本都可能至关重要。 本文将介绍如何在 .NET 项目中结合使用 C# string.Contains() 与 IronPDF,搜索和提取 PDF 文件中的文本。
字符串比较和指定子字符串
在执行搜索时,您可能需要根据特定字符串子字符串要求执行字符串比较。 在这种情况下,C#提供了类似string.Contains()这样的选项,这是最简单的比较形式之一。
如果您需要指定是否忽略大小写,可以使用StringComparison枚举。 这使您可以选择所需的字符串比较类型,例如序数比较或不区分大小写的比较。
如果您想处理字符串中的特定位置,如第一个字符位置或最后一个字符位置,可以随时使用Substring来隔离字符串的某些部分以进行进一步处理。
如果您正在查找空字符串检查或其他边界情况,请确保在逻辑中处理这些场景。
如果您正在处理大型文档,优化文本提取的起始位置非常有用,以便仅提取相关部分而不是整个文档。 如果您想避免过度加载内存和处理时间,这将特别有用。
如果您不确定用于比较规则的最佳方法,请考虑具体的执行方法以及您对不同场景中搜索行为的要求(例如,匹配多个术语、处理空格等)。
如果您的需求超出了简单的子字符串检查并需要更高级的模式匹配,请考虑使用正则表达式,这在处理PDF时提供了显著的灵活性。
如果您还没有,请立即尝试IronPDF的免费试用,探索其功能并查看它如何简化您的PDF处理任务。 无论您是在构建文档管理系统、处理发票,还是仅需从PDF中提取数据,IronPDF都是完成工作的完美工具。
什么是IronPDF以及为什么您应该使用它?
IronPDF 是一个强大的库,专为在 .NET 生态系统中处理 PDF 的开发人员而设计。 无需依赖外部工具或复杂配置,即可轻松创建、读取、编辑和操作 PDF 文件。
IronPDF 概览
IronPDF提供了一系列广泛的功能,用于在C#应用程序中处理PDF。 一些关键功能包括:
*文本提取:从 PDF 中提取纯文本或结构化数据。
- PDF 编辑:通过添加、删除或编辑文本、图像和页面来修改现有 PDF。
- PDF转换:将HTML或ASPX页面转换为PDF,反之亦然。 *表单处理:提取或填充交互式 PDF 表单中的表单字段。
IronPDF 设计简洁易用,同时足够灵活,能够处理复杂的 PDF 场景。 它与 .NET Core 和 .NET Framework 无缝协作,适用于任何基于 .NET 的项目。
安装 IronPDF
要使用IronPDF,请在Visual Studio中通过NuGet包管理器安装它:
Install-Package IronPdf
How to Search Text in PDF Files Using C#
在深入研究查找PDF之前,首先了解如何使用IronPDF从PDF中提取文本。
使用IronPDF的基本PDF文本提取
IronPDF提供了一个简单的API来从PDF文档中提取文本。 这使您能够轻松在PDF中搜索特定内容。
以下示例演示了如何使用IronPDF从PDF中提取文本:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Optionally, print the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Optionally, print the extracted text to the console
Console.WriteLine(text)
End Sub
End Class在这个例子中,ExtractAllText() 方法从 PDF 文档中提取所有文本。 然后可以处理这些文本以搜索特定的关键字或短语。
使用string.Contains()进行文本搜索
一旦您从PDF中提取了文本,就可以使用C#内置的string.Contains()方法来搜索特定的单词或短语。
string.Contains() 方法返回一个布尔值,指示指定的字符串是否存在于字符串中。 这对于基本的文本搜索特别有用。
以下是如何使用string.Contains()在提取的文本中搜索关键字:
bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);bool isFound = text.Contains("search term", StringComparison.OrdinalIgnoreCase);Dim isFound As Boolean = text.Contains("search term", StringComparison.OrdinalIgnoreCase)实用示例:如何检查C#字符串是否包含PDF文档中的关键字
让我们以一个实际例子进一步分解这一点。 假设您想查找特定的发票号码是否存在于PDF发票文档中。
下面是如何实现的完整示例:
using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}using IronPdf;
using System;
public class Program
{
public static void Main(string[] args)
{
string searchTerm = "INV-12345";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Search for the specific invoice number
