
如何在C#中以编程方式重新排列PDF页面
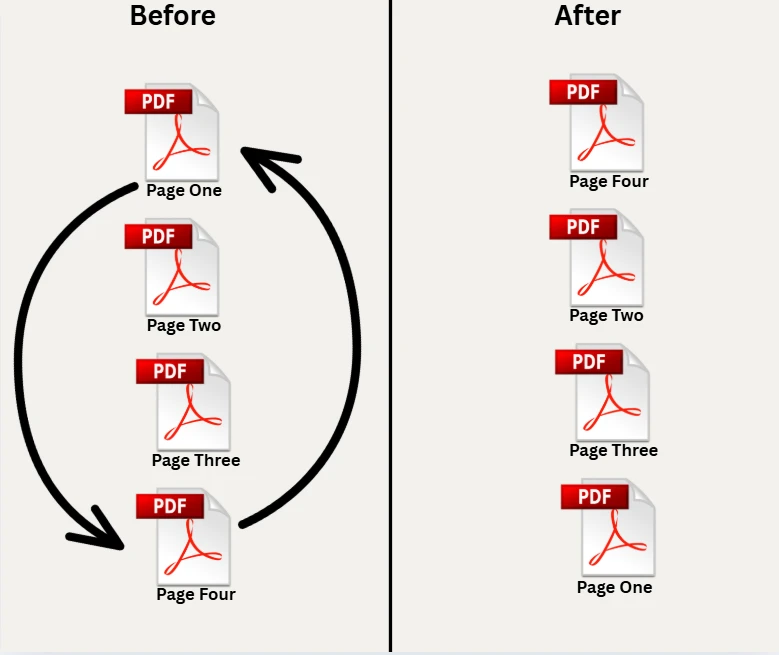
使用 C# 重新排列 PDF 文件中的页面,可以省去您在交付前重新组织报告、重新排序合同附件或重建文档包时数小时的手动工作。 IronPDF提供了一个简单的 API,只需几行 .NET 代码即可加载 PDF、指定新的页面顺序并保存结果。 本文介绍了五种实用技巧:基本页面重新排序、批量反转、将单个页面移动到新索引、删除不需要的页面以及完全在内存中工作而不触及文件系统。
IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");IronPdf.PdfDocument.FromFile("input.pdf")
.CopyPages(new[] { 2, 0, 1, 3 })
.SaveAs("reordered.pdf");Imports IronPdf
PdfDocument.FromFile("input.pdf") _
.CopyPages({2, 0, 1, 3}) _
.SaveAs("reordered.pdf")如何开始使用 IronPDF?
使用 NuGet 包管理器或 .NET CLI,即可在几秒钟内将 IronPDF 添加到任何 .NET 8 或 .NET 10 项目中。 Windows、Linux 或 macOS 系统上无需额外的运行时依赖项或本地二进制文件。
dotnet add package IronPdfdotnet add package IronPdf安装软件包后,在 C# 文件顶部添加 using IronPdf;。有效的许可证密钥可解锁完整的商业用途; 提供免费试用许可证供评估。 调用任何 API 之前请先设置密钥:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"引用了相关软件包并配置了许可证后,本文中的每个示例都无需修改即可运行。 IronPDF NuGet 包面向 .NET Standard 2.0 及更高版本,因此可在 .NET Framework 4.6.2+、.NET Core 和所有现代 .NET 版本中使用。
C# 中页面重新排序是如何工作的?
