

ASP .NET에서 PDF 생성하는 방법
많은 산업에서 PDF 파일은 보고서, 청구서, 데이터 표와 같은 구조화된 문서를 공유하는 데 주로 사용됩니다. 그러나 PDF에서 데이터를 추출하는 것은 특히 표의 경우 PDF 형식의 특성으로 인해 도전적일 수 있습니다. 구조화된 데이터 형식과 달리, PDF는 주로 프레젠테이션을 위해 설계되었고, 데이터 추출을 위한 것이 아닙니다.
그러나 강력한 C# PDF .NET 라이브러리인 IronPDF를 사용하면 PDF에서 표와 같은 구조화된 데이터를 쉽게 추출하고 .NET 응용 프로그램에서 이를 처리할 수 있습니다. 이 기사는 IronPDF를 사용하여 PDF 파일에서 표 데이터를 추출하는 방법을 단계별로 안내할 것입니다.
PDF 문서에서 표를 추출해야 하는 경우는 언제인가요?
표는 데이터 입력, 재고 관리 수행, 강우와 같은 데이터를 기록할 때든 데이터의 구조화 및 표시하는 편리한 방법입니다. 따라서 PDF 문서에서 표와 표 데이터를 추출해야 하는 많은 이유가 있을 수 있습니다. 가장 일반적인 사용 사례는 다음과 같습니다:
- 데이터 입력 자동화: PDF 보고서나 청구서의 표에서 데이터를 추출하면 데이터베이스나 스프레드시트 채우기 같은 프로세스를 자동화할 수 있습니다.
- 데이터 분석: 비즈니스는 종종 PDF 형식의 구조화된 보고서를 받습니다. 표를 추출하면 프로그래밍 방식으로 이 데이터를 분석할 수 있습니다.
- 문서 변환: 표 데이터를 Excel이나 CSV와 같은 더 쉽게 접근할 수 있는 형식으로 추출하면 조작, 저장, 공유가 더 쉬워집니다.
- 감사 및 준수: 법적 또는 재무 기록을 위해 PDF 문서에서 프로그래밍 방식으로 표 데이터를 추출하면 감사를 자동화하고 준수 여부를 보장할 수 있습니다.
PDF 표는 어떻게 작동하나요?
PDF 파일 형식은 표와 같은 구조화된 형식으로 데이터를 저장할 수 있는 네이티브 기능을 제공하지 않습니다. 오늘 예제에서 사용한 표는 HTML에서 만들어진 후 PDF 형식으로 변환되었습니다. 표는 텍스트와 선으로 렌더링되므로, 표 데이터를 추출하려면 OCR 소프트웨어인 IronOCR를 사용하지 않는 한 콘텐츠를 일부 구문 분석하고 해석해야 합니다.
How to Extract Table Data from a PDF File in C
IronPDF가 이 작업을 처리할 수 있는 방법을 탐색하기 전에 PDF 추출을 처리할 수 있는 온라인 도구를 먼저 탐색해 봅시다. 온라인 PDF 도구를 사용하여 PDF 문서에서 표를 추출하려면 아래에 나열된 단계를 따르세요:
- 무료 온라인 PDF 추출 도구로 이동
- 표가 포함된 PDF 업로드
- 결과 확인 및 다운로드
1단계: 무료 온라인 PDF 추출 도구로 이동
오늘 우리는 온라인 PDF 도구 예제로 Docsumo를 사용할 것입니다. Docsumo는 무료 PDF 표 추출 도구를 제공하는 온라인 PDF 문서 AI입니다.
2단계: 표가 포함된 PDF 업로드
이제 "파일 업로드" 버튼을 클릭하여 추출할 PDF 파일을 업로드하세요. 도구는 즉시 PDF 처리를 시작할 것입니다.
