

Como criar um PDF em ASP.NET
Em muitos setores, os arquivos PDF são o formato preferido para compartilhar documentos estruturados, como relatórios, faturas e tabelas de dados. No entanto, extrair dados de PDFs, especialmente quando se trata de tabelas, pode ser um desafio devido à natureza do formato PDF. Ao contrário dos formatos de dados estruturados, os PDFs são projetados principalmente para apresentação, não para extração de dados.
No entanto, com o IronPDF , uma poderosa biblioteca C# para PDF em .NET , você pode facilmente extrair dados estruturados, como tabelas, diretamente de PDFs e processá-los em seus aplicativos .NET . Este artigo irá guiá-lo passo a passo sobre como extrair dados tabulares de arquivos PDF usando o IronPDF.
Quando você precisaria extrair tabelas de documentos PDF?
As tabelas são uma maneira prática de estruturar e exibir seus dados, seja para gerenciamento de estoque, entrada de dados, registro de dados como precipitação, etc. Portanto, pode haver muitos motivos para precisar extrair tabelas e dados de tabelas de documentos PDF. Alguns dos casos de uso mais comuns incluem:
- Automatização da entrada de dados: Extrair dados de tabelas em relatórios em PDF ou faturas pode automatizar processos como o preenchimento de bancos de dados ou planilhas.
- Análise de dados: As empresas geralmente recebem relatórios estruturados em formato PDF. A extração de tabelas permite analisar esses dados programaticamente.
- Conversão de documentos: Extrair dados tabulares para formatos mais acessíveis, como Excel ou CSV, facilita a manipulação, o armazenamento e o compartilhamento.
- Auditoria e conformidade: Para registros legais ou financeiros, a extração programática de dados tabulares de documentos PDF pode ajudar a automatizar auditorias e garantir a conformidade.
Como funcionam as tabelas em PDF?
O formato de arquivo PDF não oferece nenhuma capacidade nativa de armazenar dados em formatos estruturados, como tabelas. A tabela que usamos no exemplo de hoje foi criada em HTML, antes de ser convertida para o formato PDF . As tabelas são representadas como texto e linhas, portanto, a extração de dados de tabelas geralmente requer alguma análise e interpretação do conteúdo, a menos que você esteja usando um software de OCR, como o IronOCR .
How to Extract Table Data from a PDF File in C
Antes de explorarmos como o IronPDF pode lidar com essa tarefa, vamos primeiro explorar uma ferramenta online capaz de extrair PDFs. Para extrair uma tabela de um documento PDF usando uma ferramenta online de PDF, siga os passos descritos abaixo:
- Acesse a ferramenta gratuita de extração de PDF online.
- Faça o upload do PDF contendo a tabela.
- Veja e baixe os resultados.
Primeiro passo: acesse a ferramenta gratuita de extração de PDF online.
Hoje, usaremos o Docsumo como exemplo de ferramenta online para criação de PDFs. Docsumo é uma IA online para documentos PDF que oferece uma ferramenta gratuita para extração de tabelas de PDFs.
Passo Dois: Carregue o PDF contendo a tabela.
Agora, clique no botão "Carregar arquivo" para enviar seu arquivo PDF para extração. A ferramenta começará imediatamente a processar seu PDF.
