
Jak wyodrębnić dane tabeli z pliku PDF w C#
W wielu branżach pliki PDF to standardowy format do udostępniania uporządkowanych dokumentów, takich jak raporty, faktury i tabele danych. Jednak wydobycie danych z plików PDF, zwłaszcza w przypadku tabel, może być trudne z powodu specyfiki formatu PDF. W przeciwieństwie do uporządkowanych formatów danych, pliki PDF są projektowane głównie do prezentacji, a nie do wydobywania danych.
Jednak dzięki IronPDF, potężnej bibliotece PDF .NET w C#, możesz łatwo wydobyć uporządkowane dane, takie jak tabele, bezpośrednio z plików PDF i przetwarzać je w swoich aplikacjach .NET. Ten artykuł przedstawi Ci krok po kroku, jak wydobywać dane tabelaryczne z plików PDF za pomocą IronPDF.
Kiedy należy wydobywać tabele z dokumentów PDF?
Tabele to wygodny sposób strukturyzowania i wyświetlania danych, niezależnie od zarządzania inwentarzem, wprowadzania danych, rejestracji danych takich jak opady deszczu itp. Zatem może istnieć wiele powodów, dla których trzeba wydobywać tabele i dane tabelaryczne z dokumentów PDF. Niektóre z najczęstszych zastosowań to:
- Automatyzacja wprowadzania danych: Wydobycie danych z tabel w raportach PDF lub fakturach może zautomatyzować procesy, takie jak wypełnianie baz danych lub arkuszy kalkulacyjnych.
- Analiza danych: Firmy często otrzymują raporty w formacie PDF. Wydobycie tabel pozwala na programistyczną analizę tych danych.
- Konwersja dokumentów: Wydobycie danych tabelarycznych do bardziej dostępnych formatów, jak Excel czy CSV, umożliwia łatwiejszą manipulację, przechowywanie i udostępnianie.
- Audyt i zgodność: W przypadku dokumentów prawnych lub finansowych, programistyczne wydobycie danych tabelarycznych z dokumentów PDF może pomóc w automatyzacji audytów i zapewnieniu zgodności.
Jak działają tabele w formacie PDF?
Format pliku PDF nie oferuje natywnej możliwości przechowywania danych w uporządkowanych formatach, takich jak tabele. Tabela użyta w dzisiejszym przykładzie została stworzona w HTML, zanim została skonwertowana na format PDF. Tabele są renderowane jako tekst i linie, więc wydobycie danych tabelarycznych często wymaga analizy i interpretacji treści, chyba że używasz oprogramowania OCR, takiego jak IronOCR.
How to Extract Table Data from a PDF File in C
Zanim przyjrzymy się, jak IronPDF może poradzić sobie z tym zadaniem, najpierw przyjrzymy się narzędziu online zdolnemu do obsługi ekstrakcji PDF. Aby wyodrębnić tabelę z dokumentu PDF za pomocą narzędzia online, postępuj zgodnie z poniższymi krokami:
- Przejdź do darmowego narzędzia online do ekstrakcji PDF
- Prześlij plik PDF zawierający tabelę
- Zobacz i pobierz wyniki
Krok pierwszy: Przejdź do darmowego narzędzia online do ekstrakcji PDF
Dziś użyjemy Docsumo jako naszego przykładu narzędzia online do ekstrakcji PDF. Docsumo to internetowy AI do dokumentów PDF, który oferuje darmowe narzędzie do ekstrakcji tabel z plików PDF.
Krok drugi: Prześlij plik PDF zawierający tabelę
Teraz kliknij przycisk "Prześlij plik", aby przesłać swój plik PDF do ekstrakcji. Narzędzie natychmiast rozpocznie przetwarzanie Twojego pliku PDF.