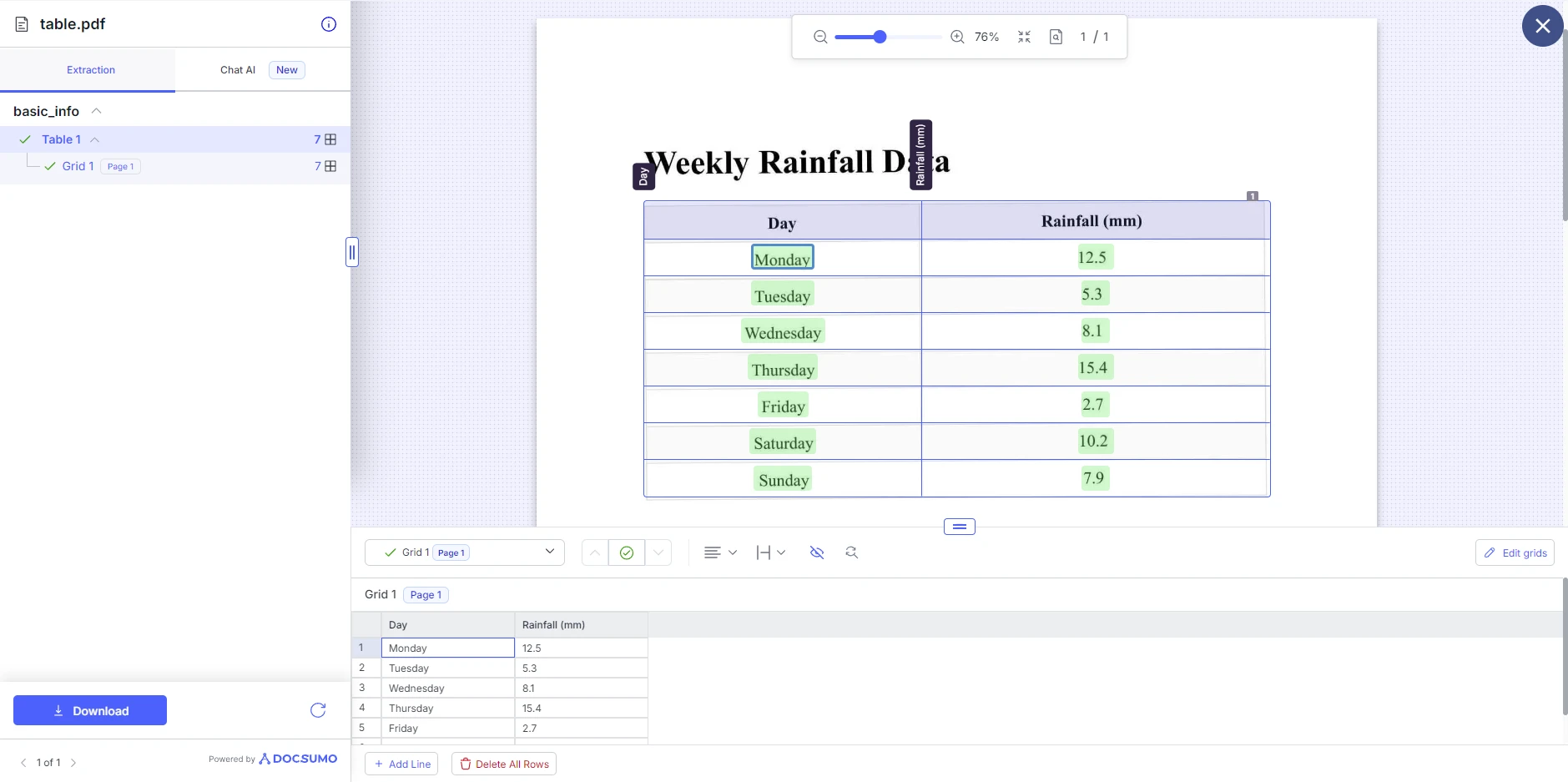
3단계: 결과 확인 및 다운로드
Docsumo가 PDF 처리를 완료하면 추출된 표를 표시합니다. 그런 다음 행을 추가하거나 제거하는 등 표 구조를 조정할 수 있습니다. 여기서 표를 다른 PDF, XLS, JSON, 텍스트 형식으로 다운로드할 수 있습니다.
