
Jak programowo przearanżować strony PDF w C#
Zmiana kolejności stron w pliku PDF za pomocą języka C# pozwala zaoszczędzić wiele godzin pracy ręcznej, gdy trzeba przeorganizować raporty, zmienić kolejność załączników do umów lub przebudować pakiety dokumentów przed dostarczeniem. IronPDF zapewnia proste API do ładowania pliku PDF, określania nowej sekwencji stron i zapisywania wyniku za pomocą zaledwie kilku wierszy kodu .NET. W tym artykule omówiono pięć praktycznych technik: podstawową zmianę kolejności stron, masowe odwracanie, przenoszenie pojedynczej strony do nowego indeksu, usuwanie niechcianych stron oraz pracę całkowicie w pamięci bez ingerencji w system plików.
IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");Imports IronPdf
PdfDocument.FromFile("input.pdf") _
.CopyPages({2, 0, 1, 3}) _
.SaveAs("reordered.pdf")Jak rozpocząć pracę z IronPDF?
Dodaj IronPDF do dowolnego projektu .NET 8 lub .NET 10 w kilka sekund, korzystając z menedżera pakietów NuGet lub interfejsu CLI .NET. W systemach Windows, Linux lub macOS nie są wymagane żadne dodatkowe zależności uruchomieniowe ani natywne pliki binarne.
dotnet add package IronPdfdotnet add package IronPdfPo zainstalowaniu pakietu dodaj using IronPdf; na początku pliku C#. Prawidłowy klucz licencyjny odblokowuje pełne wykorzystanie komercyjne; Dostępna jest bezpłatna licencja próbna do oceny. Ustaw klucz przed wywołaniem jakiegokolwiek API:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Po dodaniu odwołania do pakietu i skonfigurowaniu licencji wszystkie przykłady w tym artykule będą działać bez modyfikacji. Pakiet IronPDF NuGet jest przeznaczony dla platformy .NET Standard 2.0 i nowszych, więc działa w środowisku .NET Framework 4.6.2+, .NET Core oraz we wszystkich nowoczesnych wersjach Wersji .NET.
Jak działa zmiana kolejności stron w języku C#?
Proces zmiany kolejności stron w pliku PDF przy użyciu języka C# polega na załadowaniu dokumentu źródłowego, określeniu żądanej kolejności stron za pomocą tablicy indeksu stron oraz zapisaniu pliku wyjściowego. IronPDF udostępnia metodę CopyPages do wyodrębniania i zmiany kolejności stron z pliku PDF do nowego obiektu PdfDocument.
