

ASP .NET içinde PDF Nasıl Oluşturulur.
Birçok sektörde, PDF dosyaları raporlar, faturalar ve veri tabloları gibi yapılandırılmış belgeleri paylaşmak için tercih edilen formattır. Ancak, özellikle tablolar söz konusu olduğunda, PDF'lerden veri çıkarmak, PDF formatının doğası gereği zorlayıcı olabilir. Yapılandırılmış veri formatlarının aksine, PDF'ler öncelikle sunum için tasarlandığından, veri çıkarmak için değil.
Ancak, IronPDF gibi güçlü bir C# PDF .NET kütüphanesi ile tablolara doğrudan PDF'lerden kolayca yapılandırılmış veri çıkarabilir ve .NET uygulamalarınızda işleyebilirsiniz. Bu makale, IronPDF kullanarak PDF dosyalarından tabloları nasıl çıkartacağınızı adım adım rehberlik edecek.
PDF Belgelerinden Tabloları Ne Zaman Çıkartmanız Gerekir?
Stok yönetimi, veri girişi, yağış gibi verilerin kaydını tutma gibi işlemler yapıyor olun, tablolar verilerinizi yapılandırma ve görüntüleme açısından kullanışlıdır. Dolayısıyla, PDF belgelerinden tabloları ve tablodaki verileri çıkarmanız gerekmesinin birçok nedeni olabilir. En yaygın kullanım durumlarından bazıları şunlardır:
Veri girişini otomatikleştirme: PDF raporlarındaki veya faturalarındaki tablolardan veri çıkarmak, veritabanları veya hesap tablolarına veri doldurma gibi süreçleri otomatikleştirebilir. Veri analizi: İşletmeler genellikle PDF formatında yapılandırılmış raporlar alır. Tabloları çıkarmak, bu verileri programatik olarak analiz etmenizi sağlar. Belge dönüştürme: Tablolu verileri Excel veya CSV gibi daha erişilebilir formatlara çıkarmak, daha kolay manipülasyon, depolama ve paylaşım sağlar. Denetim ve uyumluluk: Hukuki veya finansal kayıtlar için, PDF belgelerinden programatik olarak tablolu veri çıkarmak, denetimleri otomatikleştirmeye ve uyumluluğu sağlamaya yardımcı olabilir.
PDF Tabloları Nasıl Çalışır?
PDF dosya formatı, tablolar gibi yapılandırılmış formatlarda veri saklamak için yerel bir yetenek sunmaz. Bugünkü örnekte kullandığımız tablo HTML'de oluşturuldu, ardından PDF formatına dönüştürüldü. Tablolar metin ve çizgiler olarak rendere edilir, bu nedenle tablo verilerini çıkartmak genellikle içeriklerin bir kısmının ne olduğunun analizini ve anlamasını gerektirir, aksi takdirde IronOCR gibi bir OCR yazılımı kullanılmalıdır.
How to Extract Table Data from a PDF File in C
IronPDF'nin bu görevi nasıl üstesinden gelebileceğini incelemeden önce, PDF çıkarma işlemiyle başa çıkabilecek çevrimiçi bir aracı inceleyelim. PDF belgesinden bir tabloyu çevrimiçi PDF aracı kullanarak çıkartmak için aşağıda belirttiğimiz adımları takip edin:
- Ücretsiz çevrimiçi PDF çıkarma aracına gidin
- Tabloyu içeren PDF'yi yükleyin
- Sonuçları görüntüleyin ve indirin
Birinci Adım: Ücretsiz Çevrimiçi PDF Çıkarma Araçına Git
Bugün çevrimiçi PDF aracı örneğimiz olarak Docsumo'yu kullanacağız. Docsumo, ücretsiz bir PDF tablo çıkarma aracı sunan bir çevrimiçi PDF belge yapay zeka aracıdır.
İkinci Adım: Tabloyu İçeren PDF'yi Yükle
Şimdi, çıkartmak için PDF dosyanızı yüklemek için 'Dosya Yükle' butonuna tıklayın. Araç, PDF'nizi hemen işlemeye başlayacaktır.
