
Jak wyodrębniać dane z PDF w Java
W tym samouczku dowiesz się, jak używać IronPDF for Java do wyodrębniania danych z pliku PDF. Konfiguracja środowiska, import biblioteki, odczyt pliku wejściowego i wyodrębnianie potrzebnych danych są wyjaśnione na przykładach kodu.
2. Biblioteka IronPDF Java PDF
IronPDF to biblioteka oprogramowania, która zapewnia programistom możliwość generowania, edytowania i wyodrębniania danych z plików PDF przy użyciu IronPDF for Java w ramach ich aplikacji Java. Umożliwia tworzenie plików PDF z dokumentów HTML, obrazów i innych materiałów, a także łączenie wielu plików PDF, dzielenie plików PDF oraz edycję istniejących plików PDF. IronPDF oferuje również możliwość zabezpieczenia plików PDF za pomocą funkcji ochrony hasłem oraz dodawania do nich podpisów cyfrowych, a także wiele innych funkcji.
IronPDF for Java jest tworzony i utrzymywany przez Iron Software. Jedną z jego najlepiej ocenianych funkcji jest wyodrębnianie tekstu i danych z plików PDF, a także z HTML i adresów URL.
3. Wymagania wstępne
Aby używać IronPDF do wyodrębniania danych z plików PDF, musisz spełnić następujące wymagania wstępne:
- Instalacja Javy: Upewnij się, że Java jest zainstalowana w Twoim systemie, a jej ścieżka jest ustawiona w zmiennych środowiskowych. Jeśli nie zainstalowałeś jeszcze Javy, zapoznaj się z instrukcjami na tej stronie pobierania na stronie internetowej Javy.
- Środowisko IDE dla języka Java: Zainstaluj środowisko IDE dla języka Java, takie jak Eclipse lub IntelliJ. Eclipse można pobrać z tej strony pobierania Eclipse, a IntelliJ z tej strony pobierania IntelliJ.
- Biblioteka IronPDF: Pobierz i dodaj bibliotekę IronPDF jako zależność w swoim projekcie. Odwiedź stronę z instrukcjami konfiguracji IronPDF, aby uzyskać instrukcje dotyczące konfiguracji.
- Instalacja Mavena: Przed rozpoczęciem procesu konwersji plików PDF należy zainstalować i zintegrować Maven z używanym środowiskiem IDE. Zapoznaj się z tym samouczkiem dotyczącym instalacji Maven na stronie JetBrains, aby dowiedzieć się, jak zainstalować i zintegrować Maven.
4. Instalacja IronPDF for Java
Instalacja IronPDF for Java jest łatwa i nieskomplikowana, pod warunkiem spełnienia wszystkich wymagań. W niniejszym przewodniku wykorzystamy IntelliJ IDEA firmy JetBrains do zademonstrowania instalacji i uruchomienia przykładowego kodu.
Oto, co należy zrobić:
- Otwórz IntelliJ IDEA: Uruchom JetBrains IntelliJ IDEA na swoim komputerze.
- Utwórz projekt Maven: W IntelliJ IDEA utwórz nowy projekt Maven. Zapewni to odpowiednie środowisko do instalacji IronPDF for Java.
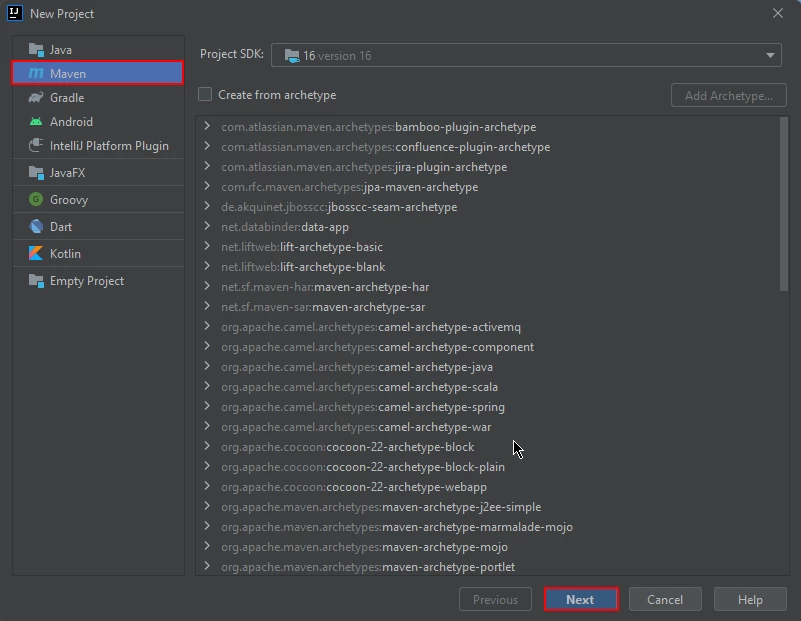 Nowy projekt Maven w IntelliJ
Nowy projekt Maven w IntelliJ
- Pojawi się nowe okno. Wpisz nazwę projektu i kliknij przycisk "Zakończ".