Poniższy kod pokazuje, jak zmienić kolejność stron, tworząc nową tablicę int, która określa docelową sekwencję. Każda wartość w tablicy odpowiada indeksowi strony z oryginalnego dokumentu, w którym strony są indeksowane od zera (strona 0 to pierwsza strona).
using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");Imports IronPdf
' Load the source document from file path
Dim pdf As PdfDocument = PdfDocument.FromFile("quarterly-report.pdf")
' Define new page order: move page 3 to front, then pages 1, 2, 0
Dim pageOrder As Integer() = {3, 1, 2, 0}
' Copy each requested page into its own PdfDocument
Dim pageDocs As New List(Of PdfDocument)()
For Each idx In pageOrder
' CopyPage returns a PdfDocument containing only that page
Dim single As PdfDocument = pdf.CopyPage(idx)
pageDocs.Add(single)
Next
' Merge the single-page docs into one ordered document
Using merged As PdfDocument = PdfDocument.Merge(pageDocs.ToArray())
' Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf")
End UsingWynikowy dokument PDF
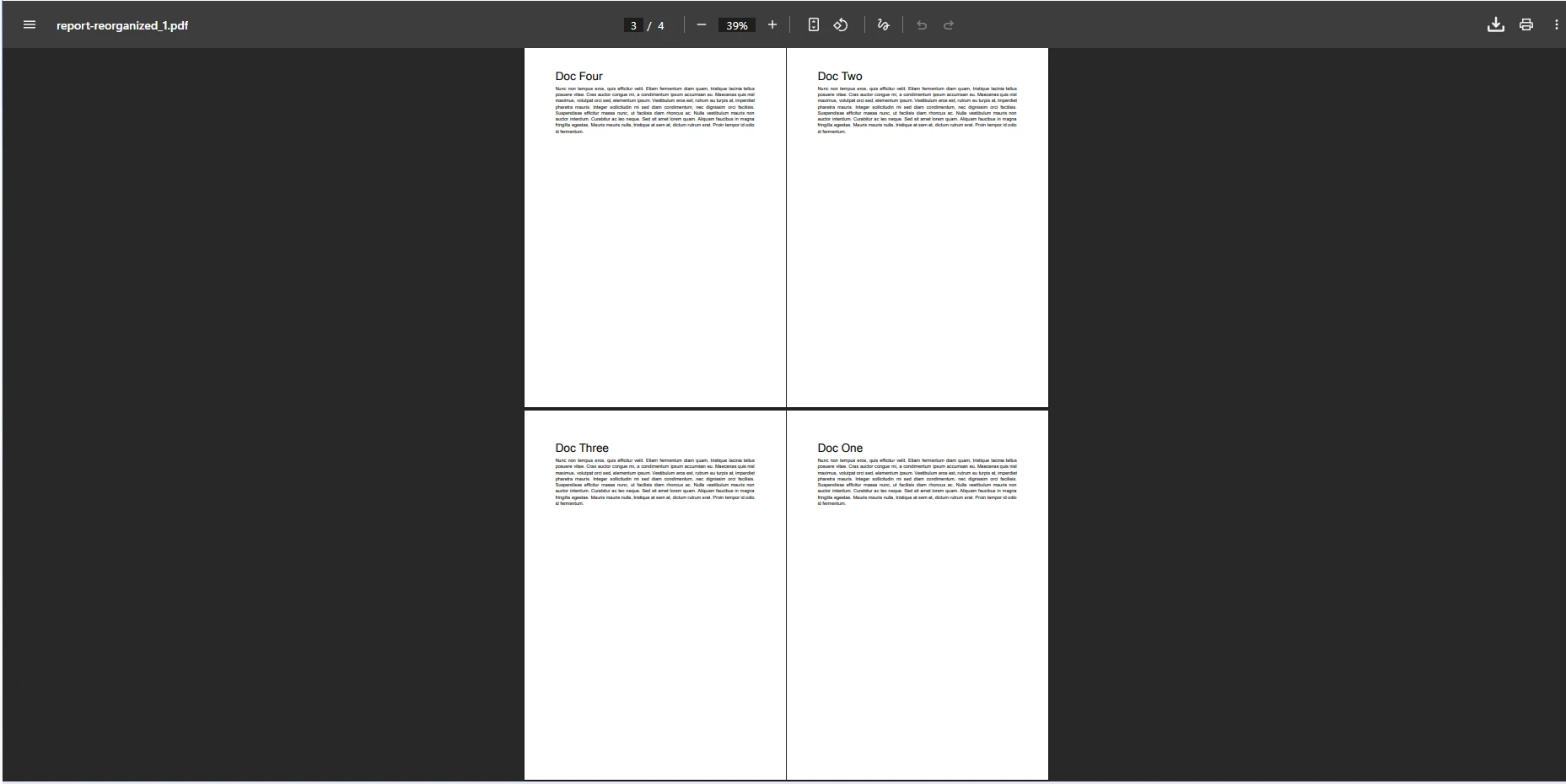
Metoda CopyPages przyjmuje IEnumerable<int> wartości indeksów stron, które odpowiadają pożądanemu układowi. To podejście pozwala na zmianę kolejności stron w pliku PDF, powielanie określonych stron lub wyodrębnianie podzbioru do osobnego dokumentu. Metoda zwraca nowy obiekt PdfDocument, pozostawiając oryginalny dokument źródłowy bez zmian. Ponieważ oryginał nigdy nie ulega zmianie, można bezpiecznie wywoływać CopyPages wielokrotnie, aby generować różne kolejności z tego samego pliku źródłowego.
Dla zespołów pracujących w środowiskach Java, IronPDF for Java udostępnia podobne metody manipulacji stronami oraz kompatybilny interfejs API, dzięki czemu umiejętności są przenoszone między różnymi językami docelowymi.
Jak rozumiesz indeksowanie stron od zera?
IronPDF stosuje indeksy stron zaczynające się od zera w całym swoim API. Strona 0 to pierwsza strona fizyczna, strona 1 to druga i tak dalej. Podczas tworzenia tablicy indeksowej należy liczyć od zera, a nie od jedynki. Indeks poza zakresem powoduje wygenerowanie błędu ArgumentOutOfRangeException, dlatego przed wywołaniem funkcji CopyPages w kodzie produkcyjnym należy zawsze sprawdzić wartości tablicy względem PdfDocument.PageCount.