Üçüncü Adım: Sonuçları Görüntüle ve İndir
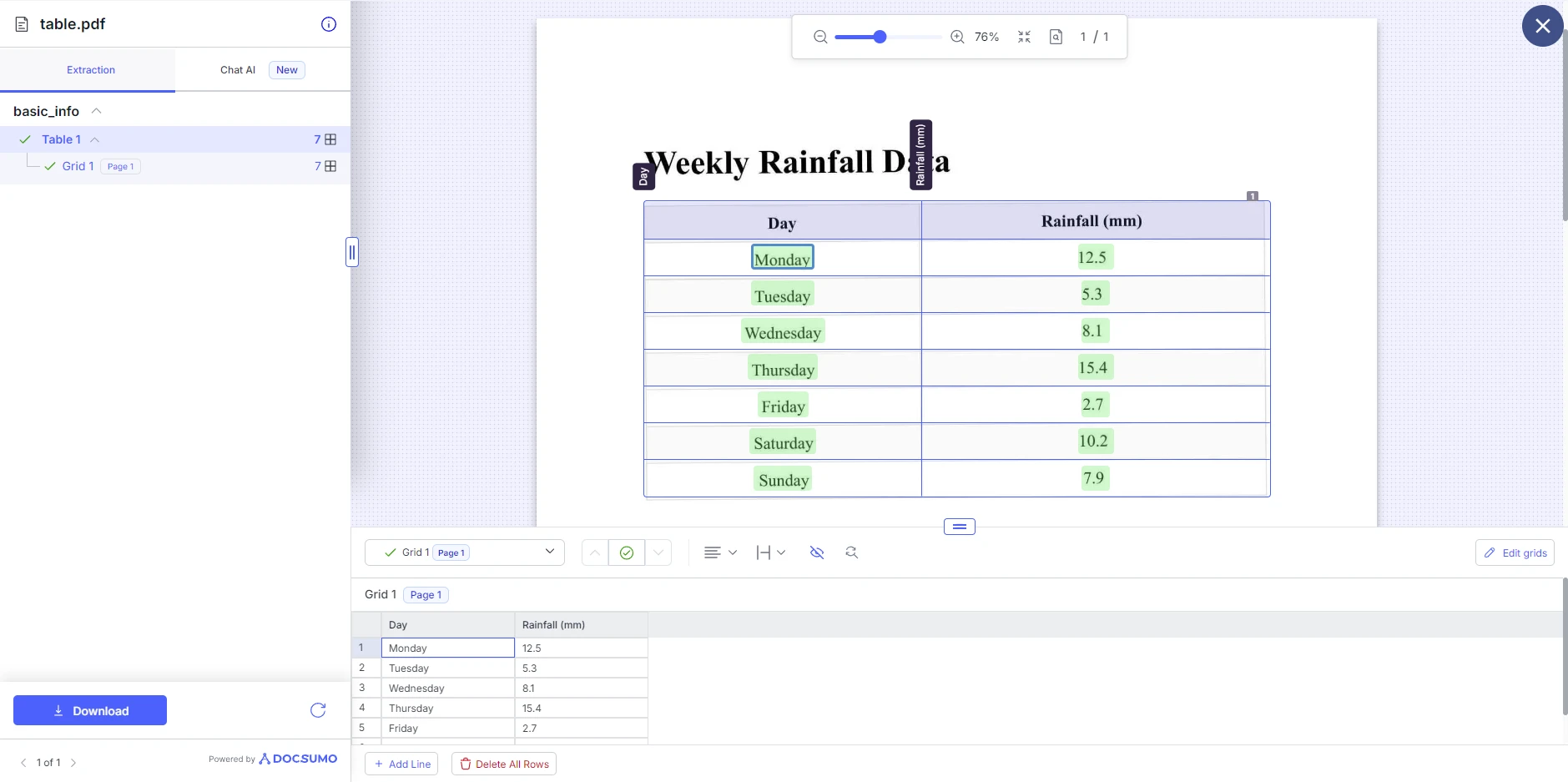
Docsumo, PDF'yi işlemi tamamladığında, çıkarılan tabloyu gösterecektir. Daha sonra, satır ekleme ve kaldırma gibi tablo yapısına ayarlamalar yapabilirsiniz. Burada, tabloyu başka bir PDF, XLS, JSON veya Metin olarak indirebilirsiniz.
