
Python Requests Library (How It Works For Developers)
Python is widely celebrated for its simplicity and readability, making it a popular choice among developers for web scraping and interacting with APIs. One of the key libraries that enable such interactions is the Python Requests library. Requests is an HTTP request library for Python that allows you to send HTTP requests straightforwardly. In this article, we’ll delve into the features of the Python Requests library, explore its usage with practical examples, and introduce IronPDF, showing how it can be combined with Requests to create and manipulate PDFs from web data.
Introduction to the Requests Library
The Python Requests library was created for making HTTP requests simpler and more human-friendly. It abstracts the complexities of making requests behind a simple API so that you can focus on interacting with services and data on the web. Whether you need to fetch web pages, interact with REST APIs, disable SSL certificate verification, or send data to a server, the Requests library has you covered.
Key Features
- Simplicity: Easy to use and understand syntax.
- HTTP Methods: Supports all HTTP methods - GET, POST, PUT, DELETE, etc.
- Session Objects: Maintains cookies across requests.
- Authentication: Simplifies adding authentication headers.
- Proxies: Support for HTTP proxies.
- Timeouts: Manages request timeouts effectively.
- SSL Verification: Verifies SSL certificates by default.
Installing Requests
To start using Requests, you need to install it. This can be done using pip:
pip install requestspip install requestsBasic Usage
Here’s a simple example of how to use Requests to fetch a web page:
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)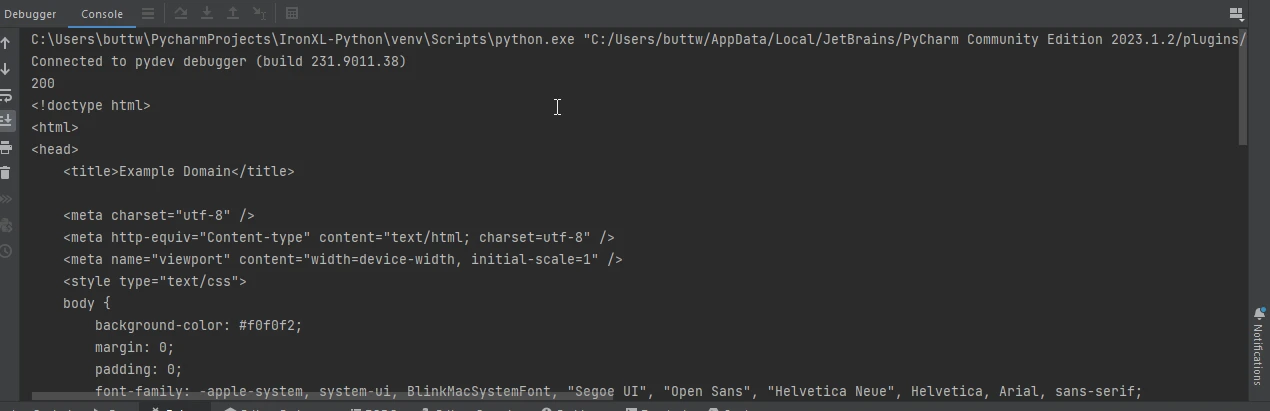
Sending Parameters in URLs
Often, you need to pass parameters to the URL. The Python Requests module makes this easy with the params keyword:
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)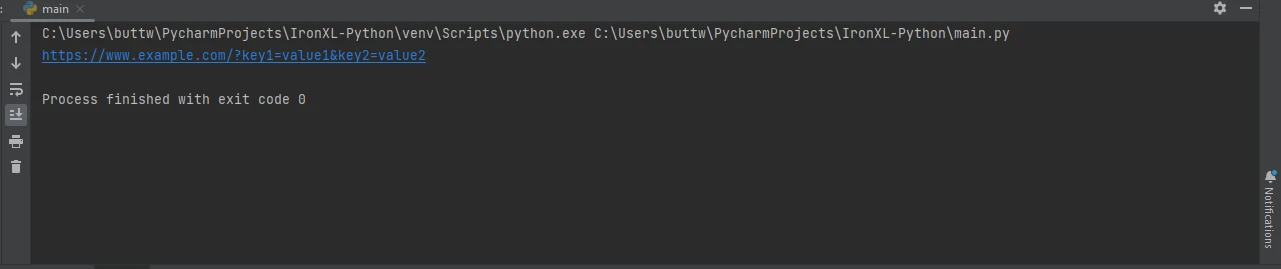
Handling JSON Data
Interacting with APIs usually involves JSON data. Requests simplifies this with built-in JSON support:
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)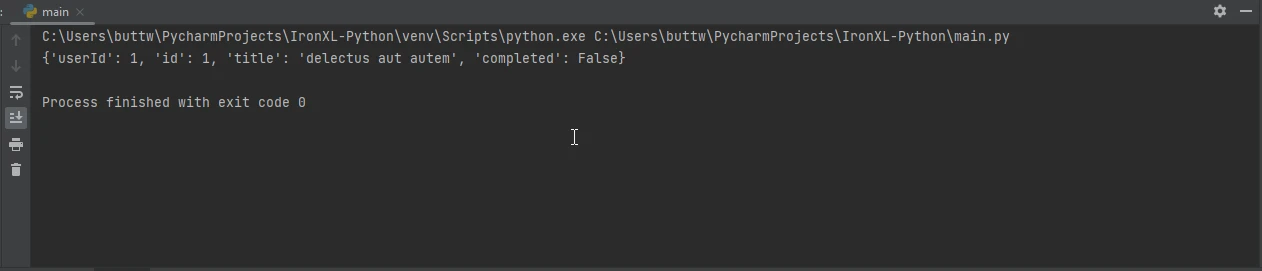
Working with Headers
Headers are crucial for HTTP requests. You can add custom headers to your requests like this:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)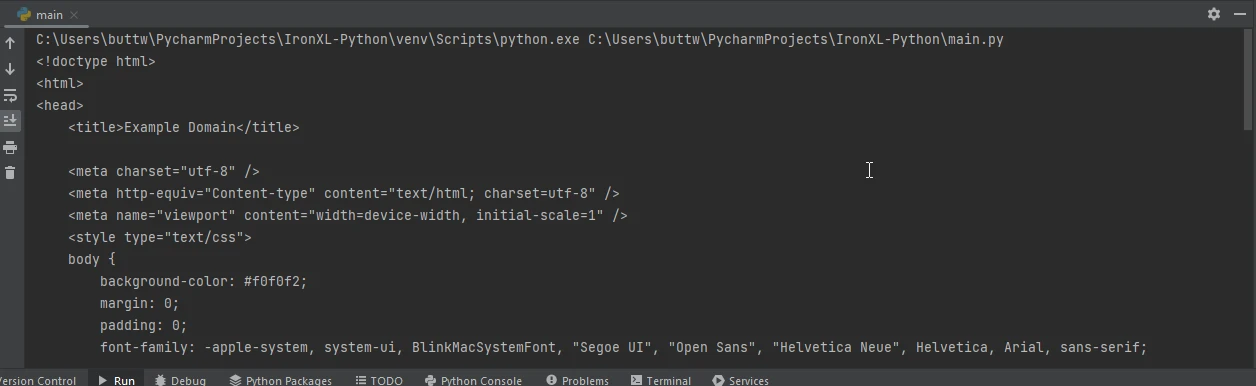
File Uploads
Requests also supports file uploads. Here’s how you can upload a file:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)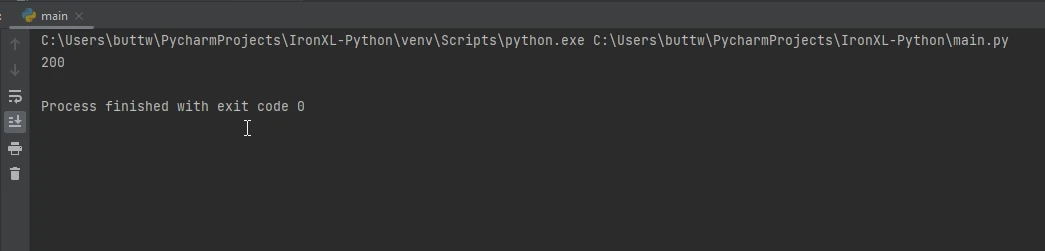
Introducing IronPDF for Python
IronPDF is a versatile PDF generation library that can be used to create, edit, and manipulate PDFs within your Python applications. It’s particularly useful when you need to generate PDFs from HTML content, making it a great tool for creating reports, invoices, or any other type of document that needs to be distributed in a portable format.