使用 C# 重新排列 PDF 中的页面,需要加载源文档,通过页面索引数组指定所需的页面顺序,然后保存输出文件。IronPDF 提供了一个方法,用于从 PDF 中提取页面并将其重新排序到一个新的对象中。
以下代码演示了如何通过创建一个新的 int 数组来重新排列页面,该数组定义了目标序列。 数组中的每个值代表原始文档中的页面索引,其中页面使用基于零的索引(第 0 页为第一页)。
using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");using IronPdf;
// Load the source document from file path
var pdf = PdfDocument.FromFile("quarterly-report.pdf");
// Define new page order: move page 3 to front, then pages 1, 2, 0
int[] pageOrder = new int[] { 3, 1, 2, 0 };
// Copy each requested page into its own PdfDocument
var pageDocs = new List<PdfDocument>();
foreach (var idx in pageOrder)
{
// CopyPage returns a PdfDocument containing only that page
var single = pdf.CopyPage(idx);
pageDocs.Add(single);
}
// Merge the single-page docs into one ordered document
using var merged = PdfDocument.Merge(pageDocs.ToArray());
// Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf");Imports IronPdf
' Load the source document from file path
Dim pdf As PdfDocument = PdfDocument.FromFile("quarterly-report.pdf")
' Define new page order: move page 3 to front, then pages 1, 2, 0
Dim pageOrder As Integer() = {3, 1, 2, 0}
' Copy each requested page into its own PdfDocument
Dim pageDocs As New List(Of PdfDocument)()
For Each idx In pageOrder
' CopyPage returns a PdfDocument containing only that page
Dim single As PdfDocument = pdf.CopyPage(idx)
pageDocs.Add(single)
Next
' Merge the single-page docs into one ordered document
Using merged As PdfDocument = PdfDocument.Merge(pageDocs.ToArray())
' Save the new ordered PDF
merged.SaveAs("report-reorganized.pdf")
End Using输出PDF文档
 。
。
CopyPages 方法接受与您期望的排列方式相匹配的 IEnumerable<int> 的页面索引值。 这种方法可以让你重新排列 PDF 页面、复制特定页面,或者将部分页面提取到单独的文档中。 该方法返回一个新的 PdfDocument 对象,而原始源文档保持不变。 因为原始文件永远不会被修改,所以您可以安全地多次调用 CopyPages,从同一个源文件生成不同的排序。
对于在 Java 环境中工作的团队, IronPDF 适用于 Java提供了类似的页面操作方法和兼容的 API 接口,因此技能可以跨语言目标进行转移。
你如何理解基于零的页面索引?
IronPDF 在其 API 中全程使用从零开始的页面索引。 第 0 页是第一页,第 1 页是第二页,依此类推。 构建索引数组时,要从零开始计数,而不是从一开始计数。 超出范围的索引会抛出ArgumentOutOfRangeException错误,因此在生产代码中调用 CopyPages 之前,务必先根据 PdfDocument.PageCount 验证数组值。