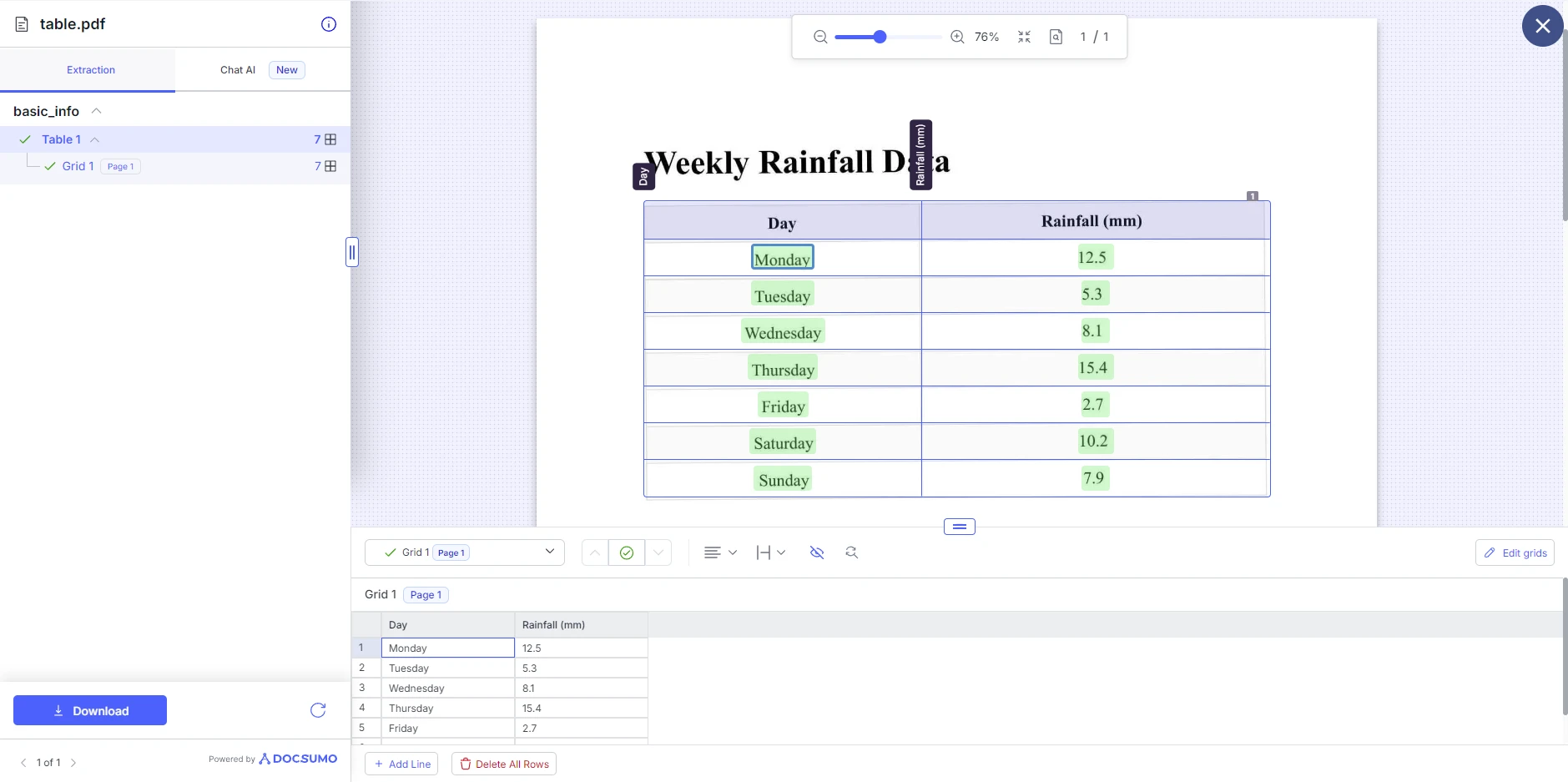
Passo Três: Visualize e baixe os resultados
Assim que o Docsumo terminar de processar o PDF, ele exibirá a tabela extraída. Em seguida, você pode fazer ajustes na estrutura da tabela, como adicionar e remover linhas. Aqui, você pode baixar a tabela em formato PDF, XLS, JSON ou texto.
