
Como converter PDF para TIFF em C#
Reorganizar páginas em um arquivo PDF usando C# elimina horas de trabalho manual quando você precisa reorganizar relatórios, reordenar anexos de contratos ou reconstruir pacotes de documentos antes da entrega. O IronPDF fornece uma API simples para carregar um PDF, especificar uma nova sequência de páginas e salvar o resultado em apenas algumas linhas de código .NET . Este artigo descreve cinco técnicas práticas: reordenação básica de páginas, reversão em massa, movimentação de uma única página para um novo índice, exclusão de páginas indesejadas e trabalho inteiramente em memória, sem acessar o sistema de arquivos.
IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");Imports IronPdf
PdfDocument.FromFile("input.pdf") _
.CopyPages({2, 0, 1, 3}) _
.SaveAs("reordered.pdf")Como começar a usar o IronPDF?
Adicione o IronPDF a qualquer projeto .NET 8 ou .NET 10 em segundos usando o Gerenciador de Pacotes NuGet ou a CLI do .NET . Não são necessárias dependências de tempo de execução adicionais nem binários nativos no Windows, Linux ou macOS.
dotnet add package IronPdf
Depois que o pacote estiver instalado, adicione using IronPdf; no topo do seu arquivo C#. Uma chave de licença válida desbloqueia o uso comercial total; Uma licença de avaliação gratuita está disponível para fins de teste. Defina sua chave antes de chamar qualquer API:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Com o pacote referenciado e a licença configurada, todos os exemplos deste artigo serão executados sem modificações. O pacote NuGet IronPDF é compatível com o .NET Standard 2.0 e versões superiores, portanto, funciona no .NET Framework 4.6.2+, .NET Core e em todas as versões modernas do .NET .
Como funciona a reordenação de páginas em C#?
O processo para reorganizar páginas em um PDF usando C# envolve carregar o documento fonte, especificar a ordem de página desejada através de um array de índices de página e salvar o arquivo de saída. IronPDF fornece o método CopyPages para extrair e reordenar páginas de um PDF em um novo objeto PdfDocument.
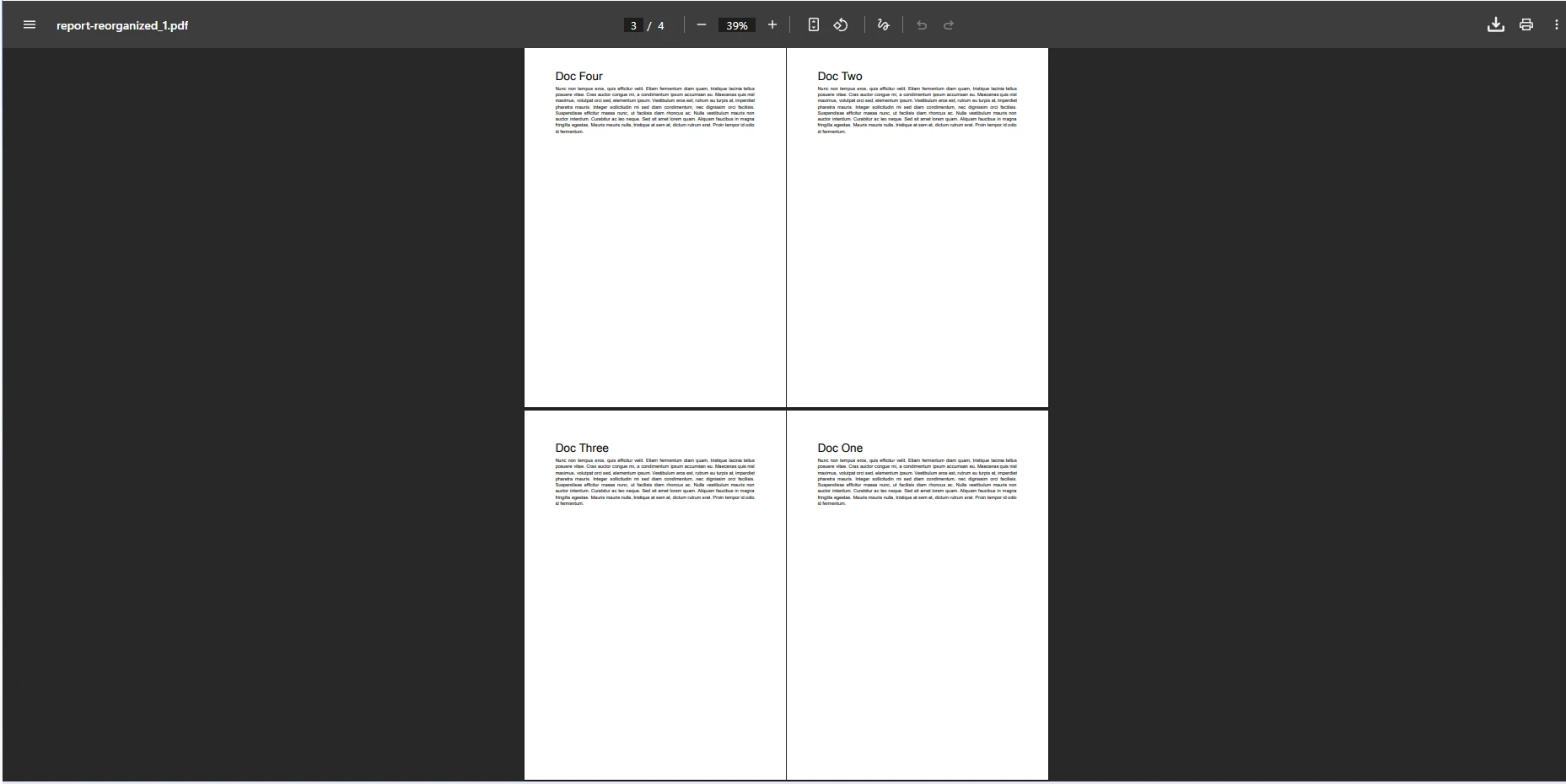
O código a seguir demonstra como reordenar páginas criando um novo array int que define a sequência alvo. Cada valor na matriz representa um índice de página do documento original, onde as páginas usam indexação baseada em zero (a página 0 é a primeira página).