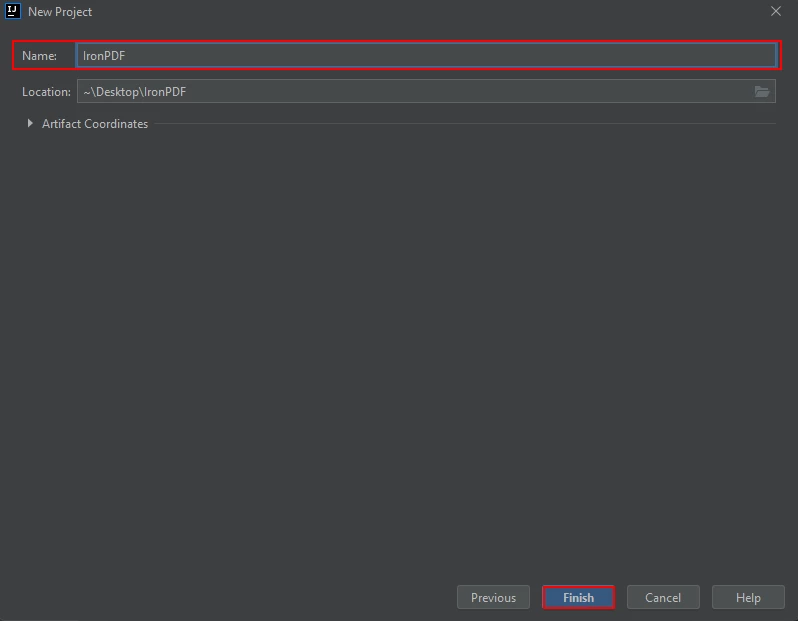 Nadaj nazwę projektowi Maven i kliknij Zakończ
Nadaj nazwę projektowi Maven i kliknij Zakończ
- Po kliknięciu przycisku "Zakończ" otworzy się nowy projekt z plikiem pom.xml. Zostanie to wykorzystane do dodania zależności IronPDF Java Maven.
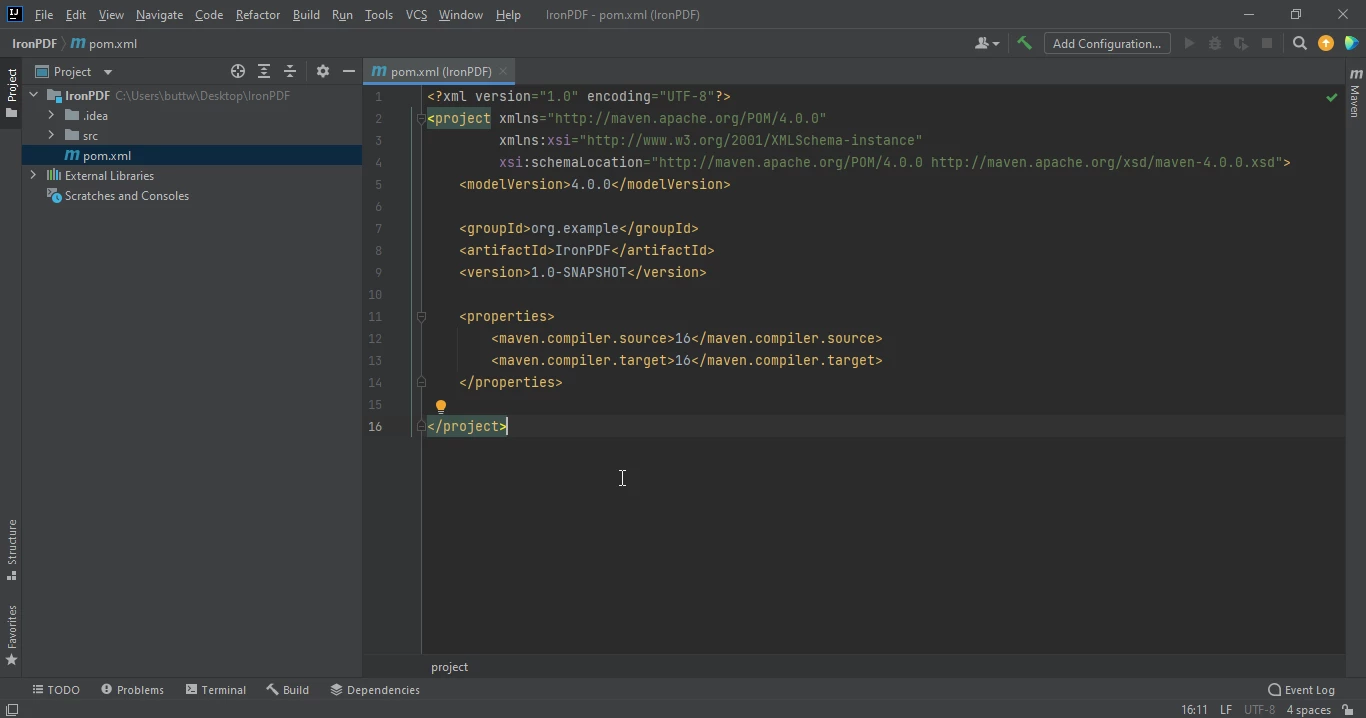 Plik pom.xml
Plik pom.xml
Dodaj następujące zależności do pliku pom.xml lub pobierz plik JAR ze strony biblioteki IronPDF w serwisie Sonatype Central.
