
C#에서 PDF를 TIFF로 변환하는 방법
C#을 사용하여 PDF 파일에서 페이지를 재배치하면 보고서를 재구성하거나, 계약 부록을 재정렬하거나, 문서 패키지를 재구성하는 데 수작업을 줄일 수 있습니다. IronPDF는 PDF를 로드하고, 새 페이지 순서를 지정하고, 결과를 저장하는 간단한 API를 제공합니다. 이는 몇 줄의 .NET 코드로 가능합니다. 이 기사는 5가지 실제 기술을 다룹니다: 기본 페이지 재정렬, 대량 역순 처리, 단일 페이지를 새 인덱스로 이동, 불필요한 페이지 삭제, 파일 시스템을 건드리지 않고 완전히 메모리로 작업하기.
IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");Imports IronPdf
PdfDocument.FromFile("input.pdf") _
.CopyPages({2, 0, 1, 3}) _
.SaveAs("reordered.pdf")IronPDF를 어떻게 시작합니까?
NuGet 패키지 관리자 또는 .NET CLI를 사용하여 몇 초 만에 IronPDF를 .NET 8 또는 .NET 10 프로젝트에 추가하십시오. Windows, Linux, macOS에서 추가적인 런타임 종속성이나 네이티브 바이너리가 필요하지 않습니다.
dotnet add package IronPdf
패키지가 설치되면, C# 파일 상단에 using IronPdf;을 추가하세요. 유효한 라이선스 키가 전체 상업적 사용을 해제합니다; 무료 체험 라이선스가 평가를 위해 제공됩니다. API를 호출하기 전에 키를 설정하세요:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"패키지를 참조하고 라이센스가 구성되면, 이 기사에 있는 모든 예제는 수정 없이 실행됩니다. IronPDF NuGet 패키지는 .NET Standard 2.0 이상을 대상으로 하므로 .NET Framework 4.6.2+, .NET Core 및 모든 최신 .NET 버전에서 작동합니다.
C#에서 페이지 재정렬은 어떻게 작동하나요?
C#를 사용하여 PDF의 페이지를 재배열하는 과정에는 원본 문서를 로드하고, 페이지 인덱스 배열을 통해 원하는 페이지 순서를 지정한 후 출력 파일을 저장하는 작업이 포함됩니다. IronPDF는 PDF에서 CopyPages 메서드를 통해 페이지를 추출하고, 새 PdfDocument 객체로 재정렬합니다.
다음 코드는 int 배열을 만들어 목표 시퀀스를 정의하여 페이지를 재정렬하는 방법을 보여줍니다. 배열의 각 값은 원본 문서에서의 페이지 인덱스를 나타내며, 페이지는 0부터 시작하는 인덱싱을 사용합니다 (페이지 0은 첫 페이지입니다).
using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");Imports IronPdf
