Como salvar uma página da web como um arquivo PDF no Mac e no Windows
Os arquivos PDF são um formato amplamente utilizado para troca de documentos devido à sua capacidade de preservar a formatação em diferentes plataformas. Em diversas aplicações, a leitura programática do conteúdo de arquivos PDF torna-se indispensável.
Neste artigo, vamos aprender a visualizar texto de arquivos PDF em C++ usando a ferramenta de linha de comando Xpdf. Xpdf fornece um conjunto de utilitários de linha de comando e bibliotecas C++ para trabalhar com arquivos PDF, incluindo extração de texto. Integrando Xpdf em nosso programa de visualização de PDF em C++, podemos visualizar eficientemente o conteúdo de texto dos arquivos PDF e processá-lo programaticamente.
Xpdf - Biblioteca C++ e Ferramentas de Linha de Comando
O Xpdf é um pacote de software de código aberto que oferece uma variedade de ferramentas e bibliotecas para trabalhar com arquivos PDF. Inclui diversos utilitários de linha de comando e bibliotecas C++ que permitem funcionalidades relacionadas a PDFs, como análise sintática, renderização, impressão e extração de texto. As ferramentas de linha de comando do Xpdf também oferecem maneiras de visualizar arquivos PDF diretamente do terminal.
Um dos principais componentes do Xpdf é o pdftotext, conhecido principalmente por extrair conteúdo de texto de arquivos PDF. No entanto, quando usado em combinação com outras ferramentas como pdftops e pdfimages, Xpdf permite que os usuários visualizem o conteúdo do PDF de maneiras diferentes. A ferramenta pdftotext prova ser valiosa para extrair informações textuais de PDFs para processamento ou análise posterior, e oferece opções para especificar de quais páginas extrair texto.
Pré-requisitos
Antes de começarmos, certifique-se de que você possui os seguintes pré-requisitos:
- Um compilador C++, como o GCC ou o Clang, instalado em seu sistema. Para isso, utilizaremos o ambiente de desenvolvimento integrado Code::Blocks .
- As ferramentas de linha de comando do Xpdf estão instaladas e acessíveis a partir da linha de comando. Baixe o Xpdf e instale a versão adequada ao seu ambiente. Em seguida, defina o diretório bin do Xpdf nas variáveis de ambiente do sistema para acessá-lo de qualquer local no sistema de arquivos.
Criando um projeto de visualizador de PDF
- Abra o Code::Blocks: Inicie o ambiente de desenvolvimento integrado (IDE) Code::Blocks no seu computador.
- Criar um novo projeto: Clique em "Arquivo" no menu superior e selecione "Novo" no menu suspenso. Em seguida, clique em "Projeto" no submenu.
- Escolha o tipo de projeto: Na janela "Novo a partir de modelo", escolha "Aplicativo de console" e clique em "Ir". Em seguida, selecione a linguagem "C/C++" e clique em "Avançar".
- Insira os detalhes do projeto: No campo "Título do projeto", dê um nome ao seu projeto (por exemplo, "Visualizador de PDF"). Escolha o local onde deseja salvar os arquivos do projeto e clique em "Avançar".
- Selecione o compilador: Escolha o compilador que deseja usar para o seu projeto. Por padrão, o Code::Blocks deve detectar automaticamente os compiladores disponíveis no seu sistema. Caso contrário, selecione um compilador adequado na lista e clique em "Concluir".
Passos para visualizar texto de um PDF em C++
Inclua os cabeçalhos necessários
Primeiro, vamos adicionar os arquivos de cabeçalho necessários ao nosso arquivo main.cpp :
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenience#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenienceConfigurar caminhos de entrada e saída
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";string pdfPath = "input.pdf";
string outputFilePath = "output.txt";Na função main, declaramos duas strings: pdfPath e outputFilePath. pdfPath armazena o caminho para o arquivo PDF de entrada, e outputFilePath armazena o caminho onde o texto extraído será salvo como um arquivo de texto simples.
O arquivo de entrada é o seguinte:

Execute o Comando pdftotext
// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());Aqui, construímos o comando pdftotext usando as variáveis pdfPath e outputFilePath para abrir o arquivo PDF e visualizar seu conteúdo. A função system é então chamada para executar o comando, e seu valor de retorno é armazenado na variável status.
Verificar o status da extração de texto
if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}Verificamos a variável status para ver se o comando pdftotext foi executado com sucesso. Se status for igual a 0, significa que a extração de texto foi bem-sucedida, e imprimimos uma mensagem de sucesso. Se o status for diferente de zero, isso indica um erro, e imprimimos uma mensagem de erro.