using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");Imports IronPdf
' Load the source document from file path
Dim pdf As PdfDocument = PdfDocument.FromFile("quarterly-report.pdf")
' Define new page order: move page 3 to front, then pages 1, 2, 0
Dim pageOrder As Integer() = {3, 1, 2, 0}
' Copy each requested page into its own PdfDocument
Dim pageDocs As New List(Of PdfDocument)()
For Each idx In pageOrder
' CopyPage returns a PdfDocument containing only that page
Dim single As PdfDocument = pdf.CopyPage(idx)
pageDocs.Add(single)
Next
' Merge the single-page docs into one ordered document
Using merged As PdfDocument = PdfDocument.Merge(pageDocs.ToArray())
' Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf")
End UsingDocumento PDF de saída
O método CopyPages aceita um IEnumerable<int> de valores de índice de página que correspondem ao seu arranjo desejado. Essa abordagem permite reorganizar páginas de PDF, duplicar páginas específicas ou extrair um subconjunto para um documento separado. O método retorna um novo objeto PdfDocument, deixando o documento fonte original inalterado. Como o original nunca é modificado, você pode chamar CopyPages várias vezes para gerar diferentes ordenações do mesmo arquivo fonte.
Para equipes que trabalham em ambientes Java, o IronPDF for Java expõe métodos semelhantes de manipulação de páginas e uma API compatível, permitindo a transferência de habilidades entre diferentes linguagens de programação.
Como você entende a indexação de páginas baseada em zero?
O IronPDF utiliza índices de página baseados em zero em toda a sua API. A página 0 é a primeira página física, a página 1 é a segunda, e assim por diante. Ao construir seu array de índices, conte a partir de zero em vez de um. Um índice fora do intervalo lança uma ArgumentOutOfRangeException, então sempre valide os valores do array contra PdfDocument.PageCount antes de chamar CopyPages no código de produção.
Um padrão de validação seguro é verificar que cada índice no array caia dentro de [0, PageCount - 1] antes de passar o array para qualquer método de cópia de página. Isso evita exceções em tempo de execução em cenários onde o documento de entrada muda de forma entre as etapas de processamento.
Como reorganizar várias páginas ao mesmo tempo?
