如何在Mac和Windows上將網頁保存為PDF文件
由於 PDF 文件格式能夠跨不同平台保留格式,因此被廣泛用作文件交換格式。 在各種應用中,透過程式化方式讀取 PDF 文件的內容變得無價。
在本文中,我們將學習如何利用 Xpdf 命令行工具在 C++ 中查看 PDF 文件中的文字。 Xpdf 提供了一套命令行工具和 C++ 程式庫,用於處理 PDF 文件,包括文字提取。 透過將 Xpdf 整合到我們的 C++ PDF 檢視器程式中,我們可以有效地從 PDF 文件中查看文字內容並程式化處理。
Xpdf - C++ 程式庫和命令行工具
Xpdf 是一套開源軟體套件,提供一系列工具和程式庫,用於處理 PDF 文件。 它包括各種命令行工具和 C++ 程式庫,啟用 PDF 相關功能,如解析、渲染、列印和文字提取。 Xpdf 的命令行工具也提供了直接從終端查看 PDF 文件的方法。
Xpdf 的一個主要組成部分是 pdftotext,主要以從 PDF 文件中提取文字內容而聞名。 然而,當與其他工具如 pdftops 和 pdfimages 結合使用時,Xpdf 允許使用者以不同方式查看 PDF 內容。 對於進一步處理或分析來說,pdftotext 工具提供了從 PDF 中提取文字資訊的價值,並提供了選項來指定要提取文字的頁面。
必要條件
在我們開始之前,請確保您具備以下先決條件:
- 在您的系統上安裝了 C++ 編譯器,如 GCC 或 Clang。 我們將使用 Code::Blocks IDE 達成此目的。
- Xpdf 命令行工具已經安裝並可以從命令行存取。下載 Xpdf 並安裝符合您環境的版本。 之後,將 Xpdf 的 bin 目錄設置在系統環境變數路徑中,以便可以從文件系統的任何地方存取它。
建立 PDF 檢視器專案
- 打開Code::Blocks:在您的電腦上啟動Code::Blocks IDE。
- 建立新專案: 從頂部選單中點擊 "File" 並從下拉選單中選擇 "New"。 然後從子選單中點擊 "Project"。
- 選擇專案型別: 在 "New from template" 窗口中,選擇 "Console application",然後點擊 "Go"。 然後選擇語言 "C/C++" 並點擊 "Next"。
- 輸入專案詳情: 在 "Project title" 欄位中,給您的專案命名(例如 "PDFViewer")。 選擇您要保存專案文件的位置,然後點擊 "Next"。
- 選擇編譯器: 選擇要用於專案的編譯器。 預設情況下,Code::Blocks 應該已自動偵測到您系統上的可用編譯器。 如果沒有,從列表中選擇一個合適的編譯器,然後點擊 "Finish"。
在 C++ 中查看 PDF 的步驟
包含必要的標頭
首先,讓我們將所需的標頭文件新增到我們的 main.cpp 文件中:
#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenience#include <cstdlib>
#include <iostream>
#include <fstream>
#include <cstdio>
using namespace std; // Use standard namespace for convenience設定輸入和輸出路徑
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";string pdfPath = "input.pdf";
string outputFilePath = "output.txt";在 main 函式中,我們宣告了兩個字串:pdfPath 和 outputFilePath。 pdfPath 儲存輸入 PDF 文件的路徑,outputFilePath 儲存提取的文字將被保存為純文字文件的路徑。
輸入文件如下:

執行 pdftotext 命令
// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());// Construct the command to execute pdftotext with input and output paths
string command = "pdftotext " + pdfPath + " " + outputFilePath;
// Execute the command using system function and capture the status
int status = system(command.c_str());在這裡,我們使用 pdfPath 和 outputFilePath 變數構建 pdftotext 命令,以打開 PDF 文件以查看其內容。 然後調用 system 函式來執行命令,並將其返回值儲存在 status 變數中。
檢查文字提取狀態
if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}if (status == 0)
{
cout << "Text extraction successful." << endl;
}
else
{
cout << "Text extraction failed." << endl;
}我們檢查 status 變數,以查看 pdftotext 命令是否成功執行。 如果 status 等於 0,表示文字提取成功,然後我們列印成功訊息。 如果 status 不為零,則表示發生錯誤,然後我們列印錯誤消息。
讀取提取的文字並顯示
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open())
{
string textContent;
string line;
while (getline(outputFile, line))
{
textContent += line + "\n"; // Concatenate each line to the text content
}
outputFile.close();
cout << "Text content extracted from PDF:" << endl;
