
Jak scalać pliki PDF w .NET

Łączenie wielu plików PDF w jeden nowy dokument jest częstym wymaganiem w aplikacjach biznesowych. Niezależnie od tego, czy konsolidujesz raporty, łączysz faktury, czy tworzysz pakiety dokumentacji, możliwość programowego scalania plików PDF pozwala zaoszczędzić czas i ograniczyć nakład pracy ręcznej. IronPDF to potężna biblioteka PDF, która sprawia, że proces ten jest niezwykle prosty w aplikacjach .NET przy użyciu zaledwie kilku linii kodu.
W tym artykule dowiesz się, jak łączyć dokumenty PDF za pomocą prostego interfejsu API IronPDF, od podstawowych połączeń dwóch plików po dynamiczną obsługę wielu dokumentów. Biblioteka IronPDF zapewnia solidne rozwiązanie do wydajnego łączenia plików PDF przy zachowaniu integralności dokumentów. Wykorzystamy różne funkcje biblioteki, w tym tworzenie nowego ciągu znaków dla treści HTML oraz obsługę różnych źródeł.
Jak zainstalować IronPDF for .NET Merge PDF?
Rozpoczęcie pracy z IronPDF wymaga jedynie prostej instalacji pakietu NuGet. Otwórz konsolę menedżera pakietów w Visual Studio i uruchom:
Install-Package IronPdf
Po zainstalowaniu dodaj przestrzeń nazw IronPDF do pliku C#:
using IronPdf;using IronPdf;Imports IronPdfTo wszystko, co trzeba zrobić. IronPDF zajmuje się wszystkimi skomplikowanymi operacjami na plikach PDF w tle, pozwalając Ci skupić się na logice aplikacji. Po zainstalowaniu biblioteki możesz od razu zacząć łączyć zarówno istniejące, jak i nowe dokumenty PDF. Należy pamiętać, że proces ten jest kompatybilny z różnymi systemami operacyjnymi, w tym z systemem Linux poprzez .NET Core. Szczegółowe instrukcje dotyczące instalacji można znaleźć w dokumentacji instalacyjnej IronPDF.
Jak połączyć dwa dokumenty PDF?
Najbardziej podstawowy scenariusz scalania polega na połączeniu dwóch istniejących lub nowych obiektów PDFDocument. Oto jak wykonać to zadanie:
using IronPdf;
class Program
{
static void Main()
{
// Load the PDF documents
var pdf1 = PdfDocument.FromFile("Invoice1.pdf");
var pdf2 = PdfDocument.FromFile("Invoice2.pdf");
// Merge the documents
var merged = PdfDocument.Merge(pdf1, pdf2);
// Save the merged document
merged.SaveAs("Merged.pdf");
}
}using IronPdf;
class Program
{
static void Main()
{
// Load the PDF documents
var pdf1 = PdfDocument.FromFile("Invoice1.pdf");
var pdf2 = PdfDocument.FromFile("Invoice2.pdf");
// Merge the documents
var merged = PdfDocument.Merge(pdf1, pdf2);
// Save the merged document
merged.SaveAs("Merged.pdf");
}
}Imports IronPdf
Class Program
Shared Sub Main()
' Load the PDF documents
Dim pdf1 = PdfDocument.FromFile("Invoice1.pdf")
Dim pdf2 = PdfDocument.FromFile("Invoice2.pdf")
' Merge the documents
Dim merged = PdfDocument.Merge(pdf1, pdf2)
' Save the merged document
merged.SaveAs("Merged.pdf")
End Sub
End ClassTen kod pokazuje, jak łatwo można łączyć pliki PDF za pomocą IronPDF. Metoda PdfDocument.FromFile() ładuje istniejące pliki PDF do pamięci. Te załadowane dokumenty stają się obiektami PdfDocument, którymi można manipulować programowo.
Metoda Merge() pobiera dwa lub więcej obiektów PdfDocument i łączy je w jeden plik PDF. Strony PDF z drugiego dokumentu są dołączane po stronach pierwszego dokumentu, zachowując oryginalną kolejność i formatowanie każdej strony. Więcej informacji na temat metody Merge można znaleźć w dokumentacji API.
Na koniec funkcja SaveAs() zapisuje scalony dokument na dysku. Powstały plik PDF zawiera wszystkie strony z obu dokumentów źródłowych w kolejności, gotowe do dystrybucji lub dalszego przetwarzania.
