
Wie man Tabellendaten aus einer PDF-Datei in C# extrahiert
In vielen Branchen sind PDF-Dateien das bevorzugte Format zum Teilen strukturierter Dokumente wie Berichte, Rechnungen und Datentabellen. Das Extrahieren von Daten aus PDFs, insbesondere Tabellen, kann aufgrund der Beschaffenheit des PDF-Formats jedoch eine Herausforderung sein. Im Gegensatz zu strukturierten Datenformaten sind PDFs in erster Linie für die Präsentation und nicht für die Datenextraktion konzipiert.
Mit IronPDF, einer leistungsstarken C# PDF .NET-Bibliothek, können Sie jedoch strukturierte Daten wie Tabellen direkt aus PDFs extrahieren und in Ihren .NET-Anwendungen verarbeiten. Dieser Artikel führt Sie Schritt für Schritt durch den Prozess, um tabellarische Daten aus PDF-Dateien mit IronPDF zu extrahieren.
Wann müssen Sie Tabellen aus PDF-Dokumenten extrahieren?
Tabellen sind eine praktische Möglichkeit, Ihre Daten zu strukturieren und darzustellen, sei es bei der Lagerverwaltung, Datenerfassung, Aufzeichnung von Daten wie Niederschlagen usw. Daher gibt es möglicherweise viele Gründe, Tabellen und Tabellendaten aus PDF-Dokumenten extrahieren zu müssen. Einige der häufigsten Anwendungsfälle sind:
- Automatisierung der Dateneingabe: Das Extrahieren von Daten aus Tabellen in PDF-Berichten oder Rechnungen kann Prozesse wie das Füllen von Datenbanken oder Tabellenkalkulationen automatisieren.
- Datenanalyse: Unternehmen erhalten häufig strukturierte Berichte im PDF-Format. Das Extrahieren von Tabellen ermöglicht es Ihnen, diese Daten programmatisch zu analysieren.
- Dokumentenkonvertierung: Das Extrahieren tabellarischer Daten in zugänglichere Formate wie Excel oder CSV ermöglicht eine einfachere Manipulation, Speicherung und Weitergabe.
- Prüfung und Konformität: Für rechtliche oder finanzielle Aufzeichnungen kann das programmatische Extrahieren tabellarischer Daten aus PDF-Dokumenten helfen, Audits zu automatisieren und die Einhaltung von Vorschriften sicherzustellen.
Wie funktionieren PDF-Tabellen?
Das PDF-Dateiformat bietet keine native Möglichkeit, Daten in strukturierten Formaten wie Tabellen zu speichern. Die Tabelle, die wir im heutigen Beispiel verwenden, wurde in HTML erstellt, bevor sie in das PDF-Format konvertiert wurde. Tabellen werden als Text und Linien gerendert, daher erfordert das Extrahieren von Tabellendaten oft eine Analyse und Interpretation des Inhalts, es sei denn, Sie verwenden OCR-Software wie IronOCR.
So extrahieren Sie Tabellendaten aus einer PDF-Datei in C
Bevor wir untersuchen, wie IronPDF diese Aufgabe bewältigen kann, schauen wir uns zunächst ein Online-Tool an, das in der Lage ist, PDF-Extraktionen durchzuführen. Um eine Tabelle mit einem Online-PDF-Tool aus einem PDF-Dokument zu extrahieren, befolgen Sie die nachstehend aufgeführten Schritte:
- Navigieren Sie zum kostenlosen Online-PDF-Extraktionstool.
- Laden Sie das PDF hoch, das die Tabelle enthält.
- Zeigen Sie die Ergebnisse an und laden Sie sie herunter.
Schritt eins: Navigieren Sie zum kostenlosen Online-Tool zur PDF-Extraktion
Heute werden wir Docsumo als unser Beispiel für ein Online-PDF-Tool verwenden. Docsumo ist eine Online-PDF-Dokumenten-KI, die ein kostenloses Tool zur Extraktion von PDF-Tabellen bietet.
Schritt zwei: Hochladen der PDF-Datei mit der Tabelle
Klicken Sie nun auf die Schaltfläche "Datei hochladen", um Ihre PDF-Datei zur Extraktion hochzuladen. Das Tool beginnt sofort mit der Verarbeitung Ihres PDFs.