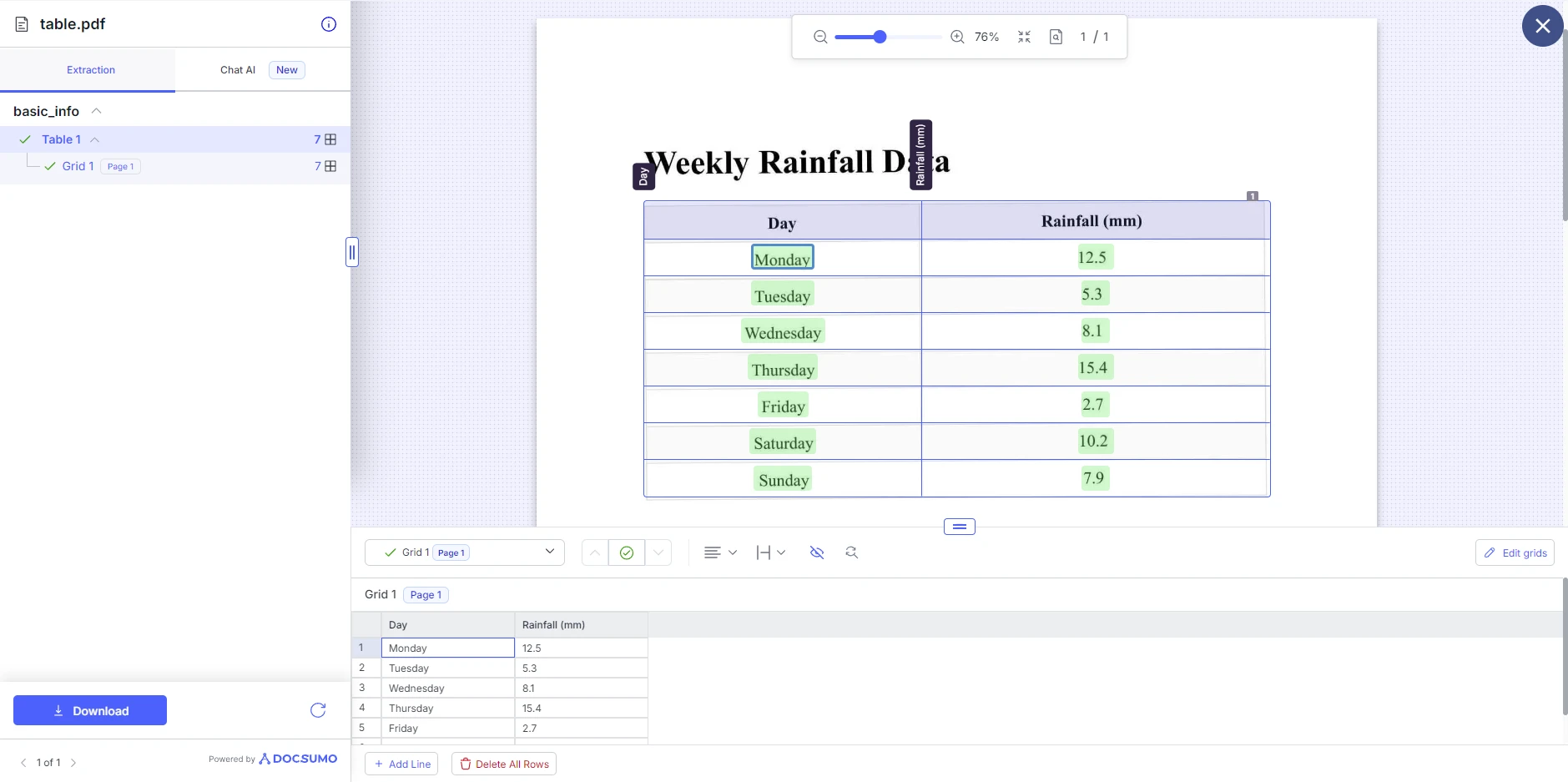
Krok trzeci: Zobacz i pobierz wyniki
Gdy Docsumo zakończy przetwarzanie pliku PDF, wyświetli wydobytą tabelę. Możesz wtedy dokonać korekt w strukturze tabeli, takich jak dodawanie i usuwanie wierszy. Tutaj możesz pobrać tabelę jako inny PDF, XLS, JSON lub tekst.
