
fastparquet Python (How It Works For Developers)
fastparquet is a Python library designed to handle the Parquet file format, which is commonly used in big data workflows. It integrates well with other Python-based data processing tools like Dask and Pandas. Let’s explore its features and see some code examples. Later in this article, we will also learn about IronPDF, a PDF generation library from Iron Software.
Overview of fastparquet
fastparquet is efficient and supports a wide range of Parquet features. Some of its key features include:
Reading and Writing Parquet Files
Easily read from and write to Parquet files and other data files.
Integration with Pandas and Dask
Seamlessly work with Pandas DataFrames and Dask for parallel processing.
Compression Support
Supports various compression algorithms like gzip, snappy, brotli, lz4, and zstandard in data files.
Efficient Storage
Optimized for both storage and retrieval of large datasets or data files using parquet columnar file format and metadata file pointing to file.
Installation
You can install fastparquet using pip:
pip install fastparquetpip install fastparquetOr using conda:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquetBasic Usage
Here’s a simple example to get you started with fastparquet.
Writing a Parquet File
You can write a Pandas DataFrame to a Parquet file:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")Output
![]()
Reading a Parquet File
You can read a Parquet file into a Pandas DataFrame:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())Output

Displaying Parquet File Metadata
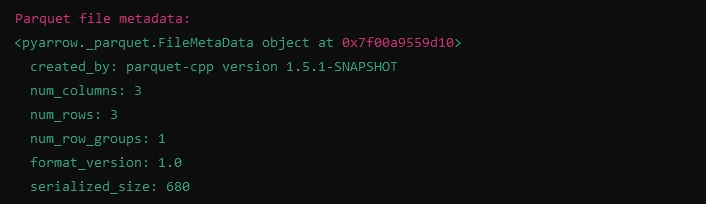
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)Output
Advanced Features
Using Dask for Parallel Processing
fastparquet integrates well with Dask for handling large datasets in parallel:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)Customizing Compression
You can specify different compression algorithms when writing Parquet files:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')Introducing IronPDF
IronPDF is a robust Python library crafted for generating, modifying, and digitally signing PDF documents derived from HTML, CSS, images, and JavaScript. It excels in performance while maintaining a minimal memory footprint. Here are its key features:
1. HTML to PDF Conversion
Convert HTML files, HTML strings, and URLs into PDF documents with IronPDF. For instance, effortlessly render webpages into PDFs using the Chrome PDF renderer.
2. Cross-Platform Support
Compatible with Python 3+ across Windows, Mac, Linux, and various Cloud Platforms. IronPDF is also accessible for .NET, Java, Python, and Node.js environments.
3. Editing and Signing
Modify document properties, enhance security with password protection and permissions, and integrate digital signatures into your PDFs using IronPDF.
4. Page Templates and Settings
Tailor PDFs with customized headers, footers, page numbers, and adjustable margins. It supports responsive layouts and accommodates custom paper sizes.
5. Standards Compliance
Conforms to PDF standards like PDF/A and PDF/UA. It handles UTF-8 character encoding and manages assets such as images, CSS stylesheets, and fonts effectively.
Generate PDF Documents using IronPDF and fastparquet
IronPDF for Python prerequisites
- IronPDF counts on .NET 6.0 as its underlying technology. Thus, please make sure .NET 6.0 runtime is installed on your system.
- Python 3.0+: Ensure you have Python version 3 or later installed.
- pip: Install Python package installer pip for installing IronPDF package.