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency><dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>1.0.0</version>
</dependency>Po umieszczeniu zależności w pliku pom.xml w prawym górnym rogu pliku pojawi się mała ikona.
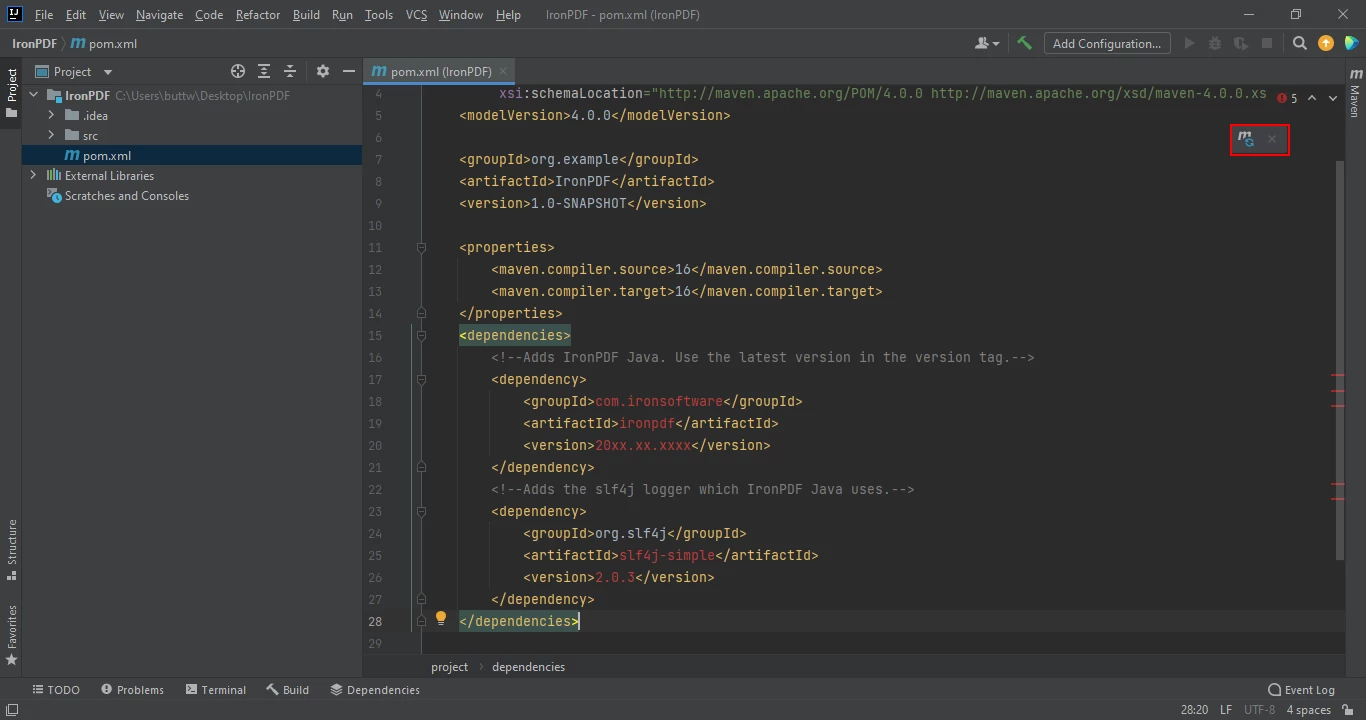 Kliknij pływającą ikonę, aby automatycznie zainstalować zależności Maven
Kliknij pływającą ikonę, aby automatycznie zainstalować zależności Maven
Zainstaluj zależności IronPDF for Java dla Maven, klikając ten przycisk. W zależności od szybkości połączenia internetowego powinno to zająć tylko kilka minut.