cout << textContent << endl;
}
else
{
cout << "Failed to open output file." << endl;
}在上述範例程式碼中,我們打開 outputFile(由 pdftotext 生成的文字文件),逐行讀取其內容,並將其儲存在 textContent 字串中。 最後,我們關閉文件並在控制台上列印提取的文字內容。
刪除輸出文件
如果您不需要可編輯的輸出文字文件或想釋放磁碟空間,程式結尾時只需在結束主函式之前使用以下命令將其刪除:
// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());// Remove the output file to free up disk space and if output is not needed
remove(outputFilePath.c_str());編譯並運行程式
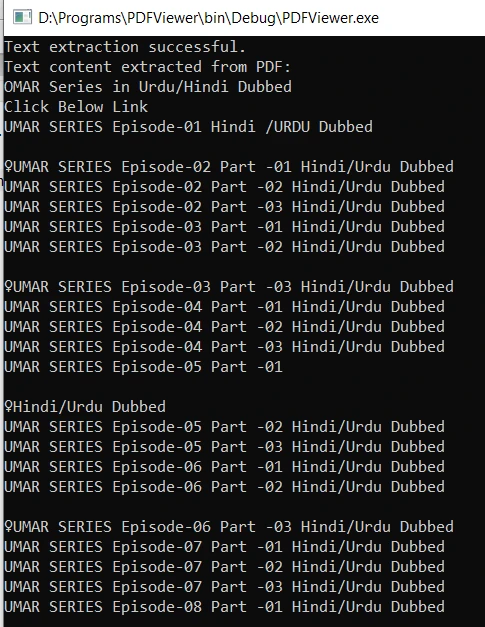
using "Ctrl+F9" 快捷鍵來構建程式碼。 成功編譯後,運行可執行文件將從指定的 PDF 文件中提取文字內容並在控制台上顯示。 輸出結果如下:
View PDF files in C
IronPDF .NET C# 程式庫 是一個強大的 .NET C# PDF 程式庫,允許使用者在他們的 C# 應用程式中輕鬆查看 PDF 文件。 利用 Chromium 網頁瀏覽器引擎,IronPDF 準確地渲染和顯示 PDF 內容,包括圖片、字體和複雜格式。 憑藉其使用者友好的介面和豐富的功能開發人員可以無縫地將 IronPDF 整合到他們的 C# 專案中,方便使用者高效且互動地查看 PDF 文件。 無論是顯示報告、發票還是任何其他 PDF 內容,IronPDF 為在 C# 中建立功能豐富的 PDF 檢視器提供了一個強大的解決方案。
要在 Visual Studio 中安裝 IronPDF NuGet 套件,請遵循以下步驟:
- 開啟 Visual Studio: 啟動 Visual Studio 或您偏好的其他 IDE。
- 建立或打開您的項目: 建立一個新的 C# 項目或打開一個現有的專案,您希望在其中安裝 IronPDF 套件。
- 打開 NuGet 套件管理器: 在 Visual Studio 中,轉到 "Tools" > "NuGet Package Manager" > "Manage NuGet Packages for Solution"。 或者,點擊解決方案資源管理器,然後選擇 "Manage NuGet Packages for Solution"。
- 搜尋 IronPDF: 在 "NuGet Package Manager" 視窗中,點擊 "Browse" 標籤,然後在搜尋欄中搜尋 "IronPDF"。 或者,存取 NuGet IronPDF Package 並直接下載最新版本的 "IronPDF"。
- 選擇 IronPDF 套件: 找到 "IronPDF" 套件並點擊將其選擇用於項目。
- 安裝 IronPDF: 點擊 "Install" 按鈕來安裝選定的套件。
-
但是,您也可以使用 NuGet 套件管理器控制台,使用以下命令來安裝 IronPDF:
Install-Package IronPdf
using IronPDF,我們可以執行操作,例如提取文字和圖像從 PDF 文件並在控制台中顯示以進行查看。 以下程式碼幫助實現此任務:
using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}using IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Extracting Image and Text content from Pdf Documents
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text to put in a search index
string text = pdf.ExtractAllText();
// Get all Images
var allImages = pdf.ExtractAllImages();
// Or even find the precise text and images for each page in the document
for (var index = 0 ; index < pdf.PageCount ; index++)
{
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Further processing here...
}Imports IronPdf
Imports IronSoftware.Drawing
Imports System.Collections.Generic
' Extracting Image and Text content from Pdf Documents
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text to put in a search index
Private text As String = pdf.ExtractAllText()
' Get all Images
Private allImages = pdf.ExtractAllImages()
' Or even find the precise text and images for each page in the document
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Further processing here...
Next index如需有關 IronPDF 的詳細資訊,請存取 IronPDF 文件。
結論
在本文中,我們學習了如何使用 Xpdf 命令行工具在 C++ 中提取和查看 PDF 文件的內容。 這種方法讓我們能夠在我們的 C++ 應用中無縫地處理和分析提取的文字。
免費試用授權 可用於商業用途測試。