Bezpiecznym wzorcem walidacji jest sprawdzenie, czy każdy indeks w tablicy mieści się w zakresie [0, PageCount - 1] przed przekazaniem tablicy do jakiejkolwiek metody kopiowania strony. Zapobiega to wyjątkom w czasie wykonywania w sytuacjach, gdy dokument wejściowy zmienia formę między etapami przetwarzania.
Jak można zmienić kolejność wielu stron jednocześnie?
Gdy dokument PDF zawiera wiele stron, można zmienić całą strukturę w jednym przejściu. Poniższy kod pokazuje, jak odwrócić kolejność wszystkich stron lub utworzyć dowolną sekwencję poprzez programowe obliczenie tablicy indeksowej.
using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");Imports IronPdf
' Load PDF document with several pages
Dim doc = PdfDocument.FromFile("quarterly-report.pdf")
Dim count As Integer = doc.PageCount
' Build reversed single-page PDFs
Dim pages As New List(Of PdfDocument)()
For i As Integer = count - 1 To 0 Step -1
' Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i))
Next
' Merge all the reversed single-page PDFs
Using reversed = PdfDocument.Merge(pages.ToArray())
' Save to a new filename
reversed.SaveAs("report-reversed.pdf")
End UsingOdwrócony wydruk stron PDF

Ten kod ładuje plik PDF, wysyła zapytanie PageCount i tworzy listę, która odwraca kolejność stron. Pętla for dynamicznie tworzy nowy porządek, dzięki czemu podejście to można skalować do dokumentów o dowolnej długości. Ten sam wzorzec można dostosować do dowolnego nietrywialnego porządkowania: alfabetycznego według metadanych, sortowanego według rozmiaru pliku w przypadku wyodrębniania poszczególnych stron z wielu źródeł lub losowego w przypadku anonimowych danych testowych.
Można również zamienić dokładnie dwie strony bez konieczności odtwarzania całej listy. Aby zamienić strony 0 i 2, pozostawiając stronę 1 na swoim miejscu w dokumencie składającym się z trzech stron, należy przekazać new int[] { 2, 1, 0 } jako tablicę indeksową. Dokumentacja dotycząca manipulacji stronami w IronPDF zawiera dodatkowe przykłady kopiowania, wstawiania i usuwania stron.
Jak efektywnie radzić sobie z dużymi dokumentami?
W przypadku dokumentów liczących setki stron wywołanie CopyPage w ciasnej pętli powoduje przydzielenie wielu obiektów pośrednich. Bardziej wydajną alternatywą jest jednorazowe utworzenie pełnej tablicy indeksowej i przekazanie jej bezpośrednio do CopyPages. Przeładowanie CopyPages(IEnumerable<int>) wykonuje całą zmianę kolejności w jednym wewnętrznym przebiegu, co jest szybsze i zużywa mniej pamięci niż scalanie indywidualnie skopiowanych stron.
Podczas przetwarzania dużych partii plików PDF należy rozważyć szybkie usuwanie obiektów pośrednich PdfDocument za pomocą instrukcji using lub jawnych wywołań Dispose(). Moduł czyszczący pamięć .NET zarządza pamięcią automatycznie, ale szybkie zwalnianie zasobów niezarządzanych zmniejsza szczytowe zużycie pamięci w usługach o dużej przepustowości.
Jak przenieść pojedynczą stronę w nowe miejsce?
Przeniesienie jednej strony w inne miejsce wymaga połączenia operacji kopiowania, usuwania i wstawiania. Metoda InsertPdf umieszcza PdfDocument w dowolnym miejscu dokumentu docelowego.
using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");Imports IronPdf
' Load the input PDF file
Dim pdf = PdfDocument.FromFile("presentation.pdf")
Dim sourceIndex As Integer = 1 ' page to move
Dim targetIndex As Integer = 3 ' destination position
' Track direction to handle index shift after removal
Dim movingForward As Boolean = targetIndex > sourceIndex
' 1. Copy the page to move (produces a one-page PdfDocument)
Dim pageDoc = pdf.CopyPage(sourceIndex)
' 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex)
' 3. Adjust target index if moving forward (removal shifts remaining pages left)
If movingForward Then
targetIndex -= 1
End If
' 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex)
' Save the result
pdf.SaveAs("presentation-reordered.pdf")Oryginalny plik PDF a wynik

Algorytm kopiuje stronę źródłową, usuwa ją z dokumentu (co powoduje przesunięcie wszystkich kolejnych indeksów stron o jeden w dół), dostosowuje indeks docelowy, aby uwzględnić to przesunięcie, a następnie wstawia stronę w skorygowanej pozycji. Ten wzorzec poprawnie obsługuje zarówno ruchy do przodu, jak i do tyłu. Użyj go, gdy potrzebujesz precyzyjnej kontroli nad jedną lub dwiema stronami bez konieczności przebudowywania całego dokumentu.