Demoyu IronPDF ile Uygulama
IronPDF, PDF'lerden veri, metin ve grafik çıkarımına izin verir, bu da daha sonra programatik olarak tabloyu yeniden yapılandırmada kullanılabilir. Bunu yapmak için önce PDF'deki tablodan metni çıkarmanız gerekecek ve ardından bu metni, satırlara ve sütunlara ayrıştırarak tablo haline getirmelisiniz. IronPDF'in ExtractAllText() metodunun tablo içerisindeki verileri çıkartarak nasıl çalıştığını görelim:
using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class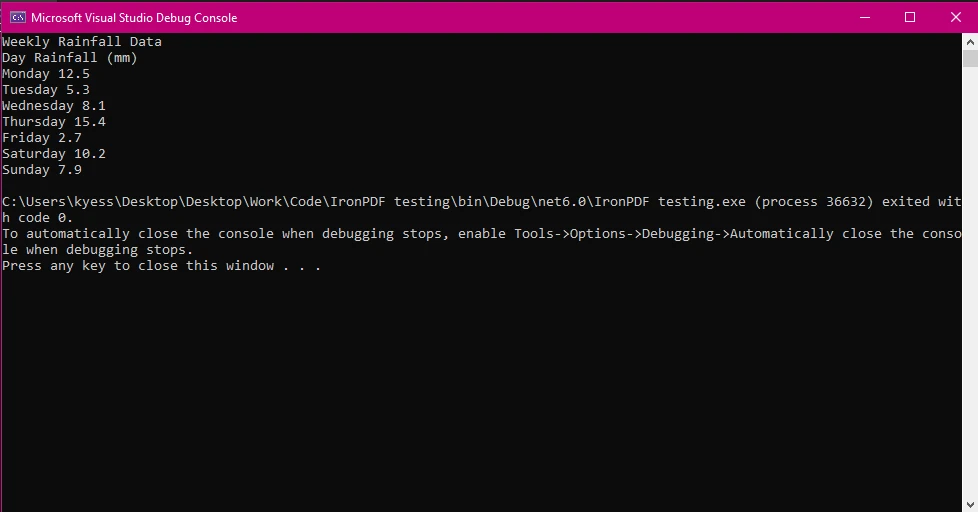
Bu örnekte, PDF belgesini PdfDocument sınıfı ile yükledik ve ardından belgedeki tüm metni çıkartmak için ExtractAllText() metodu kullanıldı, son olarak metin konsolda gösterildi.
IronPDF Kullanarak Metinle Tablo Verisi Çıkartma
PDF'den metin çıkardıktan sonra, tablo düz metin olarak bir dizi satırlar ve sütunlar olarak görünecektir. Bu metni satır kırılmalarına (\n) göre ayırabilir ve daha sonra satırları, virgül veya sekmeler gibi sabit aralıklı veya ayırıcılar kullanarak sütunlara ayırabilirsiniz. Metinden tabloyu almanın temel bir örneği aşağıda verilmiştir:
using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPDF
Imports System
Imports System.Linq
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("table.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Split the text into lines (rows)
Dim lines() As String = text.Split(ControlChars.Lf)
For Each line As String In lines
' Split the line into columns using the tab character
Dim columns() As String = line.Split(ControlChars.Tab).Where(Function(col) Not String.IsNullOrWhiteSpace(col)).ToArray()
Console.WriteLine("Row:")
For Each column As String In columns
Console.WriteLine(" " & column) ' Output each column in the row
Next column
Next line
End Sub
End Class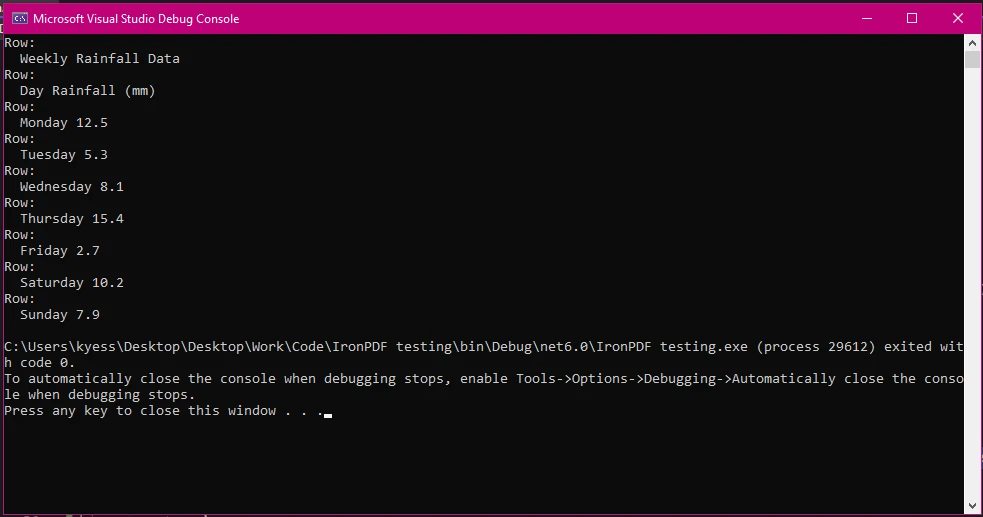
Bu örnekte, PDF belgemizi yükleme ve metni çıkarma için daha önceki adımları takip ettik. Ardından, text.Split('\n') kullanarak çıkarılan metni satırlara böler ve sonuçları lines dizisine kaydederiz. Bir foreach döngüsü daha sonra dizinin satırları üzerinde dolaşmak için kullanılır ve burada line.Split('\t') tablo karakteri '\t' ayırıcı olarak kullanılarak satırları sütunlara daha fazla ayırır. Sütunlar dizisinin bir sonraki bölümü, Where(col => !string.IsNullOrWhiteSpace(col)).ToArray() ekstra boşluklardan kaynaklanabilecek boş sütunları filtreler ve sonra sütunları diziye ekler.