Installing IronPDF
To install IronPDF, use pip:
pip install ironpdf
Using IronPDF with Requests
Combining Requests and IronPDF allows you to fetch data from the web and directly convert it into PDF documents. This can be particularly useful for creating reports from web data or saving web pages as PDFs.
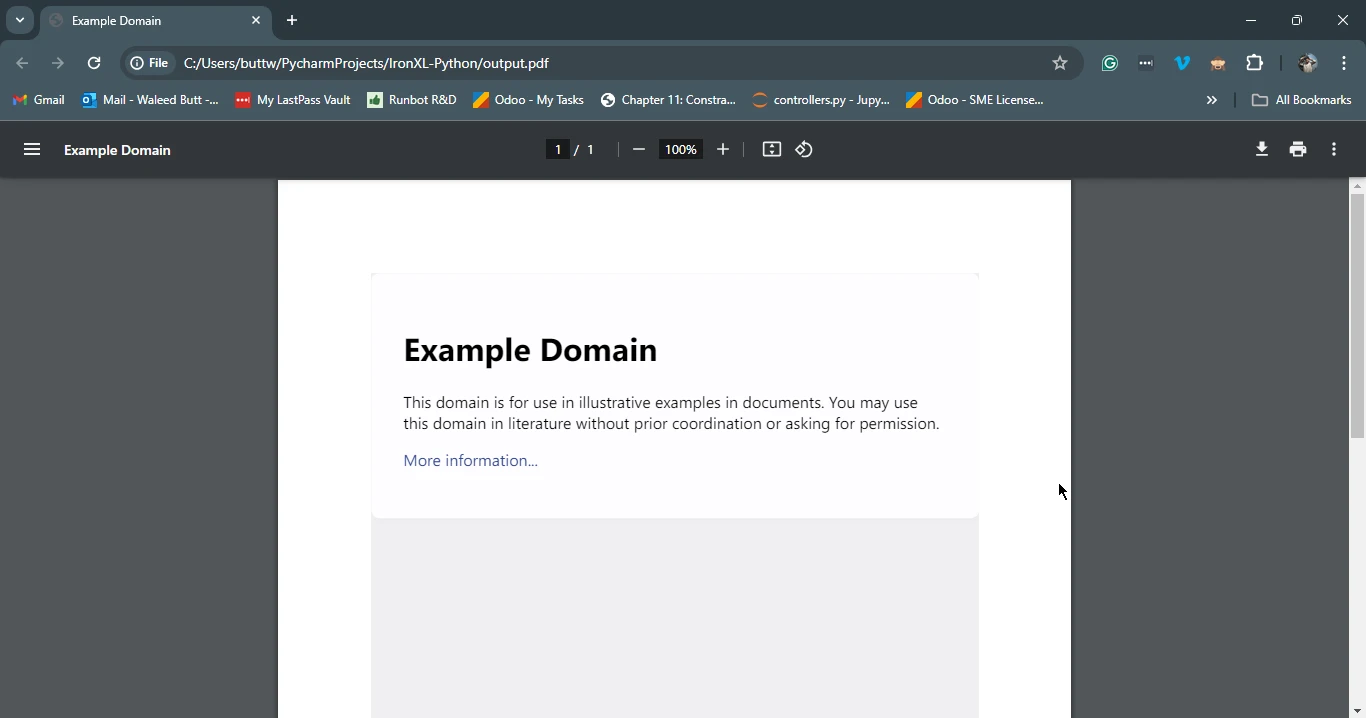
Here’s an example of how to use Requests to fetch a web page and then use IronPDF to save it as a PDF:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')This script first fetches the HTML content of the specified URL using Requests. It then uses IronPDF to convert this response object's HTML content into a PDF and saves the resulting PDF to a file.
Conclusion
The Requests library is an essential tool for any Python developer who needs to interact with web APIs. Its simplicity and ease of use make it a go-to choice for making HTTP requests. When combined with IronPDF, it opens up even more possibilities, allowing you to fetch data from the web and convert it into professional-quality PDF documents. Whether you’re creating reports, invoices, or archiving web content, the combination of Requests and IronPDF provides a powerful solution for your PDF generation needs.
For further information on IronPDF licensing, refer to the IronPDF license page. You can also explore our detailed tutorial on HTML to PDF Conversion for more insights.
