Extrair dados de tabelas usando o IronPDF
O IronPDF permite extrair dados, texto e gráficos de PDFs, que podem então ser usados para reconstruir tabelas programaticamente. Para isso, primeiro você precisará extrair o conteúdo textual da tabela no PDF e, em seguida, usar esse texto para analisar a tabela em linhas e colunas. Antes de começarmos a extrair tabelas, vamos dar uma olhada em como o método ExtractAllText() do IronPDF funciona, extraindo os dados de uma tabela:
using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class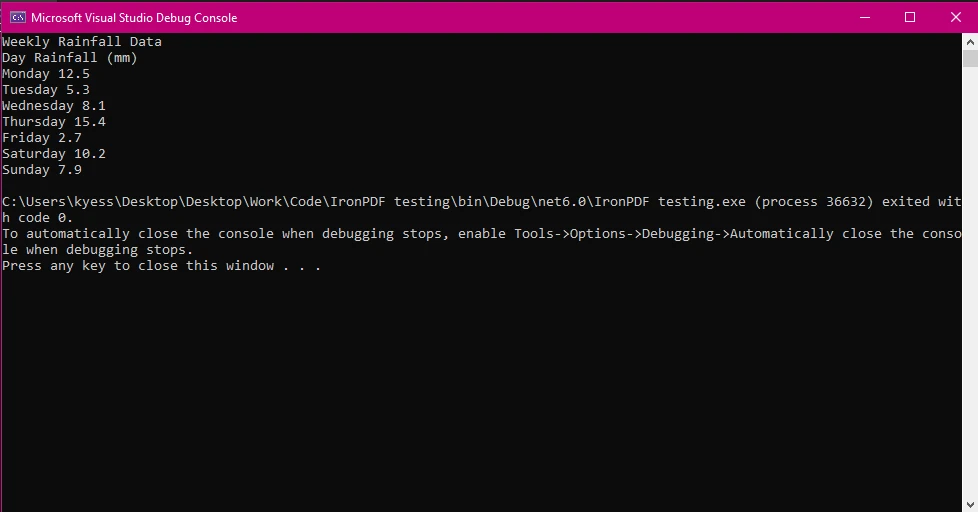
Neste exemplo, carregamos o documento PDF usando a classe PdfDocument e, em seguida, usamos o método ExtractAllText() para extrair todo o texto do documento, antes de finalmente exibi-lo no console.
Extraindo dados de tabelas de texto usando o IronPDF
Após extrair o texto do PDF, a tabela aparecerá como uma série de linhas e colunas em texto simples. Você pode dividir este texto com base em quebras de linha ( \n ) e, em seguida, dividir ainda mais as linhas em colunas com base em espaçamento consistente ou delimitadores, como vírgulas ou tabulações. Aqui está um exemplo básico de como analisar a tabela a partir do texto:
using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPDF
Imports System
Imports System.Linq
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("table.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Split the text into lines (rows)
Dim lines() As String = text.Split(ControlChars.Lf)
For Each line As String In lines
' Split the line into columns using the tab character
Dim columns() As String = line.Split(ControlChars.Tab).Where(Function(col) Not String.IsNullOrWhiteSpace(col)).ToArray()
Console.WriteLine("Row:")
For Each column As String In columns
Console.WriteLine(" " & column) ' Output each column in the row
Next column
Next line
End Sub
End Class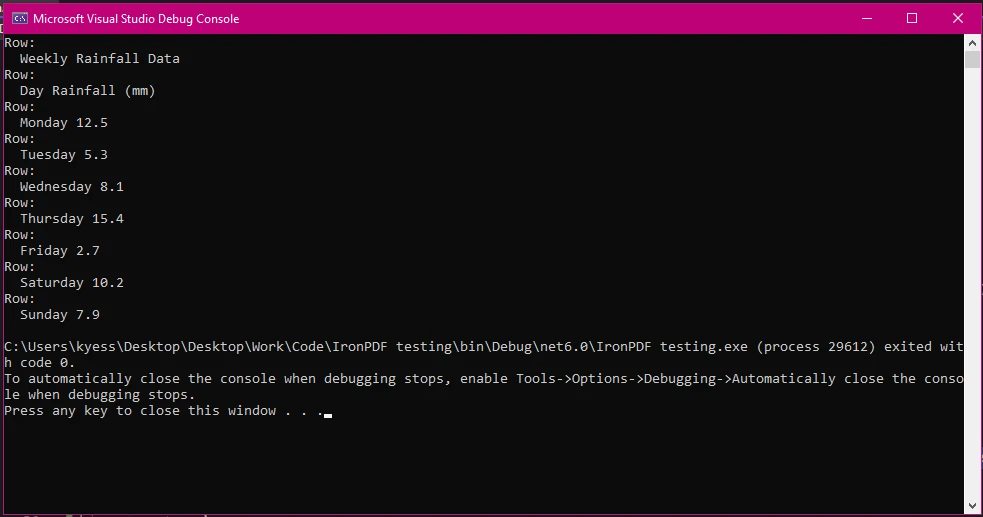