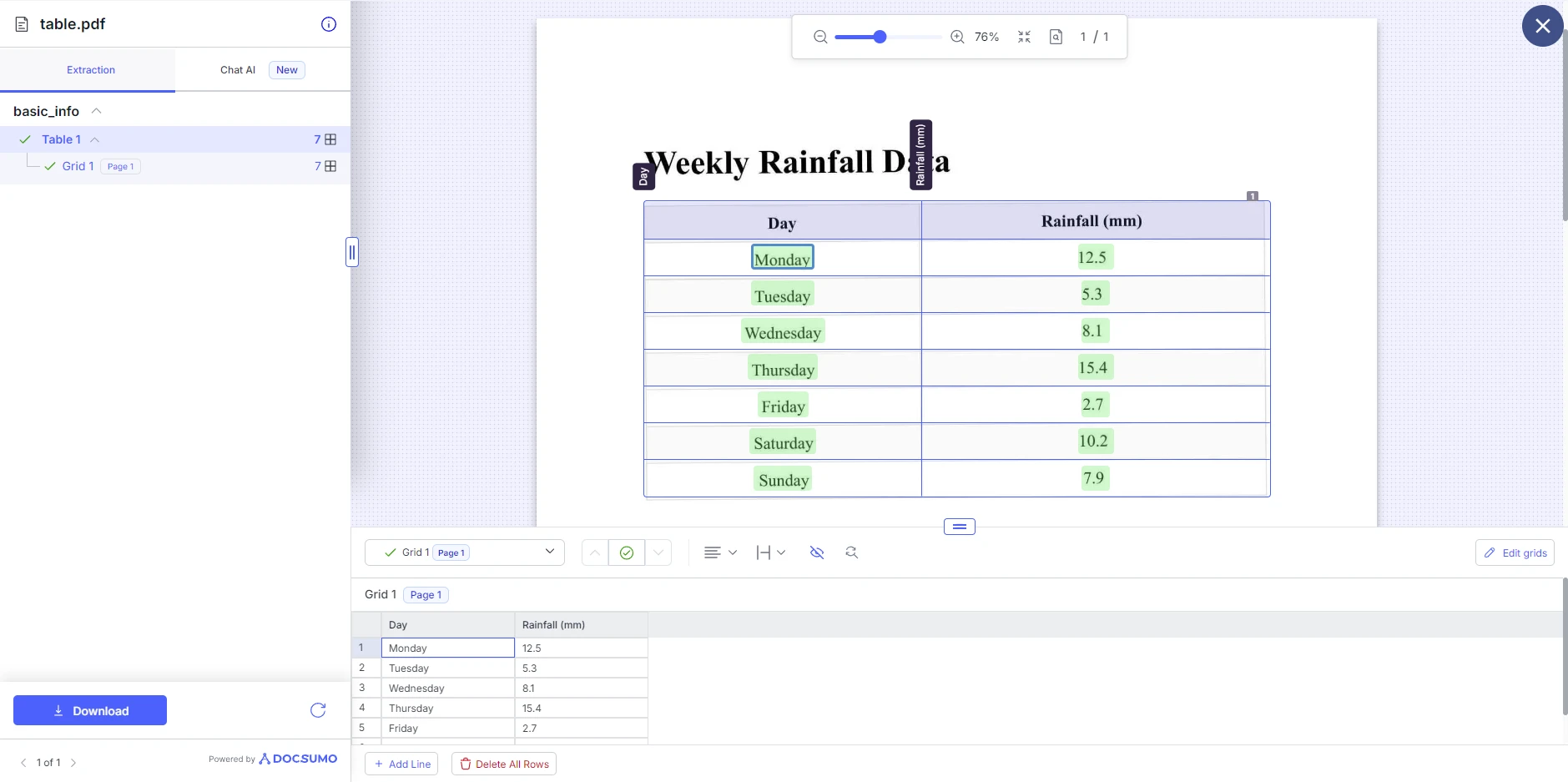
Schritt 3: Anzeigen und Herunterladen der Ergebnisse
Nachdem Docsumo die Verarbeitung des PDFs abgeschlossen hat, zeigt es die extrahierte Tabelle an. Sie können dann Anpassungen an der Tabellenstruktur vornehmen, wie z. B. das Hinzufügen und Entfernen von Zeilen. Hier können Sie die Tabelle als PDF, XLS, JSON oder Text herunterladen.