Son olarak, temel satır ve sütun yapısı ile metni konsol çıkış penceresine yazarız.
Çıkarılan Tablo Verisini CSV'ye Aktarma
Artık PDF dosyalarından tabloları nasıl çıkartacağımızı ele aldığımıza göre, çıkarılan veriyle yapabileceklerimize bir göz atalım. Tabloyu bir CSV dosyası olarak dışa aktarmak, tablo verilerini işlemek ve veri girişini otomatikleştirmek gibi görevleri kolaylaştırma açısından kullanışlı bir yoldur. Bu örnekte, bir hafta boyunca günlük yağış miktarını simüle edilmiş verilerle bir tablo doldurduk, tabloyu PDF'den çıkardık ve ardından bir CSV dosyasına aktardık.
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfPath As String = "table.pdf"
Dim csvPath As String = "output.csv"
' Extract and parse table data
Dim tableData = ExtractTableDataFromPdf(pdfPath)
' Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath)
Console.WriteLine($"Data extracted and saved to {csvPath}")
End Sub
Private Shared Function ExtractTableDataFromPdf(ByVal pdfPath As String) As List(Of String())
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract text from the first page
Dim text = pdf.ExtractTextFromPage(0)
Dim rows = New List(Of String())()
' Split text into lines (rows)
Dim lines = text.Split(ControlChars.Lf)
' Variable to hold column values temporarily
Dim tempColumns = New List(Of String)()
For Each line In lines
Dim trimmedLine = line.Trim()
' Check for empty lines or lines that don't contain table data
If String.IsNullOrEmpty(trimmedLine) OrElse trimmedLine.Contains("Header") Then
Continue For
End If
' Split line into columns. Adjust this based on how columns are separated.
Dim columns = trimmedLine.Split( { " "c, ControlChars.Tab }, StringSplitOptions.RemoveEmptyEntries)
If columns.Length > 0 Then
' Add columns to temporary list
tempColumns.AddRange(columns)
rows.Add(tempColumns.ToArray())
tempColumns.Clear() ' Clear temporary list after adding to rows
End If
Next line
Return rows
End Function