IronPDF를 사용하여 표 데이터 추출
IronPDF는 PDF에서 데이터, 텍스트 및 그래픽을 추출할 수 있으며, 이를 프로그래밍 방식으로 테이블을 복원하는 데 사용할 수 있습니다. 이를 수행하려면 먼저 PDF의 표에서 텍스트 콘텐츠를 추출한 다음 해당 텍스트를 사용하여 표를 행과 열로 구문 분석해야 합니다. 표를 추출하기 전에 IronPDF의 ExtractAllText() 메서드가 표 안의 데이터를 추출하는 방법을 살펴보겠습니다:
using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class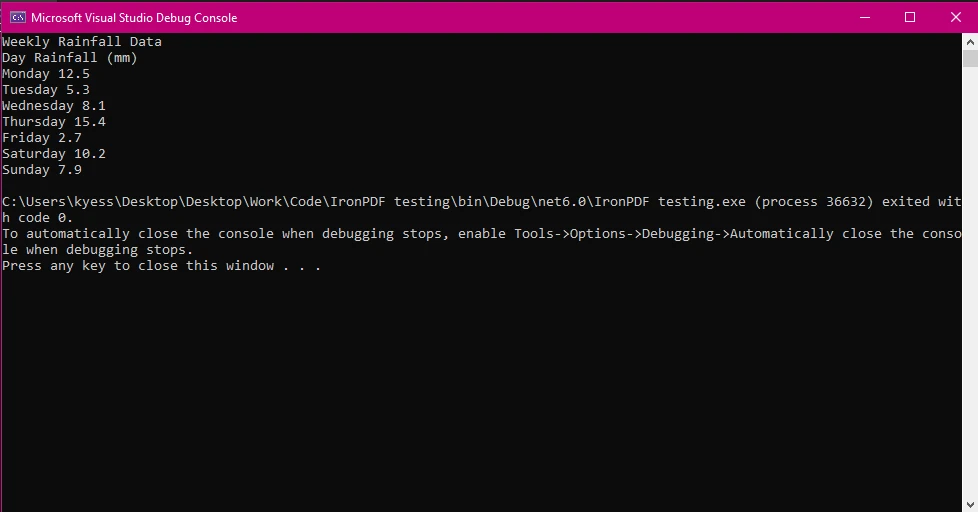
이 예제에서는 PdfDocument 클래스를 사용하여 PDF 문서를 로드한 다음 ExtractAllText() 메서드를 사용하여 문서 내의 모든 텍스트를 추출한 후 콘솔에 텍스트를 표시했습니다.
IronPDF를 사용하여 텍스트에서 표 데이터 추출하기
PDF에서 텍스트를 추출한 후 표는 일반 텍스트로 행과 열의 시리즈로 나타납니다. 이 텍스트를 줄 바꿈(\n)을 기준으로 분할한 후, 행을 일관된 간격 또는 쉼표나 탭과 같은 구분자를 사용하여 열로 추가로 분할할 수 있습니다. 다음은 텍스트에서 표를 구문 분석하는 기본 예입니다:
using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPDF
Imports System
Imports System.Linq
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("table.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Split the text into lines (rows)
Dim lines() As String = text.Split(ControlChars.Lf)
For Each line As String In lines
' Split the line into columns using the tab character
Dim columns() As String = line.Split(ControlChars.Tab).Where(Function(col) Not String.IsNullOrWhiteSpace(col)).ToArray()
Console.WriteLine("Row:")
For Each column As String In columns
Console.WriteLine(" " & column) ' Output each column in the row
Next column
Next line
End Sub
End Class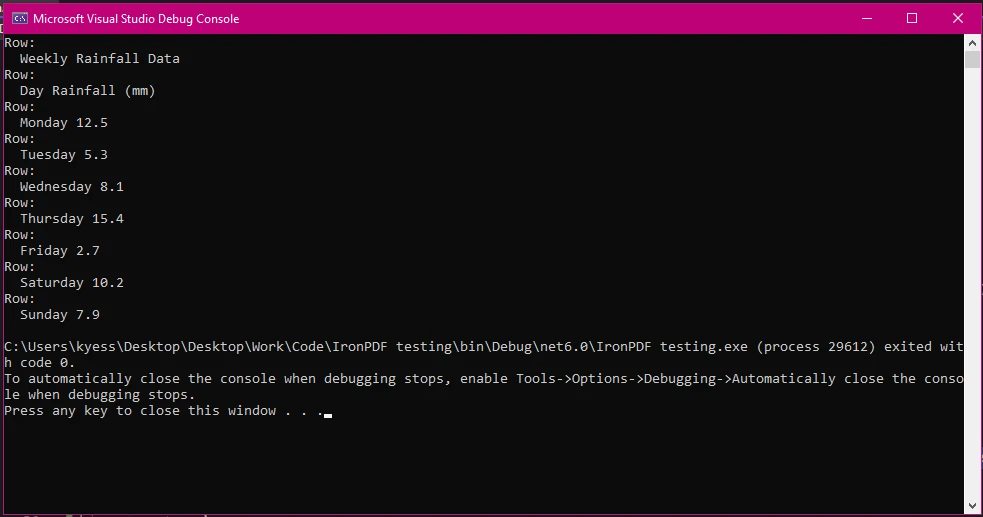
이 예제에서는 PDF 문서를 로드하고 텍스트를 추출하기 위해 이전과 동일한 단계를 따랐습니다. 그런 다음, text.Split('\n')을 사용하여 줄 바꿈을 기준으로 추출한 텍스트를 행으로 분할하고 lines 배열에 결과를 저장합니다. 이후 foreach 루프를 사용하여 배열의 행을 반복하고 line.Split('\t')를 사용하여 탭 문자 '\t'를 구분자로 행을 열로 추가로 분할합니다. 열 배열의 다음 부분인 Where(col => !string.IsNullOrWhiteSpace(col)).ToArray()는 추가 공간으로 인해 발생할 수 있는 빈 열을 필터링하고 열 배열에 열을 추가합니다.