Quando um documento PDF contém muitas páginas, você pode reorganizar toda a estrutura de uma só vez. O código abaixo mostra como inverter todas as páginas ou criar qualquer sequência personalizada, calculando o índice do array programaticamente.
using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");Imports IronPdf
' Load PDF document with several pages
Dim doc = PdfDocument.FromFile("quarterly-report.pdf")
Dim count As Integer = doc.PageCount
' Build reversed single-page PDFs
Dim pages As New List(Of PdfDocument)()
For i As Integer = count - 1 To 0 Step -1
' Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i))
Next
' Merge all the reversed single-page PDFs
Using reversed = PdfDocument.Merge(pages.ToArray())
' Save to a new filename
reversed.SaveAs("report-reversed.pdf")
End UsingSaída de páginas PDF invertidas

Este código carrega um arquivo PDF, consulta PageCount, e constrói uma lista que inverte a sequência de páginas. O loop for constrói a nova ordem dinamicamente, permitindo que a abordagem escale para documentos de qualquer comprimento. Você pode adaptar o mesmo padrão a qualquer ordenação não trivial: alfabética por metadados, classificada por tamanho de arquivo se estiver extraindo páginas individuais de várias fontes ou embaralhada para dados de teste anonimizados.
Você também pode trocar exatamente duas páginas sem reconstruir a lista completa. Para trocar as páginas 0 e 2 enquanto mantém a página 1 no lugar em um documento de três páginas, passe new int[] { 2, 1, 0 } como seu array de índices. A documentação de manipulação de páginas do IronPDF inclui exemplos adicionais de como copiar, inserir e excluir páginas.
Como lidar com documentos extensos de forma eficiente?
Para documentos com centenas de páginas, chamar CopyPage em um loop apertado aloca muitos objetos intermediários. Uma alternativa mais eficiente é construir o array de índices completo uma vez e passá-lo diretamente para CopyPages. A sobrecarga CopyPages(IEnumerable<int>) realiza todo o reordenamento em uma única passagem interna, que é mais rápida e usa menos memória do que mesclar páginas copiadas individualmente.
Ao processar grandes lotes de PDFs, considere descartar objetos PdfDocument intermediários prontamente usando declarações using ou chamadas explícitas Dispose(). O coletor de lixo do .NET gerencia a memória automaticamente, mas a liberação imediata de recursos não gerenciados reduz o pico de uso de memória para serviços de alto desempenho.
Como mover uma única página para um novo local?
Mover uma página para uma posição diferente requer uma combinação de cópia, remoção e inserção. O método InsertPdf coloca um PdfDocument em qualquer índice dentro do documento alvo.
using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");Imports IronPdf
' Load the input PDF file
Dim pdf = PdfDocument.FromFile("presentation.pdf")
Dim sourceIndex As Integer = 1 ' page to move
Dim targetIndex As Integer = 3 ' destination position
' Track direction to handle index shift after removal
Dim movingForward As Boolean = targetIndex > sourceIndex
' 1. Copy the page to move (produces a one-page PdfDocument)
Dim pageDoc = pdf.CopyPage(sourceIndex)
' 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex)
' 3. Adjust target index if moving forward (removal shifts remaining pages left)
If movingForward Then
targetIndex -= 1
End If
' 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex)
' Save the result
pdf.SaveAs("presentation-reordered.pdf")PDF original vs. PDF de saída

O algoritmo copia a página de origem, remove-a do documento (o que desloca todos os índices de páginas subsequentes para baixo em uma posição), ajusta o índice de destino para compensar esse deslocamento e, em seguida, insere a página na posição corrigida. Este padrão lida corretamente tanto com movimentos para frente quanto para trás. Use-o quando precisar de controle preciso sobre uma ou duas páginas sem reconstruir o documento inteiro.
Para situações que exigem inserir conteúdo de um segundo PDF em vez de mover uma página existente, InsertPdf aceita qualquer PdfDocument como seu primeiro argumento, incluindo documentos gerados a partir de HTML usando o IronPDF HTML-to-PDF API.
Como excluir páginas e reordená-las usando o MemoryStream?
Aplicações que automatizam fluxos de trabalho em PDF às vezes precisam manipular documentos sem gravar arquivos intermediários no disco. Carregar a partir de um array de bytes e exportar para um MemoryStream mantém todo o processamento em memória, o que é mais rápido para operações transitórias e evita problemas de permissões no sistema de arquivos em ambientes containerizados ou sem servidor.
using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);Imports IronPdf
Imports System.IO
' Load PDF from byte array (simulating input from a database or API response)
Dim pdfBytes As Byte() = File.ReadAllBytes("report-with-blank.pdf")
Dim pdf As New PdfDocument(pdfBytes)
' Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2)
' Reorder remaining pages: new sequence from a four-page document
Dim reorderedPdf = pdf.CopyPages(New Integer() {1, 0, 2, 3})
' Export to MemoryStream for further processing (e.g., HTTP response body)
Dim outputStream As MemoryStream = reorderedPdf.Stream
' Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData)O construtor PdfDocument aceita um byte[] diretamente, e a propriedade Stream retorna o PDF resultante como um MemoryStream. Esse padrão é adequado para controladores ASP.NET Core que retornam respostas em formato de arquivo, Azure Functions que leem e gravam no Armazenamento de Blobs e serviços em segundo plano que processam lotes de PDFs a partir de uma fila de mensagens. A biblioteca gerencia a memória de forma eficiente, mesmo para documentos grandes com imagens incorporadas.