5. Pobieranie danych
IronPDF to biblioteka Java służąca do tworzenia, edycji i wyodrębniania danych z dokumentów PDF. Zapewnia proste API do wyodrębniania tekstu z plików PDF, adresów URL i tabel.
5.1. Pobieranie danych z dokumentów PDF
Korzystając z IronPDF for Java, można łatwo wyodrębnić dane tekstowe z dokumentów PDF. Poniżej znajduje się przykładowy kod służący do wyodrębniania danych z pliku PDF.
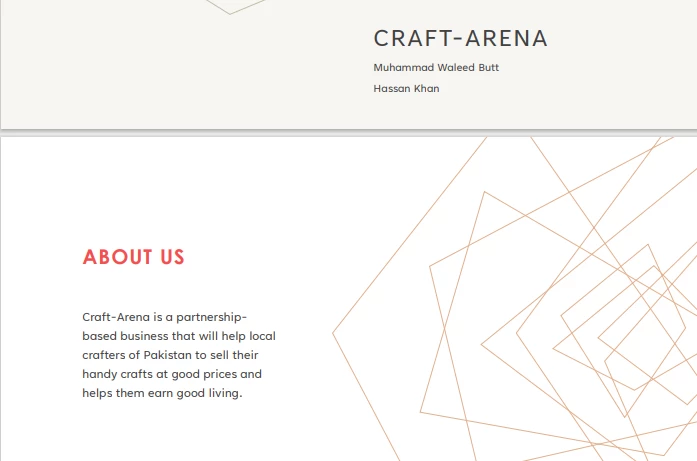 Plik wejściowy PDF
Plik wejściowy PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business plan.pdf"));
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the PDF: " + text);
}
}Kod źródłowy generuje poniższy wynik:
> Text extracted from the PDF:
>
> CRAFT-ARENA
>
> Muhammad Waleed Butt
>
> Hassan Khan
>
> ABOUT US
>
> Craft-Arena is a partnership based business that will help local crafters of Pakistan to sell their handicrafts at good prices and helps them earn a good living.5.2. Pobieranie danych z adresów URL
IronPDF for Java konwertuje adres URL na plik PDF w czasie wykonywania i wyodrębnia z niego tekst. Ten przykład pokaże kod źródłowy służący do wyodrębniania tekstu z adresów URL.
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// Convert a URL to a PDF and load it into a PdfDocument
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://ironpdf.com/java/");
// Extract all text from the PDF document
String text = pdf.extractAllText();
// Print the extracted text to the console
System.out.println("Text extracted from the URLs: " + text);
}
} Wyodrębnione dane ze stron internetowych
Wyodrębnione dane ze stron internetowych
5.3. Wyodrębnianie danych z tabeli
Wyodrębnianie danych z tabel w pliku PDF za pomocą IronPDF for Java jest bardzo proste; Wystarczy plik PDF zawierający tabelę oraz uruchomienie poniższego kodu.