Tabellendaten mit IronPDF extrahieren
IronPDF ermöglicht es Ihnen, Daten, Text und Grafiken aus PDFs zu extrahieren, die dann verwendet werden können, um Tabellen programmatisch zu rekonstruieren. Dazu müssen Sie zuerst den Textinhalt aus der Tabelle im PDF extrahieren und diesen Text dann verwenden, um die Tabelle in Zeilen und Spalten zu zerlegen. Bevor wir mit dem Extrahieren von Tabellen beginnen, werfen wir einen Blick darauf, wie die ExtractAllText()-Methode von IronPDF funktioniert, indem wir die Daten innerhalb einer Tabelle extrahieren:
using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPDF;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class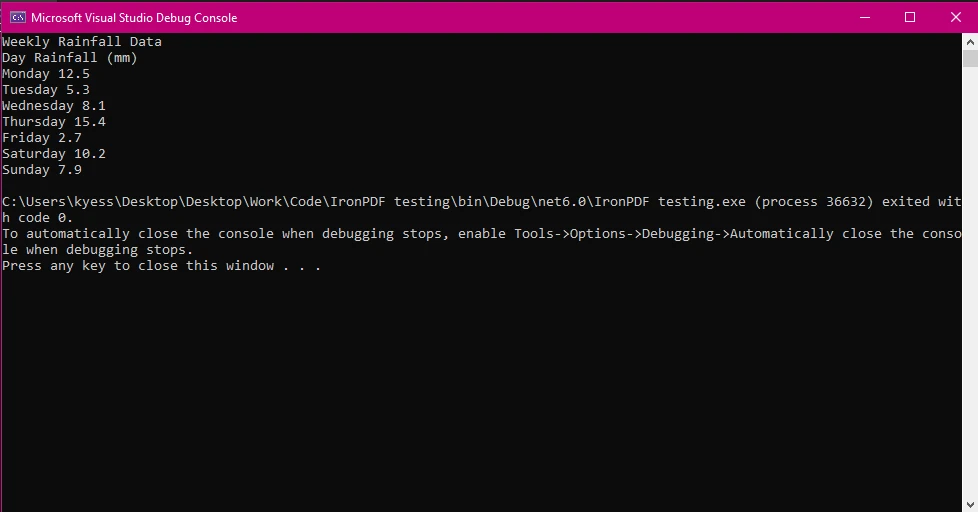
In diesem Beispiel haben wir das PDF-Dokument mithilfe der PdfDocument-Klasse geladen und dann die ExtractAllText()-Methode verwendet, um den gesamten Text innerhalb des Dokuments zu extrahieren, bevor der Text schließlich auf der Konsole angezeigt wird.
Tabellendaten aus Text extrahieren mit IronPDF
Nach der Textextraktion aus dem PDF erscheint die Tabelle als eine Reihe von Zeilen und Spalten im Klartext. Sie können diesen Text basierend auf Zeilenumbrüchen (\n) aufteilen und dann die Zeilen weiter in Spalten anhand von konstantem Abstand oder Trennzeichen wie Kommas oder Tabs aufteilen. Hier ist ein einfaches Beispiel, wie die Tabelle aus dem Text geparst wird:
using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}using IronPDF;
using System;
using System.Linq;
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = PdfDocument.FromFile("table.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Split the text into lines (rows)
string[] lines = text.Split('\n');
foreach (string line in lines)
{
// Split the line into columns using the tab character
string[] columns = line.Split('\t').Where(col => !string.IsNullOrWhiteSpace(col)).ToArray();
Console.WriteLine("Row:");
foreach (string column in columns)
{
Console.WriteLine(" " + column); // Output each column in the row
}
}
}
}Imports Microsoft.VisualBasic
Imports IronPDF
Imports System
Imports System.Linq