' Load the source document from file path
Dim pdf As PdfDocument = PdfDocument.FromFile("quarterly-report.pdf")
' Define new page order: move page 3 to front, then pages 1, 2, 0
Dim pageOrder As Integer() = {3, 1, 2, 0}
' Copy each requested page into its own PdfDocument
Dim pageDocs As New List(Of PdfDocument)()
For Each idx In pageOrder
' CopyPage returns a PdfDocument containing only that page
Dim single As PdfDocument = pdf.CopyPage(idx)
pageDocs.Add(single)
Next
' Merge the single-page docs into one ordered document
Using merged As PdfDocument = PdfDocument.Merge(pageDocs.ToArray())
' Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf")
End UsingPDF 문서 출력
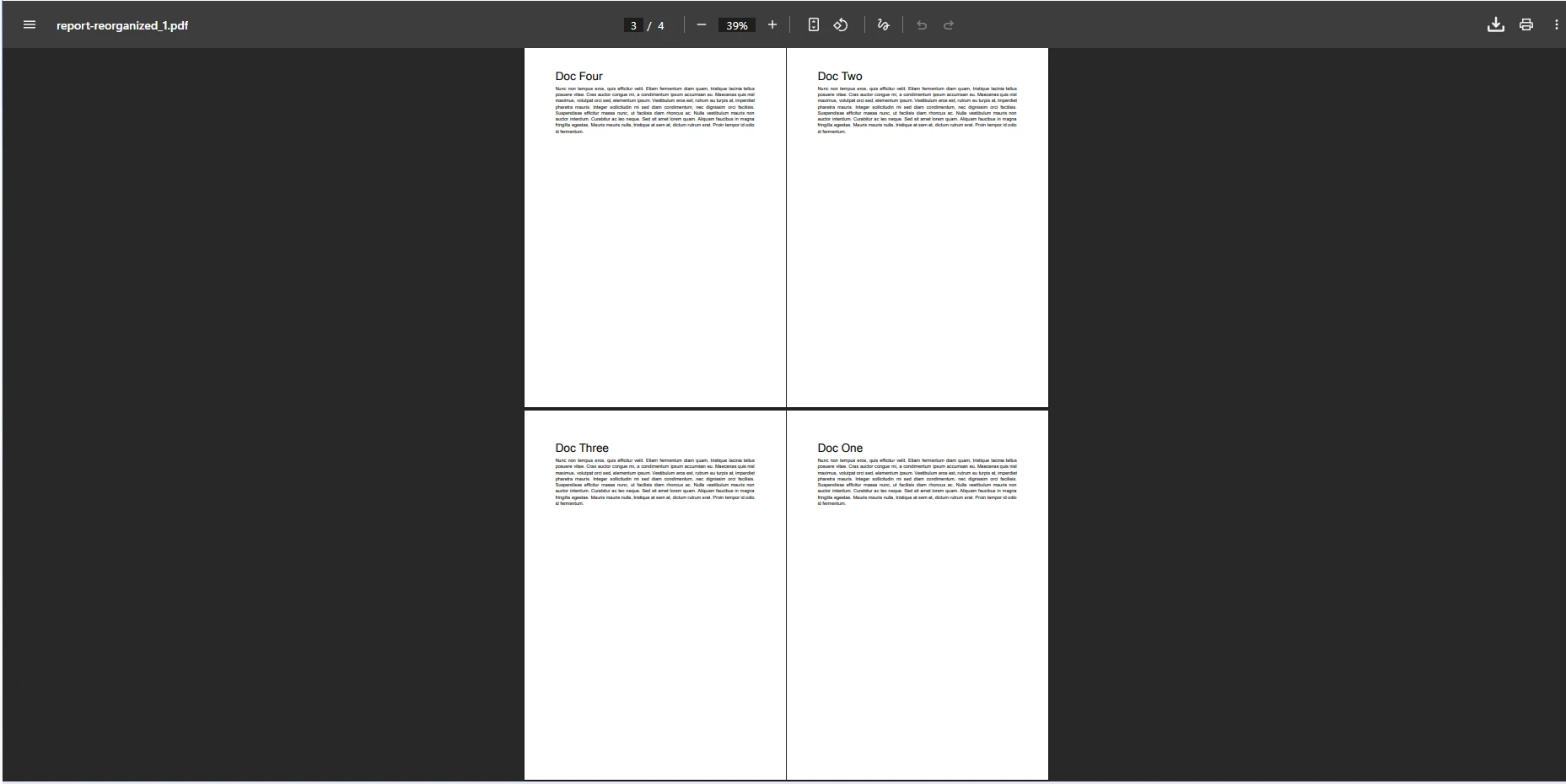
CopyPages 메서드는 원하는 배열과 매칭되는 페이지 인덱스 값을 가진 IEnumerable<int>을 허용합니다. 이 접근법으로 PDF 페이지를 재배치하거나, 특정 페이지를 복제하거나, 서브셋을 별도의 문서로 추출할 수 있습니다. 이 메서드는 원본 문서를 변경하지 않고 새로운 PdfDocument 객체를 반환합니다. 원본은 절대로 변경되지 않으므로 CopyPages을 여러 번 호출하여 같은 원본 파일에서 다른 순서를 안전하게 생성할 수 있습니다.
Java 환경에서 작업하는 팀을 위해, IronPDF Java용는 유사한 페이지 조작 메서드와 호환 가능한 API 표면을 제공하므로, 언어 대상 간에 기술 전환이 가능합니다.
제로 기반 페이지 인덱싱을 어떻게 이해합니까?
IronPDF는 API 전체에 걸쳐 제로 기반 페이지 인덱스를 사용합니다. 페이지 0은 첫 물리적인 페이지이고, 페이지 1은 두 번째 페이지입니다. 인덱스 배열을 만들 때, 숫자를 1이 아니라 0부터 세어야 합니다. 범위를 벗어난 인덱스는 ArgumentOutOfRangeException를 던지므로, 프로덕션 코드에서 CopyPages을 호출하기 전에 항상 PdfDocument.PageCount와 배열 값을 검증하세요.