W sytuacjach, które wymagają wstawienia treści z drugiego pliku PDF zamiast przenoszenia istniejącej strony, InsertPdf akceptuje dowolny PdfDocument jako pierwszy argument, w tym dokumenty wygenerowane z HTML przy użyciu interfejsu API IronPDF HTML-to-PDF.
Jak usuwać strony i zmieniać ich kolejność za pomocą MemoryStream?
Aplikacje automatyzujące przepływ pracy z plikami PDF czasami muszą przetwarzać dokumenty bez zapisywania plików pośrednich na dysku. Wczytywanie z tablicy bajtów i eksportowanie do MemoryStream pozwala na przetwarzanie w pamięci, co przyspiesza operacje przejściowe i pozwala uniknąć problemów z uprawnieniami do systemu plików w środowiskach kontenerowych lub bezserwerowych.
using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);Imports IronPdf
Imports System.IO
' Load PDF from byte array (simulating input from a database or API response)
Dim pdfBytes As Byte() = File.ReadAllBytes("report-with-blank.pdf")
Dim pdf As New PdfDocument(pdfBytes)
' Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2)
' Reorder remaining pages: new sequence from a four-page document
Dim reorderedPdf = pdf.CopyPages(New Integer() {1, 0, 2, 3})
' Export to MemoryStream for further processing (e.g., HTTP response body)
Dim outputStream As MemoryStream = reorderedPdf.Stream
' Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData)Konstruktor PdfDocument przyjmuje bezpośrednio byte[], a właściwość Stream zwraca wynikowy plik PDF jako MemoryStream. Ten wzorzec pasuje do kontrolerów .NET Core, które zwracają odpowiedzi plikowe, funkcji Azure, które odczytują i zapisują dane w magazynie obiektów Blob, oraz usług działających w tle, które przetwarzają partie plików PDF z kolejki komunikatów. Biblioteka efektywnie zarządza pamięcią nawet w przypadku dużych dokumentów z osadzonymi obrazami.
Zapoznaj się z dokumentacją API PdfDocument, aby poznać pełen zestaw metod operacji na stronach, w tym obracanie, wyodrębnianie i stemplowanie.
Jak przetwarzać strony PDF w kontrolerze ASP.NET Core?
Zwrot pliku PDF o zmiennej kolejności bezpośrednio z kontrolera jest prosty. Wywołaj RemovePage lub CopyPages w załadowanym dokumencie, a następnie wpisz BinaryData w odpowiedzi:
using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}Imports IronPdf
Imports Microsoft.AspNetCore.Mvc
Imports System.IO
<ApiController>
<Route("api/pdf")>
Public Class PdfController
Inherits ControllerBase
<HttpPost("reorder")>
Public Function Reorder(file As IFormFile, <FromQuery> order As String) As IActionResult
' Parse comma-separated page indexes from query string
Dim indexes = order.Split(","c).Select(Function(s) Integer.Parse(s)).ToArray()
Using stream = file.OpenReadStream()
Using ms = New MemoryStream()
stream.CopyTo(ms)
Dim pdf = New PdfDocument(ms.ToArray())
Dim reordered = pdf.CopyPages(indexes)
' Return the reordered PDF as a downloadable file
Return File(reordered.BinaryData, "application/pdf", "reordered.pdf")
End Using
End Using
End Function
End ClassTen kontroler odczytuje przesłany plik, przyjmuje kolejność stron rozdzieloną przecinkami za pośrednictwem ciągu zapytania i wysyła z powrotem zmieniony plik PDF jako odpowiedź. W żadnym momencie nie są zapisywane żadne pliki tymczasowe. To samo podejście sprawdza się przy generowaniu plików PDF w ASP.NET Core z HTML lub szablonów.
Jak połączyć pliki PDF po zmianie kolejności?