Neste exemplo, seguimos os mesmos passos de antes para carregar nosso documento PDF e extrair o texto. Em seguida, usando text.Split('\n'), dividimos o texto extraído em linhas com base nas quebras de linha e armazenamos os resultados na matriz lines . Em seguida, um loop foreach é usado para percorrer as linhas da matriz, onde line.Split('\t') é usado para dividir ainda mais as linhas em colunas usando o caractere de tabulação '\t' como delimitador. A próxima parte da matriz de colunas, Where(col => !string.IsNullOrWhiteSpace(col)).ToArray() filtra colunas vazias que podem surgir devido a espaços extras e, em seguida, adiciona as colunas à matriz de colunas.
Finalmente, escrevemos o texto na janela de saída do console com estrutura básica de linhas e colunas.
Exportando dados extraídos da tabela para CSV
Agora que já vimos como extrair tabelas de arquivos PDF, vamos dar uma olhada no que podemos fazer com esses dados extraídos. Exportar a tabela exportada como um arquivo CSV é uma maneira útil de lidar com dados de tabelas e automatizar tarefas como a entrada de dados. Neste exemplo, preenchemos uma tabela com dados simulados, neste caso, a quantidade diária de chuva em uma semana, extraímos a tabela do PDF e, em seguida, exportamos para um arquivo CSV.
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfPath As String = "table.pdf"
Dim csvPath As String = "output.csv"
' Extract and parse table data
Dim tableData = ExtractTableDataFromPdf(pdfPath)
' Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath)
Console.WriteLine($"Data extracted and saved to {csvPath}")
End Sub
Private Shared Function ExtractTableDataFromPdf(ByVal pdfPath As String) As List(Of String())
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract text from the first page
Dim text = pdf.ExtractTextFromPage(0)
Dim rows = New List(Of String())()
' Split text into lines (rows)
Dim lines = text.Split(ControlChars.Lf)
' Variable to hold column values temporarily
Dim tempColumns = New List(Of String)()
For Each line In lines
Dim trimmedLine = line.Trim()
' Check for empty lines or lines that don't contain table data
If String.IsNullOrEmpty(trimmedLine) OrElse trimmedLine.Contains("Header") Then
Continue For
End If
' Split line into columns. Adjust this based on how columns are separated.