안전한 검증 패턴은 배열의 모든 인덱스가 [0, PageCount - 1]에 속하는지를 확인한 후, 어떤 페이지 복사 메서드에도 배열을 넘기기 전에 이러한 단계를 준수하는 것입니다. 이는 처리 단계 사이에 입력 문서의 형태가 변경되는 시나리오에서 런타임 예외를 방지합니다.
여러 페이지를 한 번에 재배치할 수 있습니까?
PDF 문서에 여러 페이지가 포함될 경우 단 한 번의 작업으로 전체 구조를 재배열할 수 있습니다. 아래 코드는 모든 페이지를 반전시키거나 프로그래매틱하게 인덱스 배열을 계산하여 사용자 정의 시퀀스를 만드는 방법을 보여줍니다.
using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");Imports IronPdf
' Load PDF document with several pages
Dim doc = PdfDocument.FromFile("quarterly-report.pdf")
Dim count As Integer = doc.PageCount
' Build reversed single-page PDFs
Dim pages As New List(Of PdfDocument)()
For i As Integer = count - 1 To 0 Step -1
' Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i))
Next
' Merge all the reversed single-page PDFs
Using reversed = PdfDocument.Merge(pages.ToArray())
' Save to a new filename
reversed.SaveAs("report-reversed.pdf")
End Using반전된 PDF 페이지 출력

이 코드는 PDF 파일을 로드하고 PageCount에 대한 쿼리를 수행하며, 페이지 순서를 뒤집는 목록을 구성합니다. for 루프는 새 순서를 동적으로 만들어, 어떤 길이의 문서에도 이 접근법을 확장할 수 있게 합니다. 메타데이터에 따라 알파벳 순서로, 여러 소스에서 개별 페이지를 추출할 경우 파일 크기에 따라 정렬하거나 익명화된 테스트 데이터를 위해 무작위로 셔플하는 등 이 패턴을 임의의 비표준 주문에 적용할 수 있습니다.
전체 목록을 새로 만들지 않고도 정확히 두 페이지를 교환할 수 있습니다. 세 페이지짜리 문서에서 페이지 0과 2를 교환하고 페이지 1을 제자리에 두려면, 인덱스 배열로 new int[] { 2, 1, 0 }을 전달하세요. IronPDF 페이지 조작 문서에는 페이지를 복사, 삽입 및 삭제하는 추가 예제가 포함되어 있습니다.
대용량 문서를 효율적으로 처리하는 방법은 무엇입니까?
수백 페이지에 달하는 문서의 경우, CopyPage을 타이트한 루프에서 호출하면 많은 중간 객체가 할당됩니다. 보다 효율적인 대안은 전체 인덱스 배열을 한 번 작성하고 CopyPages에 직접 전달하는 것입니다. CopyPages(IEnumerable<int>) 오버로드는 모든 재정렬 작업을 단일 내부 단계에서 수행하여 별도로 복사된 페이지를 병합하는 것보다 더 빠르고 메모리를 덜 사용합니다.
대량의 PDF 작업 시, 중간 PdfDocument 객체를 신속하게 폐기하기 위해 using 문이나 명시적인 Dispose() 호출을 고려하세요. .NET 가비지 수집기는 메모리를 자동으로 관리하지만 관리되지 않는 리소스를 즉시 해제하면 고처리량 서비스를 위한 메모리 사용량을 줄입니다.
단일 페이지를 새 위치로 이동하는 방법은 무엇입니까?