Zmiana kolejności stron często wiąże się z łączeniem treści z wielu plików źródłowych. Metoda PdfDocument.Merge biblioteki IronPDF przyjmuje tablicę obiektów PdfDocument i łączy je w podanej kolejności, co w naturalny sposób współgra z technikami kopiowania stron przedstawionymi powyżej.
using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");Imports IronPdf
' Load two separate PDF files
Dim docA = PdfDocument.FromFile("section-a.pdf")
Dim docB = PdfDocument.FromFile("section-b.pdf")
' Reorder pages within each source document
Dim reorderedA = docA.CopyPages(New Integer() {1, 0, 2})
Dim reorderedB = docB.CopyPages(New Integer() {0, 2, 1})
' Merge into a single output document
Using combined = PdfDocument.Merge(reorderedA, reorderedB)
combined.SaveAs("combined-report.pdf")
End UsingPo scaleniu wynikowy dokument zawiera wszystkie strony z reorderedA, a następnie wszystkie strony z reorderedB. Możesz połączyć dodatkowe wywołania Merge lub przekazać więcej dokumentów, aby połączyć dowolną liczbę źródeł. Dokumentacja dotycząca scalania i dzielenia plików w IronPDF obejmuje dzielenie dokumentów na poszczególne sekcje, co jest operacją odwrotną.
Aby uzyskać bardziej szczegółowe informacje na temat łączenia tablic bajtów i dokumentów przechowywanych w pamięci, w przewodniku dotyczącym łączenia plików PDF z tablic bajtów w języku C# omówiono procesy oparte na bazach danych, w których dokumenty są przechowywane jako obiekty binarne, a nie ścieżki do plików.
Jakie są najlepsze praktyki w zakresie zarządzania stronami PDF?
Nawyki związane z kodowaniem defensywnym zapobiegają subtelnym błędom i awariom produkcyjnym podczas manipulowania stronami PDF na dużą skalę. Konsekwentne stosowanie tych praktyk sprawia, że kod służący do zmiany kolejności stron jest łatwiejszy do testowania i utrzymania.
Zawsze sprawdzaj indeksy stron względem PdfDocument.PageCount przed przekazaniem ich do CopyPages lub RemovePage. Indeks wykraczający poza [0, PageCount - 1] powoduje wygenerowanie błędu ArgumentOutOfRangeException w czasie wykonywania. Jednowierszowa kontrola zabezpieczająca całkowicie eliminuje tę kategorię błędów.
W przypadku zmian kolejności stron w wielostronicowych dokumentach preferuj nadpisywanie CopyPages(IEnumerable<int>) zamiast ręcznego przechodzenia przez pętlę CopyPage. Przeciążenie wsadowe przetwarza całą sekwencję w jednym przebiegu, zmniejszając zarówno alokacje, jak i czas wykonania. Wzór pętli na stronę należy zarezerwować dla przypadków, w których konieczne jest zastosowanie transformacji na stronie, takich jak obracanie poszczególnych stron przed scaleniem.
Zawiąż obiekty pośrednie PdfDocument w instrukcjach using, aby zapewnić, że ich zasoby niezarządzane zostaną zwolnione natychmiast po użyciu. Jest to szczególnie ważne w przypadku modułów obsługi żądań sieciowych i zadań w tle, gdzie w pamięci może gromadzić się wiele dokumentów, jeśli obiekty pośrednie nie zostaną szybko usunięte. Przewodnik rozwiązywania problemów IronPDF szczegółowo omawia typowe problemy związane z pamięcią i wydajnością.
Podczas tworzenia procesów automatyzacji dokumentów warto rozważyć oddzielenie logiki zmiany kolejności od operacji wejścia/wyjścia plików. Zaakceptuj i zwróć byte[] lub MemoryStream w warstwie usług, aby zapewnić szybkie działanie testów jednostkowych i uniknąć zależności od systemu plików. Przykłady IronPDF dotyczące operacji na stronach PDF pokazują obok siebie wzorce zarówno dla ścieżek plików, jak i przepływów pracy w pamięci.
Jakie są Twoje kolejne kroki?