Ler o texto extraído e exibi-lo
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}No código de exemplo acima, abrimos o outputFile (o arquivo de texto gerado por pdftotext), lemos seu conteúdo linha por linha e o armazenamos na string textContent. Por fim, fechamos o arquivo e imprimimos o conteúdo do texto extraído no console.
Remover arquivo de saída
Se você não precisar do arquivo de texto editável gerado ou quiser liberar espaço em disco, basta excluí-lo ao final do programa usando o seguinte comando antes de encerrar a função principal:
// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());Compilando e executando o programa
Compile o código usando o atalho de teclado "Ctrl+F9". Após a compilação bem-sucedida, a execução do arquivo extrairá o conteúdo de texto do documento PDF especificado e o exibirá no console. O resultado é o seguinte:
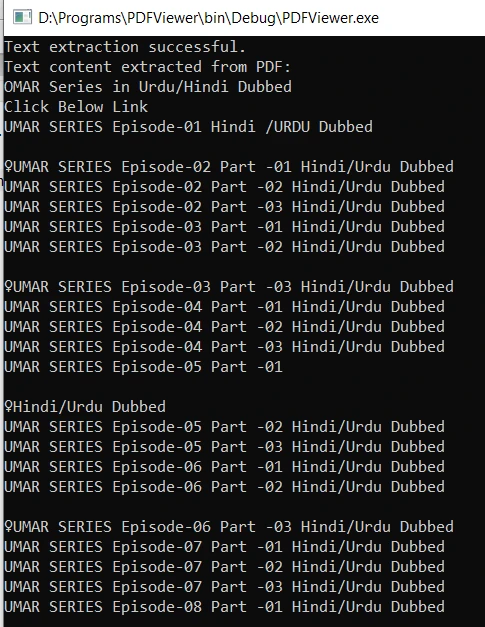
View PDF files in C
A biblioteca IronPDF .NET C# é uma poderosa biblioteca PDF for .NET C# que permite aos usuários visualizar facilmente arquivos PDF em seus aplicativos C#. Aproveitando o mecanismo do navegador web Chromium, o IronPDF renderiza e exibe com precisão o conteúdo de PDFs, incluindo imagens, fontes e formatação complexa. Com sua interface amigável e amplas funcionalidades, os desenvolvedores podem integrar o IronPDF em seus projetos C# de forma simples, permitindo que os usuários visualizem documentos PDF de maneira eficiente e interativa. Seja para exibir relatórios, faturas ou qualquer outro conteúdo em PDF, o IronPDF oferece uma solução robusta para criar visualizadores de PDF ricos em recursos em C#.
Para instalar o pacote NuGet IronPDF no Visual Studio, siga estes passos:
- Abra o Visual Studio: Inicie o Visual Studio ou qualquer outra IDE de sua preferência.
- Crie ou abra seu projeto: Crie um novo projeto C# ou abra um existente onde você deseja instalar o pacote IronPDF .
- Abra o Gerenciador de Pacotes NuGet : No Visual Studio, acesse "Ferramentas" > "Gerenciador de Pacotes NuGet " > "Gerenciar Pacotes NuGet para a Solução". Como alternativa, clique em Explorador de Soluções e selecione "Gerenciar Pacotes NuGet para a Solução".
- Pesquise por IronPDF: Na janela "Gerenciador de Pacotes NuGet ", clique na guia "Procurar" e, em seguida, pesquise por "IronPDF" na barra de pesquisa. Alternativamente, visite o pacote NuGet IronPDF e faça o download direto da versão mais recente do "IronPDF".
- Selecione o pacote IronPDF : Encontre o pacote "IronPDF" e clique nele para selecioná-lo para o seu projeto.
- Instale o IronPDF: Clique no botão "Instalar" para instalar o pacote selecionado.
-
No entanto, você também pode instalar o IronPDF usando o Console do Gerenciador de Pacotes NuGet com o seguinte comando:
Install-Package IronPdf
Utilizando o IronPDF, podemos realizar operações como extrair texto e imagens de documentos PDF e exibi-los no console para visualização. O código a seguir ajuda a realizar essa tarefa:
using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}Imports IronPdf
Imports IronSoftware.Drawing
Imports System.Collections.Generic
' Extracting Image and Text content from Pdf Documents
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text to put in a search index
Private text As String = pdf.ExtractAllText()
' Get all Images
Private allImages = pdf.ExtractAllImages()
' Or even find the precise text and images for each page in the document
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Further processing here...
Next indexPara obter informações mais detalhadas sobre o IronPDF, visite a Documentação do IronPDF .
Conclusão
Neste artigo, aprendemos como extrair e visualizar o conteúdo de um documento PDF em C++ usando a ferramenta de linha de comando Xpdf. Essa abordagem nos permite processar e analisar o texto extraído em nossos aplicativos C++ de forma integrada.
Está disponível uma licença de avaliação gratuita para testes com fins comerciais.