다른 위치로 페이지 하나를 이동하려면 복사, 제거 및 삽입을 결합해야 합니다. InsertPdf 메서드는 대상 문서의 어떤 인덱스에서든 PdfDocument을 배치합니다.
using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");Imports IronPdf
' Load the input PDF file
Dim pdf = PdfDocument.FromFile("presentation.pdf")
Dim sourceIndex As Integer = 1 ' page to move
Dim targetIndex As Integer = 3 ' destination position
' Track direction to handle index shift after removal
Dim movingForward As Boolean = targetIndex > sourceIndex
' 1. Copy the page to move (produces a one-page PdfDocument)
Dim pageDoc = pdf.CopyPage(sourceIndex)
' 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex)
' 3. Adjust target index if moving forward (removal shifts remaining pages left)
If movingForward Then
targetIndex -= 1
End If
' 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex)
' Save the result
pdf.SaveAs("presentation-reordered.pdf")원본 PDF vs. 출력

알고리즘은 소스 페이지를 복사하여 문서에서 제거합니다(이는 모든 이후 페이지 인덱스가 하나씩 아래로 이동함을 의미), 해당 이동을 고려하여 대상 인덱스를 조정한 다음 수정된 위치에 페이지를 삽입합니다. 이 패턴은 순방향과 역방향 이동을 모두 올바르게 처리합니다. 전체 문서를 재구성하지 않고 1~2페이지에 대한 세밀한 제어가 필요할 때 사용하세요.
기존 페이지를 이동하는 대신 두 번째 PDF에서 콘텐츠를 삽입해야 하는 상황을 위해, InsertPdf은 HTML에서 생성된 문서를 포함한 모든 PdfDocument을 첫 번째 인수로 허용합니다. IronPDF HTML-to-PDF API.
MemoryStream을 사용하여 페이지를 삭제하고 재정렬하는 방법은 무엇입니까?
PDF 워크플로를 자동화하는 애플리케이션은 때때로 중간 파일을 디스크에 쓰지 않고 문서를 조작해야 합니다. 바이트 배열에서 로드하고 MemoryStream로 내보내면 모든 처리가 메모리에서 이루어져, 일시적 작업에 더 빠르고 컨테이너화 또는 서버리스 환경에서 파일 시스템 권한 문제를 피합니다.
using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);Imports IronPdf
Imports System.IO
' Load PDF from byte array (simulating input from a database or API response)
Dim pdfBytes As Byte() = File.ReadAllBytes("report-with-blank.pdf")
Dim pdf As New PdfDocument(pdfBytes)
' Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2)
' Reorder remaining pages: new sequence from a four-page document
Dim reorderedPdf = pdf.CopyPages(New Integer() {1, 0, 2, 3})
' Export to MemoryStream for further processing (e.g., HTTP response body)
Dim outputStream As MemoryStream = reorderedPdf.Stream
' Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData)PdfDocument 생성자는 byte[]을 직접 받아들이며, Stream 속성은 MemoryStream로 결과 PDF를 반환합니다. 이 패턴은 ASP.NET Core 컨트롤러가 파일 응답을 반환하거나 Blob Storage에 읽고 쓰는 Azure Functions 및 메시지 큐에서 PDF 배치를 처리하는 백그라운드 서비스에 적합합니다. 이 라이브러리는 임베디드 이미지를 포함해 큰 문서에 대해서도 메모리 관리를 효율적으로 처리합니다.
PdfDocument API 참조를 참조하여 회전, 추출 및 스탬핑을 포함한 페이지 작업 방법의 전체 세트를 탐색하세요.
PDF 페이지를 ASP.NET Core 컨트롤러에서 처리하는 방법은 무엇입니까?
컨트롤러에서 일괄 정렬된 PDF를 직접 반환하는 것은 간단합니다. 로드된 문서에서 RemovePage 또는 CopyPages을 호출한 다음, BinaryData을 응답으로 씁니다:
using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}Imports IronPdf
Imports Microsoft.AspNetCore.Mvc
Imports System.IO
<ApiController>
<Route("api/pdf")>
Public Class PdfController
Inherits ControllerBase
<HttpPost("reorder")>
Public Function Reorder(file As IFormFile, <FromQuery> order As String) As IActionResult
' Parse comma-separated page indexes from query string
Dim indexes = order.Split(","c).Select(Function(s) Integer.Parse(s)).ToArray()
Using stream = file.OpenReadStream()
Using ms = New MemoryStream()
stream.CopyTo(ms)
Dim pdf = New PdfDocument(ms.ToArray())
Dim reordered = pdf.CopyPages(indexes)
' Return the reordered PDF as a downloadable file
Return File(reordered.BinaryData, "application/pdf", "reordered.pdf")
End Using
End Using
End Function
End Class이 컨트롤러는 업로드된 파일을 읽고, 쿼리 문자열을 통해 쉼표로 구분된 페이지 순서를 수락하며, 재정렬된 PDF를 응답으로 스트림합니다. 어느 것도 중간 파일에 기록되지 않습니다. 동일한 접근법은 HTML이나 템플릿에서 ASP.NET Core에서 PDF 생성에 대해서도 사용할 수 있습니다.