Private Shared Sub WriteDataToCsv(ByVal data As List(Of String()), ByVal csvPath As String)
Using writer = New StreamWriter(csvPath)
For Each row In data
' Join columns with commas and quote each field to handle commas within data
Dim csvRow = String.Join(",", row.Select(Function(field) $"""{field.Replace("""", """""")}"""))
writer.WriteLine(csvRow)
Next row
End Using
End Sub
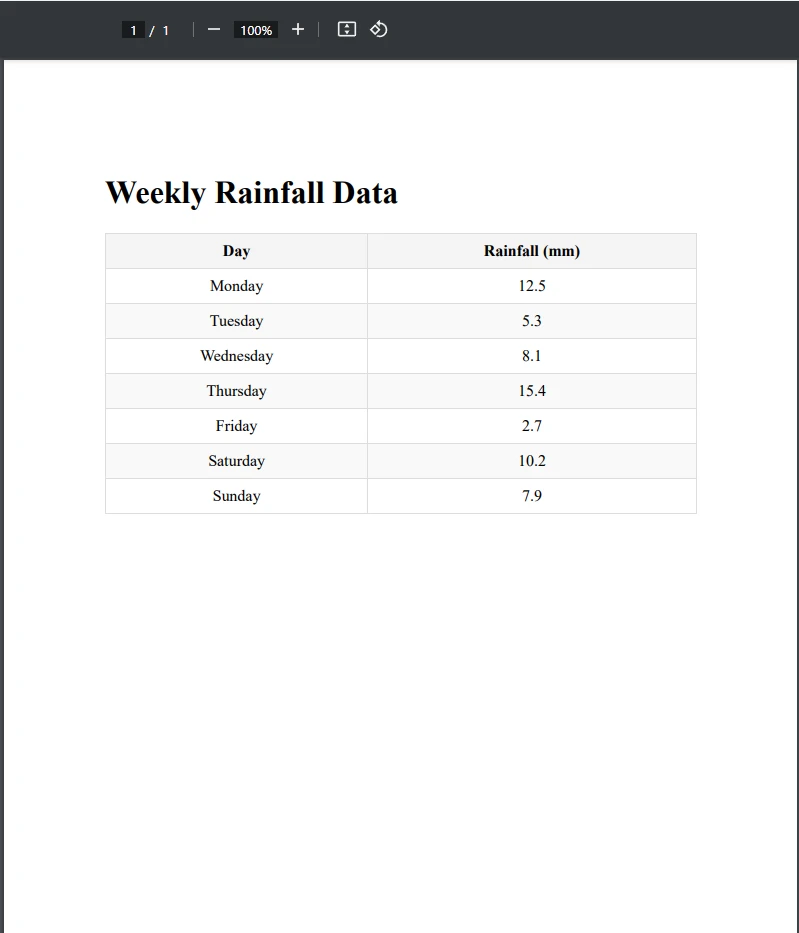
End ClassÖrnek PDF Dosyası
Çıktı CSV Dosyası
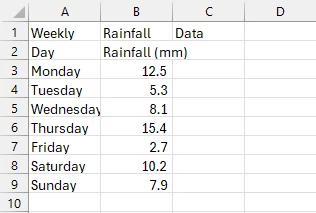
Gördüğünüz gibi, PDF tablosunu başarıyla CSV'ye aktardık. İlk olarak, tabloyu içeren PDF'yi yükledik ve yeni bir CSV dosya yolu oluşturduk. Bundan sonra, tabloyu var tableData = ExtractTableDataFromPdf(pdfPath) satırı ile çıkardık, bu ExtractTableDataFromPdf() metodunun çağrıldığı yer. Bu yöntem, tablonun bulunduğu PDF sayfasında bulunan tüm metni çıkarır ve onları metin değişkeninde depolar.
Daha sonra, metni satırlara ve sütunlara böldük. Son olarak, bu bölme işleminden sonucu döndürdükten sonra, static void WriteDataToCsv() metodunu çağırırız, bu yöntem çıkarılan ve bölünmüş metni alarak StreamWriter kullanarak CSV dosyamıza yazar.
İpuçları ve En İyi Uygulamalar
PDF tablolarıyla çalışırken, bazı temel en iyi uygulamaları takip etmek, herhangi bir hata veya sorunla karşılaşma olasılığınızı minimize etmenizi sağlar.
PDF'leri önceden işleyin: Mümkünse, PDF'lerinizi tutarlı bir biçimlendirme sağlamak için önceden işleyin, bu durum çıkarma sürecini kolaylaştırır. Veriyi doğrulayın: Doğruluk ve eksiksizliği sağlamak için her zaman çıkarılan veriyi doğrulayın. Hataları yönetin: Metin çıkarma veya ayrıştırma başarısız olduğunda, try-catch bloğuna kodunuzu sarmak gibi hata yönetimini uygulayın. Performansı optimize edin: Büyük PDF'ler için metin çıkarımı ve ayrıştırmayı optimize ederek performans sorunlarını ele almayı düşünün.
IronPDF Lisanslama
IronPDF, lisansın halledilmesinden önce IronPDF'in sunduğu tüm güçlü özellikleri kendiniz denemenize olanak tanıyan farklı lisanslama seçenekleri sunar.