Wydobywanie danych tabelarycznych za pomocą IronPDF
IronPDF pozwala na wydobycie danych, tekstów i grafik z plików PDF, które można następnie wykorzystać do programistycznej rekonstrukcji tabel. Aby to zrobić, najpierw musisz wydobyć tekstową zawartość tabeli w pliku PDF, a następnie użyć tego tekstu do parsowania tabeli na wiersze i kolumny. Zanim zaczniemy wydobywać tabele, przyjrzyjmy się, jak działa metoda IronPDF ExtractAllText() poprzez wydobycie danych w tabeli:
using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class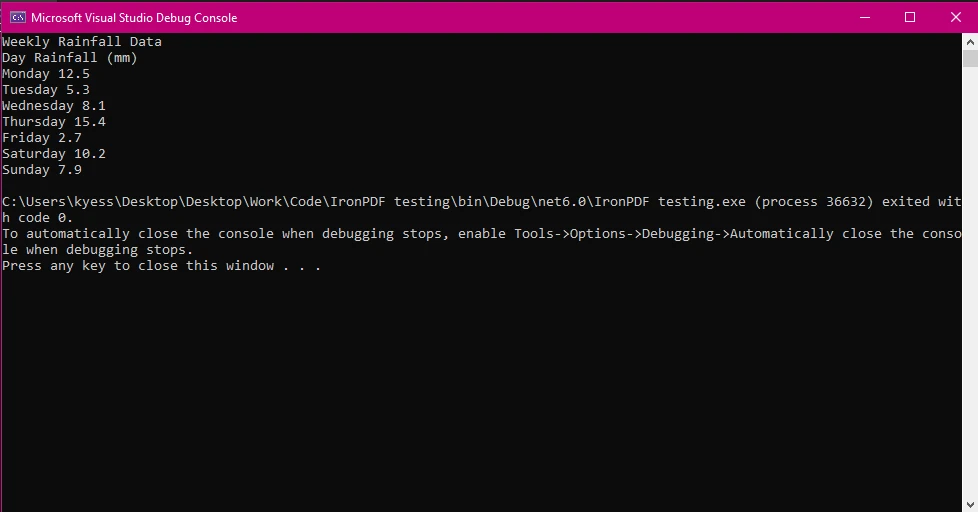
W tym przykładzie załadowaliśmy dokument PDF za pomocą klasy PdfDocument, a następnie użyliśmy metody ExtractAllText() do wydobycia całego tekstu w dokumencie, a następnie wyświetliliśmy tekst na konsoli.
Wydobywanie danych tabelarycznych z tekstu za pomocą IronPDF
Po wydobyciu tekstu z pliku PDF tabela pojawi się jako seria wierszy i kolumn w tekście o prostym układzie. Możesz podzielić ten tekst na podstawie znaków nowej linii (\n), a następnie dalej podzielić wiersze na kolumny na podstawie spójnego odstępu lub separatorów, takich jak przecinki czy tabulatory. Oto podstawowy przykład, jak przeanalizować tabelę z tekstu:
using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPDF
Imports System
Imports System.Linq
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("table.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Split the text into lines (rows)
Dim lines() As String = text.Split(ControlChars.Lf)
For Each line As String In lines
' Split the line into columns using the tab character
Dim columns() As String = line.Split(ControlChars.Tab).Where(Function(col) Not String.IsNullOrWhiteSpace(col)).ToArray()
Console.WriteLine("Row:")
For Each column As String In columns
Console.WriteLine(" " & column) ' Output each column in the row
Next column
Next line
End Sub
End Class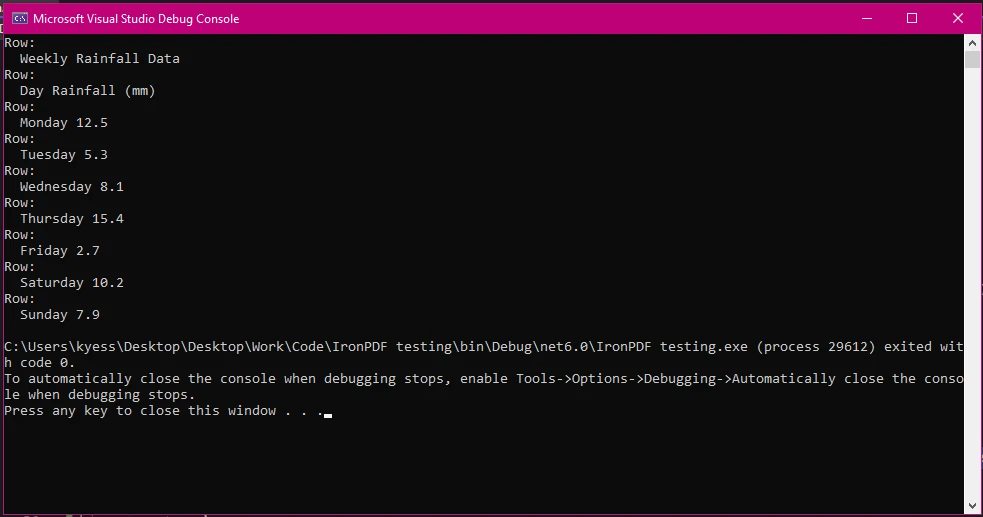
W tym przykładzie postąpiliśmy według tych samych kroków co wcześniej, aby załadować nasz dokument PDF i wydobyć tekst. Następnie, używając text.Split('\n'), podzieliliśmy wydobyty tekst na wiersze, bazując na znakach nowej linii, i zapisaliśmy wyniki w tablicy lines. Pętla foreach jest następnie używana do przechodzenia przez wiersze w tablicy, gdzie line.Split('\t') jest używana do dalszego podziału wierszy na kolumny przy użyciu znaku tabulatora '\t' jako separatora. Kolejna część tablicy kolumn, Where(col => !string.IsNullOrWhiteSpace(col)).ToArray(), filtruje puste kolumny, które mogą powstać z powodu dodatkowych spacji, a następnie dodaje kolumny do tablicy kolumn.