재배열 후 PDF를 병합하는 방법은 무엇입니까?
페이지 재배치는 종종 여러 소스 파일에서 콘텐츠를 결합하는 것과 함께 이루어집니다. IronPDF의 PdfDocument.Merge 메서드는 PdfDocument 객체 배열을 받아 제공된 순서로 이를 결합하며, 이는 위에 설명된 페이지 복사 기술과 자연스럽게 결합됩니다.
using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");Imports IronPdf
' Load two separate PDF files
Dim docA = PdfDocument.FromFile("section-a.pdf")
Dim docB = PdfDocument.FromFile("section-b.pdf")
' Reorder pages within each source document
Dim reorderedA = docA.CopyPages(New Integer() {1, 0, 2})
Dim reorderedB = docB.CopyPages(New Integer() {0, 2, 1})
' Merge into a single output document
Using combined = PdfDocument.Merge(reorderedA, reorderedB)
combined.SaveAs("combined-report.pdf")
End Using병합 후, 결과 문서에는 reorderedA의 모든 페이지가 reorderedB의 모든 페이지 다음에 포함됩니다. 추가적인 Merge 호출을 체인하거나 더 많은 문서를 전달하여 원하는 출처의 수만큼 조합할 수 있습니다. IronPDF 병합 및 분할 문서는 문서를 개별 섹션으로 나누는 작업을 다룹니다. 이는 역연산입니다.
C#에서 바이트 배열에서 PDF 병합에 대한 가이드는 문서를 파일 경로 대신 바이너리 블롭으로 저장하는 데이터베이스 기반 워크플로를 설명합니다.
PDF 페이지 관리에 대한 모범 사례는 무엇입니까?
대규모 PDF 페이지를 조작할 때 방어적인 코딩 습관은 미세한 버그와 생산 문제를 방지합니다. 이러한 관행을 일관되게 적용함으로써 페이지 재배열 코드를 테스트 및 유지 관리하기 더 쉽게 만듭니다.
CopyPages 또는 RemovePage에게 전달하기 전에 항상 페이지 인덱스를 PdfDocument.PageCount과 확인하세요. [0, PageCount - 1]을 벗어난 인덱스는 런타임에 ArgumentOutOfRangeException을 발생시킵니다. 한 줄짜리 보호 검사로 이러한 실패 유형을 완전히 제거할 수 있습니다.
다중 페이지 재정렬 시, 수동으로 CopyPage를 순회하는 것보다 CopyPages(IEnumerable<int>) 오버로드를 선호하세요. 배치 오버로드는 전체 시퀀스를 단일 패스로 처리하여 할당과 실행 시간을 모두 줄입니다. 개별 페이지를 병합하기 전에 회전 등의 페이지별 변형을 적용해야 하는 경우를 위해 페이지별 반복 패턴을 예약하십시오.
중간 PdfDocument 객체를 using 문으로 감싸 사용 후에 관리되지 않은 리소스가 즉시 해제되도록 보장하세요. 이는 웹 요청 핸들러 및 백그라운드 작업에서 특히 중요하며, 중간 개체가 신속하게 폐기되지 않으면 많은 문서가 메모리에 축적될 수 있습니다. IronPDF 문제 해결 가이드는 일반적인 메모리 및 성능 패턴을 자세히 다룹니다.
문서 자동화 파이프라인을 구축할 때, 파일 입출력에서 재정렬 로직을 분리하는 것을 고려하세요. 단위 테스트를 빠르게 유지하고 파일 시스템 종속성을 피하기 위해 서비스 레이어에서 byte[] 또는 MemoryStream을 수용하고 반환하세요. PDF 페이지 작업을 위한 IronPDF 예제는 파일 경로 및 메모리 내 워크플로 패턴을 나란히 보여줍니다.
다음 단계는 무엇입니까?
IronPDF와 함께 C#에서 PDF 페이지를 재배열하면 복잡한 문서 조작 작업을 소수의 메서드 호출로 줄일 수 있습니다. 이 글에서 다룬 주요 기술에는 CopyPages을 이용하여 인덱스 배열을 통한 페이지 재정렬, 루프를 사용한 모든 페이지 프로그래밍적 뒤집기, CopyPage, RemovePage, InsertPdf을 결합하여 단일 페이지 이동, 재배열 전에 필요한 페이지 삭제, 바이트 배열 및 MemoryStream을 사용하여 메모리에서 문서를 완전히 처리하는 것이 포함됩니다.