최종적으로 텍스트를 기본 행과 열 구조로 콘솔 출력 창에 씁니다.
추출된 표 데이터를 CSV로 내보내기
이제 PDF 파일에서 표를 추출하는 방법을 다뤘으니, 추출된 데이터로 할 수 있는 작업을 살펴봅시다. 추출된 표를 CSV 파일로 내보내는 것은 테이블 데이터를 처리하고 데이터 입력과 같은 작업을 자동화하는 유용한 방법입니다. 이 예제에서는 모의 데이터를 사용하여 표를 채운 후, PDF에서 표를 추출하고 이를 CSV 파일로 내보냈습니다.
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfPath As String = "table.pdf"
Dim csvPath As String = "output.csv"
' Extract and parse table data
Dim tableData = ExtractTableDataFromPdf(pdfPath)
' Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath)
Console.WriteLine($"Data extracted and saved to {csvPath}")
End Sub
Private Shared Function ExtractTableDataFromPdf(ByVal pdfPath As String) As List(Of String())
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract text from the first page
Dim text = pdf.ExtractTextFromPage(0)
Dim rows = New List(Of String())()
' Split text into lines (rows)
Dim lines = text.Split(ControlChars.Lf)
' Variable to hold column values temporarily
Dim tempColumns = New List(Of String)()
For Each line In lines
Dim trimmedLine = line.Trim()
' Check for empty lines or lines that don't contain table data
If String.IsNullOrEmpty(trimmedLine) OrElse trimmedLine.Contains("Header") Then
Continue For
End If
' Split line into columns. Adjust this based on how columns are separated.
Dim columns = trimmedLine.Split( { " "c, ControlChars.Tab }, StringSplitOptions.RemoveEmptyEntries)