Consulte a documentação da API PdfDocument para explorar o conjunto completo de métodos de operação de página, incluindo rotação, extração e carimbo.
Como processar páginas PDF em um controlador ASP.NET Core ?
Retornar um PDF reordenado diretamente de um controlador é simples. Chame RemovePage ou CopyPages no documento carregado, então escreva BinaryData na resposta:
using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}Imports IronPdf
Imports Microsoft.AspNetCore.Mvc
Imports System.IO
<ApiController>
<Route("api/pdf")>
Public Class PdfController
Inherits ControllerBase
<HttpPost("reorder")>
Public Function Reorder(file As IFormFile, <FromQuery> order As String) As IActionResult
' Parse comma-separated page indexes from query string
Dim indexes = order.Split(","c).Select(Function(s) Integer.Parse(s)).ToArray()
Using stream = file.OpenReadStream()
Using ms = New MemoryStream()
stream.CopyTo(ms)
Dim pdf = New PdfDocument(ms.ToArray())
Dim reordered = pdf.CopyPages(indexes)
' Return the reordered PDF as a downloadable file
Return File(reordered.BinaryData, "application/pdf", "reordered.pdf")
End Using
End Using
End Function
End ClassEste controlador lê o arquivo carregado, aceita uma ordem de páginas separadas por vírgulas através de uma string de consulta e transmite o PDF reordenado como resposta. Nenhum arquivo temporário é gravado em nenhum momento. A mesma abordagem funciona para gerar PDFs em ASP.NET Core a partir de HTML ou modelos.
Como mesclar PDFs após reordená-los?
Reordenar páginas geralmente está associado à combinação de conteúdo de vários arquivos de origem. O método PdfDocument.Merge do IronPDF aceita um array de objetos PdfDocument e os une na ordem fornecida, o que se alinha naturalmente com as técnicas de cópia de página mostradas acima.
using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");Imports IronPdf
' Load two separate PDF files
Dim docA = PdfDocument.FromFile("section-a.pdf")
Dim docB = PdfDocument.FromFile("section-b.pdf")
' Reorder pages within each source document
Dim reorderedA = docA.CopyPages(New Integer() {1, 0, 2})
Dim reorderedB = docB.CopyPages(New Integer() {0, 2, 1})
' Merge into a single output document
Using combined = PdfDocument.Merge(reorderedA, reorderedB)
combined.SaveAs("combined-report.pdf")
End UsingApós a mesclagem, o documento resultante contém todas as páginas de reorderedA seguidas por todas as páginas de reorderedB. Você pode encadear chamadas Merge adicionais ou passar mais documentos para combinar qualquer número de fontes. A documentação do IronPDF sobre mesclagem e divisão aborda a divisão de documentos em seções individuais, que é a operação inversa.
Para uma análise mais aprofundada sobre a fusão de arrays de bytes e documentos em memória, o guia sobre como mesclar PDFs a partir de arrays de bytes em C# aborda fluxos de trabalho baseados em banco de dados, nos quais os documentos são armazenados como blocos binários em vez de caminhos de arquivo.
Quais são as melhores práticas para o gerenciamento de páginas em PDF?
Hábitos de programação defensiva evitam erros sutis e falhas de produção ao manipular páginas PDF em grande escala. A aplicação consistente dessas práticas facilita o teste e a manutenção do código de reordenação de páginas.
Sempre valide os índices de página contra PdfDocument.PageCount antes de passá-los para CopyPages ou RemovePage. Um índice que cai fora [0, PageCount - 1] levanta um ArgumentOutOfRangeException durante a execução. Uma verificação de guarda de uma linha elimina completamente essa categoria de falha.
Prefira a sobrecarga CopyPages(IEnumerable<int>) em relação ao loop manual através de CopyPage ao trabalhar com reordenações de várias páginas. O processamento em lote sobrecarrega a sequência completa em uma única passagem, reduzindo tanto as alocações quanto o tempo de execução. Reserve o padrão de loop por página para casos em que você precise aplicar transformações por página, como rotacionar páginas individuais antes de mesclar.