Dim columns = trimmedLine.Split( { " "c, ControlChars.Tab }, StringSplitOptions.RemoveEmptyEntries)
If columns.Length > 0 Then
' Add columns to temporary list
tempColumns.AddRange(columns)
rows.Add(tempColumns.ToArray())
tempColumns.Clear() ' Clear temporary list after adding to rows
End If
Next line
Return rows
End Function
Private Shared Sub WriteDataToCsv(ByVal data As List(Of String()), ByVal csvPath As String)
Using writer = New StreamWriter(csvPath)
For Each row In data
' Join columns with commas and quote each field to handle commas within data
Dim csvRow = String.Join(",", row.Select(Function(field) $"""{field.Replace("""", """""")}"""))
writer.WriteLine(csvRow)
Next row
End Using
End Sub
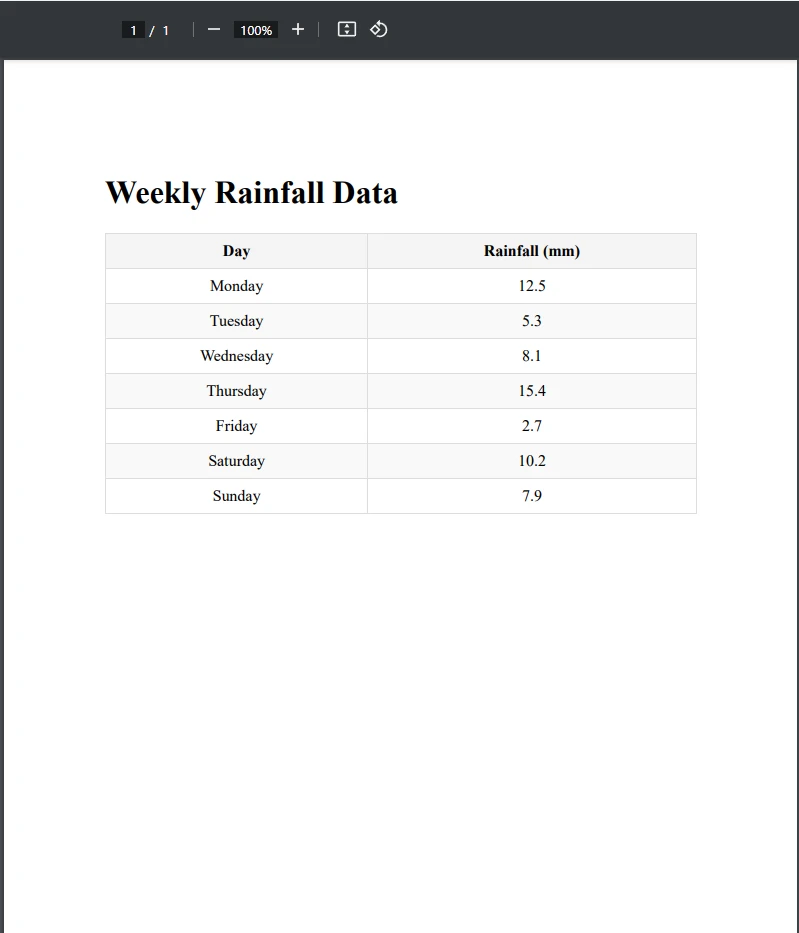
End ClassArquivo PDF de exemplo
Arquivo CSV de saída
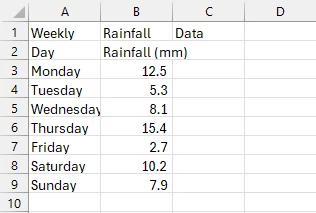
Como você pode ver, exportamos com sucesso a tabela do PDF para CSV. Primeiro, carregamos o PDF contendo a tabela e criamos um novo caminho de arquivo CSV. Depois disso, extraímos a tabela usando a linha var tableData = ExtractTableDataFromPdf(pdfPath) , que é chamada de método ExtractTableDataFromPdf() . Este método extrai todo o texto da página do PDF onde a tabela está localizada, armazenando-o na variável de texto .
Em seguida, dividimos o texto em linhas e colunas. Finalmente, após retornar o resultado desse processo de divisão, chamamos o método estático void WriteDataToCsv() que pega o texto extraído e dividido e o escreve em nosso arquivo CSV usando StreamWriter .
Dicas e boas práticas
Ao trabalhar com tabelas em PDF, seguir algumas boas práticas básicas pode ajudar a minimizar a probabilidade de erros ou problemas.
- Pré-processamento de PDFs: Se possível, pré-processe seus PDFs para garantir uma formatação consistente, o que simplifica o processo de extração.
- Validar dados: Sempre valide os dados extraídos para garantir precisão e integridade.
- Tratamento de erros: Implemente o tratamento de erros para lidar com casos em que a extração ou análise de texto falha, como por exemplo, envolvendo seu código em um bloco try-catch.