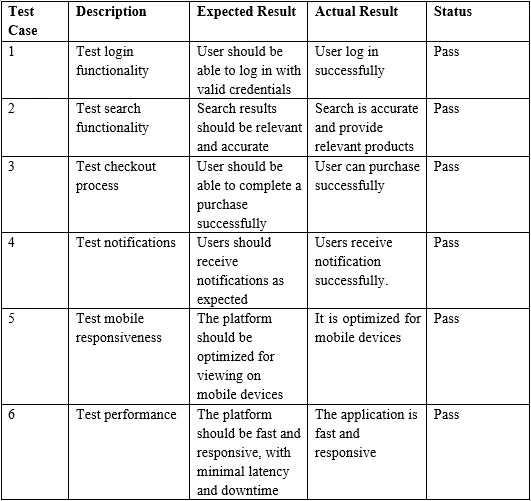 Przykładowa tabela w formacie PDF
Przykładowa tabela w formacie PDF
// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}// Import the necessary IronPDF package for working with PDF documents
import com.ironsoftware.ironpdf.PdfDocument;
import java.io.IOException;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from the specified file
PdfDocument pdf = PdfDocument.fromFile(Paths.get("table.pdf"));
// Extract all text from the PDF document, including table data
String text = pdf.extractAllText();
// Print the extracted table data to the console
System.out.print("Text extracted from the Marked tables: " + text);
}
}> Test Case Description Expected Result Actual Result Status
>
> 1 Test login functionality User should be able to log in with valid credentials
>
> User log in successfully Pass
>
> 2 Test search functionality Search results should be relevant and accurate
>
> Search is accurate and provide relevant products Pass
>
> 3 Test checkout process User should be able to complete a purchase successfully
>
> User can purchase successfully Pass6. Podsumowanie
Podsumowując, w tym samouczku pokazano, jak wyodrębnić dane, a konkretnie dane tabelaryczne, z pliku PDF przy użyciu biblioteki IronPDF for Java.
Więcej informacji można znaleźć w przykładzie wyodrębniania tekstu z pliku PDF na stronie internetowej IronPDF.
IronPDF to biblioteka objęta licencją komercyjną, której cena zaczyna się od $799. Można jednak ocenić go w środowisku produkcyjnym, korzystając z bezpłatnej wersji probnej na licencji IronPDF.
Często Zadawane Pytania
Jak wyodrębnić tekst z pliku PDF w Javie?
Możesz użyć IronPDF for Java do wyodrębnienia tekstu z pliku PDF, ładując dokument za pomocą klasy PdfDocument i wykorzystując metodę extractAllText do pobrania tekstu.
Czy mogę wyodrębnić dane z adresu URL i przekonwertować je do formatu PDF w Javie?
Tak, IronPDF for Java pozwala na konwersję adresu URL do formatu PDF w czasie wykonywania oraz wyodrębnianie danych z niego przy użyciu klasy PdfDocument.
Jakie kroki należy wykonać, aby skonfigurować IronPDF w IntelliJ IDEA?
Aby skonfigurować IronPDF w IntelliJ IDEA, utwórz nowy projekt Maven, dodaj bibliotekę IronPDF do pliku pom.xml i zainstaluj zależności Maven, klikając pojawiającą się ikonę.
Jakie są wymagania wstępne dotyczące korzystania z IronPDF w Javie?
Wymagania wstępne obejmują zainstalowaną platformę Java, środowisko IDE dla Javy, takie jak Eclipse lub IntelliJ, bibliotekę IronPDF oraz zainstalowany i zintegrowany z IDE framework Maven.
Jak wyodrębnić dane z tabeli z pliku PDF przy użyciu języka Java?
Aby wyodrębnić dane z tabeli z pliku PDF przy użyciu IronPDF for Java, należy załadować dokument PDF za pomocą klasy PdfDocument i użyć metody extractAllText w celu pobrania danych z tabeli.
Czy do korzystania z IronPDF for Java wymagana jest licencja komercyjna?
Tak, IronPDF for Java wymaga licencji komercyjnej, ale dostępna jest bezpłatna wersja próbna do celów ewaluacyjnych.
Gdzie mogę znaleźć samouczki dotyczące korzystania z IronPDF w Javie?
Samouczki i przykłady korzystania z IronPDF for Java można znaleźć na stronie internetowej IronPDF, w szczególności w sekcjach przykładów i samouczków.
Jakie funkcje oferuje IronPDF for Java?
IronPDF for Java oferuje funkcje tworzenia, edycji, łączenia, dzielenia i manipulowania plikami PDF, a także funkcje zabezpieczania plików PDF hasłem i dodawania podpisów cyfrowych.
Jak mogę rozwiązać problemy z pobieraniem danych z plików PDF przy użyciu Javy?
Upewnij się, że wszystkie wymagania wstępne są spełnione, takie jak posiadanie najnowszej wersji Javy, kompatybilnego środowiska IDE oraz biblioteki IronPDF. Sprawdź poprawność integracji z Mavenem oraz zależności bibliotek w pliku pom.xml.

