安全的验证模式是在将数组传递给任何页面复制方法之前,检查数组中的每个索引是否都在 [0, PageCount - 1] 范围内。 这样可以防止在处理步骤之间输入文档形状发生变化的情况下出现运行时异常。
如何同时重新排列多个页面?
当 PDF 文档包含很多页时,您可以一次性重新排列整个结构。 下面的代码展示了如何通过以编程方式计算索引数组来反转所有页面或创建任何自定义序列。
using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");using IronPdf;
// Load PDF document with several pages
var doc = PdfDocument.FromFile("quarterly-report.pdf");
int count = doc.PageCount;
// Build reversed single-page PDFs
var pages = new List<PdfDocument>();
for (int i = count - 1; i >= 0; i--)
{
// Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i));
}
// Merge all the reversed single-page PDFs
using var reversed = PdfDocument.Merge(pages.ToArray());
// Save to a new filename
reversed.SaveAs("report-reversed.pdf");Imports IronPdf
' Load PDF document with several pages
Dim doc = PdfDocument.FromFile("quarterly-report.pdf")
Dim count As Integer = doc.PageCount
' Build reversed single-page PDFs
Dim pages As New List(Of PdfDocument)()
For i As Integer = count - 1 To 0 Step -1
' Copy a single page as a standalone PdfDocument
pages.Add(doc.CopyPage(i))
Next
' Merge all the reversed single-page PDFs
Using reversed = PdfDocument.Merge(pages.ToArray())
' Save to a new filename
reversed.SaveAs("report-reversed.pdf")
End Using反转 PDF 页输出
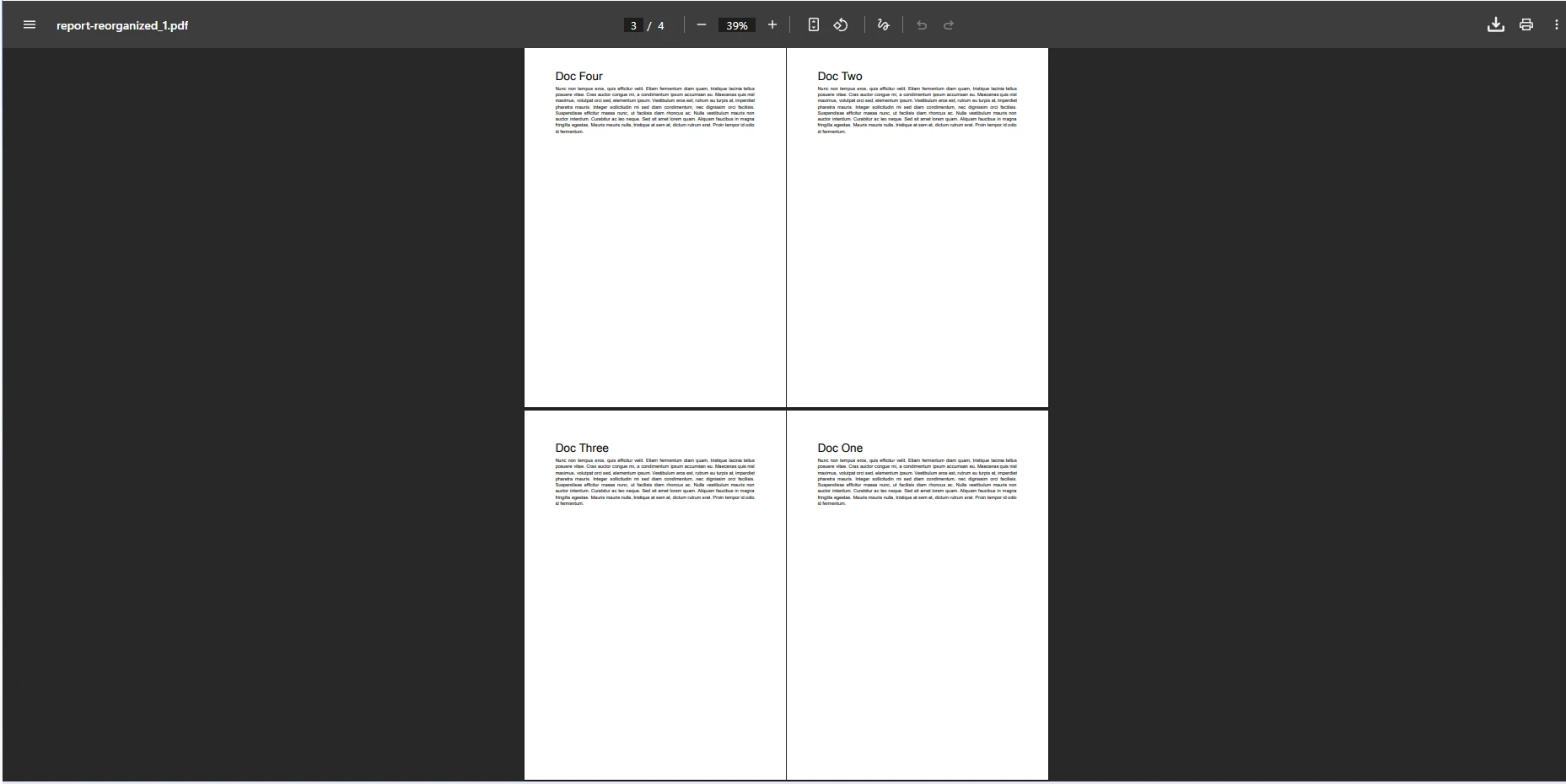
!a href="/static-assets/pdf/blog/rearrange-page-csharp/rearrange-page-csharp-3.webp">How to Rearrange Pages in PDF C# With IronPDF:图片 3 - 页面颠倒的 PDF,因此结论位于起始位置。
这段代码加载一个 PDF 文件,查询 PageCount,并构造一个反转页面顺序的列表。 for 循环动态地构建新顺序,使该方法能够扩展到任何长度的文档。 您可以将此模式应用于任何非平凡的排序:按元数据字母顺序排序、从多个来源提取单个页面时按文件大小排序,或者对匿名测试数据进行随机排序。
您也可以只交换两页,而无需重建整个列表。例如,要在三页文档中交换第 0 页和第 2 页,同时保持第 1 页不变,请将 new int[] { 2, 1, 0 } 作为索引数组传递。 IronPDF 页面操作文档包含复制、插入和删除页面的更多示例。
如何高效处理大型文档?
对于有数百页的文档,在紧密循环中调用 CopyPage 会分配许多中间对象。 更有效的替代方法是构建一次完整的索引数组,然后直接将其传递给 CopyPages。 CopyPages(IEnumerable<int>) 重载在一次内部遍历中执行整个重新排序,这比合并单独复制的页面更快,并且使用的内存更少。
处理大量 PDF 时,请考虑使用 PdfDocument 语句或显式 Dispose() 调用及时处置中间 PdfDocument 对象。 .NET 垃圾回收器会自动管理内存,但及时释放非托管资源可以降低高吞吐量服务的峰值内存使用量。
如何将单个页面移动到新位置?