Zmiana kolejności stron w pliku PDF w języku C# za pomocą IronPDF sprowadza złożone zadanie manipulacji dokumentem do kilku wywołań metod. Główne techniki omówione w tym artykule obejmują zmianę kolejności stron za pomocą tablicy indeksowej przy użyciu CopyPages, odwracanie wszystkich stron programowo za pomocą pętli, przenoszenie pojedynczej strony poprzez połączenie CopyPage, RemovePage oraz InsertPdf, usuwanie niepotrzebnych stron przed zmianą kolejności oraz przetwarzanie dokumentów w całości w pamięci przy użyciu tablic bajtów i MemoryStream.
Każdy z tych wzorców integruje się z pozostałymi funkcjami pakietu IronPDF. Po zmianie kolejności stron można dodać znak wodny lub stempel, przyciąć poszczególne strony lub dodać numery stron przed dostarczeniem ostatecznej wersji dokumentu. Poradniki IronPDF zawierają przykłady kodu dla każdej z tych operacji.
Zacznij od bezpłatnej licencji próbnej, aby przetestować zmianę kolejności stron i wszystkie inne funkcje IronPDF we własnym środowisku. Gdy będziesz gotowy do wdrożenia, zapoznaj się z opcjami licencyjnymi IronPDF, aby znaleźć poziom odpowiadający wymaganiom Twojego projektu. Dokumentacja IronPDF i opis obiektów są dostępne zawsze, gdy chcesz zapoznać się z zaawansowanymi scenariuszami, takimi jak podpisy cyfrowe, zgodność z PDF/A i tagowanie dostępności.
Często Zadawane Pytania
Jak zmienić kolejność stron w pliku PDF w języku C# przy użyciu IronPDF?
Załaduj plik PDF za pomocą PdfDocument.FromFile, utwórz tablicę int[] określającą żądaną kolejność stron zaczynającą się od zera, a następnie wywołaj pdf.CopyPages(indexArray) i zapisz wynik za pomocą SaveAs.
Czym jest indeksowanie stron od zera w IronPDF?
IronPDF numeruje strony, zaczynając od 0. Pierwsza strona ma indeks 0, druga — 1 i tak dalej. Zawsze sprawdzaj, czy każdy indeks w tablicy mieści się w przedziale [0, PageCount - 1] przed wywołaniem funkcji CopyPages.
Czy mogę zmienić kolejność stron w pliku PDF bez zapisywania pliku tymczasowego?
Tak. Załaduj plik PDF z tablicy bajtów [] za pomocą new PdfDocument(bytes), wywołaj metodę CopyPages, a następnie uzyskaj dostęp do wyniku poprzez reorderedPdf.BinaryData lub reorderedPdf.Stream bez zapisywania w systemie plików.
Jak przenieść pojedynczą stronę w inne miejsce w pliku PDF?
Należy zastosować schemat trzyetapowy: wywołać CopyPage(sourceIndex) w celu wyodrębnienia strony, wywołać RemovePage(sourceIndex) w celu usunięcia jej z dokumentu, a następnie wywołać InsertPdf(pageDoc, targetIndex) w celu umieszczenia jej w nowej pozycji. Podczas przesuwania się do przodu należy skorygować indeks docelowy o -1, aby uwzględnić Shift spowodowany usunięciem.
Jak usunąć stronę z pliku PDF w języku C#?
Wywołaj PDF.RemovePage(index), gdzie index to numer strony (liczony od zera) do usunięcia. Po usunięciu wszystkie kolejne indeksy stron przesuwają się o jeden w dół.
Czy mogę zwrócić plik PDF z nową kolejnością z kontrolera ASP.NET Core?
Tak. Załaduj przesłany plik do tablicy byte[], wywołaj metodę CopyPages z żądaną tablicą indeksów, a następnie zwróć File(reordered.BinaryData, "application/PDF", "reordered.PDF") z akcji kontrolera.
Jak połączyć wiele plików PDF w jednym dokumencie?
Wywołaj metodę CopyPages dla każdego dokumentu źródłowego, aby utworzyć niezależnie uporządkowane obiekty PdfDocument, a następnie przekaż je wszystkie do metody PdfDocument.Merge(docA, docB), aby uzyskać pojedynczy, połączony plik wyjściowy.
Jaki jest najbardziej efektywny sposób zmiany kolejności stron w dużym pliku PDF?
Zastosuj przeciążenie CopyPages(IEnumerable z pełną tablicą indeksową zamiast wywoływać CopyPage w pętli. Przeciążenie wsadowe przetwarza całą sekwencję w jednym wewnętrznym przebiegu, zmniejszając alokacje i czas wykonania.