If columns.Length > 0 Then
' Add columns to temporary list
tempColumns.AddRange(columns)
rows.Add(tempColumns.ToArray())
tempColumns.Clear() ' Clear temporary list after adding to rows
End If
Next line
Return rows
End Function
Private Shared Sub WriteDataToCsv(ByVal data As List(Of String()), ByVal csvPath As String)
Using writer = New StreamWriter(csvPath)
For Each row In data
' Join columns with commas and quote each field to handle commas within data
Dim csvRow = String.Join(",", row.Select(Function(field) $"""{field.Replace("""", """""")}"""))
writer.WriteLine(csvRow)
Next row
End Using
End Sub
End Class예제 PDF 파일
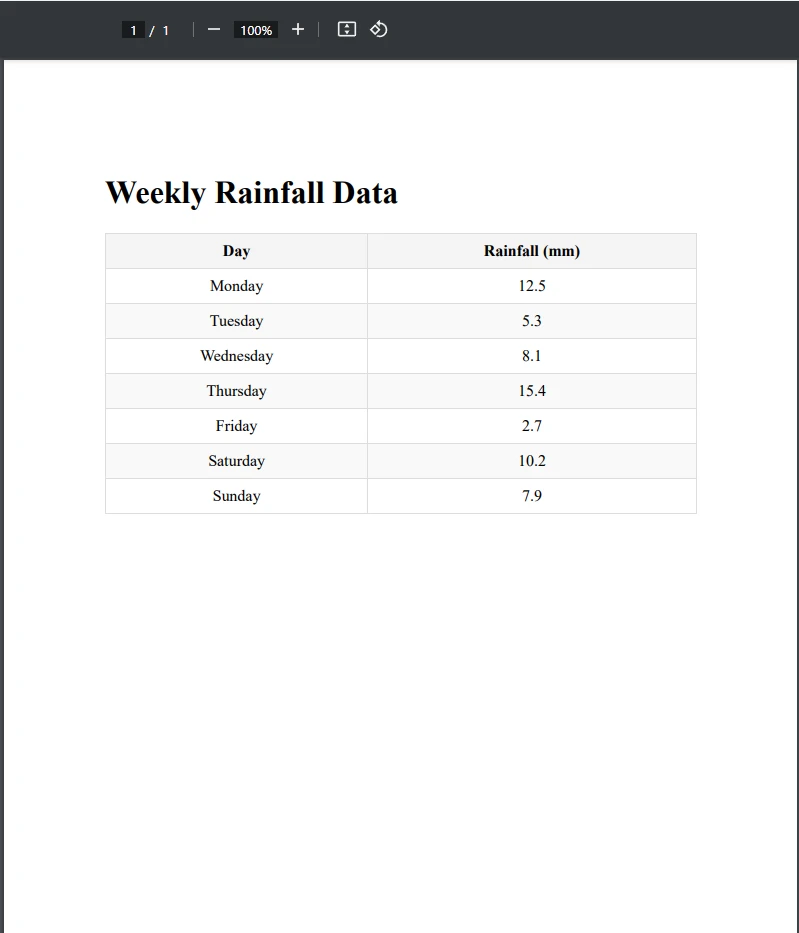
CSV 파일 출력
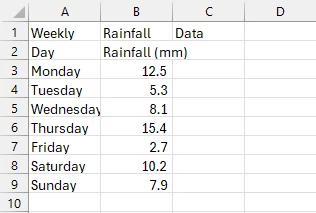
보시다시피, 우리는 PDF 표를 성공적으로 CSV로 내보냈습니다. 먼저, 표를 포함한 PDF를 로드하고 새 CSV 파일 경로를 생성했습니다. 그 다음, var tableData = ExtractTableDataFromPdf(pdfPath) 줄을 사용하여 ExtractTableDataFromPdf() 메서드를 호출해 테이블을 추출했습니다. 이 메서드는 테이블이 있는 PDF 페이지의 모든 텍스트를 추출하고 text 변수에 저장합니다.
그런 후, 텍스트를 줄과 열로 분할합니다. 이 분할 과정의 결과를 반환한 후, static void WriteDataToCsv() 메소드를 호출하여 추출된 분할 텍스트를 가져와 StreamWriter를 사용하여 CSV 파일에 씁니다.
팁 및 모범 사례
PDF 테이블 작업 시, 일부 기본 모범 사례를 따르십시오. 이렇게 하면 오류나 문제를 최소화할 수 있습니다.
- PDF 사전 처리: 가능하다면, PDF를 사전 처리하여 일관된 형식을 보장하십시오. 이렇게 하면 추출 과정이 단순화됩니다.
- 데이터 검증: 항상 추출된 데이터의 정확성과 완전성을 보장하기 위해 데이터를 검증하십시오.
- 오류 처리: 텍스트 추출 또는 구문 분석 실패 시를 위한 오류 처리를 구현하십시오. 예를 들어, try-catch 블록 내에 코드를 래핑하시기 바랍니다.
- 성능 최적화: 큰 PDF의 경우 성능 문제를 처리하기 위해 텍스트 추출 및 구문 분석을 최적화하는 것을 고려하십시오.
IronPDF 라이선스
IronPDF는 다양한 라이센싱 옵션을 제공하여 라이센스를 확정하기 전에 IronPDF가 제공하는 강력한 기능을 직접 시도해 볼 수 있게 해줍니다.