将一页纸移动到不同的位置需要结合复制、删除和插入操作。 InsertPdf 方法将 PdfDocument 放置在目标文档中的任何索引处。
using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");using IronPdf;
// Load the input PDF file
var pdf = PdfDocument.FromFile("presentation.pdf");
int sourceIndex = 1; // page to move
int targetIndex = 3; // destination position
// Track direction to handle index shift after removal
bool movingForward = targetIndex > sourceIndex;
// 1. Copy the page to move (produces a one-page PdfDocument)
var pageDoc = pdf.CopyPage(sourceIndex);
// 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex);
// 3. Adjust target index if moving forward (removal shifts remaining pages left)
if (movingForward)
targetIndex--;
// 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex);
// Save the result
pdf.SaveAs("presentation-reordered.pdf");Imports IronPdf
' Load the input PDF file
Dim pdf = PdfDocument.FromFile("presentation.pdf")
Dim sourceIndex As Integer = 1 ' page to move
Dim targetIndex As Integer = 3 ' destination position
' Track direction to handle index shift after removal
Dim movingForward As Boolean = targetIndex > sourceIndex
' 1. Copy the page to move (produces a one-page PdfDocument)
Dim pageDoc = pdf.CopyPage(sourceIndex)
' 2. Remove the original page from its current position
pdf.RemovePage(sourceIndex)
' 3. Adjust target index if moving forward (removal shifts remaining pages left)
If movingForward Then
targetIndex -= 1
End If
' 4. Insert the copied page at the target position
pdf.InsertPdf(pageDoc, targetIndex)
' Save the result
pdf.SaveAs("presentation-reordered.pdf")原始 PDF 与输出结果对比
!a href="/static-assets/pdf/blog/rearrange-page-csharp/rearrange-page-csharp-4.webp">How to Rearrange Pages in PDF C# With IronPDF:图片 4 - 输入 PDF 与带有移动页面的输出 PDF 的对比。
该算法复制源页面,将其从文档中删除(这将使所有后续页面索引向下移动一位),调整目标索引以适应该偏移,然后将页面插入到更正后的位置。 这种模式可以正确处理向前和向后的移动。 当您需要对一两页进行精确控制,而无需重建整个文档时,可以使用此功能。
对于需要从第二个 PDF 插入内容而不是移动现有页面的情况,InsertPdf 接受任何 PdfDocument 作为其第一个参数,包括使用IronPDF HTML-to-PDF API从 HTML 生成的文档。
如何使用 MemoryStream 删除页面并重新排序?
实现 PDF 工作流程自动化的应用程序有时需要在不将中间文件写入磁盘的情况下处理文档。 从字节数组加载并导出到 MemoryStream 可以将所有处理都保留在内存中,这对于瞬态操作来说速度更快,并且可以避免容器化或无服务器环境中的文件系统权限问题。
using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);using IronPdf;
using System.IO;
// Load PDF from byte array (simulating input from a database or API response)
byte[] pdfBytes = File.ReadAllBytes("report-with-blank.pdf");
var pdf = new PdfDocument(pdfBytes);
// Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2);
// Reorder remaining pages: new sequence from a four-page document
var reorderedPdf = pdf.CopyPages(new int[] { 1, 0, 2, 3 });
// Export to MemoryStream for further processing (e.g., HTTP response body)
MemoryStream outputStream = reorderedPdf.Stream;
// Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData);Imports IronPdf
Imports System.IO
' Load PDF from byte array (simulating input from a database or API response)
Dim pdfBytes As Byte() = File.ReadAllBytes("report-with-blank.pdf")
Dim pdf As New PdfDocument(pdfBytes)
' Delete the blank page at index 2 (zero-based)
pdf.RemovePage(2)
' Reorder remaining pages: new sequence from a four-page document
Dim reorderedPdf = pdf.CopyPages(New Integer() {1, 0, 2, 3})
' Export to MemoryStream for further processing (e.g., HTTP response body)
Dim outputStream As MemoryStream = reorderedPdf.Stream
' Or save directly using the BinaryData property
File.WriteAllBytes("cleaned-report.pdf", reorderedPdf.BinaryData)PdfDocument 构造函数直接接受一个 byte[],而 Stream 属性返回生成的 PDF 作为 MemoryStream。 这种模式适用于返回文件响应的ASP.NET Core控制器、读取和写入 Blob 存储的 Azure 函数以及从消息队列处理批量 PDF 的后台服务。 即使对于包含嵌入式图像的大型文档,该库也能高效地处理内存管理。
请参阅PdfDocument API 参考文档,了解完整的页面操作方法集,包括旋转、提取和盖章。
如何在 ASP.NET Core 控制器中处理 PDF 页面?