Wynik
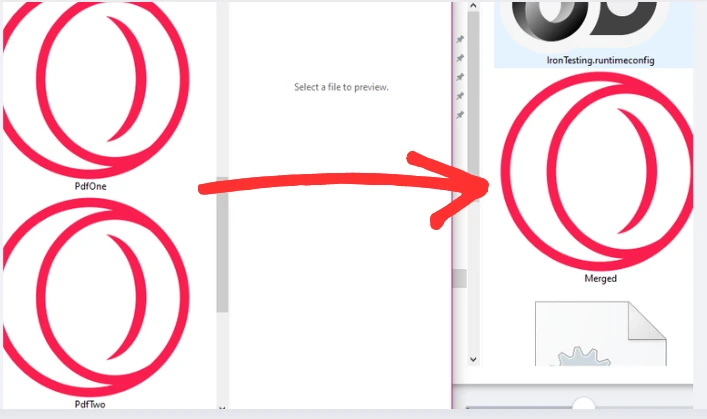
Jak połączyć wiele plików PDF?
W praktyce często trzeba łączyć pliki PDF, a nie tylko dwa dokumenty. Jak widzieliśmy w poprzednim przykładzie, IronPDF z łatwością radzi sobie z łączeniem plików PDF za pomocą zaledwie kilku wierszy kodu. Teraz przyjrzymy się, jak IronPDF może elegancko poradzić sobie z tym scenariuszem, wykorzystując kolekcję List:
using IronPdf;
using System.Collections.Generic;
using System.IO;
class Program
{
static void Main()
{
// Create a list to store PDF documents
var files = new List<PdfDocument>();
// Get all PDF files from a directory
string[] fileNames = Directory.GetFiles(@"C:\Reports\", "*.pdf");
// Load each PDF file
foreach (var fileName in fileNames)
{
files.Add(PdfDocument.FromFile(fileName));
}
// Merge all PDFs into one
var merged = PdfDocument.Merge(pdfs);
// Save the combined document
merged.SaveAs("CombinedReports.pdf");
}
}using IronPdf;
using System.Collections.Generic;
using System.IO;
class Program
{
static void Main()
{
// Create a list to store PDF documents
var files = new List<PdfDocument>();
// Get all PDF files from a directory
string[] fileNames = Directory.GetFiles(@"C:\Reports\", "*.pdf");
// Load each PDF file
foreach (var fileName in fileNames)
{
files.Add(PdfDocument.FromFile(fileName));
}
// Merge all PDFs into one
var merged = PdfDocument.Merge(pdfs);
// Save the combined document
merged.SaveAs("CombinedReports.pdf");
}
}Imports IronPdf
Imports System.Collections.Generic
Imports System.IO
Class Program
Shared Sub Main()
' Create a list to store PDF documents
Dim files As New List(Of PdfDocument)()
' Get all PDF files from a directory
Dim fileNames As String() = Directory.GetFiles("C:\Reports\", "*.pdf")
' Load each PDF file
For Each fileName In fileNames
files.Add(PdfDocument.FromFile(fileName))
Next
' Merge all PDFs into one
Dim merged = PdfDocument.Merge(files)
' Save the combined document
merged.SaveAs("CombinedReports.pdf")
End Sub
End ClassTen przykładowy kod pokazuje bardziej dynamiczne podejście do łączenia plików PDF. Kod wykorzystuje metodę Directory.GetFiles(), aby automatycznie wykryć wszystkie pliki PDF w określonym folderze, eliminując konieczność ręcznego wpisywania nazw poszczególnych plików. Zgodnie z dokumentacją Microsoftu dotyczącą operacji na plikach, metoda ta skutecznie pobiera ścieżki plików spełniające określone kryteria.
Każdy znaleziony plik PDF jest ładowany jako obiekt PdfDocument i dodawany do kolekcji typu List. Takie podejście sprawdza się równie dobrze, niezależnie od tego, czy łączysz trzy pliki, czy trzysta. Metoda Merge() przyjmuje całą listę, przetwarzając wszystkie dokumenty źródłowe w ramach jednej operacji w celu utworzenia jednego nowego dokumentu. Jeśli chcesz, możesz również skorzystać z typu danych int do śledzenia indeksu każdego pliku w trakcie jego przetwarzania.