결론
IronPDF를 사용하여 PDF에서 테이블을 추출하는 것은 데이터 추출을 자동화하고, 분석을 용이하게 하며, 문서를 더 접근 가능한 형식으로 변환하는 강력한 방법입니다. 단순한 테이블이든 복잡하고 비정상적인 형식이든 IronPDF는 표 데이터를 효율적으로 추출하고 처리하는 데 필요한 도구를 제공합니다.
IronPDF를 사용하면 자동화된 데이터 입력, 문서 변환 및 데이터 분석과 같은 워크플로를 간소화할 수 있습니다. IronPDF가 제공하는 유연성과 고급 기능은 다양한 PDF 기반 작업을 처리하는 데 있어 가치 있는 도구가 되게 합니다.
자주 묻는 질문
C#을 사용하여 PDF에서 표를 어떻게 추출할 수 있습니까?
C#에서 IronPDF를 사용하여 PDF에서 표를 추출할 수 있습니다. IronPDF를 사용하여 PDF 문서를 로드하고 텍스트를 추출한 다음, 프로그래밍 방식으로 텍스트를 행과 열로 구문 분석합니다.
PDF 문서에서 표 데이터를 추출하는 것이 왜 어려운가요?
PDF는 주로 데이터 구조보다는 표현을 위해 설계되어 있어, 표와 같은 구조화된 데이터를 추출하는 것이 어렵습니다. IronPDF와 같은 도구는 이 데이터를 효과적으로 해석하고 추출하는 데 도움을 줍니다.
PDF에서 표를 추출하는 것의 이점은 무엇입니까?
PDF에서 표를 추출하면 데이터 입력을 자동화하고, 데이터 분석을 수행하며, 문서를 보다 접근 가능하게 변환하고, 감사 프로세스에서의 규정 준수를 보장할 수 있습니다.
PDF 추출에서 복잡한 표 형식을 어떻게 처리합니까?
IronPDF는 복잡하고 불규칙한 표 형식에서도 정확한 데이터 추출을 보장하는 표 데이터 추출 및 처리 기능을 제공합니다.
PDF에서 추출한 표 데이터를 CSV로 변환하는 과정은 무엇입니까?
IronPDF를 사용하여 PDF에서 표 데이터를 추출하고 구문 분석한 후, StreamWriter를 사용하여 구문 분석한 데이터를 CSV 파일로 내보낼 수 있습니다.
PDF 표 추출의 모범 사례는 무엇입니까?
일관된 형식을 위해 PDF를 사전 처리하고, 추출된 데이터를 검증하며, 오류 처리 및 큰 PDF 파일을 다룰 때 성능을 최적화합니다.
IronPDF가 감사 및 규정 준수 작업에 도움이 될 수 있습니까?
예, IronPDF는 PDF의 표 데이터를 추출하여 Excel 또는 CSV와 같은 형식으로 변환할 수 있어, 데이터를 검토 및 분석하기 쉽게 만들어 감사 및 규정 준수에 도움이 됩니다.
IronPDF는 어떤 라이선스 옵션을 제공하나요?
IronPDF는 체험판을 포함하여 다양한 라이선스 옵션을 제공하므로, 전체 라이선스를 구매하기 전에 기능을 탐색할 수 있습니다.
PDF에서 표를 추출할 때 발생할 수 있는 일반적인 문제 해결 시나리오는 무엇입니까?
일반적인 문제로는 일관되지 않은 표 형식 및 텍스트 추출 오류가 있습니다. IronPDF의 강력한 기능을 사용하면 정확한 구문 분석 기능을 제공하여 이러한 문제를 완화할 수 있습니다.
IronPDF는.NET 10과 완전히 호환되며 표 추출 작업 흐름에 어떠한 이익을 줍니까?
예 — IronPDF는 .NET 10(및 .NET 9, 8, 7, 6, Core, Standard, Framework)을 지원하여 최신 .NET 10 프로젝트에서 구성 문제 없이 사용할 수 있습니다. .NET 10 기반으로 개발하는 개발자는 PDF 처리 및 표 추출 작업을 가속화하는 데 도움을 주는, 할당 감소 및 향상된 JIT 컴파일러 최적화와 같은 런타임 성능 개선의 이점을 얻습니다.