- Otimize o desempenho: Para PDFs grandes, considere otimizar a extração e a análise de texto para lidar com problemas de desempenho.
Licenciamento IronPDF
A IronPDF oferece diferentes opções de licenciamento , permitindo que você experimente todos os recursos poderosos que a IronPDF oferece antes de se comprometer com uma licença.
Conclusão
Extrair tabelas de PDFs usando o IronPDF é uma maneira poderosa de automatizar a extração de dados, facilitar a análise e converter documentos em formatos mais acessíveis. Seja lidando com tabelas simples ou formatos complexos e irregulares, o IronPDF fornece as ferramentas necessárias para extrair e processar dados tabulares de forma eficiente.
Com o IronPDF, você pode otimizar fluxos de trabalho como entrada automatizada de dados, conversão de documentos e análise de dados. A flexibilidade e os recursos avançados oferecidos pelo IronPDF o tornam uma ferramenta valiosa para lidar com diversas tarefas baseadas em PDF.
Perguntas frequentes
Como posso extrair tabelas de um PDF usando C#?
Você pode usar o IronPDF para extrair tabelas de um PDF em C#. Carregue o documento PDF usando o IronPDF, extraia o texto e, em seguida, analise o texto em linhas e colunas programaticamente.
Por que é difícil extrair dados de tabelas de documentos PDF?
Os PDFs são projetados principalmente para apresentação, e não para estrutura de dados, o que torna a extração de dados estruturados, como tabelas, um desafio. Ferramentas como o IronPDF ajudam a interpretar e extrair esses dados com eficiência.
Quais são os benefícios de extrair tabelas de PDFs?
A extração de tabelas de PDFs facilita a automatização da entrada de dados, a realização de análises de dados, a conversão de documentos para formatos mais acessíveis e a garantia de conformidade nos processos de auditoria.
Como lidar com formatos de tabela complexos na extração de PDFs?
O IronPDF oferece recursos para extrair e processar dados de tabelas, mesmo em formatos complexos e irregulares, garantindo uma extração de dados precisa.
Qual é o processo para converter dados extraídos de uma tabela PDF em CSV?
Após extrair e analisar os dados da tabela de um PDF usando o IronPDF, você pode exportar esses dados para um arquivo CSV gravando os dados analisados usando um StreamWriter .
Quais são as melhores práticas para extração de tabelas em PDF?
Pré-processar PDFs para formatação consistente, validar dados extraídos, implementar tratamento de erros e otimizar o desempenho ao lidar com arquivos PDF grandes.
O IronPDF pode ajudar em tarefas de auditoria e conformidade?
Sim, o IronPDF pode extrair dados tabulares de PDFs e convertê-los para formatos como Excel ou CSV, auxiliando na auditoria e conformidade, tornando os dados mais acessíveis para revisão e análise.
Quais são as opções de licenciamento oferecidas pelo IronPDF?
O IronPDF oferece diversas opções de licenciamento, incluindo versões de avaliação, para que você possa explorar seus recursos antes de adquirir uma licença completa.
Quais são os cenários comuns de resolução de problemas que podem surgir ao extrair tabelas de PDFs?
Problemas comuns incluem formatação inconsistente de tabelas e erros de extração de texto. O uso dos recursos robustos do IronPDF pode ajudar a mitigar esses desafios, fornecendo capacidades de análise precisas.
O IronPDF é totalmente compatível com o .NET 10 e como isso beneficia os fluxos de trabalho de extração de tabelas?
Sim, o IronPDF é compatível com o .NET 10 (assim como com o .NET 9, 8, 7, 6, Core, Standard e Framework), o que significa que você pode usá-lo nos projetos .NET 10 mais recentes sem problemas de configuração. Os desenvolvedores que criam projetos no .NET 10 se beneficiam de melhorias de desempenho em tempo de execução, como alocações reduzidas e otimizações aprimoradas do compilador JIT, que ajudam a acelerar o processamento de PDFs e as operações de extração de tabelas.