Pętla foreach zapewnia przejrzysty sposób iteracji przez wiele plików PDF i można tu łatwo dodać logikę filtrowania, aby wybrać konkretne pliki docelowe na podstawie wzorców nazewnictwa, dat lub innych kryteriów. Ten wzorzec sprawdza się dobrze w scenariuszach przetwarzania wsadowego, takich jak tworzenie raportów miesięcznych lub procesy archiwizacji dokumentów. Aby uzyskać dostęp do bardziej zaawansowanych opcji manipulacji stronami, zapoznaj się z funkcjami zarządzania stronami IronPDF.
!{--01001100010010010100001001010010010000010101001001011001010111110100011101000101010101000101111101010011010101000100000101010010010101000100010101000100010111110101011101001001010100010010000101111101010000010100100100111101000100010101010100001101010100010111110101010001010010010010010100000101001100010111110100001001001100010011110100001101001011--}
Jak połączyć pliki PDF z różnych źródeł?
Czasami trzeba połączyć pliki PDF z różnych źródeł — na przykład scalając dynamicznie generowaną treść z istniejącymi szablonami. IronPDF radzi sobie z tym bez problemu:
using IronPdf;
using System;
using System.IO;
class Program
{
static void Main(string[] args)
{
var renderer = new ChromePdfRenderer();
// Create a PDF from HTML
string html = @"<h1>Cover Page</h1>
<p>Example PDF From Multiple Sources</p>
<div style='page-break-after: always;'></div>";
var coverPage = renderer.RenderHtmlAsPdf(html);
// Load an existing PDF report
var pdf = PdfDocument.FromFile(@"invoice.pdf");
// Create a summary from URL
var summary = renderer.RenderUrlAsPdf("https://en.wikipedia.org/wiki/Main_Page");
// Merge all three sources
var finalDocument = PdfDocument.Merge(new[] { coverPage, pdf, summary });
// Save the complete document
finalDocument.SaveAs("MultipleSources.pdf");
}
}using IronPdf;
using System;
using System.IO;
class Program
{
static void Main(string[] args)
{
var renderer = new ChromePdfRenderer();
// Create a PDF from HTML
string html = @"<h1>Cover Page</h1>
<p>Example PDF From Multiple Sources</p>
<div style='page-break-after: always;'></div>";
var coverPage = renderer.RenderHtmlAsPdf(html);
// Load an existing PDF report
var pdf = PdfDocument.FromFile(@"invoice.pdf");
// Create a summary from URL
var summary = renderer.RenderUrlAsPdf("https://en.wikipedia.org/wiki/Main_Page");
// Merge all three sources
var finalDocument = PdfDocument.Merge(new[] { coverPage, pdf, summary });
// Save the complete document
finalDocument.SaveAs("MultipleSources.pdf");
}
}Imports IronPdf
Imports System
Imports System.IO
Class Program
Shared Sub Main(args As String())
Dim renderer = New ChromePdfRenderer()
' Create a PDF from HTML
Dim html As String = "<h1>Cover Page</h1>
<p>Example PDF From Multiple Sources</p>
<div style='page-break-after: always;'></div>"
Dim coverPage = renderer.RenderHtmlAsPdf(html)
' Load an existing PDF report
Dim pdf = PdfDocument.FromFile("invoice.pdf")
' Create a summary from URL
Dim summary = renderer.RenderUrlAsPdf("https://en.wikipedia.org/wiki/Main_Page")
' Merge all three sources
Dim finalDocument = PdfDocument.Merge(New PdfDocument() {coverPage, pdf, summary})
' Save the complete document
finalDocument.SaveAs("MultipleSources.pdf")
End Sub
End ClassTen zaawansowany przykład pokazuje wszechstronność IronPDF w obsłudze różnych źródeł PDF. Klasa ChromePdfRenderer umożliwia konwersję HTML do PDF, co idealnie nadaje się do generowania dynamicznych stron tytułowych lub sformatowanej treści na podstawie danych z aplikacji. Renderer obsługuje nowoczesne standardy internetowe zgodnie ze specyfikacjami W3C.