Installation
pip install fastparquet pandas ironpdf
Code example
The following code example demonstrates the use of fastparquet and IronPDF together in Python:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
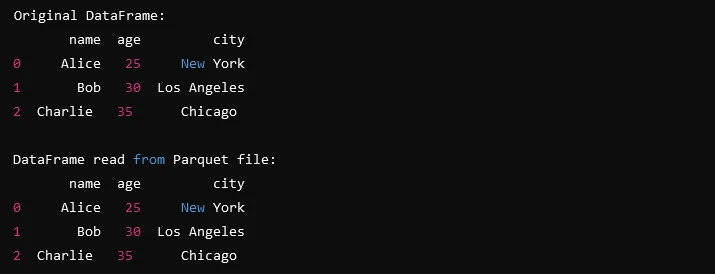
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
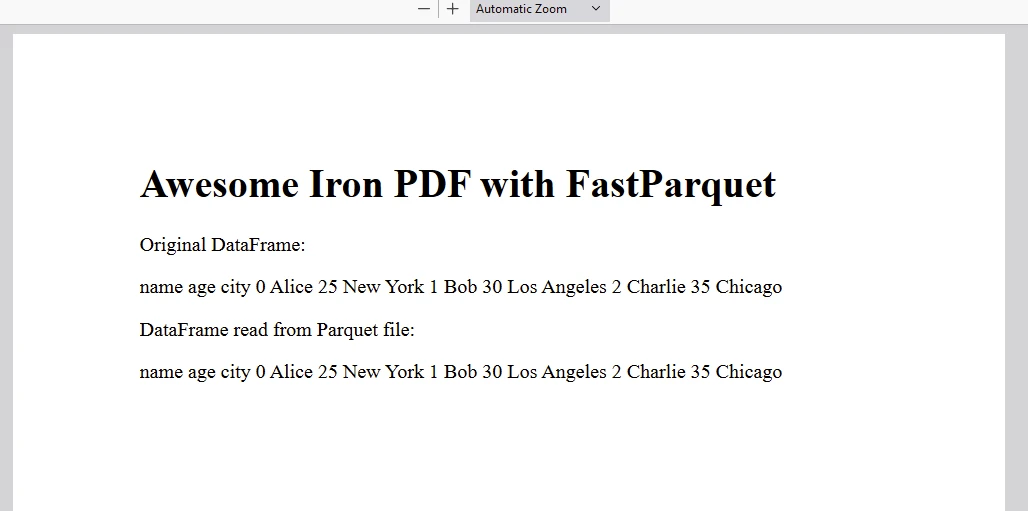
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")Code Explanation
This code snippet demonstrates how to utilize several Python libraries to manipulate data and generate a PDF document from HTML content.
Imports and Setup: Import necessary libraries for data manipulation, reading and writing Parquet files, and PDF generation.
Setting License Key: Set the license key for IronPDF, enabling its full features.
Creating a Sample DataFrame: Define a sample DataFrame (
df) containing information about individuals (name, age, city).Writing DataFrame to Parquet: Write the DataFrame
dfto a Parquet file namedexample.parquet.Reading from Parquet File: Read data from the Parquet file (
example.parquet) back into a DataFrame (df_read).- Generating PDF from HTML:
- Initialize a ChromePdfRenderer instance using IronPDF.
- Construct an HTML string (
content) that includes a heading (<h1>) and paragraphs (<p>) displaying the original DataFrame (df) and the DataFrame read from the Parquet file (df_read). - Render the HTML content as a PDF document using IronPDF.
- Save the generated PDF document as
Demo-FastParquet.pdf.
The code demonstrates a sample code for FastParquet, integrating data processing capabilities with PDF generation, making it useful for creating reports or documents based on data stored in parquet files.
OUTPUT
OUTPUT PDF
IronPDF License
For license information, visit the IronPDF licensing page.
Place the License Key at the start of the script before using IronPDF package:
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"Conclusion
fastparquet is a powerful and efficient library for working with parquet files in Python. Its integration with Pandas and Dask makes it a great choice for handling large datasets in a Python-based big data workflow. IronPDF is a robust Python library that facilitates the creation, manipulation, and rendering of PDF documents directly from Python applications. It simplifies tasks such as converting HTML content into PDF documents, creating interactive forms, and performing various PDF manipulations like merging files or adding watermarks. IronPDF integrates seamlessly with existing Python frameworks and environments, providing developers with a versatile solution for generating and customizing PDF documents dynamically. Together with fastparquet, IronPDF enables seamless data manipulation in parquet file formats and PDF generation.
IronPDF offers comprehensive documentation and code examples to help developers make the best of its features. For more information, please refer to the documentation and code example pages.
