bool isFound = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase);
// Provide output based on whether the search term was found
if (isFound)
{
Console.WriteLine($"Invoice number: {searchTerm} found in the document");
}
else
{
Console.WriteLine($"Invoice number {searchTerm} not found in the document");
}
}
}Imports IronPdf
Imports System
Public Class Program
Public Shared Sub Main(ByVal args() As String)
Dim searchTerm As String = "INV-12345"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Search for the specific invoice number
Dim isFound As Boolean = text.Contains(searchTerm, StringComparison.OrdinalIgnoreCase)
' Provide output based on whether the search term was found
If isFound Then
Console.WriteLine($"Invoice number: {searchTerm} found in the document")
Else
Console.WriteLine($"Invoice number {searchTerm} not found in the document")
End If
End Sub
End Class输入PDF
控制台输出
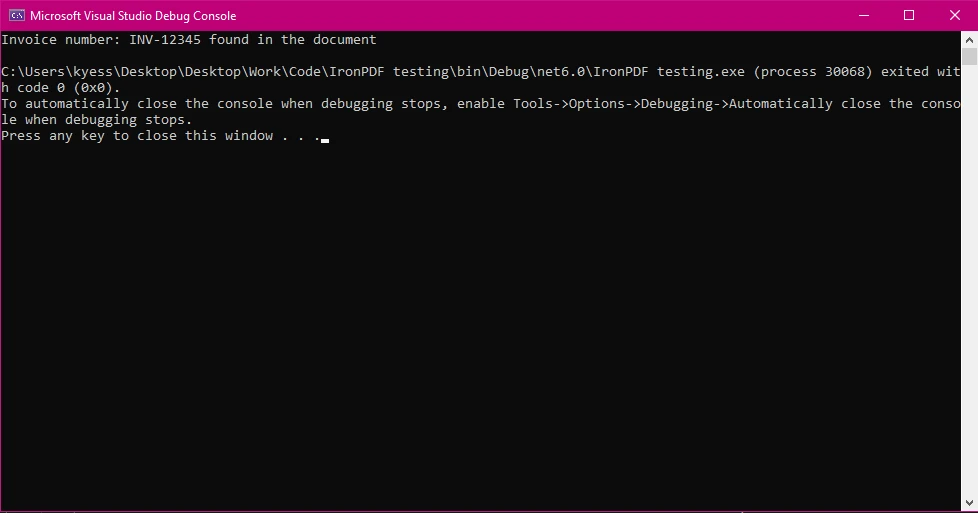
在此示例中:
- 我们加载PDF文件并提取其文本。
然后,我们使用
string.Contains()在提取的文本中搜索发票号码INV-12345。 - 由于
StringComparison.OrdinalIgnoreCase,搜索不区分大小写。
使用正则表达式增强搜索
虽然 string.Contains() 可以用于简单的子字符串搜索,但您可能希望执行更复杂的搜索,例如查找模式或一系列关键字。 为此,您可以使用正则表达式。
以下是如何使用正则表达式在PDF文本中搜索任何有效发票号格式的示例:
using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}using IronPdf;
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Define a regex pattern for a typical invoice number format (e.g., INV-12345)
string pattern = @"INV-\d{5}";
// Load the PDF from a file
PdfDocument pdf = PdfDocument.FromFile("exampleInvoice.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Perform the regex search
Match match = Regex.Match(text, pattern);
// Check if a match was found
if (match.Success)
{
Console.WriteLine($"Invoice number found: {match.Value}");
}
else
{
Console.WriteLine("No matching invoice number found.");
}
}
}Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Define a regex pattern for a typical invoice number format (e.g., INV-12345)
Dim pattern As String = "INV-\d{5}"
' Load the PDF from a file
Dim pdf As PdfDocument = PdfDocument.FromFile("exampleInvoice.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Perform the regex search
Dim match As Match = Regex.Match(text, pattern)
' Check if a match was found
If match.Success Then
Console.WriteLine($"Invoice number found: {match.Value}")
Else
Console.WriteLine("No matching invoice number found.")