Friend Class Program
Shared Sub Main(ByVal args() As String)
' Load the PDF document
Dim pdf As PdfDocument = PdfDocument.FromFile("table.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Split the text into lines (rows)
Dim lines() As String = text.Split(ControlChars.Lf)
For Each line As String In lines
' Split the line into columns using the tab character
Dim columns() As String = line.Split(ControlChars.Tab).Where(Function(col) Not String.IsNullOrWhiteSpace(col)).ToArray()
Console.WriteLine("Row:")
For Each column As String In columns
Console.WriteLine(" " & column) ' Output each column in the row
Next column
Next line
End Sub
End Class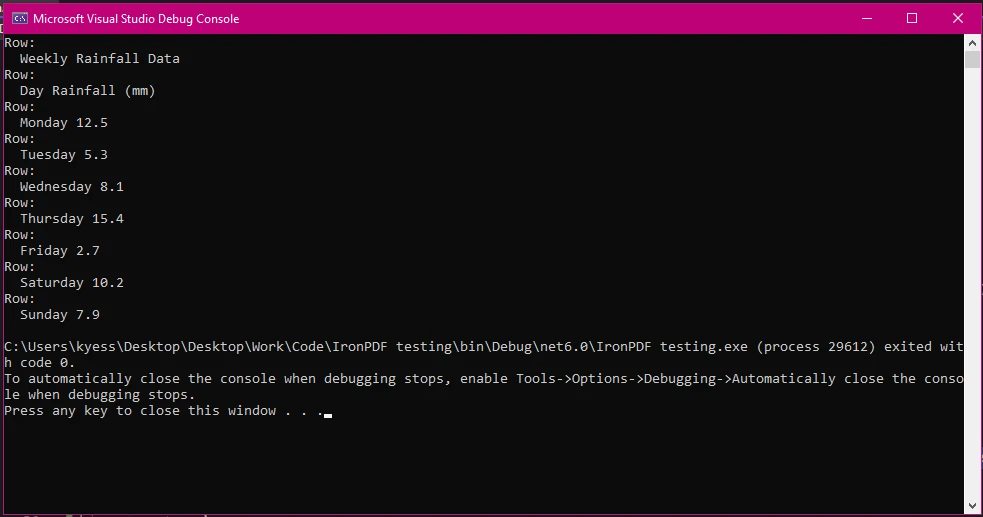
In diesem Beispiel folgten wir den gleichen Schritten wie zuvor, um unser PDF-Dokument zu laden und den Text zu extrahieren. Dann haben wir mit text.Split('\n') den extrahierten Text in Zeilen aufgeteilt basierend auf Zeilenumbrüchen und die Ergebnisse im lines-Array gespeichert. Eine foreach-Schleife wird dann verwendet, um durch die Zeilen im Array zu schleifen, wobei line.Split('\t') verwendet wird, um die Zeilen weiter in Spalten zu unterteilen, wobei das Tabulatorzeichen '\t' als Trennzeichen dient. Der nächste Teil des Spaltenarrays, Where(col => !string.IsNullOrWhiteSpace(col)).ToArray() filtert leere Spalten heraus, die aufgrund von zusätzlichen Leerzeichen entstehen können, und fügt die Spalten dann dem Spaltenarray hinzu.
Schließlich schreiben wir Text mit grundlegender Zeilen- und Spaltenstrukturierung in das Konsolenausgabefenster.
Exportieren von extrahierten Tabellendaten nach CSV
Da wir nun behandelt haben, wie man Tabellen aus PDF-Dateien extrahiert, schauen wir uns an, was wir mit diesen extrahierten Daten machen können. Das Exportieren der Tabelle als CSV-Datei ist eine nützliche Möglichkeit, Tabellendaten zu handhaben und Aufgaben wie die Dateneingabe zu automatisieren. Für dieses Beispiel haben wir eine Tabelle mit simulierten Daten gefüllt, in diesem Fall der täglichen Niederschlagsmenge in einer Woche, die Tabelle aus dem PDF extrahiert und dann in eine CSV-Datei exportiert.