Envolva objetos PdfDocument intermediários em declarações using para garantir que seus recursos não gerenciados sejam liberados imediatamente após o uso. Isso é especialmente importante em manipuladores de requisições web e tarefas em segundo plano, onde muitos documentos podem se acumular na memória se os objetos intermediários não forem descartados prontamente. O guia de resolução de problemas do IronPDF aborda em detalhes os padrões comuns de memória e desempenho.
Ao criar fluxos de trabalho de automação de documentos, considere separar a lógica de reordenação da entrada/saída de arquivos. Aceite e retorne byte[] ou MemoryStream em sua camada de serviço para manter os testes de unidade rápidos e evitar dependências do sistema de arquivos. Os exemplos do IronPDF para operações em páginas PDF mostram padrões para fluxos de trabalho com caminho de arquivo e em memória, lado a lado.
Quais são os seus próximos passos?
Reorganizar páginas de um PDF em C# com o IronPDF reduz uma tarefa complexa de manipulação de documentos a um pequeno número de chamadas de método. As técnicas principais abordadas neste artigo incluem reordenar páginas com um array de índices usando CopyPages, inverter todas as páginas programaticamente com um loop, mover uma única página combinando CopyPage, RemovePage, e InsertPdf, excluir páginas indesejadas antes de reordenar e processar documentos inteiramente na memória usando arrays de bytes e MemoryStream.
Cada um desses padrões se integra com o restante do conjunto de recursos do IronPDF . Após reorganizar as páginas, você pode adicionar uma marca d'água ou carimbo , recortar páginas individuais ou adicionar números de página antes de entregar o documento final. Os guias práticos do IronPDF fornecem exemplos de código para cada uma dessas operações subsequentes.
Comece com uma licença de avaliação gratuita para testar a reordenação de páginas e todos os outros recursos do IronPDF em seu próprio ambiente. Quando estiver pronto para implementar, revise as opções de licenciamento do IronPDF para encontrar o plano que melhor se adapta aos requisitos do seu projeto. A IronPDF e a referência de objetos do IronPDF estão disponíveis sempre que você precisar explorar cenários avançados, como assinaturas digitais, conformidade com PDF/A e marcação de acessibilidade.
Perguntas frequentes
Como reorganizo páginas de PDF em C# usando IronPDF?
Carregue o PDF com PdfDocument.FromFile, crie um int[] especificando a ordem de página desejada baseada em zero, então chame pdf.CopyPages(indexArray) e salve o resultado com SaveAs.
O que é indexação de página baseada em zero no IronPDF?
O IronPDF numera as páginas começando em 0. A primeira página é o índice 0, a segunda é o índice 1, e assim por diante. Sempre valide que cada índice no seu array esteja dentro de [0, PageCount - 1] antes de chamar CopyPages.
Posso reordenar páginas de PDF sem salvar um arquivo temporário?
Sim. Carregue o PDF a partir de um byte[] usando new PdfDocument(bytes), chame CopyPages, e acesse o resultado via reorderedPdf.BinaryData ou reorderedPdf.Stream sem qualquer gravação no sistema de arquivos.
Como posso mover uma única página para uma posição diferente em um PDF?
Use o padrão de três etapas: chame CopyPage(sourceIndex) para extrair a página, chame RemovePage(sourceIndex) para excluí-la do documento, então chame InsertPdf(pageDoc, targetIndex) para colocá-la na nova posição. Ajuste o índice alvo em -1 ao mover para frente para contabilizar o deslocamento causado pela remoção.
Como posso excluir uma página de um PDF em C#?
Chame pdf.RemovePage(index), onde index é o número da página baseada em zero a ser removida. Após a remoção, todos os índices das páginas subsequentes são deslocados para baixo em um.
Posso retornar um PDF reordenado de um controlador ASP.NET Core?
Sim. Carregue o arquivo enviado em um byte[], chame CopyPages com o array de índice desejado, então retorne File(reordered.BinaryData, "application/pdf", "reordered.pdf") da sua ação do controlador.
Como posso mesclar múltiplos PDFs reordenados em um único documento?
Chame CopyPages em cada documento fonte para produzir objetos PdfDocument reordenados independentemente, depois passe todos eles para PdfDocument.Merge(docA, docB) para produzir uma única saída combinada.
Qual é a maneira mais eficiente de reordenar páginas em um PDF grande?
Use a sobrecarga CopyPages(IEnumerable<int>) com o array de índice completo em vez de chamar CopyPage em um loop. A sobrecarga de lote processa a sequência inteira em uma única passagem interna, reduzindo as alocações e o tempo de execução.