W końcu zapisujemy tekst w oknie wyjścia konsoli z podstawową strukturą wierszy i kolumn.
Eksportowanie wydobytych danych tabelarycznych do CSV
Teraz, gdy omówiliśmy, jak wydobyć tabele z plików PDF, spójrzmy, co możemy zrobić z tymi wydobytymi danymi. Eksportowanie wydobytej tabeli jako pliku CSV to jeden z użytecznych sposobów obsługi danych tabelarycznych i automatyzacji zadań, takich jak wprowadzanie danych. W tym przykładzie wypełniliśmy tabelę danymi symulowanymi, w tym przypadku, ilością opadów dziennych w tygodniu, wydobyliśmy tabelę z pliku PDF, a następnie wyeksportowaliśmy ją do pliku CSV.
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfPath As String = "table.pdf"
Dim csvPath As String = "output.csv"
' Extract and parse table data
Dim tableData = ExtractTableDataFromPdf(pdfPath)
' Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath)
Console.WriteLine($"Data extracted and saved to {csvPath}")
End Sub
Private Shared Function ExtractTableDataFromPdf(ByVal pdfPath As String) As List(Of String())
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract text from the first page
Dim text = pdf.ExtractTextFromPage(0)
Dim rows = New List(Of String())()
' Split text into lines (rows)
Dim lines = text.Split(ControlChars.Lf)
' Variable to hold column values temporarily
Dim tempColumns = New List(Of String)()
For Each line In lines
Dim trimmedLine = line.Trim()
' Check for empty lines or lines that don't contain table data
If String.IsNullOrEmpty(trimmedLine) OrElse trimmedLine.Contains("Header") Then
Continue For
End If
' Split line into columns. Adjust this based on how columns are separated.
Dim columns = trimmedLine.Split( { " "c, ControlChars.Tab }, StringSplitOptions.RemoveEmptyEntries)
If columns.Length > 0 Then
' Add columns to temporary list
tempColumns.AddRange(columns)
rows.Add(tempColumns.ToArray())
tempColumns.Clear() ' Clear temporary list after adding to rows
End If
Next line
Return rows
End Function
Private Shared Sub WriteDataToCsv(ByVal data As List(Of String()), ByVal csvPath As String)
