
如何在C#中从PDF文件中提取表数据
在许多行业中,PDF文件是分享结构化文档(如报告、发票和数据表)的首选格式。 然而,从PDF中提取数据,特别是当涉及到表格时,由于PDF格式的特性,可能会有挑战。 与结构化数据格式不同,PDF主要是为展示而设计的,而不是数据提取。
然而,借助IronPDF,一个强大的C# PDF .NET库,您可以轻松地直接从PDF中提取表格等结构化数据,并在您的.NET应用程序中处理它们。 本文将一步步引导您如何使用IronPDF从PDF文件中提取表格数据。
您何时需要从PDF文档中提取表格?
无论是在进行库存管理、数据录入、记录降雨量等数据时,表格都是结构化和显示数据的便捷方式。因此,也可能有许多提取表格和表格数据的原因。 一些最常见的使用案例包括:
- 自动化数据录入: 从PDF报告或发票中的表格中提取数据可以自动化填充数据库或电子表格等流程。
- 数据分析: 企业通常会收到PDF格式的结构化报告。 提取表格可让您以编程方式分析这些数据。
- 文档转换: 将表格数据提取为更易访问的格式,如Excel或CSV,能够更容易地操作、存储和分享。
- 审计和合规: 对于法律或财务记录,以编程方式从PDF文档中提取表格数据可以帮助自动化审计并确保合规性。
PDF表格的工作原理是什么?
PDF文件格式不提供任何原生的能力来以表格等结构化格式存储数据。 在今天的例子中,我们使用HTML创建了表格,然后转换为PDF格式。 表格被渲染为文本和线条,因此提取表格数据通常需要一些解析和解释内容,除非您使用OCR软件,例如IronOCR。
How to Extract Table Data from a PDF File in C#
在我们探讨IronPDF如何完成这一任务之前,让我们先探讨一个在线PDF提取工具的操作。 要使用在线PDF工具从PDF文档中提取表格,请按照以下步骤操作:
- 导航到免费的在线PDF提取工具
- 上传包含表格的PDF
- 查看和下载结果
步骤一:导航至免费在线PDF提取工具
今天,我们将使用Docsumo作为我们的在线PDF工具示例。 Docsumo 是一个在线PDF文档AI,提供免费的PDF表格提取工具。
步骤二:上传包含表格的PDF
现在,点击"上传文件"按钮,上传您的PDF文件以进行提取。 该工具将立即开始处理您的PDF。
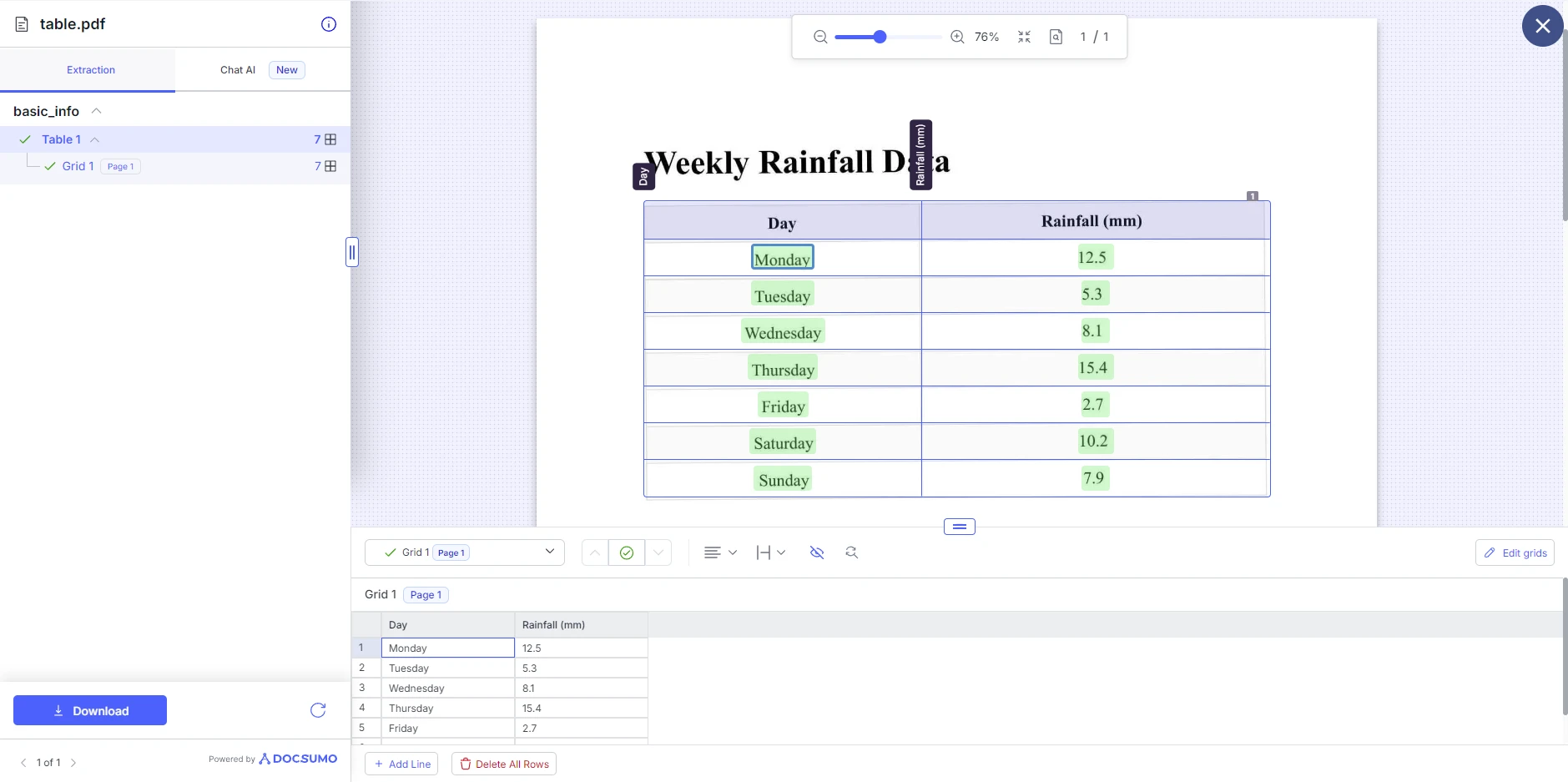
步骤三:查看和下载结果
一旦Docsumo处理完成PDF,它将显示提取的表格。 然后,您可以对表格结构进行调整,例如添加和删除行。 在这里,您可以将表格下载为另一个PDF、XLS、JSON或文本。
使用IronPDF提取表格数据
IronPDF 允许你从 PDF 中提取数据、文本和图形,然后可以用其编程地重建表格。 要做到这一点,您首先需要从PDF中的表格中提取文本内容,然后使用该文本将表格解析为行和列。 在我们开始提取表格之前,让我们看看IronPDF的ExtractAllText()方法如何通过提取表格中的数据来工作:
using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class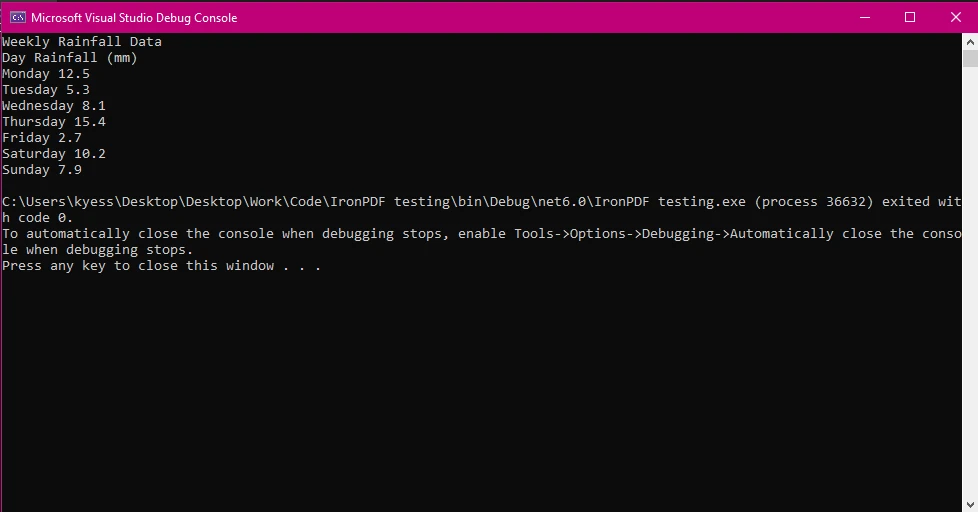
在这个例子中,我们使用PdfDocument类加载了PDF文档,然后使用了ExtractAllText()方法提取文档中的所有文本,最后在控制台上显示文本。
使用IronPDF从文本中提取表格数据
从PDF中提取文本后,表格将作为一系列行和列以纯文本形式出现。 您可以根据换行符(\n)拆分这些文本,然后根据一致的空格或分隔符(如逗号或制表符)进一步将行拆分为列。 以下是一个解析表格内容的基本示例:
using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPDF
Imports System
Imports System.Linq
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("table.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Split the text into lines (rows)
Dim lines() As String = text.Split(ControlChars.Lf)
For Each line As String In lines
' Split the line into columns using the tab character
Dim columns() As String = line.Split(ControlChars.Tab).Where(Function(col) Not String.IsNullOrWhiteSpace(col)).ToArray()
Console.WriteLine("Row:")
For Each column As String In columns
Console.WriteLine(" " & column) ' Output each column in the row
Next column
Next line
End Sub
End Class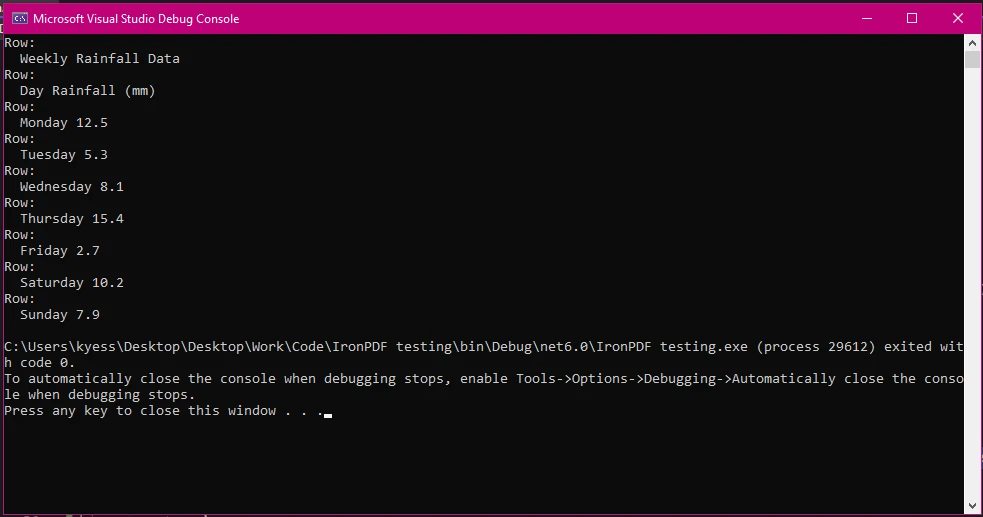
在这个例子中,我们按照之前的步骤一样加载我们的PDF文档并提取了文本。 然后,使用text.Split('\n')根据换行符将提取的文本拆分为行,并将结果存储在lines数组中。 然后使用foreach循环遍历数组中的行,其中line.Split('\t')用于采用制表符'\t'为分隔符进一步将行拆分为列。 列数组的下一部分,Where(col => !string.IsNullOrWhiteSpace(col)).ToArray()过滤掉由于额外空格可能出现的空列,然后将列添加到列数组中。