Metoda RenderHtmlAsPdf() konwertuje nowe ciągi znaków HTML bezpośrednio do formatu PDF, obsługując pełne style CSS i JavaScript. Długość ciągu HTML nie ma wpływu na jakość konwersji. Metoda RenderUrlAsPdf() pobiera i konwertuje treści internetowe, co jest przydatne do włączania danych na żywo lub zasobów zewnętrznych. W przypadku źródeł internetowych strumieniem danych zarządza wewnętrzny moduł odczytu. Więcej informacji na temat tych opcji renderowania można znaleźć w samouczku dotyczącym konwersji HTML do PDF.
Łącząc te metody renderowania z istniejącymi dokumentami PDF, można tworzyć zaawansowane przepływy pracy z dokumentami. Takie podejście doskonale sprawdza się w sytuacjach takich jak dodawanie markowych stron tytułowych do raportów, dołączanie informacji prawnych do umów lub łączenie treści generowanych przez użytkowników z szablonami. Wersja scalonego dokumentu zachowuje całe formatowanie z każdego pliku źródłowego, tworząc spójny, pojedynczy plik PDF.
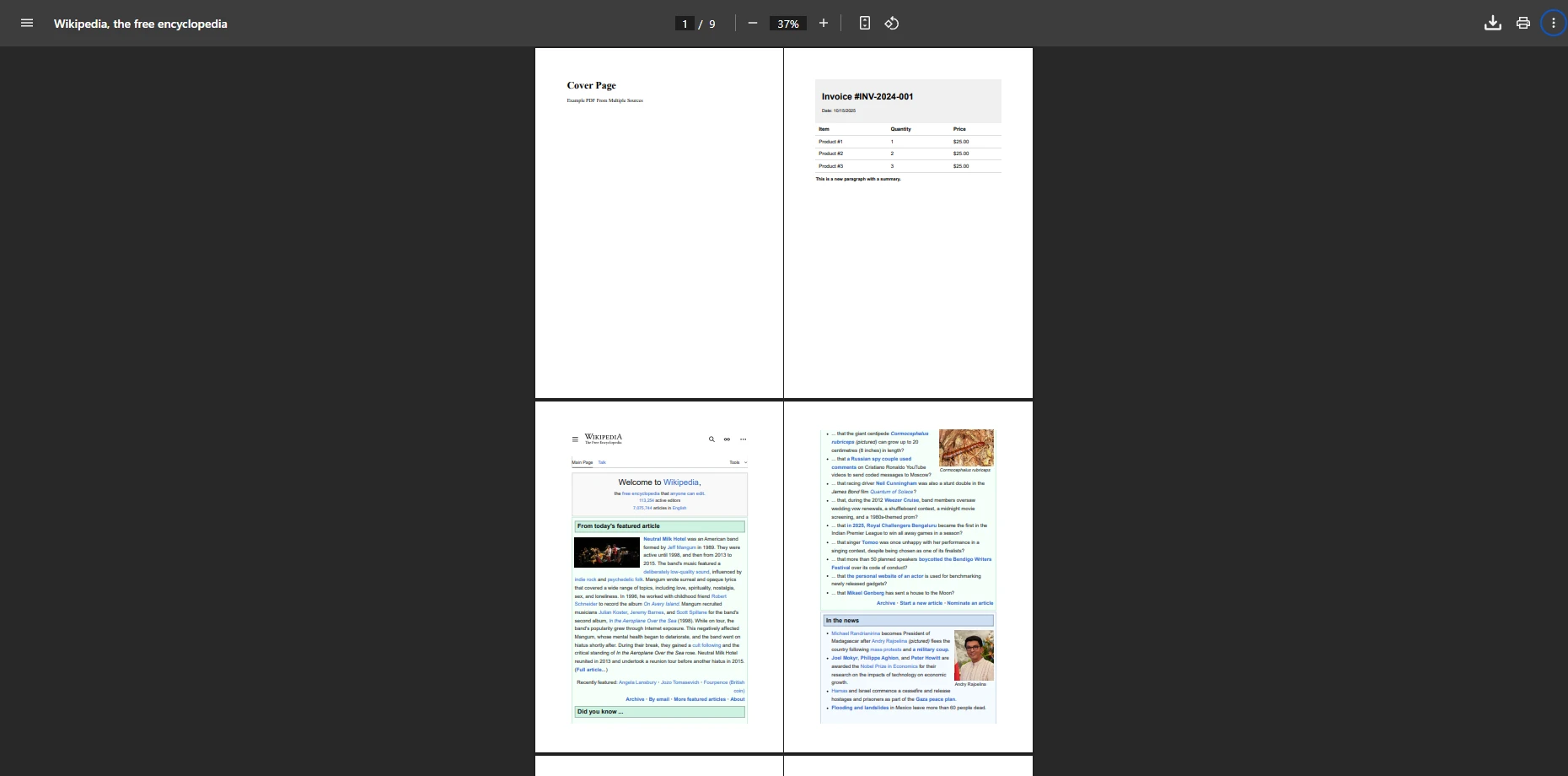
Wynik
Na tym zrzucie ekranu widać, że nasz plik PDF został pomyślnie utworzony poprzez połączenie wielu plików.