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using IronPDF;
class Program
{
static void Main(string[] args)
{
string pdfPath = "table.pdf";
string csvPath = "output.csv";
// Extract and parse table data
var tableData = ExtractTableDataFromPdf(pdfPath);
// Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath);
Console.WriteLine($"Data extracted and saved to {csvPath}");
}
static List<string[]> ExtractTableDataFromPdf(string pdfPath)
{
var pdf = PdfDocument.FromFile(pdfPath);
// Extract text from the first page
var text = pdf.ExtractTextFromPage(0);
var rows = new List<string[]>();
// Split text into lines (rows)
var lines = text.Split('\n');
// Variable to hold column values temporarily
var tempColumns = new List<string>();
foreach (var line in lines)
{
var trimmedLine = line.Trim();
// Check for empty lines or lines that don't contain table data
if (string.IsNullOrEmpty(trimmedLine) || trimmedLine.Contains("Header"))
{
continue;
}
// Split line into columns. Adjust this based on how columns are separated.
var columns = trimmedLine.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries);
if (columns.Length > 0)
{
// Add columns to temporary list
tempColumns.AddRange(columns);
rows.Add(tempColumns.ToArray());
tempColumns.Clear(); // Clear temporary list after adding to rows
}
}
return rows;
}
static void WriteDataToCsv(List<string[]> data, string csvPath)
{
using (var writer = new StreamWriter(csvPath))
{
foreach (var row in data)
{
// Join columns with commas and quote each field to handle commas within data
var csvRow = string.Join(",", row.Select(field => $"\"{field.Replace("\"", "\"\"")}\""));
writer.WriteLine(csvRow);
}
}
}
}Imports Microsoft.VisualBasic
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports IronPDF
Friend Class Program
Shared Sub Main(ByVal args() As String)
Dim pdfPath As String = "table.pdf"
Dim csvPath As String = "output.csv"
' Extract and parse table data
Dim tableData = ExtractTableDataFromPdf(pdfPath)
' Write the extracted data to a CSV file
WriteDataToCsv(tableData, csvPath)
Console.WriteLine($"Data extracted and saved to {csvPath}")
End Sub
Private Shared Function ExtractTableDataFromPdf(ByVal pdfPath As String) As List(Of String())
Dim pdf = PdfDocument.FromFile(pdfPath)
' Extract text from the first page
Dim text = pdf.ExtractTextFromPage(0)
Dim rows = New List(Of String())()
' Split text into lines (rows)
Dim lines = text.Split(ControlChars.Lf)
' Variable to hold column values temporarily
Dim tempColumns = New List(Of String)()
For Each line In lines
Dim trimmedLine = line.Trim()
' Check for empty lines or lines that don't contain table data
If String.IsNullOrEmpty(trimmedLine) OrElse trimmedLine.Contains("Header") Then