最后,我们在控制台输出窗口中写入具有基本行和列结构的文本。
将提取的表格数据导出为CSV
现在我们已经介绍了如何从PDF文件中提取表格,让我们看看可以用提取的数据做什么。 将提取的表格导出为CSV文件是处理表格数据和自动化任务(如数据录入)的一种有用方式。 在这个例子中,我们用模拟数据填充了一个表格,这种情况下是一周中的每日日降雨量,从PDF中提取了表格,然后将其导出为CSV文件。
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfPath As String = "table.pdf"
Dim csvPath As String = "output.csv"
' Extract and parse table data
Dim tableData = ExtractTableDataFromPdf(pdfPath)
' Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath)
Console.WriteLine($"Data extracted and saved to {csvPath}")
End Sub
Private Shared Function ExtractTableDataFromPdf(ByVal pdfPath As String) As List(Of String())
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract text from the first page
Dim text = pdf.ExtractTextFromPage(0)
Dim rows = New List(Of String())()
' Split text into lines (rows)
Dim lines = text.Split(ControlChars.Lf)
' Variable to hold column values temporarily
Dim tempColumns = New List(Of String)()
For Each line In lines
Dim trimmedLine = line.Trim()
' Check for empty lines or lines that don't contain table data
If String.IsNullOrEmpty(trimmedLine) OrElse trimmedLine.Contains("Header") Then
Continue For
End If
' Split line into columns. Adjust this based on how columns are separated.