이러한 패턴 각각은 IronPDF 기능 세트의 나머지 부분과 통합됩니다. 페이지를 재배열한 후, 최종 문서를 전달하기 전에 워터마크 또는 스탬프 추가, 개별 페이지 자르기 또는 페이지 번호 추가를 수행할 수 있습니다. IronPDF 사용 방법 가이드는 각각의 후속 작업에 대한 코드 예제를 제공합니다.
자신의 환경에서 페이지 재정렬 및 모든 다른 IronPDF 기능을 테스트하기 위해 무료 체험판 라이선스로 시작하십시오. 배포할 준비가 되면, IronPDF 라이선스 옵션을 검토하여 프로젝트의 요구 사항에 맞는 티어를 찾으십시오. IronPDF 문서와 객체 참조는 디지털 서명, PDF/A 준수, 접근성 태그 지정과 같은 고급 시나리오를 탐색해야 할 때마다 사용할 수 있습니다.
자주 묻는 질문
IronPDF를 사용하여 C#에서 PDF 페이지를 어떻게 재배치할 수 있나요?
PdfDocument.FromFile로 PDF를 로드하고, 원하는 0 기반 페이지 순서를 지정하는 int[]를 생성한 다음 pdf.CopyPages(indexArray)를 호출하여 결과를 SaveAs로 저장합니다.
IronPDF에서 0 기반 페이지 인덱싱이란 무엇인가요?
IronPDF는 페이지를 0부터 시작하여 번호를 매깁니다. 첫 번째 페이지는 인덱스 0이고, 두 번째는 인덱스 1입니다. CopyPages를 호출하기 전에 모든 인덱스가 [0, PageCount - 1]에 속하는지 항상 확인하세요.
임시 파일을 저장하지 않고 PDF 페이지를 재배열할 수 있나요?
네. byte[]에서 new PdfDocument(bytes)를 사용하여 PDF를 로드한 뒤 CopyPages를 호출하고, 파일 시스템에 쓰지 않고 reorderedPdf.BinaryData 또는 reorderedPdf.Stream을 통해 결과를 접근하세요.
PDF 내에서 단일 페이지를 다른 위치로 이동하려면 어떻게 하나요?
세 가지 단계 패턴을 사용하세요: CopyPage(sourceIndex)를 호출하여 페이지를 추출하고, RemovePage(sourceIndex)를 호출하여 문서에서 제거한 다음 InsertPdf(pageDoc, targetIndex)를 호출하여 새로운 위치에 배치하세요. 제거로 인한 변화를 고려하여 앞으로 이동할 때는 대상 인덱스를 -1 조정합니다.
C#에서 PDF에서 페이지를 삭제하려면 어떻게 하나요?
제거할 0 기반 페이지 번호의 인덱스를 사용하여 pdf.RemovePage(index)를 호출하세요. 삭제 후 모든 후속 페이지 인덱스가 하나씩 내려갑니다.
ASP.NET Core 컨트롤러에서 재배열된 PDF를 반환할 수 있나요?
네. 업로드된 파일을 byte[]로 로드하고, 원하는 인덱스 배열과 함께 CopyPages를 호출한 다음 File(reordered.BinaryData, "application/pdf", "reordered.pdf")를 컨트롤러 액션에서 반환하세요.
여러 재배열된 PDF를 하나의 문서로 병합하려면 어떻게 하나요?
각 소스 문서에서 CopyPages를 호출하여 독립적으로 재배열된 PdfDocument 객체를 생성한 다음 PdfDocument.Merge(docA, docB)에 모두 전달하여 하나의 결합된 출력을 생성하세요.
큰 PDF에서 페이지를 재배열하는 가장 효율적인 방법은 무엇인가요?
CopyPage를 반복 호출하는 대신 전체 인덱스 배열을 포함한 CopyPages(IEnumerable<int>) 오버로드를 사용하세요. 배치 오버로드는 단일 내부 통과에서 전체 시퀀스를 처리하여 할당과 실행 시간을 줄입니다.