Sonuç
PDF'lerden IronPDF kullanarak tablolar çıkarmak, veri çıkarımını otomatikleştirmenin, analize olanak sağlamanın ve belgeleri daha erişilebilir formatlara dönüştürmenin güçlü bir yoludur. Basit tablo içeriği ile karmaşık, düzensiz formatlarla ilgileniyor olun, IronPDF, tablo verisini verimli bir şekilde çıkarmak ve işlemek için gereken araçları sağlar.
IronPDF ile otomatik veri girişi, belge dönüşümü ve veri analizi gibi iş akışlarını kolaylaştırabilirsiniz. IronPDF'in sunduğu esneklik ve gelişmiş özellikler, PDF tabanlı çeşitli görevleri ele almakta değerli bir araç yapar.
Sıkça Sorulan Sorular
C# kullanarak PDF'den tabloları nasıl çıkarırım?
IronPDF'i kullanarak C# dilinde PDF'den tabloları çıkarabilirsiniz. IronPDF'i kullanarak PDF belgesini yükleyin, metni çıkarın ve ardından metni programatik olarak satırlara ve sütunlara dönüştürün.
PDF belgelerinden tablo verilerini çıkarmak neden zordur?
PDF'ler, verinin sunumu için tasarlanmıştır ama yapılandırması için tasarlanmamıştır bu da tablolar gibi yapılandırılmış verilerin çıkarılmasını zorlaştırır. IronPDF gibi araçlar, bu verileri etkin bir şekilde yorumlamayı ve çıkarmayı sağlar.
PDF'lerden tablo çıkarımının faydaları nelerdir?
PDF'lerden tabloları çıkarmak, veri girişini otomatikleştirmeyi, veri analizini gerçekleştirmeyi, belgeleri daha erişilebilir formatlara dönüştürmeyi ve denetim süreçlerinde uyumu sağlamayı kolaylaştırır.
PDF çıkarımında karmaşık tablo formatlarını nasıl işliyorsunuz?
IronPDF, doğruluğu sağlamak için karmaşık ve düzensiz tablo formatlarından bile tablo verilerini çıkarmak ve işlemek için olanaklar sunar.
Çıkarılan PDF tablo verilerini CSV'ye dönüştürme işlemi nedir?
IronPDF kullanarak PDF'den tablo verilerini çıkardıktan sonra, bir StreamWriter kullanarak ayrıştırılmış verileri yazarak bu verileri bir CSV dosyasına ihraç edebilirsiniz.
PDF tablo çıkarımı için en iyi uygulamalar nelerdir?
Tutarlı formatlandırma için PDF'leri ön işleme, çıkarılan verileri doğrulama, hata işlme uygulama ve büyük PDF dosyalarıyla çalışırken performansı optimize etme.
IronPDF, denetim ve uyum görevlerinde yardımcı olabilir mi?
Evet, IronPDF, PDF'lerden tablo verilerini çıkarıp Excel veya CSV gibi formatlara dönüştürerek denetim ve uyum süreçlerine yardımcı olur, gözden geçirme ve analiz için verileri daha erişilebilir hale getirir.
IronPDF hangi lisans seçeneklerini sunar?
IronPDF, özelliklerini keşfetmek üzere tam lisans satın almadan önce deneme sürümleri dahil çeşitli lisanslama seçenekleri sunar.
PDF’lerden tablo çıkarımı sırasında yaşanabilecek yaygın sorun giderme senaryoları nelerdir?
Yaygın sorunlar arasında tutarsız tablo formatlaması ve metin çıkarma hataları bulunur. IronPDF’in sağlam özelliklerini kullanmak, doğru ayrıştırma yetenekleri sağlayarak bu zorlukları hafifletmeye yardımcı olabilir.
IronPDF .NET 10 ile tamamen uyumlu mu ve bu durum tablo çıkarma iş akışlarına nasıl katkı sağlamaktadır?
Evet - IronPDF, .NET 10 (ile .NET 9, 8, 7, 6, Core, Standard ve Framework) desteği sağlar, bu da onu en son .NET 10 projelerinde yapılandırma sorunları olmadan kullanabileceğiniz anlamına gelir. .NET 10'a dayalı olarak geliştirenler, hızlanan PDF işleme ve tablo çıkarma operasyonlarında, çalışma zamanı performans artışları gibi azaltılmış tahsislerden ve gelişmiş JIT derleyici optimizasyonlarından yararlanırlar.