Dim columns = trimmedLine.Split( { " "c, ControlChars.Tab }, StringSplitOptions.RemoveEmptyEntries)
If columns.Length > 0 Then
' Add columns to temporary list
tempColumns.AddRange(columns)
rows.Add(tempColumns.ToArray())
tempColumns.Clear() ' Clear temporary list after adding to rows
End If
Next line
Return rows
End Function
Private Shared Sub WriteDataToCsv(ByVal data As List(Of String()), ByVal csvPath As String)
Using writer = New StreamWriter(csvPath)
For Each row In data
' Join columns with commas and quote each field to handle commas within data
Dim csvRow = String.Join(",", row.Select(Function(field) $"""{field.Replace("""", """""")}"""))
writer.WriteLine(csvRow)
Next row
End Using
End Sub
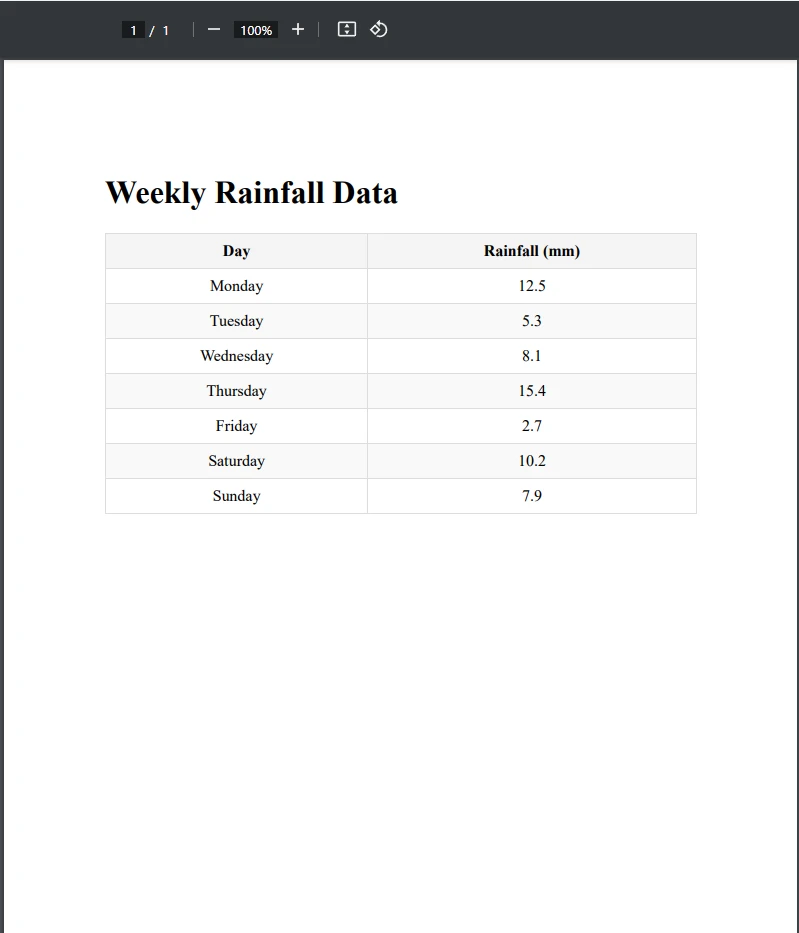
End ClassPDF文件示例
输出CSV文件
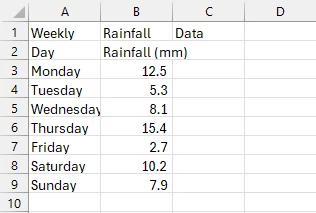
正如您所见,我们成功将PDF表格导出为CSV。首先,我们加载了包含表格的PDF并创建了新的CSV文件路径。 在此之后,我们使用var tableData = ExtractTableDataFromPdf(pdfPath)行提取了表格,调用了ExtractTableDataFromPdf()方法。 此方法提取了表格所在的PDF页面上的所有文本,并将其存储在text变量中。
然后,我们将文本拆分为行和列。 最后,在返回拆分结果后,我们调用方法static void WriteDataToCsv(),该方法接收提取的分割文本并使用StreamWriter将其写入我们的CSV文件。
提示和最佳实践
在处理PDF表格时,遵循一些基本的最佳实践可以帮助确保您将遇到错误或问题的机会降到最低。
- 预处理PDF: 如果可能,预处理您的PDF以确保一致的格式,从而简化提取过程。
- 验证数据: 始终验证提取的数据以确保准确性和完整性。
- 处理错误: 实施错误处理以管理文本提取或解析失败的情况,例如将您的代码包装在try-catch块中。