End If
End Sub
End Class此代码将搜索遵循模式INV-XXXXX的任何发票号码,其中XXXXX是一系列数字。
在.NET中处理PDF的最佳实践
在处理PDF时,特别是大型或复杂文档时,请牢记一些最佳实践:
优化文本提取
*处理大型 PDF:*如果您要处理大型 PDF,最好将文本分成较小的块(按页)提取,以减少内存使用量并提高性能。 处理特殊编码:**注意 PDF 中的编码和特殊字符。 IronPDF通常对此处理得很好,但复杂的布局或字体可能需要额外的处理。
将IronPDF集成到.NET项目中
IronPDF很容易与.NET项目集成。 通过NuGet下载并安装IronPDF库后,只需将其导入到您的C#代码库中,如上面的示例所示。
IronPDF的灵活性使您能够构建复杂的文档处理工作流程,例如:
- 搜索和提取表单中的数据。
- 将HTML转换为PDF并提取内容。
- 根据用户输入或数据库中的数据创建报告。
结论
IronPDF使处理PDF变得简单高效,尤其是当您需要从PDF中提取和搜索文本时。 通过将 C# 的 string.Contains() 方法与 IronPDF 的文本提取功能相结合,您可以在 .NET 应用程序中快速搜索和处理 PDF。
如果您还没有,请立即尝试IronPDF的免费试用,以探索其功能并查看它如何简化您的PDF处理任务。 无论您是在构建文档管理系统、处理发票,还是仅需从PDF中提取数据,IronPDF都是完成工作的完美工具。
要开始使用IronPDF,请下载免费试用,亲身体验其强大的PDF操作功能。 访问IronPDF的网站立即开始。
常见问题解答
如何使用 C# string.Contains() 搜索 PDF 文件中的文本?
您可以结合使用 C# string.Contains() 和 IronPDF 搜索 PDF 文件中的特定文本。首先,使用 IronPDF 的文本提取功能从 PDF 中提取文本,然后应用 string.Contains() 找到所需的文本。
在 .NET 中使用 IronPDF 提取 PDF 文本的好处是什么?
IronPDF 提供了一个易于使用的 API 用于从 PDF 提取文本,这对于需要高效处理文档的应用程序至关重要。它简化了过程,使开发人员能够专注于实现业务逻辑,而不是处理复杂的 PDF 操作。
如何确保使用 C# 执行不区分大小写的 PDF 文本搜索?
要在 PDF 中执行不区分大小写的文本搜索,请使用 IronPDF 提取文本,然后使用 StringComparison.OrdinalIgnoreCase 的 C# string.Contains() 方法在搜索过程中忽略大小写。
哪些情况下需要使用正则表达式而不是 string.Contains()?
当您需要在从 PDF 提取的文本中搜索复杂模式或多个关键字时,正则表达式比 string.Contains() 更合适。它们提供了简单子字符串搜索无法实现的高级模式匹配功能。
如何在从大型 PDF 文档中提取文本时优化性能?
要在从大型 PDF 中提取文本时优化性能,可以考虑按较小部分(例如逐页)处理文档。这种方法可以减少内存使用,通过防止资源过载来提高系统性能。
IronPDF 是否兼容 .NET Core 和 .NET Framework?
是的,IronPDF 兼容 .NET Core 和 .NET Framework,使其适用于各种 .NET 应用程序。这种兼容性确保它可以集成到不同的项目类型中,而不会出现兼容性问题。
如何开始在 .NET 项目中使用 PDF 库?
要在 .NET 项目中开始使用 IronPDF,可以通过 Visual Studio 中的 NuGet 包管理器安装。安装后,您可以将其导入到您的 C# 代码库中,并利用其功能,如文本提取和 PDF 操作,以满足您的文档处理需求。
IronPDF用于PDF操作的关键功能是什么?
IronPDF 提供了一系列 PDF 操作功能,包括文本提取、PDF 编辑和转换。这些功能帮助开发人员有效处理 PDF 文件,简化 .NET 应用程序中的表单处理和文档生成等流程。
IronPDF 如何简化 .NET 应用程序中的 PDF 处理?
IronPDF 通过提供一个全面的 API 简化了 PDF 处理,允许开发人员轻松创建、编辑和提取 PDF 文件中的数据。这消除了复杂配置的需求,使 .NET 应用程序中的文档处理工作流程更加高效。
如何在 .NET 项目中安装 IronPDF?
可以使用 Visual Studio 中的 NuGet 包管理器在 .NET 项目中安装 IronPDF。使用命令:Install-Package IronPDF 将 IronPDF 添加到项目中,开始利用其 PDF 操作功能。