Using writer = New StreamWriter(csvPath)
For Each row In data
' Join columns with commas and quote each field to handle commas within data
Dim csvRow = String.Join(",", row.Select(Function(field) $"""{field.Replace("""", """""")}"""))
writer.WriteLine(csvRow)
Next row
End Using
End Sub
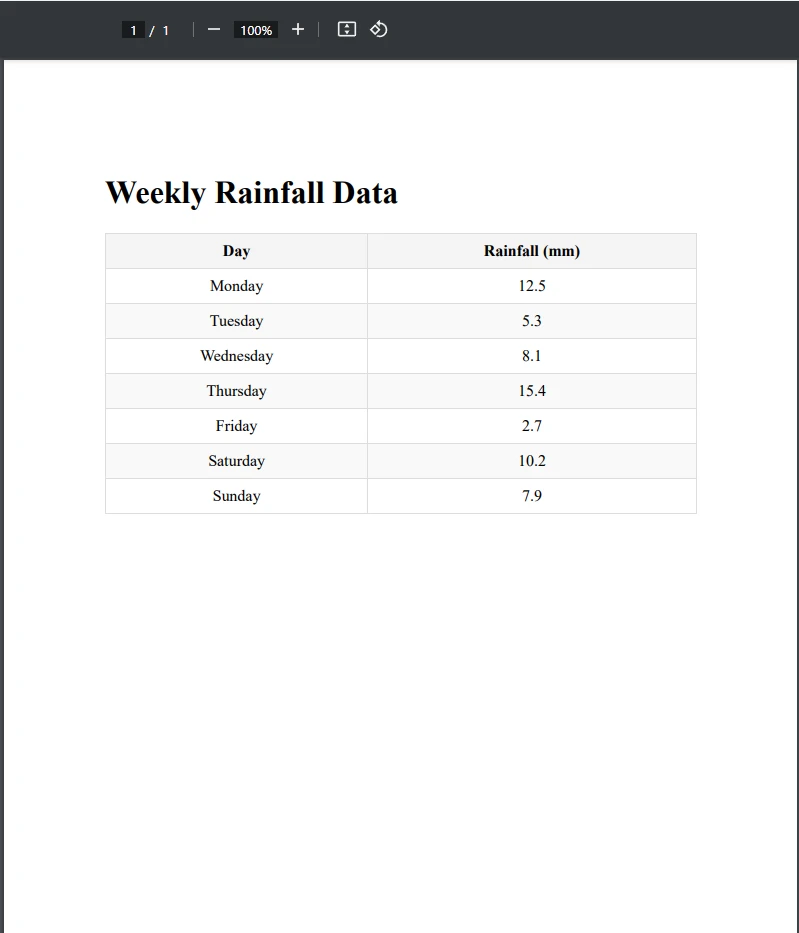
End ClassPrzykładowy plik PDF
Plik wyjściowy CSV
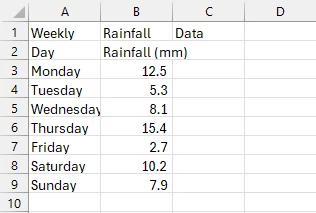
Jak widzisz, z powodzeniem wyeksportowaliśmy tabelę PDF do CSV. Najpierw załadowaliśmy PDF zawierający tabelę i utworzyliśmy nową ścieżkę pliku CSV. Następnie wydobyliśmy tabelę używając wiersza var tableData = ExtractTableDataFromPdf(pdfPath), który wywołuje metodę ExtractTableDataFromPdf(). Ta metoda wydobywa cały tekst na stronie PDF, na której znajduje się tabela, przechowując go w zmiennej text.
Następnie podzieliliśmy tekst na linie i kolumny. W końcu, po zwróceniu wyniku z tego procesu podziału, wywołujemy metodę static void WriteDataToCsv(), która pobiera wydobyty, podzielony tekst i zapisuje go do naszego pliku CSV za pomocą StreamWriter.
Wskazówki i najlepsze praktyki
Podczas pracy z tabelami w PDF, przestrzeganie kilku podstawowych najlepszych praktyk może pomóc w zminimalizowaniu szans na napotkanie błędów lub problemów.
- Wstępne przetwarzanie plików PDF: Jeśli to możliwe, wstępnie przetwórz swoje pliki PDF, aby zapewnić spójne formatowanie, co upraszcza proces ekstrakcji.
- Walidacja danych: Zawsze sprawdzaj poprawność wydobytych danych, aby zapewnić ich dokładność i kompletność.
- Zarządzanie błędami: Zaimplementuj obsługę błędów, aby zarządzać przypadkami, w których ekstrakcja lub parsowanie tekstu kończy się niepowodzeniem, na przykład umieszczając swój kod w bloku try-catch.
- Optymalizacja wydajności: W przypadku dużych plików PDF rozważ optymalizację ekstrakcji tekstu i parsowania, aby zaradzić problemom z wydajnością.
Licencjonowanie IronPDF
IronPDF oferuje różne opcje licencjonowania, pozwalając Ci samodzielnie wypróbować wszystkie potężne funkcje IronPDF przed zobowiązaniem się do zakupu licencji.