Continue For
End If
' Split line into columns. Adjust this based on how columns are separated.
Dim columns = trimmedLine.Split( { " "c, ControlChars.Tab }, StringSplitOptions.RemoveEmptyEntries)
If columns.Length > 0 Then
' Add columns to temporary list
tempColumns.AddRange(columns)
rows.Add(tempColumns.ToArray())
tempColumns.Clear() ' Clear temporary list after adding to rows
End If
Next line
Return rows
End Function
Private Shared Sub WriteDataToCsv(ByVal data As List(Of String()), ByVal csvPath As String)
Using writer = New StreamWriter(csvPath)
For Each row In data
' Join columns with commas and quote each field to handle commas within data
Dim csvRow = String.Join(",", row.Select(Function(field) $"""{field.Replace("""", """""")}"""))
writer.WriteLine(csvRow)
Next row
End Using
End Sub
End ClassBeispiel-PDF-Datei
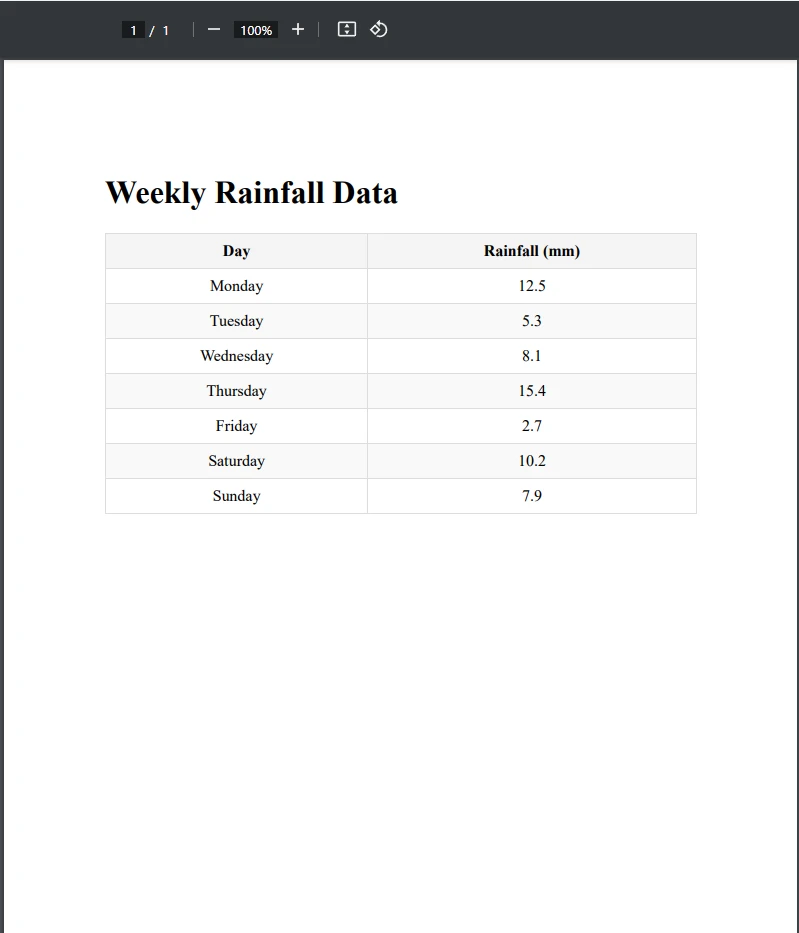
Ausgabe CSV-Datei
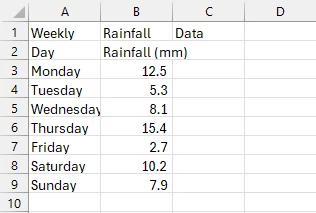
Wie Sie sehen können, haben wir die PDF-Tabelle erfolgreich in CSV exportiert. Zunächst haben wir das PDF, das die Tabelle enthält, geladen und einen neuen CSV-Dateipfad erstellt. Danach haben wir die Tabelle mit der Zeile var tableData = ExtractTableDataFromPdf(pdfPath) extrahiert, die die Methode ExtractTableDataFromPdf() aufruft. Diese Methode extrahiert den gesamten Text auf der PDF-Seite, auf der sich die Tabelle befindet, und speichert ihn in der Variablen text.
Anschließend haben wir den Text in Zeilen und Spalten aufgeteilt. Schließlich, nach Rückgabe des Ergebnisses aus diesem Aufteilungsprozess, rufen wir die Methode static void WriteDataToCsv() auf, die den extrahierten, aufgeteilten Text verwendet und ihn mithilfe von StreamWriter in unsere CSV-Datei schreibt.
Tipps und bewährte Praktiken
Beim Arbeiten mit PDF-Tabellen können einige grundlegende bewährte Praktiken helfen, die Wahrscheinlichkeit von Fehlern oder Problemen zu minimieren.
- Vorverarbeitung von PDFs: Wenn möglich, verarbeiten Sie Ihre PDFs vor, um ein einheitliches Format sicherzustellen, was den Extraktionsprozess vereinfacht.
- Datenvalidierung: Validieren Sie immer die extrahierten Daten, um Genauigkeit und Vollständigkeit sicherzustellen.
- Fehlerbehandlung: Implementieren Sie eine Fehlerbehandlung, um Fälle zu verwalten, in denen die Textextraktion oder das Parsing fehlschlägt, indem Sie beispielsweise Ihren Code in einem try-catch-Block umschließen.
- Leistungsoptimierung: Für große PDFs sollten Sie die Textextraktion und das Parsing optimieren, um Leistungsprobleme zu bewältigen.
IronPDF Lizenzierung
IronPDF bietet verschiedene Lizenzierungs-Optionen, mit denen Sie alle leistungsstarken Funktionen von IronPDF selbst ausprobieren können, bevor Sie sich für eine Lizenz entscheiden.