从控制器直接返回重新排序的 PDF 文件非常简单。 对已加载的文档调用 RemovePage 或 CopyPages,然后将 BinaryData 写入响应:
using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}using IronPdf;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("api/pdf")]
public class PdfController : ControllerBase
{
[HttpPost("reorder")]
public IActionResult Reorder(IFormFile file, [FromQuery] string order)
{
// Parse comma-separated page indexes from query string
var indexes = order.Split(',').Select(int.Parse).ToArray();
using var stream = file.OpenReadStream();
using var ms = new System.IO.MemoryStream();
stream.CopyTo(ms);
var pdf = new PdfDocument(ms.ToArray());
var reordered = pdf.CopyPages(indexes);
// Return the reordered PDF as a downloadable file
return File(reordered.BinaryData, "application/pdf", "reordered.pdf");
}
}Imports IronPdf
Imports Microsoft.AspNetCore.Mvc
Imports System.IO
<ApiController>
<Route("api/pdf")>
Public Class PdfController
Inherits ControllerBase
<HttpPost("reorder")>
Public Function Reorder(file As IFormFile, <FromQuery> order As String) As IActionResult
' Parse comma-separated page indexes from query string
Dim indexes = order.Split(","c).Select(Function(s) Integer.Parse(s)).ToArray()
Using stream = file.OpenReadStream()
Using ms = New MemoryStream()
stream.CopyTo(ms)
Dim pdf = New PdfDocument(ms.ToArray())
Dim reordered = pdf.CopyPages(indexes)
' Return the reordered PDF as a downloadable file
Return File(reordered.BinaryData, "application/pdf", "reordered.pdf")
End Using
End Using
End Function
End Class该控制器读取上传的文件,接受以逗号分隔的查询字符串指定的页面顺序,并将重新排序的 PDF 作为响应流式发送回去。 整个过程中不会写入任何临时文件。 同样的方法也适用于在 ASP.NET Core 中从 HTML 或模板生成 PDF 。
重新排序后如何合并PDF?
页面重新排序通常与合并来自多个源文件的内容密切相关。 IronPDF 的 PdfDocument.Merge 方法接受一个 PdfDocument 对象数组,并按提供的顺序将它们连接起来,这与上面显示的页面复制技术自然地结合在一起。
using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");using IronPdf;
// Load two separate PDF files
var docA = PdfDocument.FromFile("section-a.pdf");
var docB = PdfDocument.FromFile("section-b.pdf");
// Reorder pages within each source document
var reorderedA = docA.CopyPages(new int[] { 1, 0, 2 });
var reorderedB = docB.CopyPages(new int[] { 0, 2, 1 });
// Merge into a single output document
using var combined = PdfDocument.Merge(reorderedA, reorderedB);
combined.SaveAs("combined-report.pdf");Imports IronPdf
' Load two separate PDF files
Dim docA = PdfDocument.FromFile("section-a.pdf")
Dim docB = PdfDocument.FromFile("section-b.pdf")
' Reorder pages within each source document
Dim reorderedA = docA.CopyPages(New Integer() {1, 0, 2})
Dim reorderedB = docB.CopyPages(New Integer() {0, 2, 1})
' Merge into a single output document
Using combined = PdfDocument.Merge(reorderedA, reorderedB)
combined.SaveAs("combined-report.pdf")
End Using合并后,生成的文档包含来自 reorderedA 的所有页面,以及来自 reorderedB 的所有页面。 您可以链接其他 Merge 调用或传递更多文档来组合任意数量的源。 IronPDF 的文档合并和拆分功能涵盖将文档拆分为各个部分,这是相反的操作。
要深入了解如何合并字节数组和内存中的文档,请参阅C# 中关于从字节数组合并 PDF 的指南,其中文档以二进制 blob 而不是文件路径的形式存储,该指南涵盖了数据库支持的工作流程。
PDF页面管理的最佳实践是什么?