Wnioski
Wydobywanie tabel z plików PDF za pomocą IronPDF jest potężnym sposobem na automatyzację ekstrakcji danych, ułatwianie analizy i konwersję dokumentów do bardziej dostępnych formatów. Niezależnie od pracy z prostymi tabelami czy skomplikowanymi, nieregularnymi formatami, IronPDF zapewnia narzędzia potrzebne do skutecznego wydobywania i przetwarzania danych tabelarycznych.
Dzięki IronPDF możesz usprawnić przepływy pracy, takie jak automatyzacja wprowadzania danych, konwersja dokumentów i analiza danych. Elastyczność i zaawansowane funkcje oferowane przez IronPDF czynią go wartościowym narzędziem do obsługi różnych zadań związanych z plikami PDF.
Często Zadawane Pytania
Jak wyodrębnić tabele z pliku PDF przy użyciu języka C#?
Możesz użyć IronPDF do wyodrębniania tabel z pliku PDF w języku C#. Załaduj dokument PDF za pomocą IronPDF, wyodrębnij tekst, a następnie programowo podziel go na wiersze i kolumny.
Dlaczego trudno jest wyodrębnić dane z tabel w dokumentach PDF?
Pliki PDF są przeznaczone przede wszystkim do prezentacji, a nie do przechowywania struktur danych, co sprawia, że wyodrębnianie danych strukturalnych, takich jak tabele, jest trudne. Narzędzia takie jak IronPDF pomagają skutecznie interpretować i wyodrębniać te dane.
Jakie są zalety wyodrębniania tabel z plików PDF?
Wyodrębnianie tabel z plików PDF ułatwia automatyzację wprowadzania danych, przeprowadzanie analizy danych, konwersję dokumentów do bardziej dostępnych formatów oraz zapewnienie zgodności w procesach audytowych.
Jak radzisz sobie ze złożonymi formatami tabel podczas ekstrakcji z plików PDF?
IronPDF oferuje funkcje umożliwiające wyodrębnianie i przetwarzanie danych tabelarycznych nawet ze złożonych i nieregularnych formatów tabel, zapewniając dokładne wyodrębnianie danych.
Jak wygląda proces konwersji danych z tabel w pliku PDF do formatu CSV?
Po wyodrębnieniu i przeanalizowaniu danych z tabeli z pliku PDF za pomocą IronPDF można wyeksportować te dane do pliku CSV, zapisując przeanalizowane dane za pomocą StreamWriter.
Jakie są najlepsze praktyki dotyczące wyodrębniania tabel z plików PDF?
Należy wstępnie przetworzyć pliki PDF w celu uzyskania spójnego formatowania, zweryfikować wyodrębnione dane, wdrożyć obsługę błędów oraz zoptymalizować wydajność podczas pracy z dużymi plikami PDF.
Czy IronPDF może pomóc w zadaniach związanych z audytem i zgodnością z przepisami?
Tak, IronPDF może wyodrębniać dane tabelaryczne z plików PDF i konwertować je do formatów takich jak Excel lub CSV, ułatwiając audyt i zapewnienie zgodności z przepisami poprzez zwiększenie dostępności danych do przeglądu i analizy.
Jakie opcje licencyjne oferuje IronPDF?
IronPDF oferuje różne opcje licencyjne, w tym wersje próbne, dzięki czemu można zapoznać się z jego funkcjami przed zakupem pełnej licencji.
Jakie typowe problemy mogą pojawić się podczas wyodrębniania tabel z plików PDF?
Typowe problemy to niespójne formatowanie tabel i błędy podczas wyciągania tekstu. Korzystanie z solidnych funkcji IronPDF może pomóc w pokonaniu tych wyzwań, zapewniając dokładne możliwości analizowania danych.
Czy IronPDF jest w pełni kompatybilny z .NET 10 i jakie korzyści przynosi to procesom ekstrakcji tabel?
Tak — IronPDF obsługuje .NET 10 (a także .NET 9, 8, 7, 6, Core, Standard i Framework), co oznacza, że można go używać w najnowszych projektach .NET 10 bez problemów z konfiguracją. Programiści tworzący oprogramowanie w oparciu o .NET 10 korzystają z ulepszeń wydajności środowiska uruchomieniowego, takich jak zmniejszone alokacje i ulepszone optymalizacje kompilatora JIT, które pomagają przyspieszyć przetwarzanie plików PDF i operacje wyodrębniania tabel.