Abschluss
Das Extrahieren von Tabellen aus PDFs mit IronPDF ist eine leistungsstarke Methode, um die Datenextraktion zu automatisieren, Analysen zu erleichtern und Dokumente in zugänglichere Formate zu konvertieren. Egal, ob Sie es mit einfachen Tabellen oder komplexen, unregelmäßigen Formaten zu tun haben, IronPDF stellt die Werkzeuge bereit, die Sie benötigen, um Tabellendaten effizient zu extrahieren und zu verarbeiten.
Mit IronPDF können Sie Workflows wie automatisierte Dateneingabe, Dokumentenkonvertierung und Datenanalyse rationalisieren. Die Flexibilität und erweiterten Funktionen von IronPDF machen es zu einem wertvollen Werkzeug für die Bearbeitung verschiedener PDF-basierter Aufgaben.
Häufig gestellte Fragen
Wie kann ich Tabellen aus einem PDF mit C# extrahieren?
Sie können IronPDF verwenden, um Tabellen aus einem PDF in C# zu extrahieren. Laden Sie das PDF-Dokument mit IronPDF, extrahieren Sie den Text und parsen Sie dann den Text programmatisch in Zeilen und Spalten.
Warum ist es schwierig, Tabellendaten aus PDF-Dokumenten zu extrahieren?
PDFs sind hauptsächlich für die Präsentation und nicht für die Datenstruktur ausgelegt, was es schwierig macht, strukturierte Daten wie Tabellen zu extrahieren. Tools wie IronPDF helfen dabei, diese Daten effektiv zu interpretieren und zu extrahieren.
Welche Vorteile hat das Extrahieren von Tabellen aus PDFs?
Das Extrahieren von Tabellen aus PDFs erleichtert die Automatisierung der Dateneingabe, die Durchführung von Datenanalysen, die Umwandlung von Dokumenten in zugänglichere Formate und stellt die Einhaltung von Prüfprozessen sicher.
Wie gehen Sie mit komplexen Tabellenformaten bei der PDF-Extraktion um?
IronPDF bietet Funktionen zur Extraktion und Verarbeitung von Tabellendaten, selbst aus komplexen und unregelmäßigen Tabellenformaten, um eine genaue Datenauswertung zu gewährleisten.
Wie sieht der Prozess aus, um extrahierte PDF-Tabellendaten in CSV zu konvertieren?
Nach der Extraktion und dem Parsen von Tabellendaten aus einem PDF mit IronPDF können Sie diese Daten in eine CSV-Datei exportieren, indem Sie die geparsten Daten mit einem StreamWriter schreiben.
Was sind einige Best Practices für die PDF-Tabellenextraktion?
Bereiten Sie PDFs für ein konsistentes Formatieren vor, validieren Sie extrahierte Daten, implementieren Sie Fehlerbehandlung und optimieren Sie die Leistung bei der Arbeit mit großen PDF-Dateien.
Kann IronPDF bei Prüfungs- und Compliance-Aufgaben helfen?
Ja, IronPDF kann tabellarische Daten aus PDFs extrahieren und in Formate wie Excel oder CSV umwandeln, was bei der Prüfung und Einhaltung durch erleichterte Analyse und Überprüfung der Daten hilft.
Welche Lizenzierungsoptionen bietet IronPDF?
IronPDF bietet verschiedene Lizenzierungsoptionen, einschließlich Testversionen, damit Sie seine Funktionen erkunden können, bevor Sie eine Vollversion erwerben.
Welche häufigen Störungsszenarien könnten beim Extrahieren von Tabellen aus PDFs auftreten?
Häufige Probleme umfassen inkonsistente Tabellenformate und Fehler bei der Textextraktion. Die robusten Funktionen von IronPDF können helfen, diese Herausforderungen durch genaue Parsing-Fähigkeiten zu überwinden.
Ist IronPDF vollständig mit .NET 10 kompatibel und wie wirkt sich das positiv auf Workflows zur Tabellenextraktion aus?
Ja – IronPDF unterstützt .NET 10 (sowie .NET 9, 8, 7, 6, Core, Standard und Framework), sodass Sie es problemlos in aktuellen .NET 10-Projekten einsetzen können. Entwickler, die mit .NET 10 arbeiten, profitieren von Laufzeit-Leistungsverbesserungen wie reduzierten Speicherzuweisungen und optimierten JIT-Compilern, was die PDF-Verarbeitung und Tabellenextraktion beschleunigt.