防御性编码习惯可以防止在大规模操作 PDF 页面时出现不易察觉的错误和生产故障。 持续应用这些做法,可以使页面重排序代码更容易测试和维护。
在将页面索引传递给 CopyPages 或 RemovePage 之前,务必先根据 PdfDocument.PageCount 验证页面索引。 超出 [0, PageCount - 1] 范围的索引会在运行时引发 ArgumentOutOfRangeException 错误。一行简单的保护检查即可完全消除此类错误。
处理多页重新排序时,优先使用 CopyPages(IEnumerable<int>) 重载,而不是手动循环遍历 CopyPage。 批量处理模式一次性处理整个序列,从而减少内存分配和执行时间。逐页循环模式仅适用于需要进行逐页转换的情况,例如在合并前轮换单个页面。
将中间 PdfDocument 对象包装在 using 语句中,以确保其未托管资源在使用后立即释放。 这在 Web 请求处理程序和后台作业中尤其重要,因为如果中间对象没有及时释放,许多文档可能会在内存中积聚。 IronPDF故障排除指南详细介绍了常见的内存和性能模式。
构建文档自动化流程时,请考虑将重新排序逻辑与文件输入/输出分离。 在服务层中接受并返回 byte[] 或 MemoryStream,以保持单元测试快速并避免文件系统依赖。 IronPDF 提供的 PDF 页面操作示例并排展示了文件路径和内存工作流的模式。
下一步计划是什么?
使用 IronPDF 在 C# 中重新排列 PDF 页面,可以将复杂的文档操作任务简化为少量方法调用。 本文涵盖的核心技术包括:使用索引数组对页面进行重新排序(使用 CopyPages),使用循环以编程方式反转所有页面,通过组合 CopyPage、RemovePage 和 InsertPdf 来移动单个页面,在重新排序之前删除不需要的页面,以及使用字节数组和 MemoryStream 在内存中完全处理文档。
这些模式均与 IronPDF 的其他功能集集成。 重新排列页面后,您可以在交付最终文档之前添加水印或图章、裁剪单个页面或添加页码。 IronPDF 的操作指南为每个后续操作提供了代码示例。
首先申请免费试用许可证,在您自己的环境中测试页面重新排序和 IronPDF 的所有其他功能。 准备部署时,请查看IronPDF 许可选项,找到符合您项目要求的级别。 当您需要探索数字签名、PDF/A 合规性和辅助功能标记等高级场景时, IronPDF 文档和对象参考将随时可用。
常见问题解答
如何在C#中使用IronPDF重新排列PDF页面?
加载PDF使用PdfDocument.FromFile,创建一个int[]指定所需的零基页面顺序,然后调用pdf.CopyPages(indexArray)并使用SaveAs保存结果。
IronPDF中的零基页面索引是什么?
IronPDF从0开始编号页面。第一页是索引0,第二页是索引1,依此类推。在调用CopyPages之前,一定要验证数组中的每个索引都在[0, PageCount - 1]范围内。
我可以在不保存临时文件的情况下重新排序PDF页面吗?
可以。使用new PdfDocument(bytes)从byte[]加载PDF,调用CopyPages,然后通过reorderedPdf.BinaryData或reorderedPdf.Stream访问结果,不需要任何文件系统写操作。
如何将单个页面移动到PDF中的不同位置?
使用三步模式:调用CopyPage(sourceIndex)提取页面,调用RemovePage(sourceIndex)从文档中删除它,然后调用InsertPdf(pageDoc, targetIndex)将其放置在新位置。当向前移动时,调整目标索引减1以考虑删除引起的移位。
如何在C#中删除PDF中的一个页面?
调用pdf.RemovePage(index),其中index是要删除的零基页面编号。删除后,所有后续页面索引将下移一个。
我可以从ASP.NET Core控制器返回重新排序的PDF吗?
可以。将上传的文件加载到byte[]中,使用所需的索引数组调用CopyPages,然后从控制器动作返回File(reordered.BinaryData, "application/pdf", "reordered.pdf")。
如何将多个重新排序的PDF合并为一个文档?
在每个源文档上调用CopyPages以生成独立重新排序的PdfDocument对象,然后将它们全部传递给PdfDocument.Merge(docA, docB)以生成单个合并输出。
在大型PDF中重新排序页面的最有效方法是什么?
使用CopyPages(IEnumerable重载与完整索引数组,而不是在循环中调用CopyPage。批量重载在一次内部处理整个序列,减少了分配和执行时间。