- 优化性能: 对于大型PDF,考虑优化文本提取和解析以处理性能问题。
IronPDF 许可
IronPDF提供了不同的许可选项,允许您在决定是否许可之前尝试IronPDF提供的所有强大功能。
结论
使用IronPDF从PDF中提取表格是一种自动化数据提取、促进分析和将文档转换为更易访问格式的强大方式。 无论是处理简单的表格还是复杂的不规则格式,IronPDF都提供了提取和处理表格数据所需的工具。
通过IronPDF,您可以简化诸如自动数据录入、文档转换和数据分析等工作流程。 IronPDF提供的灵活性和高级功能使其在处理各种基于PDF的任务中成为一件有价值的工具。
常见问题解答
如何使用 C# 从 PDF 中提取表格?
你可以使用 IronPDF 在 C# 中从 PDF 中提取表格。使用 IronPDF 加载 PDF 文档,提取文本,然后以编程方式将文本解析为行和列。
为什么从 PDF 文档中提取表格数据很困难?
PDF 主要设计用于展示而不是数据结构,这使得提取结构化的数据如表格变得具有挑战性。像 IronPDF 这样的工具有助于有效地解释和提取这些数据。
从 PDF 中提取表格有哪些好处?
从 PDF 中提取表格有助于自动化数据输入、执行数据分析、转换文档为更方便访问的格式,并确保在审计过程中符合要求。
你如何处理 PDF 提取中的复杂表格格式?
IronPDF 提供了从复杂和不规则的表格格式中提取和处理表格数据的能力,确保准确的数据提取。
将提取的 PDF 表格数据转换为 CSV 的过程是什么?
在使用 IronPDF 从 PDF 中提取和解析表格数据后,可以通过使用 StreamWriter 将解析的数据写入导出到 CSV 文件中。
PDF 表格提取的一些最佳实践是什么?
预处理 PDF 以获得一致的格式,验证提取的数据,实施错误处理,并在处理大型 PDF 文件时优化性能。
IronPDF 能在审计和合规任务中提供帮助吗?
是的,IronPDF 可以从 PDF 中提取表格数据并将其转换为 Excel 或 CSV 格式,帮助在审计和合规中使数据更易于审查和分析。
IronPDF提供哪些许可选项?
IronPDF 提供各种许可选项,包括试用版,因此你可以在购买正式许可证前探索其功能。
从 PDF 中提取表格时可能出现哪些常见故障排除场景?
常见问题包括不一致的表格格式和文本提取错误。使用 IronPDF 的强大功能可以通过提供准确的解析能力来帮助减轻这些挑战。
IronPDF 是否完全兼容 .NET 10?它如何使表格提取工作流程受益?
是的——IronPDF 支持 .NET 10(以及 .NET 9、8、7、6、Core、Standard 和 Framework),这意味着您可以在最新的 .NET 10 项目中使用它,而无需担心配置问题。基于 .NET 10 构建项目的开发人员可以受益于运行时性能的提升,例如减少内存分配和增强的 JIT 编译器优化,这些都有助于加快 PDF 处理和表格提取操作。