Wnioski
IronPDF przekształca skomplikowane zadanie łączenia plików PDF w środowisku .NET w prosty proces wymagający minimalnej ilości kodu. Od prostych kombinacji dwóch plików po zaawansowane łączenie dokumentów z wielu źródeł — biblioteka radzi sobie ze złożonością techniczną, zapewniając jednocześnie intuicyjny interfejs API. Niezależnie od tego, czy pracujesz z pojedynczym plikiem, czy przetwarzasz dużą liczbę dokumentów źródłowych, IronPDF zachowuje integralność dokumentu docelowego podczas całego procesu scalania.
Przykłady w tym samouczku pokazują, jak łatwo można zintegrować funkcje łączenia plików PDF z aplikacjami .NET. Niezależnie od tego, czy tworzysz systemy zarządzania dokumentami, automatyzujesz generowanie raportów, czy przetwarzasz pliki przesłane przez użytkowników, IronPDF zapewnia narzędzia potrzebne do wydajnego łączenia plików PDF i wykorzystywania różnych źródeł danych wejściowych.
Chcesz wdrożyć funkcję łączenia plików PDF w swoim projekcie? Zacznij od bezpłatnej wersji próbnej, która najlepiej odpowiada Twoim potrzebom. Zapoznaj się z obszerną dokumentacją, aby poznać bardziej zaawansowane funkcje, takie jak dodawanie znaków wodnych, stosowanie zabezpieczeń, dzielenie dokumentów PDF oraz wskazówki dotyczące rozwiązywania problemów w celu lepszego obsługi wyjątków.
Często Zadawane Pytania
Jaki jest główny cel samouczka IronPDF .NET Merge PDF?
Samouczek ma na celu pokazanie programistom, jak łączyć pliki PDF w aplikacjach .NET przy użyciu prostego interfejsu API IronPDF. Obejmuje on łączenie wielu dokumentów, dodawanie stron tytułowych oraz automatyzację procesów związanych z plikami PDF.
W jaki sposób IronPDF może pomóc w automatyzacji procesów związanych z plikami PDF?
IronPDF zapewnia proste API, które pozwala programistom zautomatyzować procesy łączenia plików PDF, co może usprawnić zarządzanie dokumentami i zwiększyć wydajność w ramach aplikacji.
Czy podczas łączenia plików PDF za pomocą IronPDF można dodać stronę tytułową?
Tak, API IronPDF pozwala w łatwy sposób dodać stronę tytułową podczas łączenia wielu plików PDF, zapewniając elastyczność w organizowaniu prezentacji dokumentu.
Jakie są zalety korzystania z IronPDF for .NET do łączenia plików PDF?
IronPDF oferuje prosty i wydajny sposób łączenia plików PDF, oszczędzając czas i zmniejszając złożoność obsługi dokumentów. Obsługuje różne funkcje, takie jak dodawanie stron tytułowych i automatyzacja przepływu pracy, co zwiększa ogólną funkcjonalność aplikacji .NET.
Czy IronPDF radzi sobie z dużymi ilościami plików PDF do scalania?
IronPDF został zaprojektowany do wydajnej obsługi dużych ilości plików PDF, dzięki czemu nadaje się zarówno do aplikacji na małą skalę, jak i na poziomie Enterprise, które wymagają solidnych możliwości przetwarzania plików PDF.
Jakie są kluczowe funkcje API IronPDF do łączenia plików PDF?
API IronPDF do łączenia plików PDF zawiera funkcje takie jak łączenie wielu dokumentów, dodawanie stron tytułowych i automatyzacja przepływu pracy, które przyczyniają się do płynnego i wydajnego procesu obsługi plików PDF.














